
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
其实……不用大段大段思考,推理模型也能有效推理!
是不是有点反常识?因为大家的一贯印象里,推理模型之所以能力强大、能给出准确的有效答案,靠的就是长篇累牍的推理过程。
这个过程往往用时很长,等同于需要消耗大量算力。已经有一些研究尝试提高推理效率,但大多仍依赖显式思考过程。
来自UC伯克利和艾伦实验室团队的最新研究结果打破了这一刻板印象——
通过简单的prompt绕过「思考」这一过程直接生成解决方案,可能同样有效,甚至更好。
这种方法被称为“无思考(NoThinking)”方法。

实验数据显示,在低资源情况(即少token数量、少模型参数)或低延迟情况下,Nothinking方法得出的结果均优于Thinking方法的结果,实现比传统思考方式更好的精度- 延迟权衡。
其他情况下,NoThinking方法在部分数据集上的表现也能超越Thinking。
「思考」和「无思考」
研究团队以DeepSeek-R1-Distill-Qwen模型为基础,提出了NoThinking方法。
咱们先来分辨一下Thinking和NoThinking的区别在哪里。
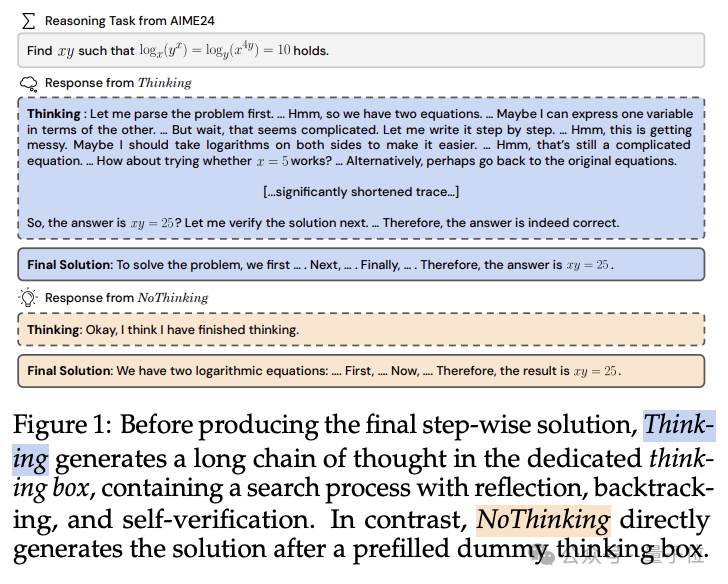
Thinking方法是传统推理模型所采用的方法,模型先生成一个长的思考过程(Thinking),包含反思、回溯和自我验证等步骤,然后再生成最终解决方案(Final Solution)。
好比你随意丢给模型一个问题,模型可能会先尝试理解问题、分解问题、探索可能的解法,然后逐步验证每个步骤的正确性,最后得出答案。

而研究人员最新提出的NoThinking方法,则通过简单的prompt直接让模型跳过显式的思考过程。
也就是在prompt中预先填充一个空的思考块,如在问题提示后直接添加“<|beginning of thinking|>Okay, I think I have finished thinking.<|end of thinking|>”,然后让模型直接从这个空思考块开始生成最终解决方案。
例如,在问题提示后直接添加一个表示思考结束的标记,然后让模型生成答案。

截至目前,Thinking是大多数推理模型默认的推理方式。
但NoThinking团队十分质疑这个过程的必要性👀
所以团队成员以DeepSeek-R1-Distill-Qwen模型为基础——选择这个模型,是因为它是当前最先进的推理模型之一——设计了无思考(NoThinking)方法。
在NoThinking中,模型的推理过程直接从预填充的思考块开始,跳过了生成详细思考步骤的阶段,直接进入解决方案的生成。
这意味着模型不需要花费时间来构建和输出思考过程,从而减少了生成的token数量,提高了推理速度。
低资源情况下,NoThinking表现优于Thinking
研究人员将NoThinking与Thinking方法在相同的模型和数据集上进行对比实验。
试图通过控制token数量、模型参数等变量,比较两种方法在不同任务上的准确性和效率差异。
他们选用了多个推理数据集来评估模型性能,这些数据集涵盖了不同的推理任务类型和难度级别,能够全面评估模型的推理能力:
包括数学问题解决(如AIME、AMC)、编程(LiveCodeBench)和形式定理证明(MiniF2F、ProofNet)等。
评估指标方面,则主要使用pass@k指标来衡量模型性能。pass@k表示的是“在生成的k个样本中至少有一个正确答案的概率”。
此外,实验过程还关注了token使用量和延迟等指标,以评估模型在资源消耗和响应速度方面的表现。
最后的实验结果怎么样?
