
-
从模糊语义匹配到逻辑驱动的目标检索 -
从简单信息聚合到逻辑连贯的上下文构建 -
以及从单一问答到系统性决策支持的转变 -
这种结合能够实现从被动知识工具到主动认知助手的进化,特别适用于深度研究、商业分析、个人助理和城市规划等复杂任务。
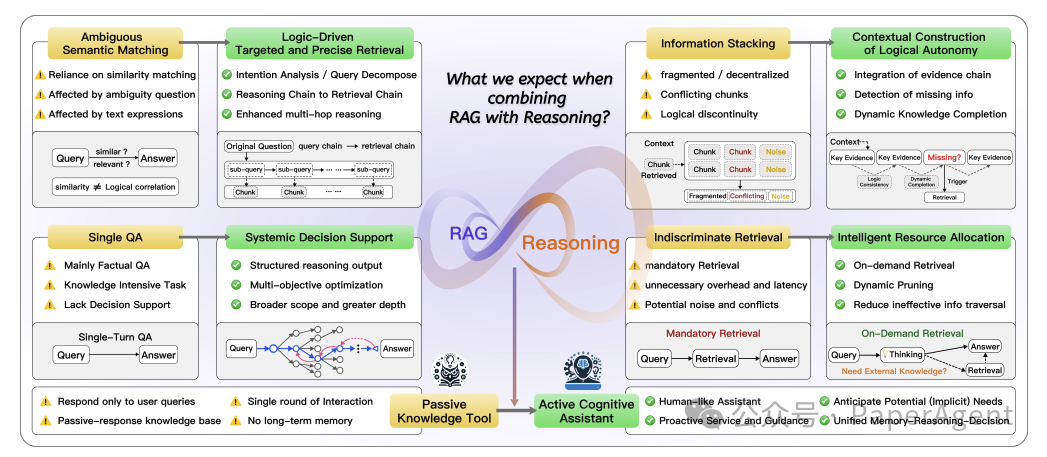
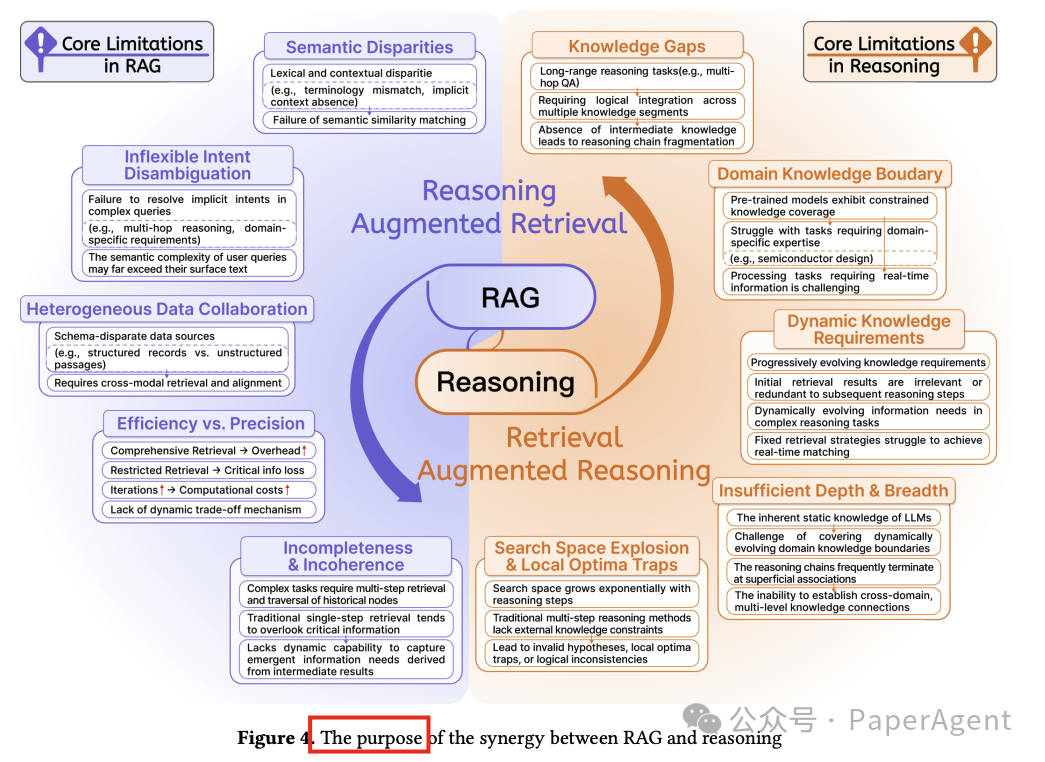
详细讨论了将检索增强型生成(RAG)与推理能力结合的主要动机和好处。这一协同作用的核心优势在于它能够克服RAG和推理过程中的关键限制,通过两种主要方式提升系统性能:
-
推理增强检索(Reasoning-Augmented Retrieval, RAR):这种方法通过多步骤推理动态提升检索质量。与传统的基于静态语义匹配的方法不同,RAR创建了一个模拟人类迭代推理的认知反馈循环,从而超越了简单的“查询-文档”交互限制。RAR的关键特点包括按需检索、通过推断隐含查询逻辑(如业务规则或实体关系)来改善语义对齐,以及应用多步骤迭代细化,使用中间推理输出(例如思维链、部分答案)来递归地重新制定查询。
-
