
今天凌晨,Qwen3 发布。
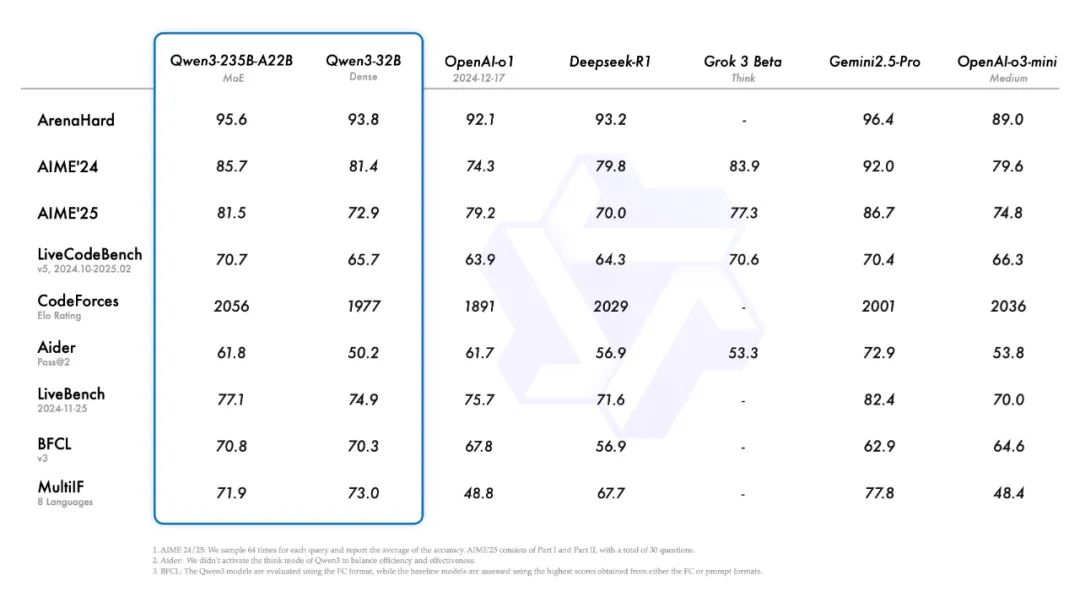
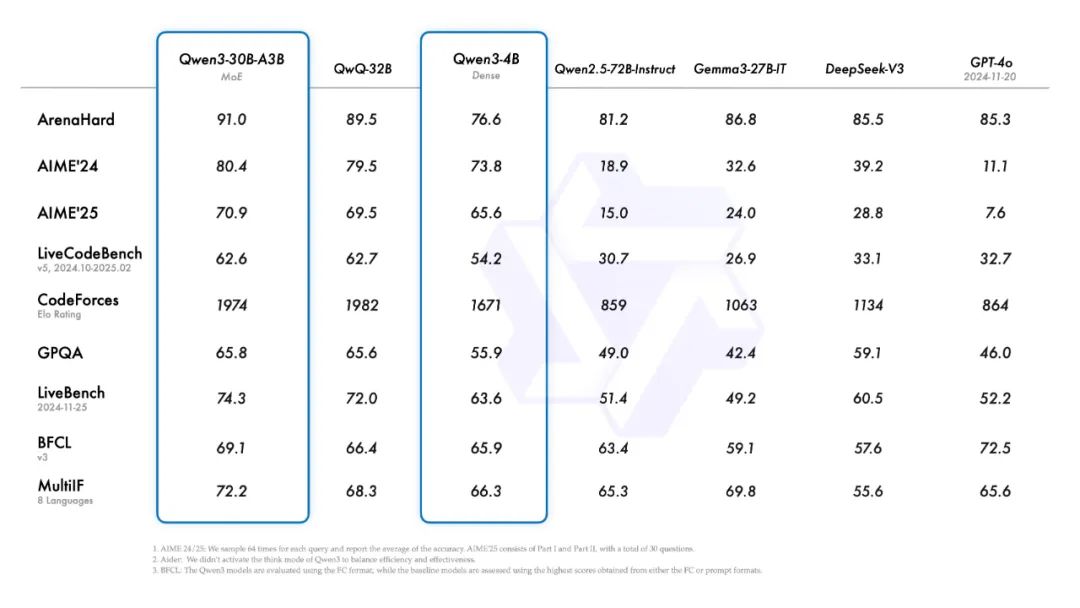
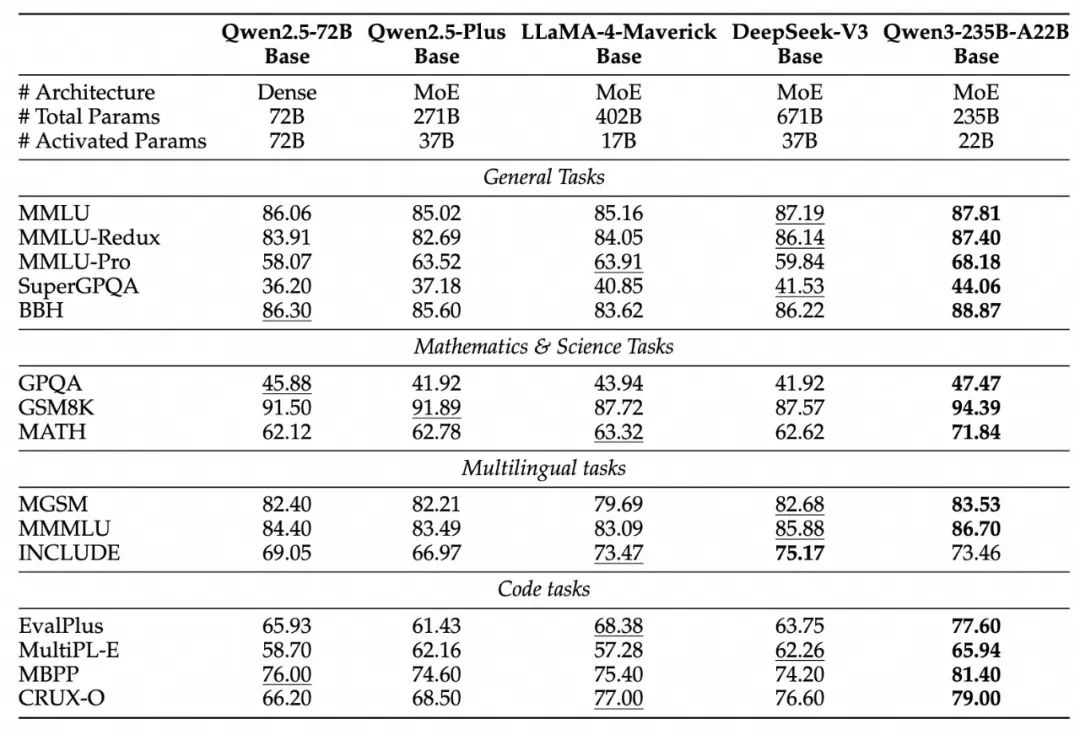
本次共开源 8 款模型,包括 2 款 MoE 模型、6 款 Dense 模型。Qwen3 系列在代码、数学、通用能力等方面能力表现优异,其中 235B 版本,在基准测试上的水平超过了 671B 的 DeepSeek R1。
同时,Qwen3 引入了「思考模式/非思考模式」无缝切换的功能。在思考模式下,模型逐步推理,经过深思熟虑后给出最终答案。非思考模式下,能够提供快速的即时响应,适用于简单问题的回答。混合推理的模式平衡了算力和输出效果。
此外,Qwen3 系列提高了 Agent 能力,同时也加强了对 MCP 的支持。Qwen 配套了一个 Qwen-Agent 项目,可以使用 API 进行工具调用,或结合现有的工具链进行扩展。