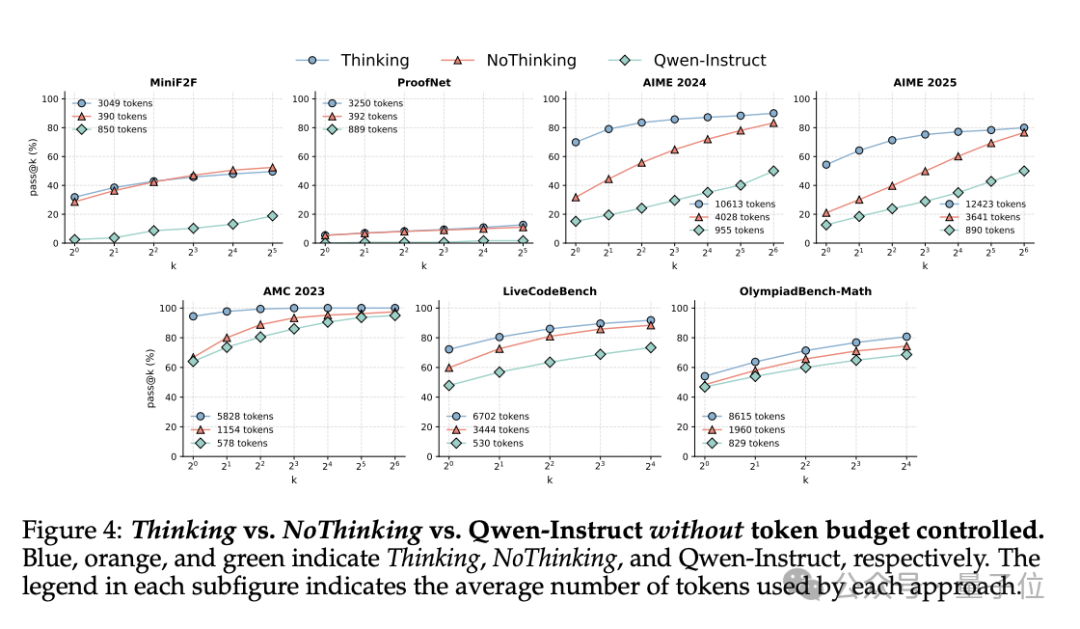
综合表现如图所示,这是无token预算下的最终结果:
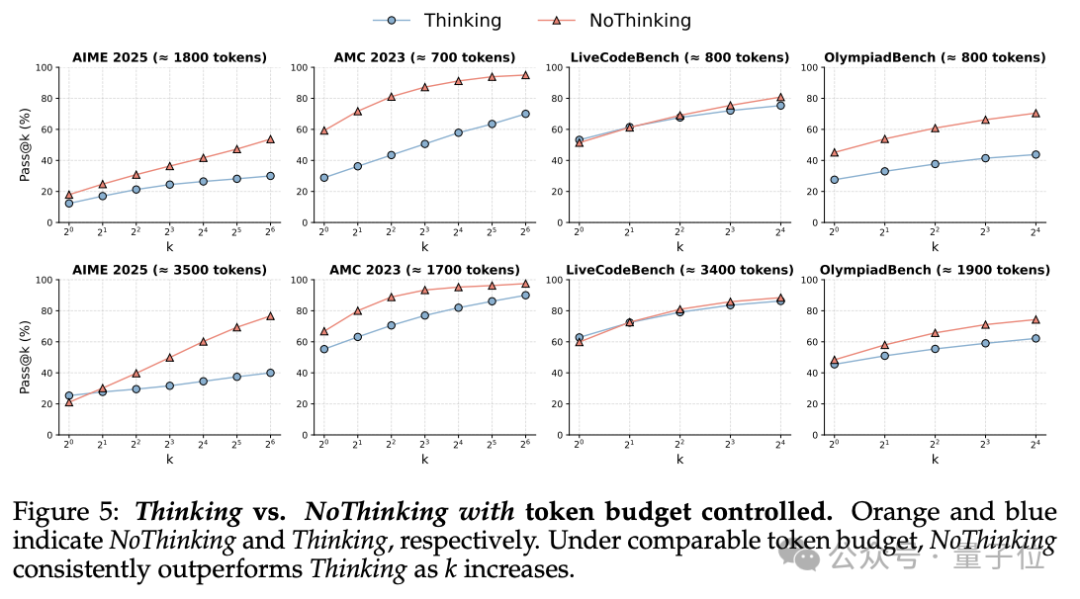
这是有token预算下的最终结果:
数学问题解决
相同token预算下,在AIME和AMC等数学问题数据集上,NoThinking通常比Thinking表现更好。
例如,在ACM23数据集上,当token数量限制为700时,NoThinking的准确率是51.3%,显著高于Thinking的28.9%。
这表明在数学推理任务中,直接生成解决方案可能比详细思考更有效(尤其是在资源受限的情况下)。
形式定理证明
在MiniF2F和ProofNet数据集上,NoThinking在pass@k指标上与Thinking相当,但使用的token数量显著减少(3.3–3.7倍)。
这表明在需要严格逻辑推理的任务中,即使没有显式的思考过程,NoThinking也能保持高准确性,同时显著降低计算成本。
编程任务
在LiveCodeBench数据集上:
-
在低token预算下,NoThinking表现优于Thinking -
在高token预算下,Thinking有时表现更好
这表明在编程任务中,思考过程可能在资源充足时提供一定优势;但资源受限时,NoThinking的效率更高。
NoThinking的pass@k性能