检索增强推理(Retrieval-Augmented Reasoning, ReAR):这种方法结合了外部知识检索和模型内在推理,以克服复杂任务中由于知识缺口或逻辑断裂导致的失败。与一次性检索信息的传统RAG方法不同,ReAR使用迭代的、上下文敏感的检索,不断提供相关数据以支持多步骤推理。这种方法对于需要严格逻辑的任务(如数学证明)至关重要,其中中间步骤需要特定的定理或引理。
通过这种协同作用的两个主要好处:
-
提高检索准确性和灵活性:通过推理增强检索过程。
-
通过使用上下文丰富的检索知识加强复杂推理:补充纯参数LLM推理的局限性。
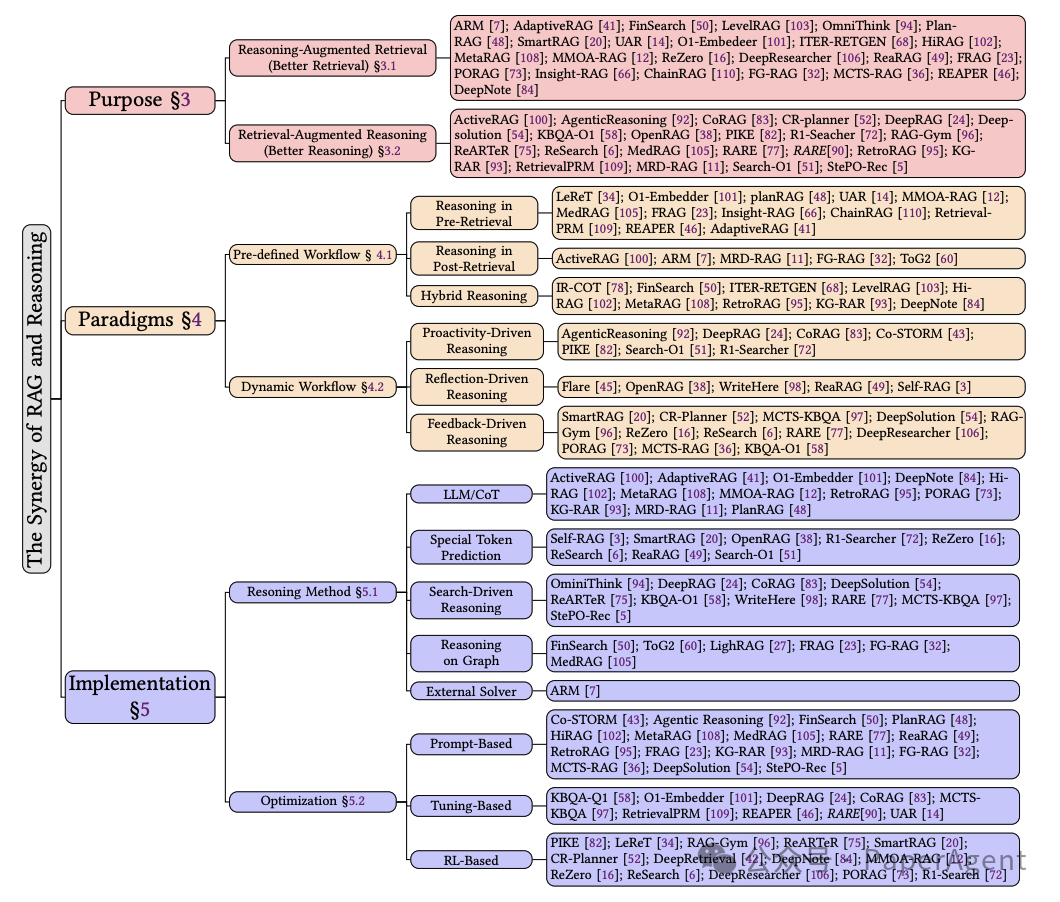
三、RAG与推理协同模式
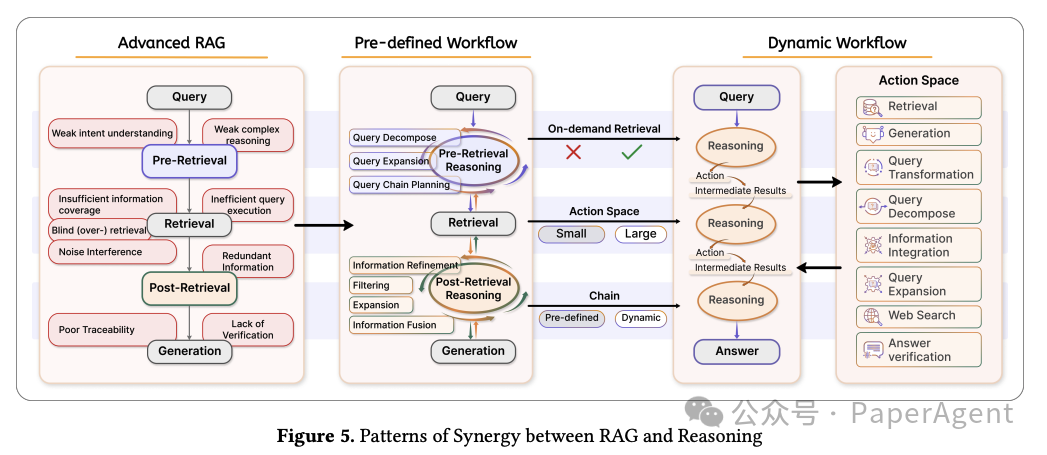
详细介绍了RAG与推理能力结合的两种核心实施模式:预定义工作流(Pre-defined Workflow)和动态工作流(Dynamic Workflow)。这两种模式展示了当前框架如何从确定性和灵活性两个不同角度结合知识检索和多步骤推理。
-
预定义工作流(Pre-defined Workflow)
预定义工作流是一种多步骤推理方法,具有固定架构和顺序执行,强调过程清晰度和操作确定性。它由预定义的迭代阶段组成,每个阶段都有严格的输入输出规则,并且不根据中间结果动态变化。这种模块化设计确保了复杂任务的可控性和结构化推理。