
FG-CLIP团队 投稿
量子位 | 公众号 QbitAI
CLIP的“近视”问题,被360搞定了。
360人工智能研究院最新图文跨模态模型FG-CLIP,宣布以“长文本深度理解”和“细粒度视觉比对”双突破,彻底解决了传统CLIP模型的“视觉近视”问题,能够精准识别局部细节。
具体怎么个说法?先来个视力大挑战:找一找右边的哪句话,正确描述了左边图像里的内容?

正确答案是:“A light brown wood stool(一个浅棕色的木凳子)”,注意看,这个木凳子位于画面的中央偏右,悄悄隐藏在狗狗的身后。

可以发现,4个常用模型——CLIP、EVACLIP、SIGLIP、FINE-CLIP基于左侧图片选出的最匹配的文本描述是:A blue dog with a white colored head。
显然这个描述是错误的,这就是CLIP的“视觉近视”问题:会因为对比损失倾向于拉近全局图像与文本的嵌入,而非局部区域的对齐,削弱了细粒度特征学习。
而FG-CLIP则精准命中了答案。
实验结果显示,FG-CLIP在细粒度理解、开放词汇对象检测、长短文本图文检索以及通用多模态基准测试等下游任务中均显著优于原始CLIP和其他最先进方法。

在12个下游任务上,FG-CLIP相比现有模型在关键的长文本理解+细粒度比对上实现了大幅突破。
360人工智能研究院还表示,将全面开源模型及其相关数据。
视觉语言模型面向的问题
2021年,OpenAI发布CLIP图文跨模态模型,通过对比学习,首次实现了大规模图像-文本对齐,开启了多模态预训练大模型的新纪元。它通过对比图像与文本的嵌入空间,使模型能够完成零样本分类、图像检索等任务。
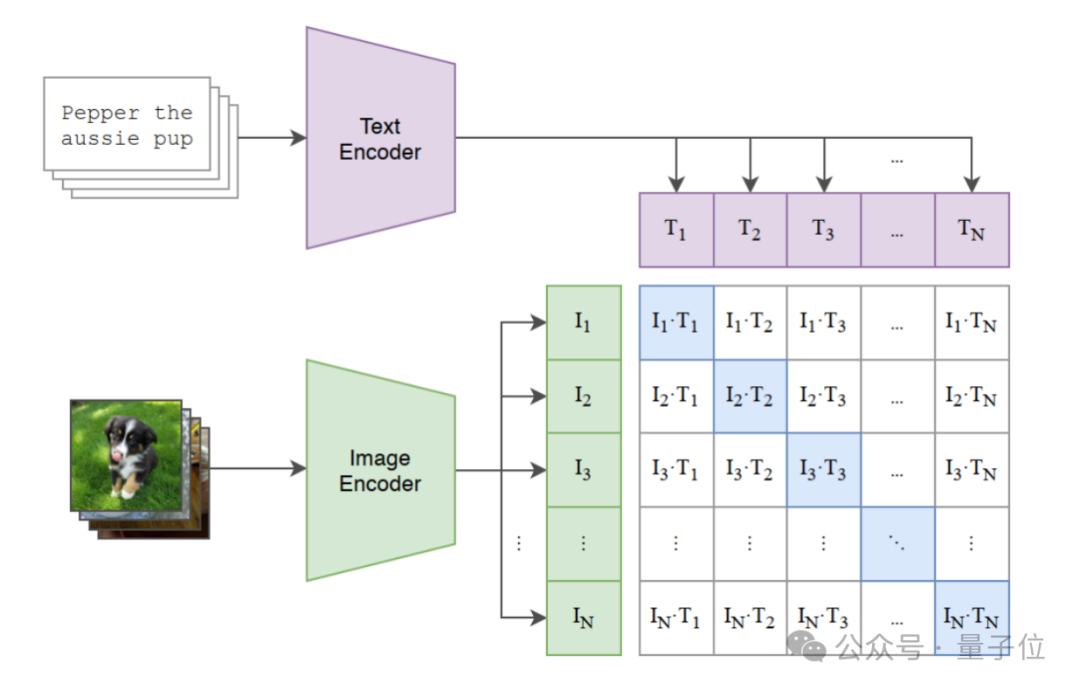
但是CLIP与后面发展的模型,在实际应用中依然面临以下的制约:
文本长度限制:CLIP的文本编码器仅支持77个token,难以处理长文本的细节描述(如“一只红色的陶瓷茶杯,杯口有轻微磨损”)。
全局对齐的盲区:CLIP将图像与文本整体对齐,忽略了局部区域的细粒度信息(如茶杯的把手形状、杯身图案)。
负样本的不足:现有数据集中,负样本(不匹配的图像-文本对)多为粗略的类别错误,缺乏对细微差异的区分能力。
对长文本细节描述理解的重要性