随着k值(生成的样本数量)增加,NoThinking的pass@k性能通常会超过Thinking。
这表明NoThinking生成的解决方案多样性更高,能够通过多次采样提高准确性。
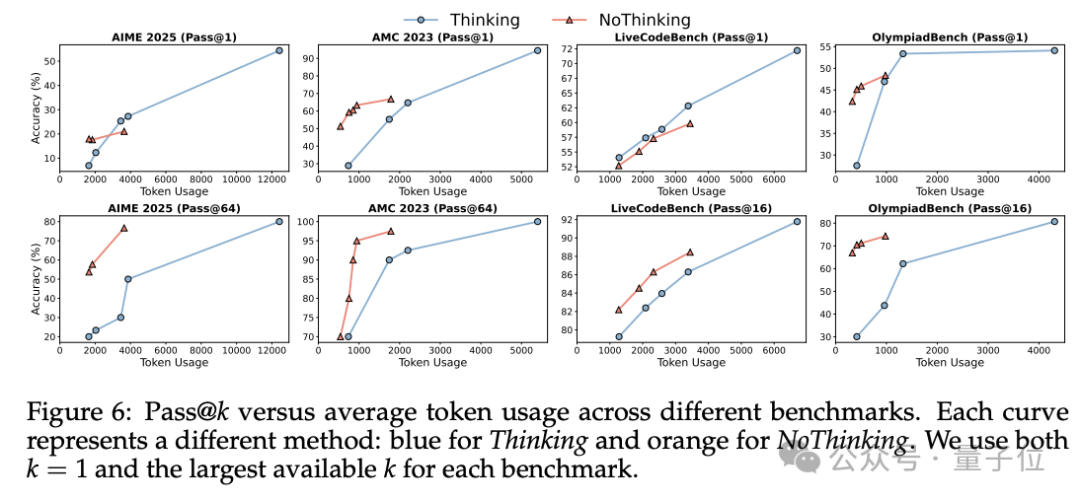
一个典型的例子体现在AIME24数据集上——
当k=64时,NoThinking在相同token预算下的pass@64准确率显著高于Thinking。
这表明NoThinking在多次尝试中更有可能找到正确答案。
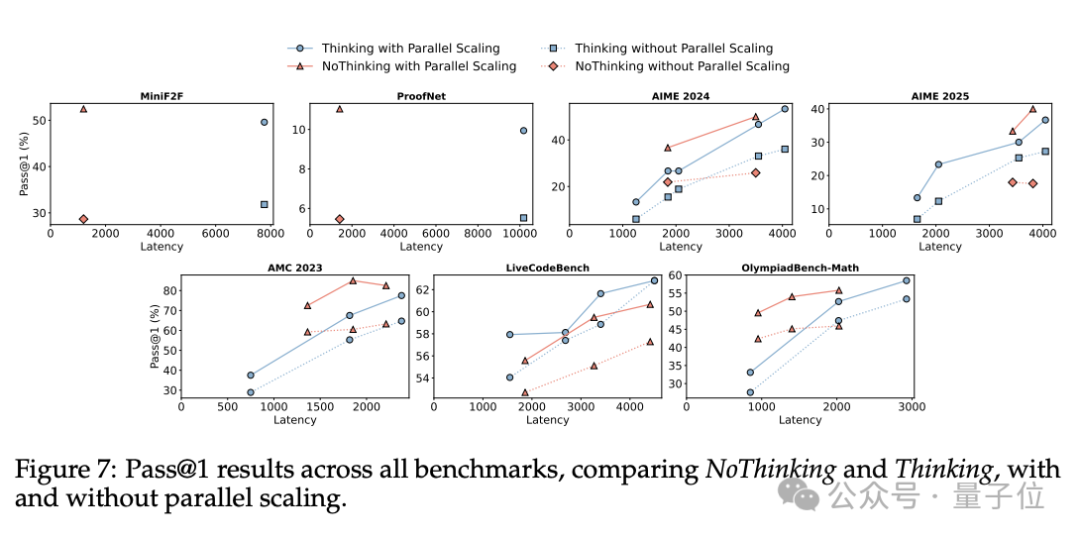
并行扩展实验
实验过程中,团队进一步探索了NoThinking与并行计算扩展结合的潜力。
通过同时生成多个输出并进行聚合(如最佳选择策略),评估这种方法在提高性能和降低延迟方面的效果。
实验结果表明,在结合并行扩展时,NoThinking表现出了显著的性能提升。
对于有Verifier的任务(如MiniF2F和ProofNet),NoThinking结合并行扩展可以实现与Thinking相当甚至更高的准确率,同时将延迟降低7倍,token使用量减少4倍。
在没有Verifier的任务中(如数学问题和编程),使用置信度选择策略的NoThinking也能在低延迟下实现与Thinking相当或更好的准确率。
例如,在AMC2023数据集上,NoThinking在并行扩展下比Thinking快9倍,同时准确率更高。
