跳至内容
前沿人工智能的发展依赖于强大的AI超级计算机,目前谁拥有着地表最强的AI算力?
近日,致力于研究人工智能未来的科学家团队Epoch AI在新发表的一篇论文报告中对此进行了研究分析。
研究人员创建了一个包含2019年至2025年间500 多台人工智能超级计算机的数据集,并对其性能、电力需求、硬件成本、所有权以及全球分布等关键趋势进行了分析,发现很多有趣现象。
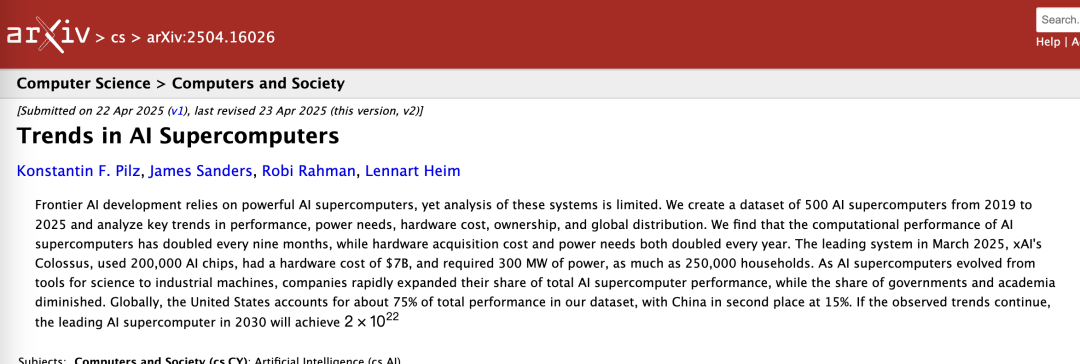
从宏观层面来看,在部署更多且更优质的人工智能芯片的推动下,领先的人工智能超级计算机的计算性能每9个月就会翻一番,每年保持2.5倍的增长速度。
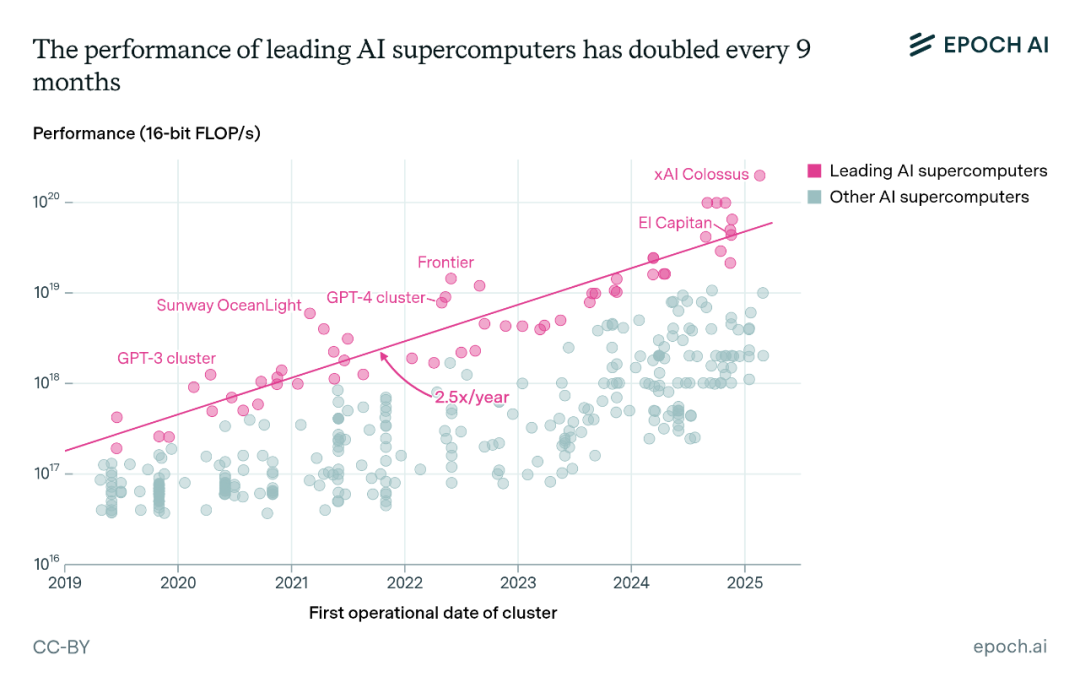
有两个关键因素推动了这一增长:芯片数量每年增长1.6倍,单个芯片的性能每年提升1.6倍。2019年,芯片数量超过1万的系统还很罕见,但在2024年,企业部署的人工智能超级计算机规模达到了这一数量的十倍以上,比如马斯克xAI公司建设的Colossus超级计算机,计划配备20万个人工智能芯片,据悉最终目标是配置超过100万个英伟达顶尖GPU。