提供丰富的背景信息与复杂查询能力:长文本能够提供详细的背景信息,包括动作状态、对象属性及变化过程等,这对于全面理解事件至关重要。
相比短文本分析,长文本允许综合查找基于多个条件(如物体、人物特征)的信息,支持更加复杂的查询需求。这使得模型不仅能识别发生了什么,还能理解事件的全貌及其上下文。
支持跨模态深度语义匹配与融合能力:跨模态模型需要在不同模态间建立有效的语义对应关系。
长文本中的多层次语义信息(如主题、段落、句子乃至词汇层面的意义)可以帮助模型更精确地进行语义匹配和特征融合。
在图文检索任务中,长文本描述可以涵盖从全局场景到局部细节的全面信息,使得模型能够在多个层次上与图像特征进行比对和匹配,从而提升检索的准确性和相关性。
对局部区域细粒度信息进行准确分析的重要性
细节捕捉:局部图像特征往往包含了区分不同对象的关键信息。
例如,在对不同人物进行分析时,着装、动作等属性差别对于区分个体至关重要。准确分析这些局部特征可以显著提高识别系统的准确性。
复杂环境适应性:在复杂的背景或低质量图像中,局部特征可以帮助算法聚焦于最重要的信息,忽略干扰因素。
在实际应用中,目标对象经常会被其他物体部分遮挡。在这种情况下,全局特征可能不足以描述对象,而局部特征则显得尤为重要。
通过对局部特征的精确分析,系统能够有效地识别出未被遮挡的部分,并利用这些信息来推断整个对象的状态。
局部图像特征属性的准确分析:在提升识别精度、增强环境理解、支持高级别应用、改进用户体验以及保障安全性等方面具有核心重要性。
通过精确解析这些细节信息,可以实现更智能、更可靠的系统性能,无论是在监控、自动驾驶、产品质量控制还是其他需要细致图像分析的领域中,都能发挥关键作用。
对图像/文本的细微差异实现准确理解的重要性
增强模型的鲁棒性和泛化能力:准确区分图像和文本中的细微差别对于增强模型的鲁棒性和泛化能力至关重要。
细粒度的理解使模型能够区分在视觉或语义上相似但存在细微差异的对象、场景或概念。
这种能力对于现实世界的应用非常重要,因为在不同的光照、角度或背景下,对象可能会有细微的变化。确保模型能够在各种复杂场景中可靠运行。
提升下游任务的精度:精确识别细微差异对提高下游任务(如图像描述生成、视觉问答和医学影像诊断)的准确性至关重要。
例如,在视觉问答中,识别图像中的微小细节并理解其与问题的相关性是正确回答问题的关键。能否准确捕捉图像中的细微差异直接影响到系统的性能和用户体验。