总体而言,通过同时生成多个输出并选择最佳答案,NoThinking在延迟和token使用量上都优于Thinking。
推理模型依赖于思考过程是“非必要的”
综上所述不难发现,虽然不同任务类型对“NoThinking”和“Thinking”的要求不同,但在低token预算和低延迟情况下,NoThinking表现优于Thinking,并且在并行扩展中展现出更高的效率。
NoThinking方法在多个推理任务中表现出了令人惊讶的有效性表示:
即使跳过了显式的思考过程,模型依然能够生成准确的解决方案。
NoThinking方法证明了“推理模型依赖于思考过程”的非必要性。换句话说,可能存在更高效的方式来实现强大的推理性能,而不依赖于冗长的思考过程。
这与目前普遍认为推理模型需要详细思考过程才能有效工作的观点相悖。
面对这个结果,不少吃瓜群众表达了自己的看法。
有赞成者,比如ExtensityAI的联合创始人兼CTO就表示,这一点也不令人意外。
考虑到蒸馏过程,这个结果并不奇怪——学生可以在微调过程中内化老师的推理,并在推理时提供一条“捷径”。

但也有人表示NoThinking看似可以省略推理过程,但其实要耗费大量人工时间来实现:
结果虽如此,但实际操作里到底有谁会耐心从k个答案里去挑选最佳的那个啊??

不管怎么说,Nothinking还是带给大家一个新视角,往后推理模型的优化,可以朝更简单有效的方向尝试看看。
或许有一天,大家在等推理模型吐精准答案的时候,也不用焦虑地等待那么久了~
(文:量子位)