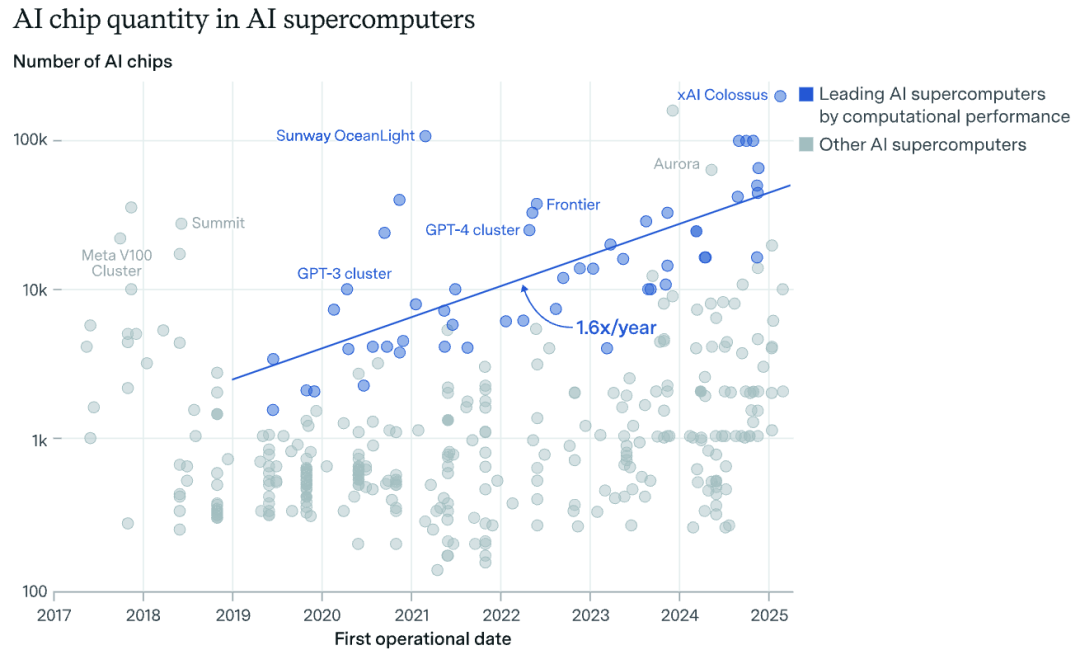
人工智能超级计算机的硬件成本每年增长1.9倍,而电力需求则每年增长2倍。除了电力需求大幅增加之外,人工智能超级计算机其实也在变得更加节能:每瓦的计算性能每年提升约1.34倍,这得益于更节能的芯片设计研发。
如果按目前观察到的趋势持续下去,到2030年6月,领先的人工智能超级计算机将会有200万个人工智能芯片,仅硬件成本就达到2000亿美元,并且需要9千兆瓦的电力。从人工智能芯片产量的增长情况,以及像5000亿美元投资的 “星际之门”(Project Stargate)这样的重大项目进展来看,很可能会快速实现。
9千兆瓦的电力相当于9座核反应堆的发电量,这一规模超过了大部分现有的工业设施,为了克服电力方面的限制,企业可能会越来越多地采用去中心化的训练方法,这种方法将使他们能够把一次训练任务分配到多个地点的人工智能超级计算机上进行。
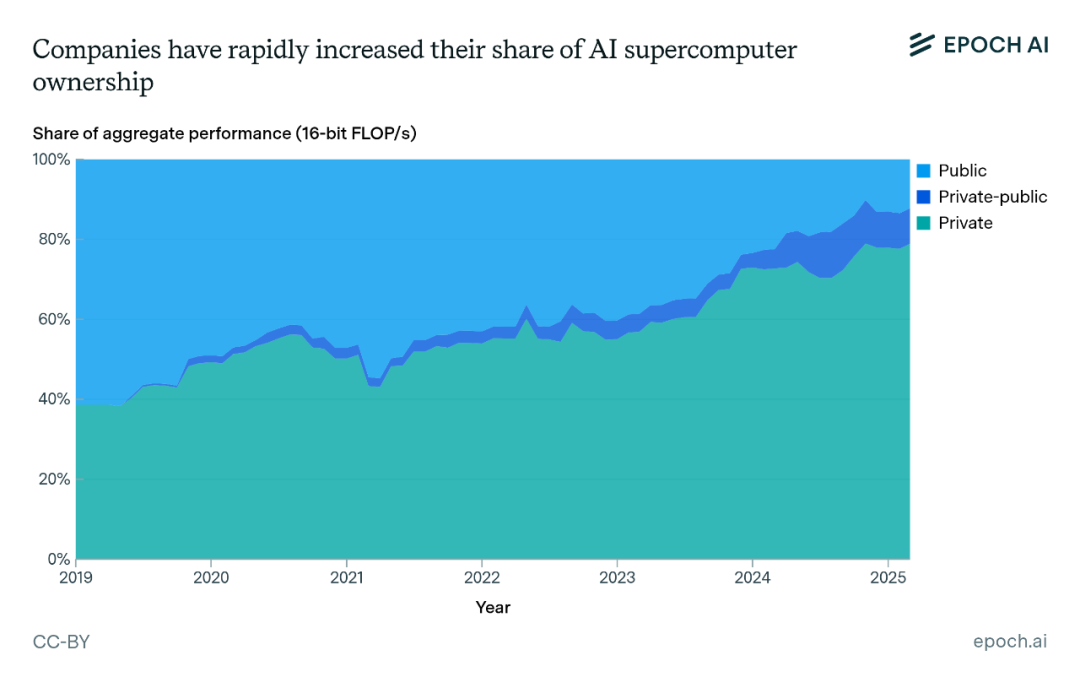