同样,在自然语言处理中,识别文本中的细微差异可以显著提高情感分析和信息检索等任务的表现
模型方法
FG-CLIP在传统双编码器架构基础上采用两阶段训练策略,有效提升了视觉语言模型的细粒度理解能力。
首阶段通过全局对比学习实现图文表征的初步对齐;次阶段引入区域对比学习与难细粒度负样本学习,利用区域-文本标注数据深化模型对视觉细节的感知能力,从而在保持全局语义理解的同时实现了对局部特征的精准捕捉。

全局对比学习
全局对比学习通过整合多模态大模型生成的长描述,显著增强了模型的细粒度理解能力。
这种方法不仅生成了内容丰富的长描述,还提供了更完整的上下文信息和更精准的细节描述。
通过引入长描述,模型得以在全局层面感知和匹配语义细节,从而大幅提升了其上下文理解能力。
同时,FG-CLIP保留了原有的短描述-图像对齐机制,使长短描述形成互补。
这种双轨并行的策略使模型既能从长描述中获取复杂的语义信息,又能从短描述中把握核心概念,从而全面提升了模型对视觉信息的理解和处理能力。
局部对比学习
局部对比学习通过精准对齐图像局部区域与对应文本描述,实现细粒度的视觉-语言关联。
具体而言,FG-CLIP首先运用RoIAlign从图像中精确提取区域特征,继而对每个检测区域施加平均池化操作,获取一组富有代表性的区域级视觉表征。
这些局部特征随后与预先构建的细粒度文本描述进行对比学习,促使模型建立区域视觉内容与文本语义之间的精确映射关系,从而掌握更为细致的跨模态对齐能力。
区域级难负样本对比学习
针对细粒度负样本稀缺这一挑战,FG-CLIP提出了一种难细粒度负样本学习方法。
FG-CLIP将语义相近但与正样本存在细微差异的样本定义为难负样本,并通过对边界框描述进行属性层面的微调和重写来构建这些样本。
为了充分利用难细粒度负样本提供的判别信息,FG-CLIP在损失函数中引入了特定的细粒度负样本学习策略。
在训练过程中,模型需要同时计算区域特征与正样本描述及其对应负样本描述之间的相似度,从而学习更精细的视觉-语言对齐关系。
数据构建
通过LMM进行详细的图像描述重写
在初始训练阶段,FG-CLIP采用了经过增强优化的LAION-2B数据集,其中的图像标注经由CogVLM2-19B重新生成。
这种改进显著提升了数据质量,使描述更加精确和内容丰富。
传统LAION-2B数据集往往采用笼统的描述方式,难以支持精细化任务的需求。
