

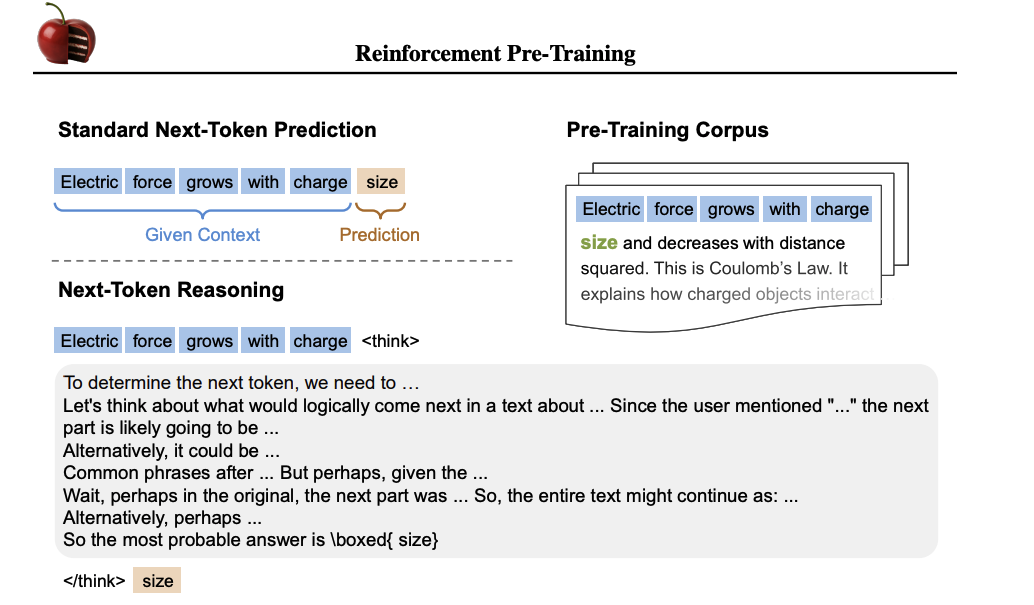
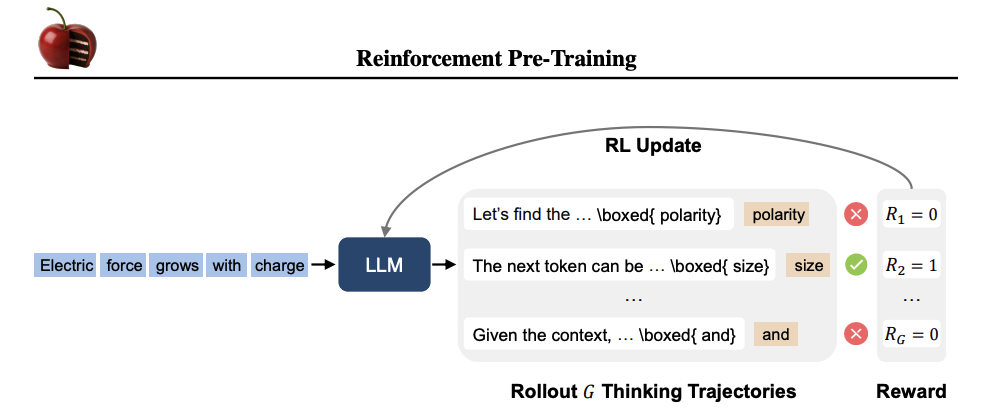
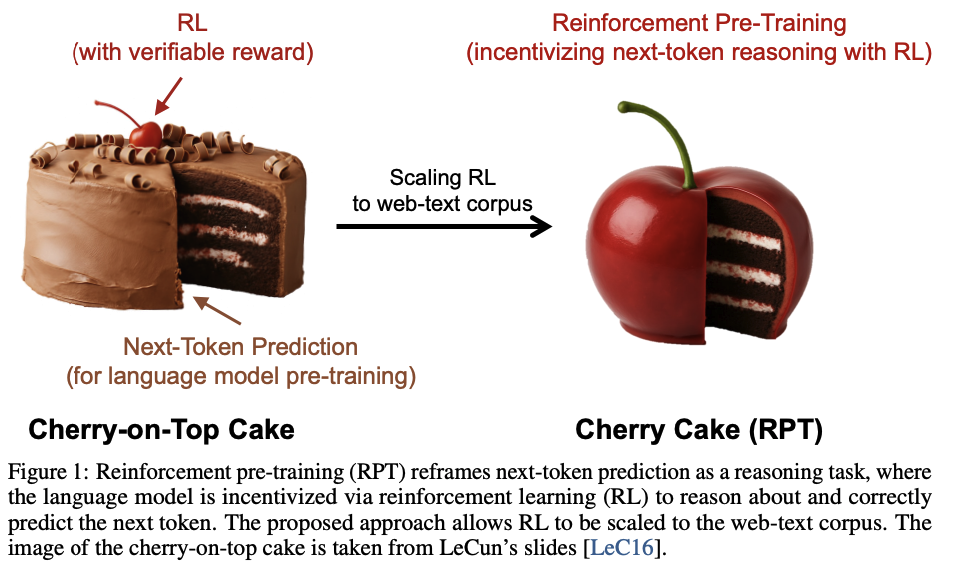
强化预训练的示意图。给定一个缺少延续的上下文,大型语言模型(LLM)执行基于策略的展开,生成G条不同的思考轨迹。每条轨迹都包含一个中间推理步骤以及对Next-Token的最终预测。如果预测与真实token匹配,则赋予正奖励;否则,奖励为零。该奖励信号用于更新LLM,鼓励那些能够导致准确延续的轨迹。
-
训练过程:使用OmniMATH数据集进行预训练,该数据集包含4428个竞赛级别的数学问题和解决方案。通过过滤低熵token(即容易预测的token),专注于训练需要更多计算工作来预测的token。
-
强化学习设置:使用Deepseek-R1-Distill-Qwen-14B作为基础模型,采用GRPO算法进行训练。训练过程中,模型生成多个响应(思考轨迹),并通过奖励信号更新模型参数。
-
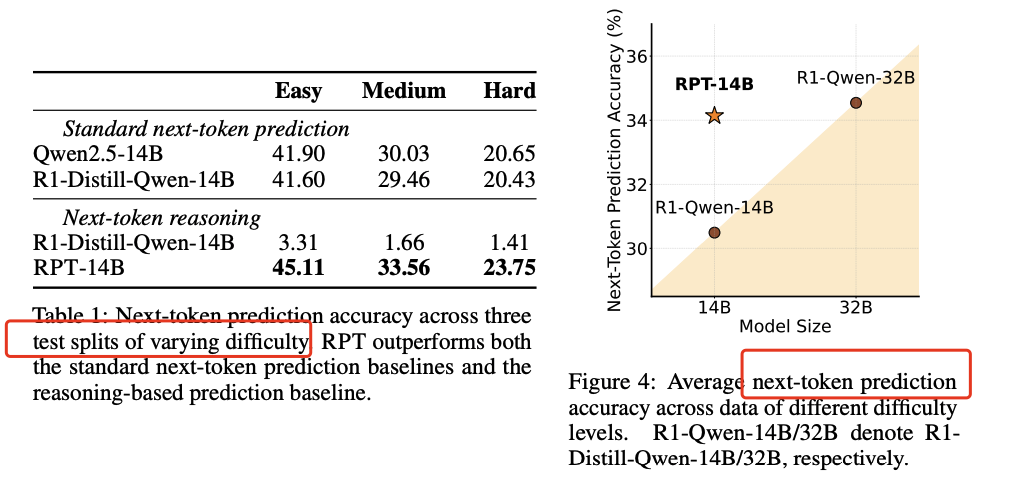