企业在人工智能超级计算机领域占据主导地位。由于人工智能开发吸引了数十亿美元的投资,各大AI企业迅速扩大了人工智能超级计算机的规模,以便进行更大规模的训练任务,这使得行业内领先系统的性能每年增长2.7倍,远远快于公共部门系统每年1.9倍的增长速度。
目前,企业在人工智能计算总量中所占的份额从2019年的40%飙升至2025年的80%,而公共部门所占的份额则降至20%以下。
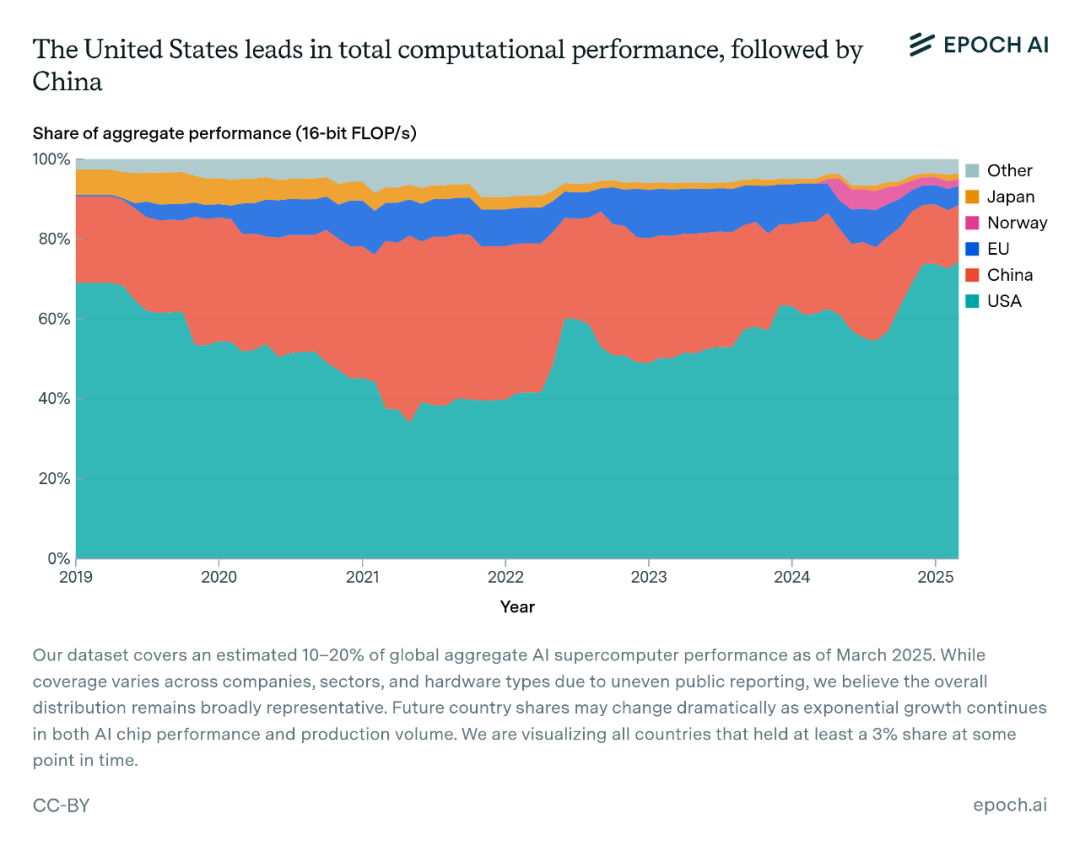
全球AI算力的分配并不均衡,75%的人工智能超级计算机位于美国,总性能占据全球总量的四分之三,中国位居第二占比15%,像英国、德国和日本这样的传统超级计算强国,如今在人工智能超级计算机领域中逐渐处于边缘角色。
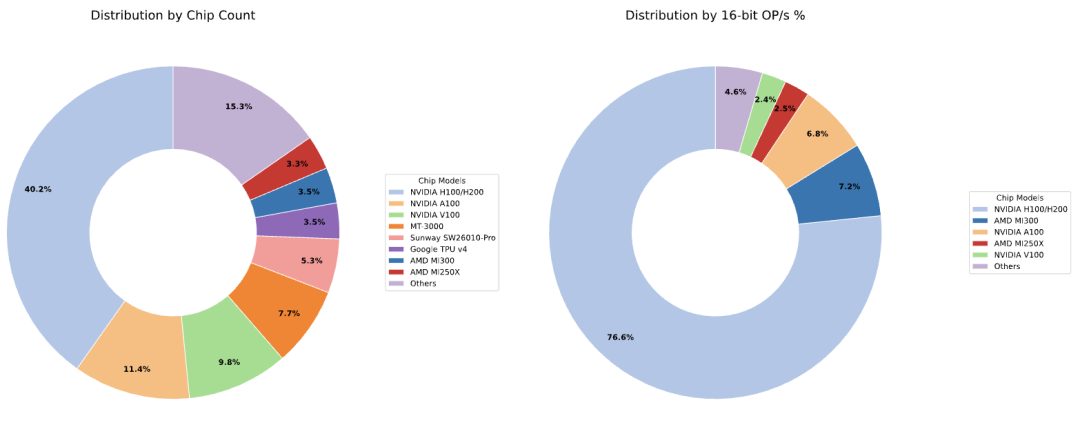
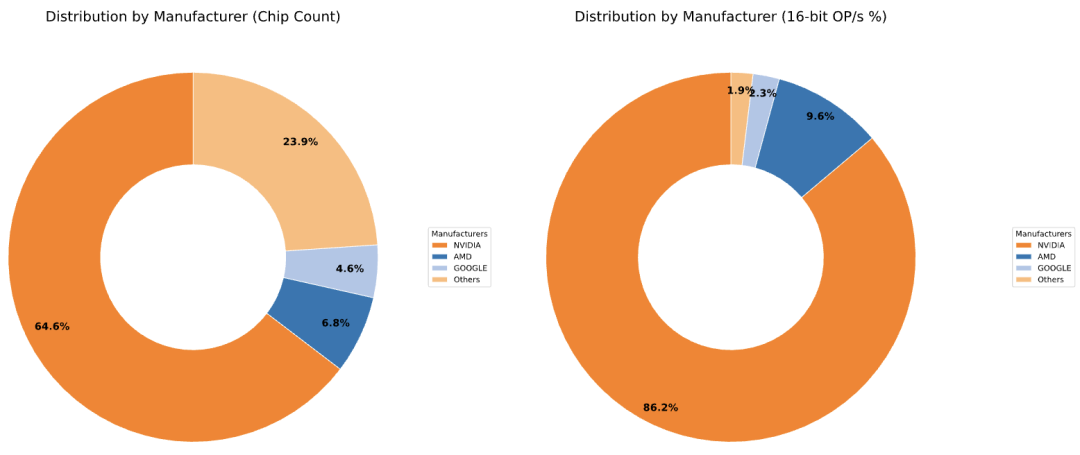
研究人员的数据集中还展示了正在运行的人工智能超级计算机所使用的芯片类型,按芯片数量统计(左图)以及按每秒浮点运算次数统计(右图),英伟达占据了绝对霸主地位,但AMD在AI算力层面逐渐显现出一定竞争力。