以鸟类图像为例,原始标注可能仅为”一只鸟”,而忽略了物种特征和环境细节。
通过引入先进的多模态大模型,FG-CLIP生成的描述不仅准确识别目标对象,还涵盖了对象特征、行为模式及场景关联等多维信息。
举例而言,简单的”一只鸟”被优化为”一只红翼黑鸟栖息在公园的树枝上”,大幅提升了描述的信息密度。
借助160×910B规模的NPU计算集群,FG-CLIP在30天内完成了全部数据处理工作。
实验结果显示,这种优化显著提升了模型在多个任务上的表现,充分证明了高质量文本标注对提升模型精确度和语境理解能力的关键作用。
创建高质量的视觉定位数据
对于训练的第二阶段,FG-CLIP开发了一个高质量的视觉定位数据集,包含精确的区域特定描述和具有挑战性的细粒度负样本。
FG-CLIP根据GRIT提供的图像来制作整个数据集。
这一过程首先使用CogVLM2-19B生成详细的图像描述,确保描述全面且细腻,能够捕捉每张图像的全部背景信息。随后,FG-CLIP使用SpaCy解析这些描述并提取出指代表达。
接着,将图像和指代表达输入预训练的开放词汇检测模型,这里采用Yolo-World,以获得相应的边界框。
通过非极大值抑制消除重叠的边界框,仅保留预测置信度得分高于0.4的边界框。
这一过程产生了1200万张图像和4000万个带有精细区域描述的边界框。

为生成高质量的细粒度负样本,FG-CLIP在维持对象名称不变的前提下,对边界框描述的属性进行精细调整。
具体而言,FG-CLIP借助Llama-3.1-70B大语言模型,为每个正样本构建10个对应的负样本。
为提升描述的可读性,FG-CLIP移除了分号、逗号和换行符等标点符号。
经过对3,000个负样本的质量评估,98.9%的样本达到预期标准,仅1.1%被判定为噪声数据,这一比例符合无监督方法的可接受范围。
这种方法产生的细微变化更贴近现实场景,能够更好地模拟物体在保持基本类目相似的同时,具体细节存在差异的情况。

这项大规模数据集由1200万张高质量图像构成,每张图像都配备精确的语义描述。
其中包含4000万个边界框标注,每个边界框都附带详尽的区域描述,同时还整合了1000万个经过筛选的难细粒度负样本。
数据处理阶段调用了160×910B算力的NPU集群,历时7天高效完成。