语言建模性能:在OmniMATH验证集上评估RPT模型的Next-Token预测准确性。RPT-14B在所有难度级别上均优于R1-Distill-Qwen-14B,并且与更大的R1-Distill-Qwen-32B模型性能相当。
-
可扩展性分析:研究了RPT在不同训练计算量下的性能变化,发现随着训练计算量的增加,Next-Token预测的准确性一致提高。
-
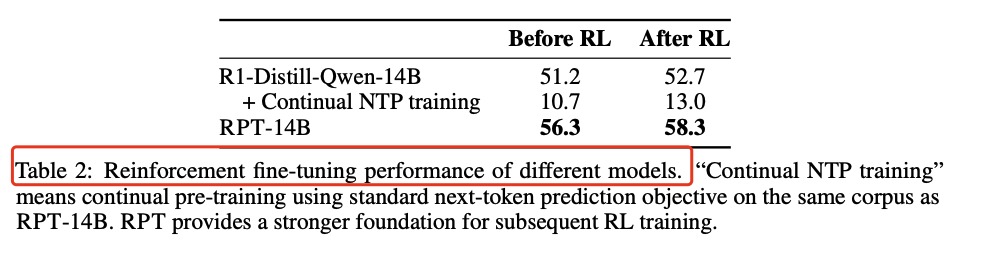
强化微调:在Skywork-OR1数据集上对RPT模型进行进一步的强化学习微调,结果表明RPT模型在微调后性能提升更为显著。
-
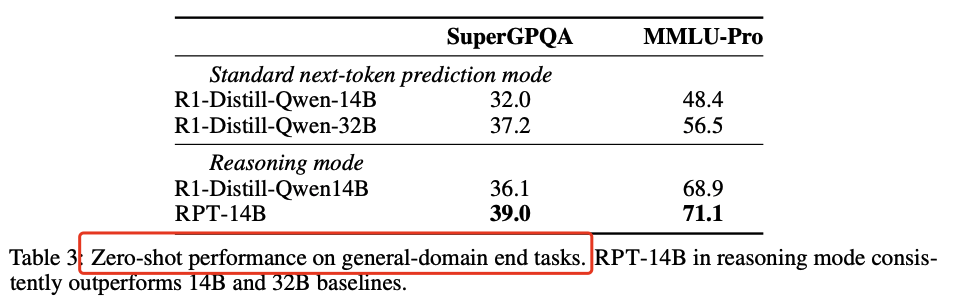
零样本性能:在MMLU-Pro和SuperGPQA两个基准测试中,RPT-14B在零样本设置下表现优于R1-Distill-Qwen-14B和R1-Distill-Qwen-32B。

https://arxiv.org/pdf/2506.08007Reinforcement Pre-Training
(文:PaperAgent)