全球领先的科技公司,如谷歌、微软、Meta和亚马逊,所拥有的人工智能计算能力相当于数十万块英伟达H100 芯片。这种计算能力既用于其内部的人工智能研发,也提供给云服务客户,其中包括许多顶尖的人工智能实验室,比如OpenAI和Anthropic。
2022年初至2024年中期,英伟达H100芯片或同等产品的销量约为300万片,研究人员根据每家公司在英伟达收入中所占的份额,估算出每家公司H100芯片的分配情况。
在科技巨头行列中,谷歌或许能够使用相当于超过100万块H100芯片的计算能力,其中大部分来自其张量处理单元(TPUs),截至2024年9月,谷歌在耗电量超过1GW的数据中心部署了约“数百万”个TPU,这相当于约650000个英伟达H100。
而支撑OpenAI算力的微软可能拥有英伟达加速器的最大单一库存,大约相当于50万块H100芯片的计算能力。
除头部四家公司外,人工智能计算能力的很大一部分掌握在其他科技集团手中,包括甲骨文和CoreWeave等其云计算公司、特斯拉和xAI等计算用户。
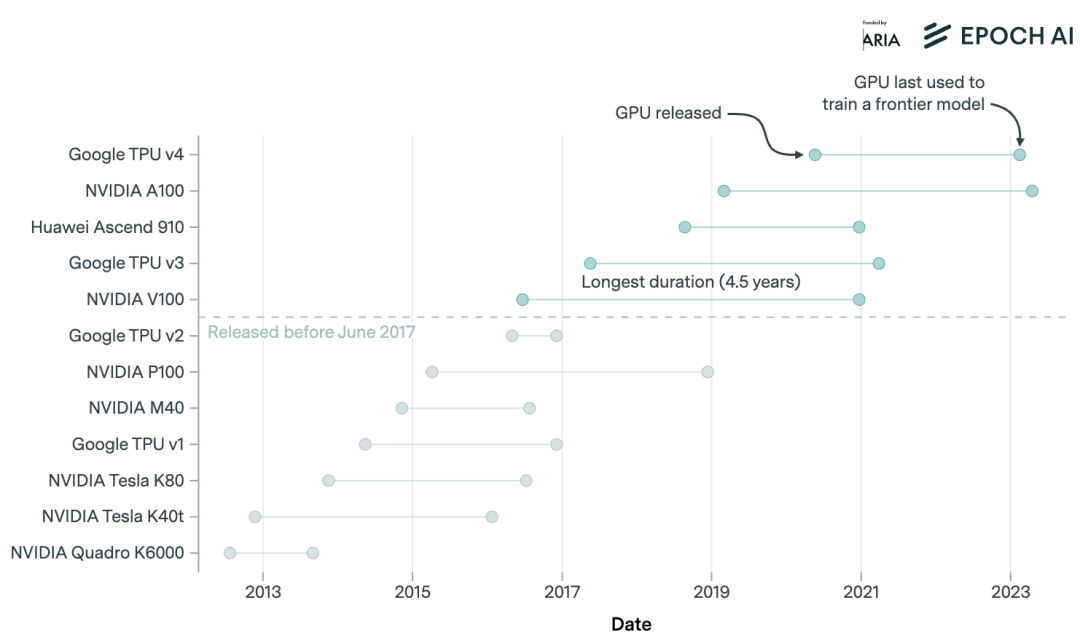