-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
本次发布,包含 MoE 和 Dense 两种架构:
-
MoE:有 30B(3B激活)和 235B(22B激活)两种;
-
Dense:包含 0.6B、1.7B、4B、8B、14B 和 32B 六款;
本次发布的旗舰模型是 Qwen3-235B-A22B,后缀 235B 指的是模型大小 235B,A22B 指的是激活参数 22B。
在代码、数学、通用能力等基准测试中,这个 235B 的 Qwen3,水平超过 671B 的 DeepSeek R1。
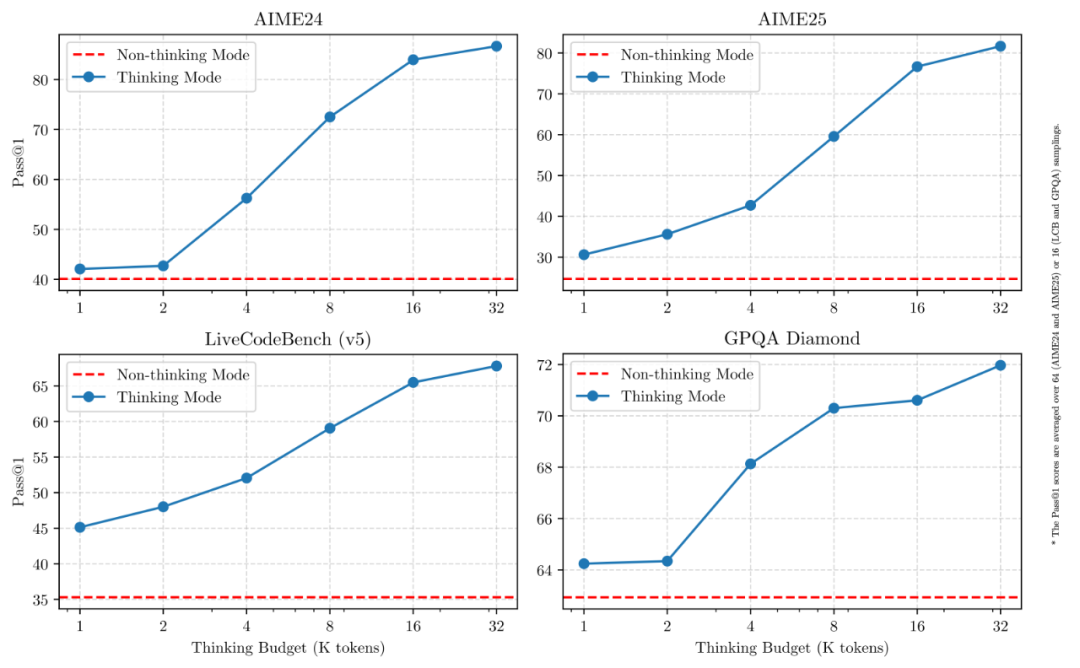
「思考模式」的无缝切换
在我看来,在功能层面,Qwen3 最显著的更新,是引入了「思考模式/非思考模式」的无缝切换。
思考模式的输出方式,类似 DeepSeek R1,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
非思考模式则更类似 DeepSeek V3,提供快速的即时响应,适用于那些简单问题。
通过这种方式,用户能够根据具体需求,来控制模型的“思考”的程度,做到效果、成本、时间上的平衡。
掌握多种语言
Qwen2 支持 29 种语言。

