
✨ 主要特点
📝 Markdown 生成与优化
-
清洁的 Markdown:生成结构化良好的 Markdown,准确保留网页的层级和格式,适合直接用于 LLM 训练或 RAG 任务。
-
Fit Markdown:通过启发式算法过滤噪音内容,保留核心信息,使得生成的 Markdown 更加精炼,便于 AI 模型处理。
-
引用与参考文献:自动将页面中的链接转换为编号引用列表,生成清晰的引用格式,方便内容追溯。
-
自定义策略:用户可以根据特定需求,创建自定义的 Markdown 生成策略,提升灵活性。
-
BM25 算法:采用 BM25 算法进行内容过滤,提取核心信息,剔除无关内容,提高数据质量。
📊 结构化数据提取
-
LLM 驱动的提取:支持与各种 LLM(如 OpenAI、Claude、DeepSeek 等)集成,进行结构化数据提取,适应复杂网页结构。
-
分块策略:实现基于主题、正则表达式、句子级别的内容分块,针对性地处理特定内容。
-
余弦相似度:基于用户查询,使用余弦相似度找到相关内容块,实现语义提取。
-
CSS 选择器提取:通过 XPath 和 CSS 选择器,快速进行基于模式的数据提取。
-
自定义模式定义:用户可以定义自定义模式,从重复模式中提取结构化的 JSON 数据。
🌐 浏览器集成与控制
-
托管浏览器:使用用户自有的浏览器,完全控制,避免被识别为机器人。
-
远程浏览器控制:连接到 Chrome 开发者工具协议,实现远程、大规模的数据提取。
-
浏览器配置文件:创建和管理持久的配置文件,保存身份验证状态、Cookie 和设置。
-
会话管理:保留浏览器状态,在多步骤爬取中复用,提高效率。
-
代理支持:无缝连接到带有身份验证的代理,确保安全访问。
-
完整的浏览器控制:修改请求头、Cookie、用户代理等,定制爬取设置。
-
多浏览器支持:兼容 Chromium、Firefox 和 WebKit。
-
动态视口调整:自动调整浏览器视口以匹配页面内容,确保完整渲染和捕获所有元素。
🔎 爬取与抓取功能
-
媒体支持:提取图像、音频、视频以及响应式图像格式,如 srcset 和 picture。
-
动态爬取:执行 JavaScript,并等待异步或同步内容加载,实现动态内容提取。
-
截图功能:在爬取过程中捕获页面截图,用于调试或分析。
-
原始数据爬取:直接处理原始 HTML(raw:)或本地文件(file://)。
-
全面的链接提取:提取内部、外部链接以及嵌入的 iframe 内容。
-
可定制的钩子:在每个步骤中定义钩子,定制爬取行为。
-
缓存机制:缓存数据,提高速度,避免重复获取。
-
元数据提取:从网页中提取结构化的元数据。
-
iframe 内容提取:无缝提取嵌入的 iframe 内容。
-
懒加载处理:等待图像完全加载,确保不会因懒加载而遗漏内容。
-
全页扫描:模拟滚动,加载并捕获所有动态内容,适用于无限滚动页面。
🚀 部署与扩展性
-
Docker 化部署:提供优化的 Docker 镜像,内置 FastAPI 服务器,便于部署。
-
安全认证:内置 JWT 令牌认证,确保 API 安全。
-
API 网关:一键部署,支持安全令牌认证的 API 工作流。
-
可扩展架构:为大规模生产设计,优化服务器性能。
-
云部署:为主要云平台提供可部署的配置。
🎯 其他功能
-
隐身模式:通过模拟真实用户,避免被识别为机器人。
-
基于标签的内容提取:根据自定义标签、标题或元数据,精细化爬取。
-
链接分析:提取并分析所有链接,进行详细的数据探索。
-
错误处理:强大的错误管理,确保顺利执行。
-
CORS 与静态服务:支持基于文件系统的缓存和跨源请求。
-
清晰的文档:提供简化和更新的指南,便于入门和高级使用。
-
社区认可:对贡献者和拉取请求进行致谢,保持透明。
-
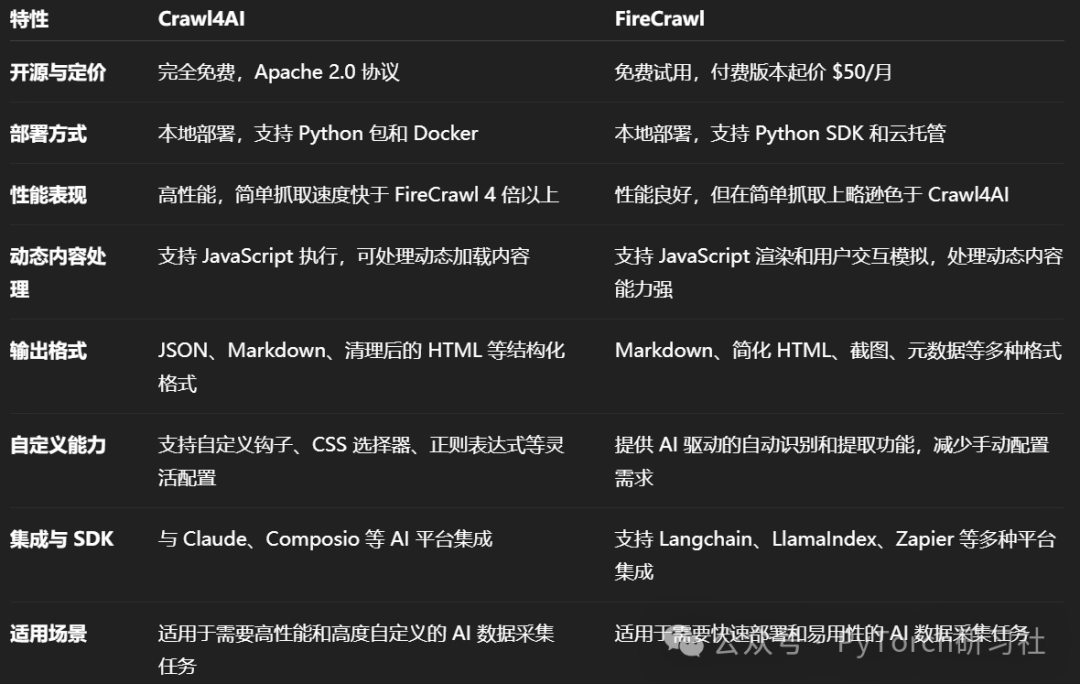
选择 Crawl4AI:如果你需要高性能、可高度自定义的爬虫工具,且具备一定的技术能力,Crawl4AI 是一个理想的选择。
-
选择 FireCrawl:如果你希望快速部署、易于使用的爬虫工具,且对动态内容处理有较高要求,FireCrawl 更适合你。
🔗 资源链接
-
GitHub 仓库:https://github.com/unclecode/crawl4ai
-
官方文档:https://docs.crawl4ai.com
-
社区讨论:https://discord.gg/jP8KfhDhyN
(文:PyTorch研习社)