所有步骤都执行,无论中间结果如何,保证了可重复性和稳定性,同时避免了动态决策的不确定性。尽管牺牲了适应性,但这种方法提供了过程的可预测性,非常适合需要清晰推理路径的场景,尽管可能存在由于缺乏实时调整而导致的计算冗余。
-
动态工作流(Dynamic Workflow)
动态工作流代表了一种以LLMs(Large Language Models)为中心的自主推理架构,特点是整合了非确定性操作工作流和实时决策能力。与预定义的管道不同,这种架构能够持续监控推理状态,动态触发检索、生成或验证操作。LLM主动评估推理过程中的上下文需求,通过混合反馈协调机制自主确定调用外部工具或资源的最佳时机。通过消除固定迭代单元和预定工具调用序列,该框架实现了执行路径的动态演化,通过基于中间推理结果实时调整计算工作流,展示了在复杂认知任务中的卓越适应性。这种动态架构体现了三个主要特征:1)操作符调用由LLM的上下文状态分析控制;2)推理轨迹表现出高度灵活性,允许动态查询重构和子问题生成;3)上下文驱动的决策机制优先考虑实时推理状态而非预定义规则,增强了系统对新兴任务复杂性的响应性,同时提高了精度。
四、实施与优化策略
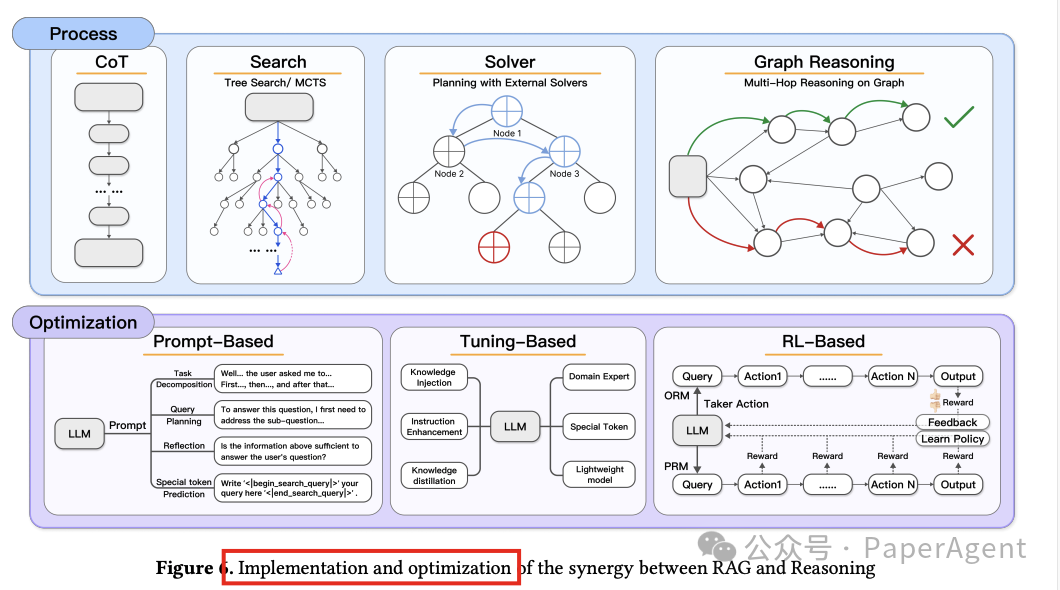
详细探讨了在RAG(Retrieval-Augmented Generation)系统中整合推理能力的具体实施和优化策略:
-
推理过程:
-
LLM CoT:将链式思考(Chain-of-Thought,CoT)推理与大型语言模型(LLMs)结合,以增强RAG系统在复杂推理任务中的表现。
-
特殊标记预测:通过在LLM词汇中嵌入特定领域或动作相关的标记(例如‘[Web-search]’),使模型能够在文本生成过程中自主触发工具或自我反思。
-
搜索驱动推理:采用结构化搜索策略,实现动态信息探索和多步推理。
-
图上推理:通过图结构化推理,为RAG系统中的多跳推理提供新方法。
-
外部求解器:通过整合外部求解器来实现RAG与推理的整合。
-
推理优化:
-
基于提示的优化:使用精心设计的自然语言提示来提高RAG和推理系统的性能,通过提示设计控制推理流程,无需参数微调或强化学习。
-
基于调整的方法:通过优化模型参数来内部化检索增强的链式思考机制,提高模型解决复杂问题的能力。
-
基于强化学习的方法:使用动态奖励机制引导LLMs平衡知识检索和逻辑推理,优化RAG结合推理任务。
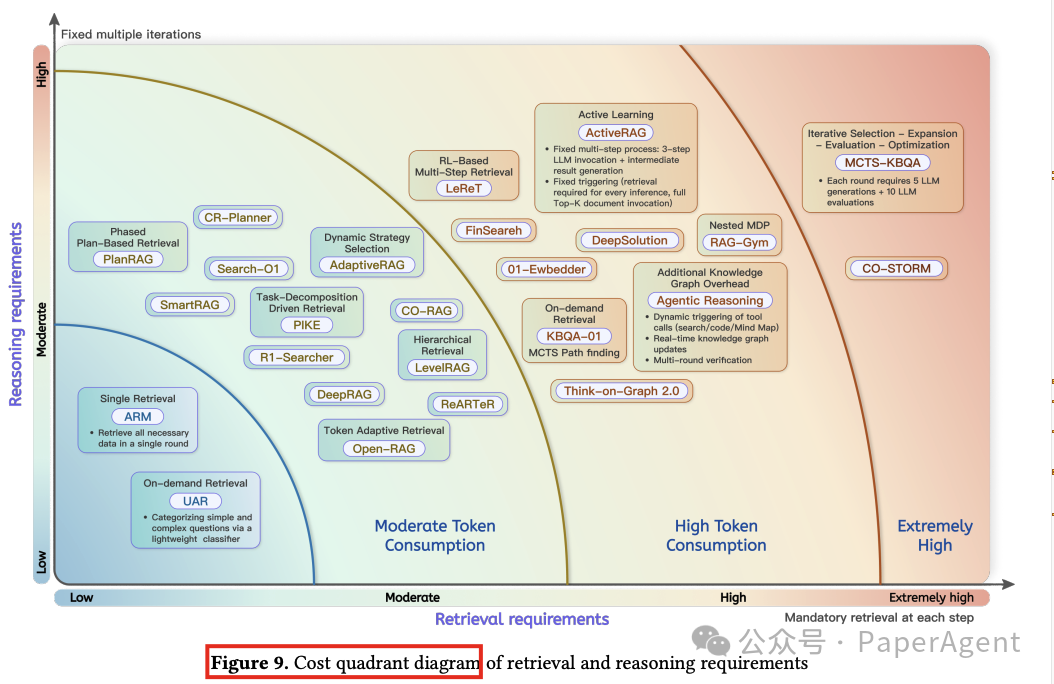
五、成本与风险
探讨了将推理能力整合到RAG(Retrieval-Augmented Generation)系统中所涉及的成本和风险:
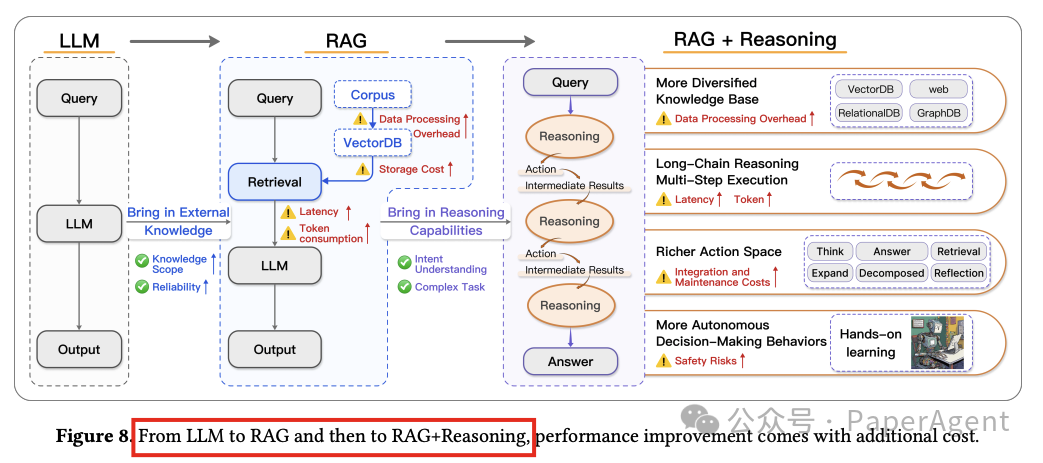
