
本文来自:https://hebiao064.github.io/fa3-attn-backend-basic ,由 GiantPandaLLM 翻译和Repost。作者是来自Linkedin的 Biaoh He && Qingquan Song .
在 SGLang 中实现 Flash Attention 后端 – 基础和 KV 缓存
0x0. 简介
在过去几周里,我们在 SGLang 中完整实现了 Flash Attention 后端,并且从 SGLang 0.4.6 版本(https://github.com/sgl-project/sglang/releases/tag/v0.4.6)开始,它已经成为默认的 attention 后端。

在整个旅程中,我们学到了很多关于现代 LLM 服务引擎中的 Attention Backend 如何工作,以及对 Flash Attention 本身有了更深入的理解。
在这篇文章中,我们将介绍如何实现一个基本的 Flash Attention 后端,并分享我们希望对任何想要在 LLM 服务引擎中实现自己的 attention 后端的人有所帮助的见解。
系列文章目录
这个系列将分为 3 部分:
-
Part 1: Basics, KV Cache and CUDA Graph Support (this post) -
Part 2: Speculative Decoding Support (coming soon) -
Part 3: MLA, Llama 4, Sliding Window and Multimodal Support (coming soon)
SGLang 中的 Attention Backend 最新状态
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Benchmark Results

基准测试结果表明,FA3 在所有测试场景中都表现出最高的吞吐量,尤其是在输入或输出大小增加时,明显优于 FlashInfer 和 Triton。
我们遵循了与这个评论(https://github.com/sgl-project/sglang/issues/5514#issuecomment-2814763352)中使用的相同基准测试设置。详细的基准测试结果可以在这个表格(https://docs.google.com/spreadsheets/d/14SjCU5Iphf2EsD4cZJqsYKQn8YbPPt0ZA5viba3gB1Y/edit?gid=0#gid=0)中找到。
0x1. 背景和动机
什么是 Flash Attention?
Flash Attention[^1] 是一种 IO-aware 的精确注意力算法,它使用分块来减少 GPU 高带宽内存 (HBM) 和 GPU 片上 SRAM 之间的高带宽内存 (HBM) 和 GPU 片上 SRAM 之间的内存读写次数。
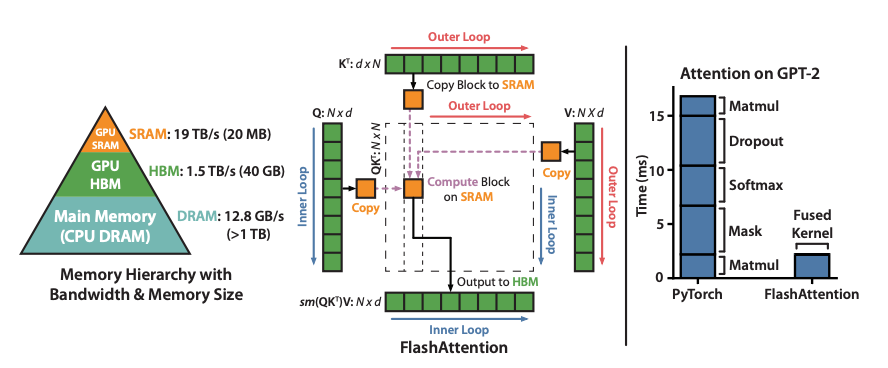
在 LLM 推理和训练中,它已经成为现代服务引擎(如 SGLang、vLLM 等)的默认注意力后端。
在大多数情况下,可以将其视为一个黑盒。然而,通过理解其核心逻辑,我们可以更智能地使用它。
我强烈推荐这篇文章[^2]来理解 Flash Attention 的核心逻辑。我还有一个关于什么是 Flash Attention?的博客(https://hebiao064.github.io/flash-attn) ,在那里我从代码级别给出了一个简短的介绍。