这套丰富而系统的数据集显著提升了模型识别精细特征的能力,为FG-CLIP的训练奠定了扎实基础,使其在视觉与文本特征的细粒度理解方面表现卓越。
实验效果-量化指标
细粒度识别
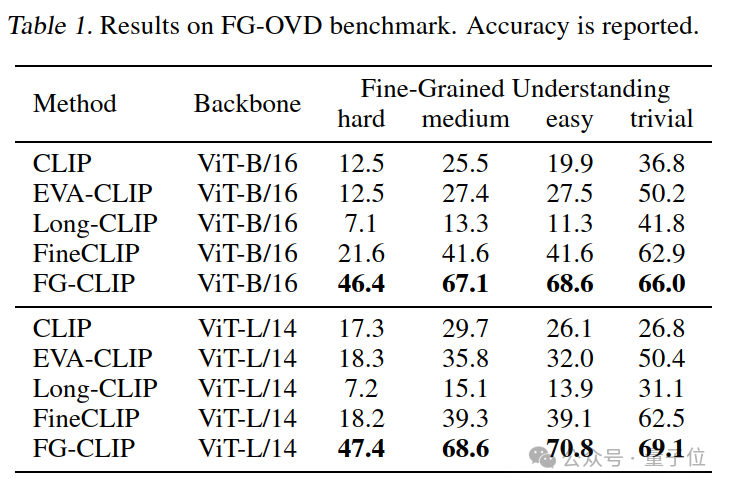
FG-CLIP基于FG-OVD数据集对开源图像-文本对齐模型进行了系统评估。
与MSCOCO和Flickr等聚焦整体匹配的传统基准不同,FG-OVD专注于考察模型识别和定位图像局部区域的精细化能力。
在评估过程中,每个目标区域都配备了一个精准描述和十个经过精心设计的负向样本,这些负向样本通过对正确描述的策略性修改而生成。
FG-OVD数据集划分为四个难度递进的子集,其区分度主要体现在待匹配文本之间的相似程度上。
具体而言,hard、medium和easy子集分别通过替换一个、两个和三个属性词来构造负样本,而trivial子集则采用完全无关的文本描述,形成了一个从细微差别到显著差异的评估体系。
由表中可以看到,FG-CLIP相对于其他方法,在各项指标上都能获得显著提升,这也证明了该方法在细粒度理解上的能力。
区域识别
FG-CLIP在COCO-val2017数据集上开展零样本测试,评估模型识别局部信息的能力,测试方案参照FineCLIP和CLIPSelf。
这项评估着重考察模型仅依靠文本描述对边界框内目标进行分类的表现。
具体实现中,FG-CLIP利用数据集中的边界框标注,结合ROIAlign技术提取局部区域的密集特征表示。
在测试阶段,将所有类别标签作为候选文本输入,对每个边界框区域进行匹配和分类,并通过Top-1和Top-5准确率进行性能评估。FG-CLIP同样在这个下游任务上取得了最好的结果。

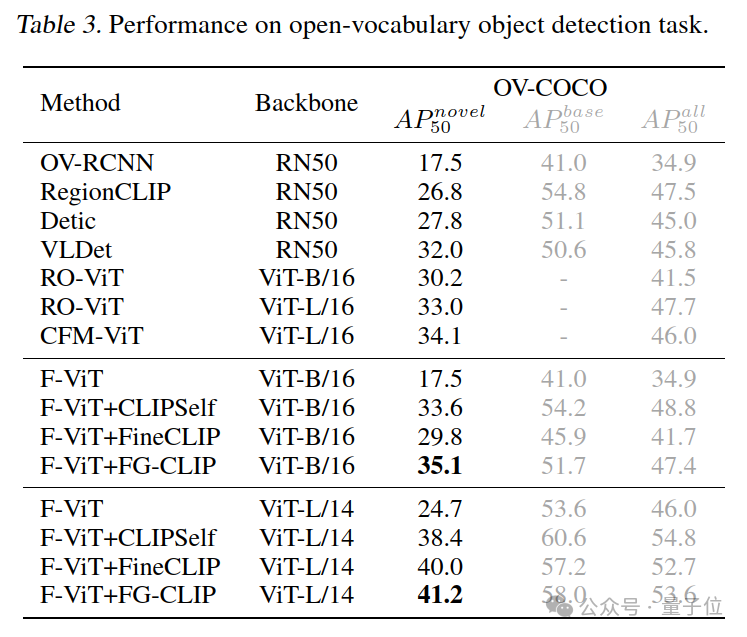
开放词汇目标检测
为了进一步评估FG-CLIP的方法的细粒度定位能力,FG-CLIP被采用作为下游开放词汇检测任务的Backbone。
具体来说,FG-CLIP采用了一个两阶段检测架构F-VIT,并在训练中冻结了视觉编码器。
从表格中可以看出,FG-CLIP在开放词汇目标检测任务上表现更加突出,证明了经过高质量数据和优化方法训练的模型能够在更深层次的任务上取得优越的性能。
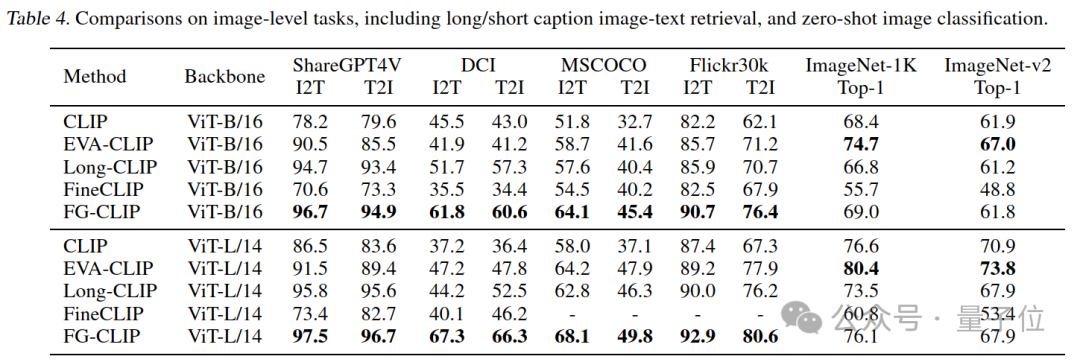
图文检索/分类结果