Qwen3 支持了 119 个语种和方言。

更强的 Agent 能力
本次 Qwen3 的更新,还体现在了 Agent 和 代码能力,同时也加强了对 MCP 的支持。
值得一提的是,Qwen 有一个配套的 Qwen-Agent 项目,可以方便地使用 API 进行工具调用,或结合现有的工具链进行扩展。
接下来用两个例子,直观的展示本次 Qwen3 的能力变化。当然了,你也可以访问 Qwen 的网站(https://chat.qwen.ai/),来直接体验。
长/短思考

代码能力
所谓原汤化原食,让他给本文做个可视化,美感还是在线的。
接下来,让我们看看这个模型是怎么训出来的,过程上包括预训练和后训练。
预训练
先做一个基础的了解:
-
Qwen2.5 的训练数据,是在 18 万亿 token
-
Qwen3 的训练数据翻倍:约 36 万亿个 token,涵盖了 119 种语言和方言。
这些数据,一方面是来自于互联网信息的收集,一方面则是通过 Qwen2.5-VL 来从各 PDF 中来提取内容,再通过 Qwen2.5 改进质量。为了补充数学和编程领域的训练数据,Qwen2.5-Math 和 Qwen2.5-Coder 被用来生成合成数据。
在预训练中,有三个阶段:
第一阶段,模型在30万亿tokens的数据上预训练,使用4K的上下文长度,这一阶段主要是帮助模型建立基本的语言技能和常识理解。
第二阶段,增强了STEM领域(科学、技术、工程、数学)和编程任务的训练,增加了5万亿tokens的数据量,进一步提升模型的推理能力。
第三阶段,通过加入高质量的长文本数据,扩展了上下文长度到32K,让Qwen3能够处理更长的输入,例如长篇文章或复杂的对话。
后训练
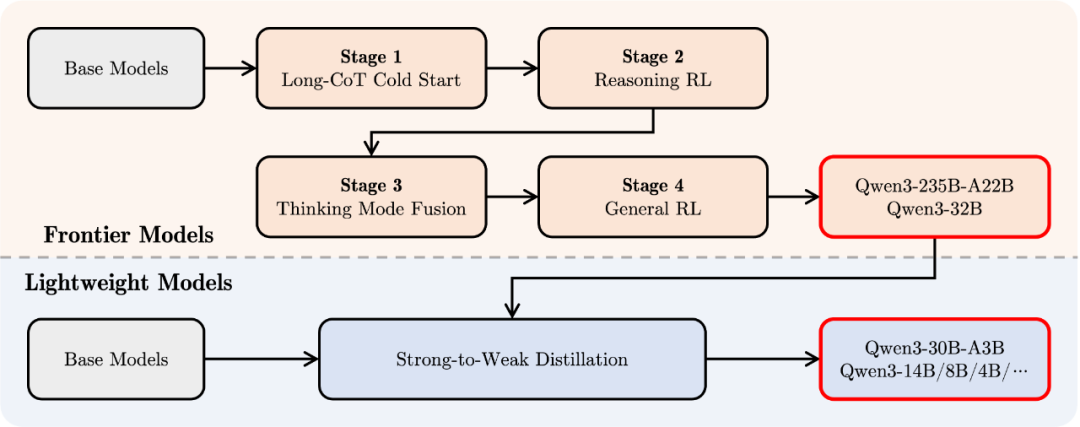
Qwen3的后训练是让模型实现“逐步推理”和“快速响应”的关键。团队通过四个阶段的优化,使得Qwen3不仅在复杂任务中有出色表现,在简单任务中也能快速给出答案。
第一阶段:长链推理冷启动:这一步通过微调多样化的推理数据,让模型具备了处理复杂任务的基本能力,包括数学、编程和逻辑推理等任务。
第二阶段:强化学习(RL):第二阶段利用强化学习进一步提升模型的推理能力,让模型能够在面对复杂任务时更加高效地寻找最佳答案。
第三阶段:思考模式和非思考模式融合:这一创新允许模型在面对不同任务时,灵活切换“思考模式”和“非思考模式”。思考模式下,模型逐步推理,适合复杂问题;而非思考模式下,模型则能快速作出反应,适合日常对话和简单问题。
第四阶段:通用任务强化学习:最后阶段,通过对20多个常见任务的强化学习微调,确保了Qwen3能够在不同应用场景下灵活应对,包括指令跟随、格式化输出和智能代理能力等。
通过这一系列后训练,使得 Qwen3 掌握了思考模式,以及更好的工具调用能力。
Qwen 发展历史回顾
阿里最早推出的AI,叫做通义千问 ,最早出现在 2023年4月。
那时,它还是阿里云的闭源模型,定位类似 ChatGPT,为企业客户提供服务,并不开放源码。
2023年8月初,Qwen 开源