成本权衡
-
计算资源的非线性增长:RAG+Reasoning框架将检索和推理分为多个阶段,导致计算需求非线性增长,特别是在动态链式推理方法中,每次推理需要多次LLM生成和检索,使得复杂度远超基线模型。
-
隐性令牌膨胀:多步骤推理框架通过迭代中间过程(如思维链、检索文档和验证反馈)导致令牌使用显著增加,增加了API成本和内存需求。
-
检索效率的边际下降:动态检索虽然提高了知识精度,但随着任务复杂性的增加,效率降低,导致额外开销。
过度思考的潜在风险
-
效率和可靠性降低:过度思考(over-thinking)现象,如冗余推理步骤、对已知结论的过度验证或不必要的广泛检索范围,可能导致计算资源浪费、错误传播和性能下降。
-
实时系统中的决策延迟:在需要快速决策的系统中,过度检索可能延迟关键决策,例如医疗诊断中可能因过度检索而延迟诊断决策。
优化框架
-
限制推理链长度:如ReaRAG框架通过限制推理链长度和引入自我反思机制来减少无效推理分支。
-
两阶段过滤过程:例如,先通过元数据过滤文档,然后验证片段的相关性,减少冗余信息的干扰。
-
强化学习与蒸馏:DeepSeek R1模型利用强化学习加蒸馏,通过奖励函数动态惩罚冗余步骤,减少数学证明任务中相同公式的重复验证。
