

大模型独立分析公司Artificial Analysis对Qwen3 在GPQA数据集最新评估来了!
GPQA – 全称: Graduate-Level Google-Proof Q&A (研究生水平、防谷歌搜索问答)
核心目标: 评估大型语言模型(LLMs)是否真正具备专家级别的知识理解和复杂的推理能力,而不仅仅是信息检索或模式匹配。它旨在衡量模型能否像一个领域专家那样思考和解决问题
GPQA Diamond 是从高难度 GPQA 基准测试中精选出的、难度最高的一部分问题,专门用于在需要专家级知识和复杂推理的极限挑战场景下,严格区分和衡量顶尖 AI 模型的真实能力上限
初步结果如下:
Qwen3:开源权重与效率的双重胜利
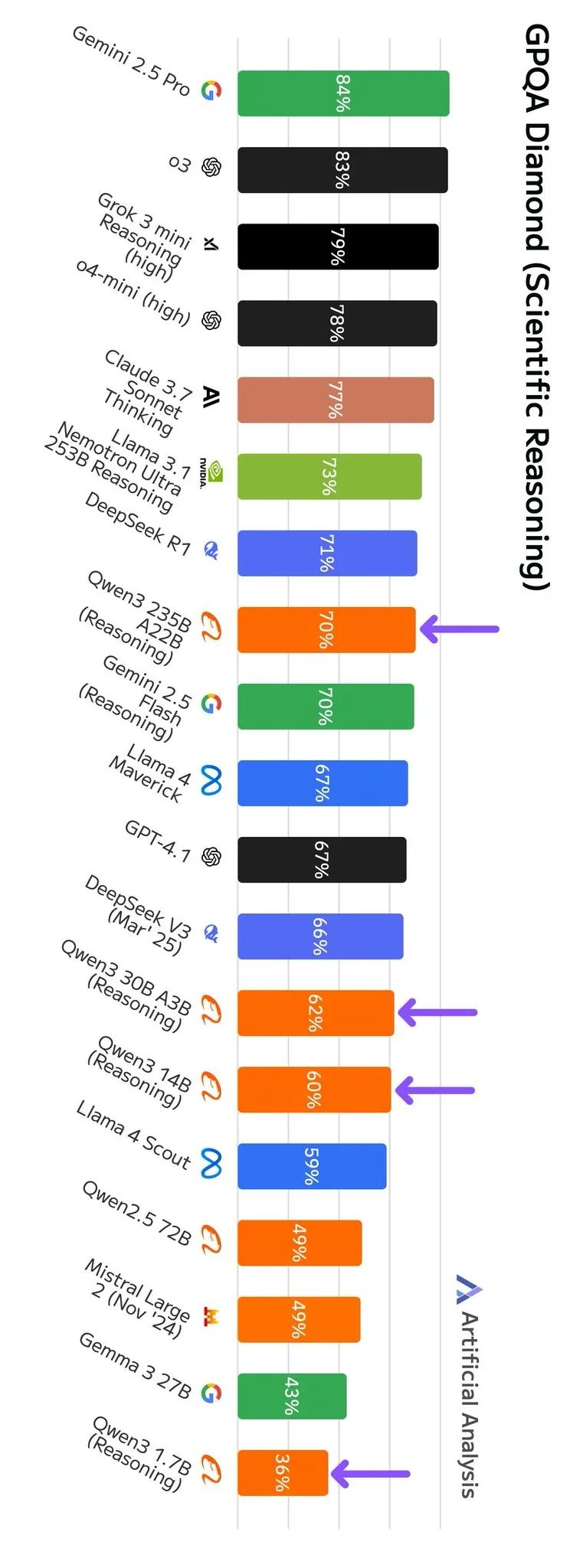
Qwen3 系列混合推理模型是一次重要的发布。这些模型仅用约 DeepSeek R1 三分之一的总参数量,其 GPQA 得分便能接近后者,同时还提供了一系列适用于计算资源受限环境的小型模型。
阿里发布了八款不同规模和架构的混合推理模型。这些模型的一大特点是可以在回答前选择性地开启“思考”模式。模型参数规模覆盖范围广泛,从 0.6B(十亿)参数的密集模型,一直到拥有 235B 总参数和 22B 激活参数的 MoE(混合专家)模型。
初步评估结果显示,所有 Qwen3 模型在其各自的参数规模级别上都展现出强大的竞争力。特别值得一提的是,235B-A22B 版本虽然参数量显著少于 DeepSeek R1(后者总参数 671B,激活参数 37B),但其性能表现已十分接近
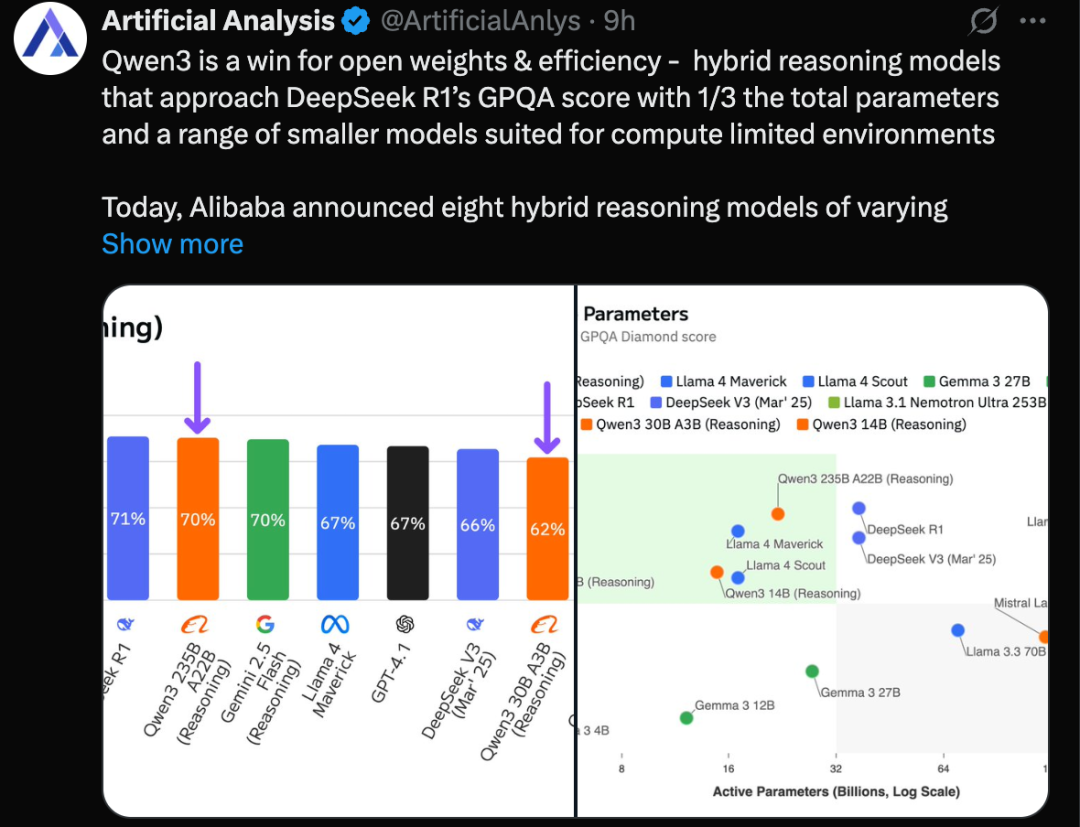