23年8月,阿里开源了两个新模型,Qwen-7B 和 Qwen-7B-Chat,在 ModelScope 和 Hugging Face 同时上线,以 Apache 2.0 的方式开源,Tech Report 也一并放出。
这一次,也是“Qwen”这一名称首次被启用,主要面向开源社区,追求开源可用性、轻量部署、广泛适配;
2023年9月底,Qwen-14B 发布

相比 Qwen-7B,Qwen-14B 训练量更大,中文能力、代码生成、长文本推理都有明显提升。
同期,阿里开源了 qwen.cpp、Qwen-Agent,工具链和应用框架开始成型。
那段时间,Qwen-7B 的训练也做了补强,tokens 从 2.2T 加到了 2.4T,上下文长度扩展到了 8K。
2023年11月底,Qwen-72B 上线
这是一版旗舰规模的模型,参数量拉到 720亿,预训练数据达到了 3万亿 tokens。
这个版本的 Qwen,原生支持 32K 上下文,在中文推理、复杂数学、多轮对话上的表现明显更稳了。
小型号也同步补了:Qwen-1.8B,面对边缘侧和轻量场景进行适配。
一波下来,Qwen把从1B到72B的参数区间基本打通了。
2024年春节期间,Qwen1.5

大过年的,Qwen1.5 发布,在基础上做了深度优化,主要是底层结构调整、训练对齐增强。
同一阶段,还放出了第一版 MoE 架构的 Qwen1.5-MoE-A2.7B,推理成本压下来了,但推理链条拉得更长。
24年6月初,Qwen2
Qwen2 算是换了新的底盘: 预训练数据量大幅扩张,推理能力、代码生成、长文本处理全部提升。
首批放出了 7B、32B、72B 三个尺寸,全覆盖了中大型场景。
2024年9月中,Qwen2.5 接棒

新加了3B、14B、32B三个尺寸,适配更多硬件资源。
同步发了 MoE版,优化了推理稀疏度,同时放出了 Qwen2.5-Omni,一个能统一文本、图像、音频、视频处理的多模态模型。
那时候,Qwen2.5-7B 和 Omni-7B 在 Hugging Face 开源榜单上连续多周霸榜。
2025年4月底,Qwen3 到来

这一次,Qwen3 系列从 Dense 和 MoE 两条线同步推进,从 0.6B 覆盖到了 235B。
训练过程中,第一次引入了 渐进式长文本预训练 和 长文本后训练,超长文本处理做了系统级的优化。
推理任务上,模型内部支持了 思考模式 / 非思考模式 的无缝切换,单个模型内可以根据复杂度自动适配推理链路。
同时的,这个版本的模型,对外部工具的调用能力得到加强,为接下来的 Agent 大战做足准备。
(文:Founder Park)