为了全面评估图像力度的任务,FG-CLIP对长标题和短标题图像文本检索任务以及零样本图像分类任务进行了实验。
如表所示,FG-CLIP在长/短标题图像-文本检索任务中都取得了显著的性能提升。
与旨在提高细粒度识别能力的 Long-CLIP 和 FineCLIP 相比,FG-CLIP在图像分类这种短文本-全图问题上的准确率方面具有明显优势。该模型处理不同图像描述长度的能力突出了其在多模态匹配中的通用性和鲁棒性。
实验效果-可视化对比
图像细节差异效果对比
FG-CLIP针对文本输入对图像特征进行了可视化。
图中,暖色调(如黄色)表示相关性较高,而冷色调(如蓝色)表示相关性较低。
首先是针对相同的输入文本和图像,对不同模型的ViT特征进行比较,可以发现FG-CLIP在这种细粒度理解问题上表现更好。如图中的第二行所示,当输入“Black nose”时,FG-CLIP可以对该小目标实现准确的识别。
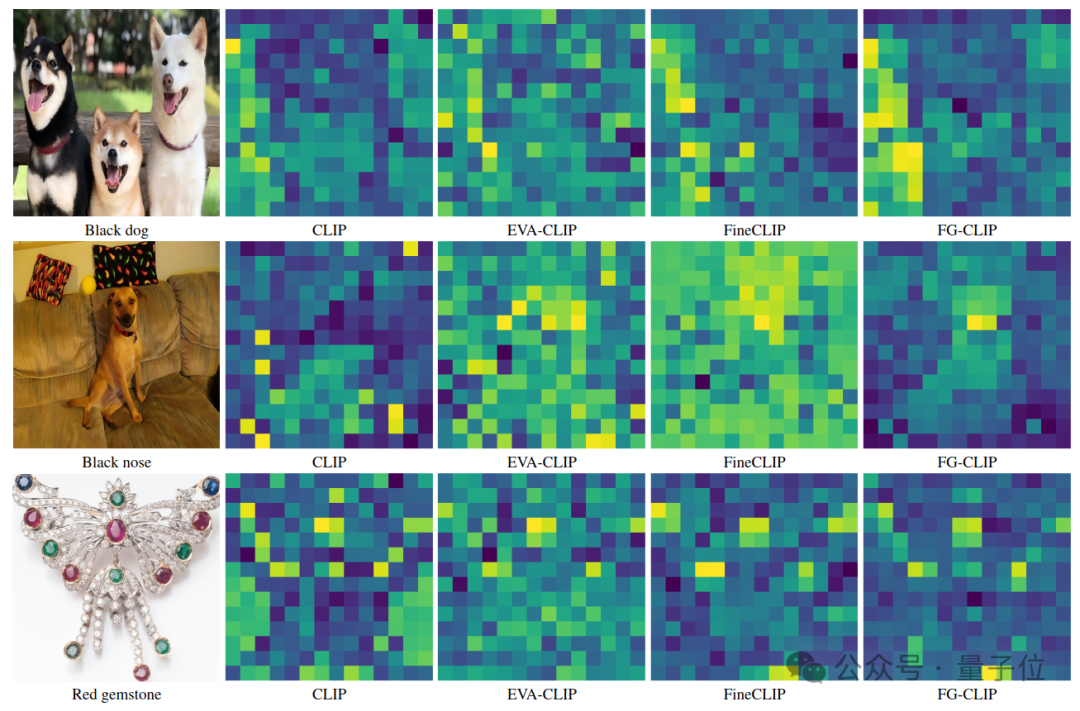
在不同输入文本下的可视化图
FG-CLIP同样将不同的输入文本和相同图片做相关性分析。
可以发现,对于图像中的不同目标,FG-CLIP都能给出准确的位置理解,这表明了该模型具有稳定的视觉定位和细粒度理解能力。
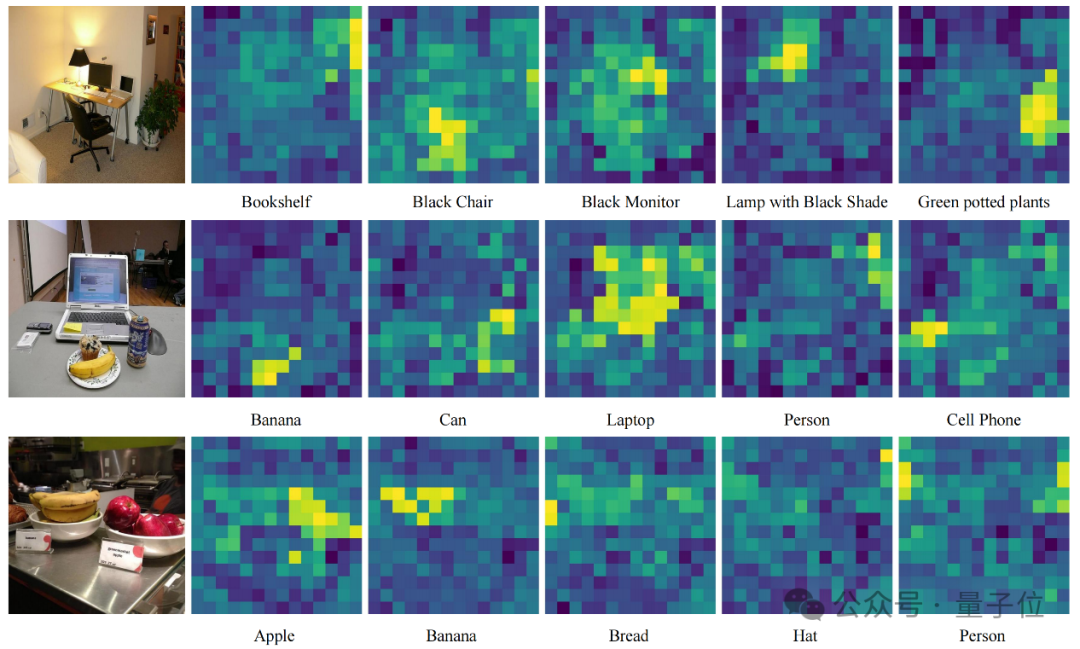
总结
FG-CLIP在细粒度视觉理解领域取得了突破性进展。
该模型创新性地整合了前沿图文对齐技术,并基于大规模精选数据集和难细粒度负样本学习策略,实现了对图像的多层次语义解析。
其独特优势在于能同时把握全局语境和局部细节,精准识别和区分细微特征差异。
大量实验结果表明,FG-CLIP在各类下游任务中均展现出优异表现。
360人工智能研究院表示:
为推动领域发展,研究团队决定将FG-CLIP相关的数据、代码和预训练模型陆续进行开源,相关内容将在360人工智能研究院的主页和GitHub发布。
未来研究团队的研究方向将聚焦于融合更先进的多模态架构,以及构建更丰富多元的训练数据集,以进一步拓展细粒度视觉理解的技术边界。
360人工智能研究院主页:
https://research.360.cn
Github:
https://github.com/360CVGroup
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)