Artificial Analysis已经启动了评估流程,并完成了对以下三款模型在开启推理(Reasoning)模式下的 GPQA Diamond 基准测试:
➤ Qwen3 235B-A22B (推理模式):得分 70%,与 DeepSeek R1 和 Gemini 2.5 Flash (推理模式) 的表现相当。相比阿里此前表现最好的模型 Qwen1.5-32B(在我们 GPQA Diamond 评估中得分 59%),这是一个显著的飞跃
➤ Qwen3 30B-A3B (推理模式):得分 62%,表现紧随顶尖的非推理模型 DeepSeek V3 0324 和 Llama 4 Maverick 之后。考虑到这款模型仅有 3B 激活参数,其表现非常亮眼——作为对比,同类竞品模型的规模要大得多(DeepSeek V3 03-24 总参数 671B,激活参数 37B;Llama 4 Maverick 总参数 402B,激活参数 17B)。Qwen3-32B 密集模型也将很快发布
➤ Qwen3-14B (推理模式):得分 60%,表现与 Llama 4 Scout 相当,但其总参数和激活参数都更少(Qwen3 为 14B/14B,而 Scout 为 109B/17B)
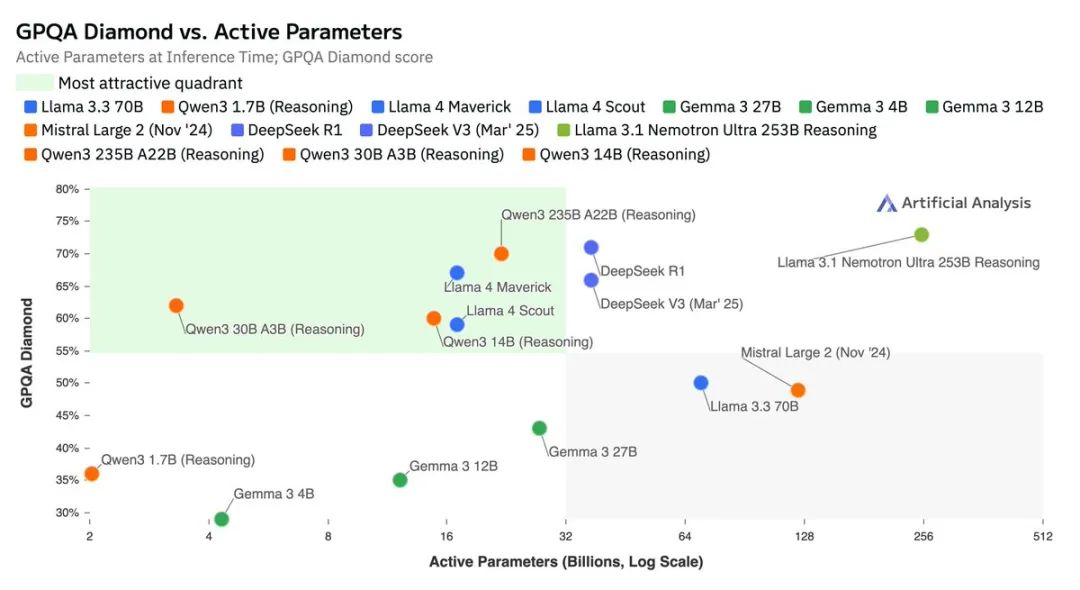
Qwen3 丰富的模型尺寸梯度能够满足从端侧设备(覆盖 8B、4B、1.7B、0.6B 模型)到大型服务器节点(如用于 235B 模型的 8xH100 DGX)的各种部署环境需求。这对开源权重社区而言是又一重大利好
针对 Qwen3 全系列模型(包含开启和关闭推理模式)的 7 项完整评估结果也会很快发布
⭐
(文:AI寒武纪)