商用AI芯片设计的“前沿寿命”实际有多久?研究人员关注了NVIDIA V100及之后的AI芯片,因为这些芯片用于与当今前沿模型类似的大规模语言模型训练,数据分析显示,从领先的AI芯片发布到使用它们训练的最后一个前沿模型的发布,平均时间目前仅为3.9年。
自2019年以来,NVIDIA芯片的总可用计算能力每10个月翻一番,每年增长约2.3倍,从而支持训练更大规模的模型。Hopper一代NVIDIA AI芯片目前占据其所有AI硬件总计算能力的77%,老一代芯片在推出约4年后累计计算能力的贡献往往不到一半。
Epoch AI的数据分析显示,OpenAI、Anthropic和Google DeepMind在2024年下半年的收入均增长了90%以上,年化增长率超过3倍,预计到 2025年4月,OpenAI的今年收入预计约为100亿美元。
语言模型对基准问题的响应长度(无论是推理模型还是非推理模型)都随着时间的推移而增长。根据我们的内部基准测试,推理模型的响应增长速度(每年5倍)远快于非推理模型(每年2.2倍),推理模型使用的标记数量比非推理模型约多出8倍,但未来GPT-5的推出可能会模糊推理和非推理之间的界限。
与美国AI科技巨头相比,中国前沿AI模型的发展受阻于美国对英伟达AI芯片的一系列限制和禁令,但挡不住的是国内企业对创新的深度挖掘。
最新消息称,中芯国际已成功在不依赖极紫外(EUV)光刻技术的情况下实现了5nm芯片制造工艺,中芯国际没有使用ASML严格限制出口的EUV光刻技术,而是采用了较老的深紫外(DUV)设备,并结合了一种名为自对准四重图案化(SAQP)的复杂技术,这一进展可能会对国内AI算力市场带来改善,据悉,华为将利用这项技术打造其AI芯片Ascend 910C,以实现与H100芯片相当的性能,旨在减少对NVIDIA的依赖。
另一方面,DeepSeek R2模型今天也传出了不少小道消息,传言称,该新模型将拥有1.2T参数,单位token成本较GPT-4 Turbo可下降97.3%,且能在华为昇腾910B芯片集群上运行。
虽然关于R2的消息目前都是传言和猜测,但许多开发者们已经迫不及待了,提前打开了社区通知坐等其开源上线,此前业内也有分析称R2很可能最快在5月份推出。
尽管英伟达芯片受限,但国产算力和国产模型的协同创新可能会开辟出一条不一样的突围路径。
(文:头部科技)