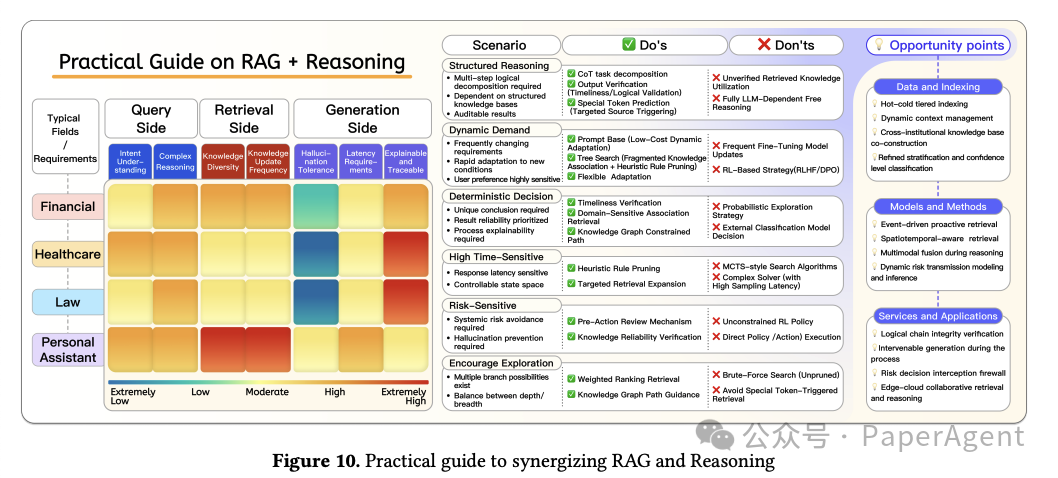
提供了将RAG和推理能力结合的实用指导:
-
领域特征(Domain characteristics):
-
根据RAG的三个核心阶段(查询、检索和生成)系统地分析不同行业的挑战和适应性需求。
-
强调了在理解查询意图、处理多样化和动态知识源以及生成高质量输出时保持原始语义的重要性。
-
实施原则(Do’s and Don’ts):
-
针对六种常见场景,提出了技术适应原则,包括结构化推理、动态需求响应、确定性决策制定、时间敏感、风险敏感和复杂路径探索场景。
-
强调了在设计RAG和推理系统时应遵循的关键优化策略(Do’s)和应避免的禁忌(Don’ts)。
-
机会点(Opportunity Points):
-
基于当前技术的Do’s和Don’ts,讨论了在数据和索引、模型和方法论以及应用服务三个维度中尚未完全探索的多个有潜力的方向。
-
包括冷热分层索引和动态上下文管理、跨机构知识库构建、细粒度分层和置信度分级、事件驱动的主动检索、时空感知检索和关联以及多模态融合在检索和推理中的应用服务。

Synergizing RAG and Reasoning: A Systematic Reviewhttps://arxiv.org/abs/2504.15909
(文:PaperAgent)