SGLang 中的注意力后端是如何工作的
SGLang 架构
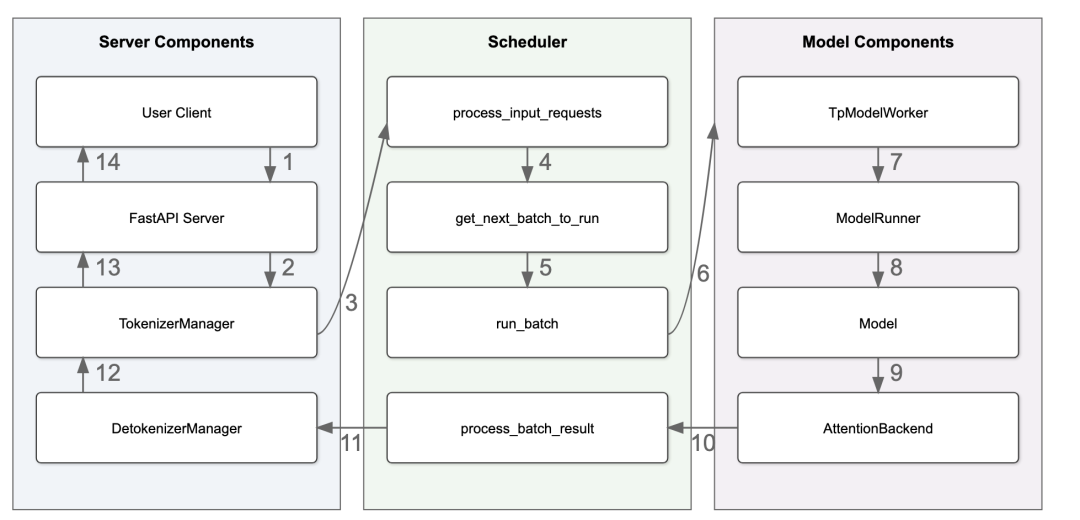
SGLang, 作为一个现代的 LLM 服务引擎,有三个主要的组件(在逻辑视图中)[^3]:
-
Server Components: 负责处理传入的请求并发送响应。 -
Scheduler Components: 负责构建批次并将它们发送给 Worker。 -
Model Components: 负责模型的推理。
让我们关注上图中的模型前向传递。
在第 8 步: ModelRunner 处理 ForwardBatch 并调用 model.forward 执行模型的前向传递。
在第 9 步: model.forward 将调用每个层的 forward 函数,大部分时间花费在自注意力部分。因此,注意力后端成为模型推理的瓶颈。除了性能之外,还有许多不同类型的注意力变体,如 MHA, MLA, GQA, Sliding Window, Local Attention 需要仔细优化的注意力后端实现。
注意力后端继承关系
以下是注意力变体的继承关系:
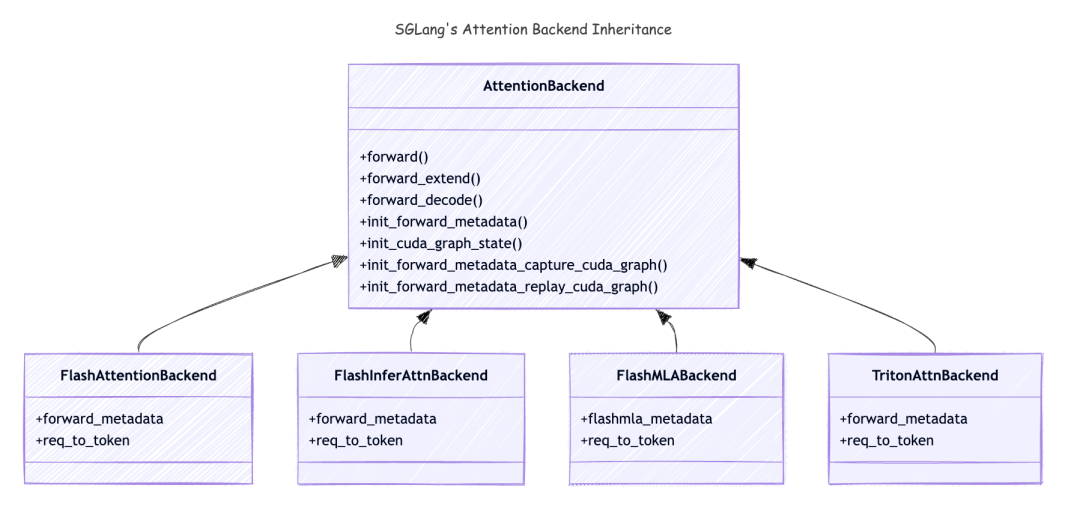
让我们通过 AttentionBackend 类中的方法来看看 SGLang 中的注意力后端是什么:
-
forward(): 当model.forward()被调用时,AttentionBackend中的forward方法将被调用。它将根据forward_batch.forward_mode调用forward_extend()和forward_decode()。在这篇博客中,我们只关注EXTEND和DECODE模式。 -
forward_extend(): 当forward_mode是EXTEND时,此方法将被调用。 -
forward_decode(): 当forward_mode是DECODE时,此方法将被调用。 -
init_cuda_graph_state(): 此方法将在服务器启动期间被调用,它将预分配那些将在 CUDA Graph 重放中使用的张量。 -
init_forward_metadata(): 当model.forward()被调用时,此方法将被调用。它可以在整个model.forward()调用中预计算一些元数据,并被每个 layer 重用,这对于加速模型推理至关重要。有趣的是,这个元数据是注意力后端中最复杂的部分,一旦我们设置好它,在这种情况下的 计算就相当简单了。 -
init_forward_metadata_capture_cuda_graph(): 此方法将在服务器启动期间被调用,CUDAGraphRunner将在 CUDA Graph 捕获期间调用此方法。CUDA Graph 将存储在CUDAGraphRunner的self.graphs对象中。 -
init_forward_metadata_replay_cuda_graph(): 当每个层的forward_decode被调用时,此方法将被调用。它将设置元数据,以确保 CUDA Graph 重放可以正确完成。
到目前为止,我们已经覆盖了注意力后端需要实现的所有方法。我们将在接下来的章节中讨论它。
如何在 SGLang 中使用 KV Cache
你可能很好奇为什么在每个 AttentionBackend 类中都有一个 req_to_token。实际上,KV Cache,作为所有 LLM 服务引擎的支柱,对注意力后端也非常重要,所以让我们简要地了解一下它。
KV Cache 管理有两个层次的内存池[^4]
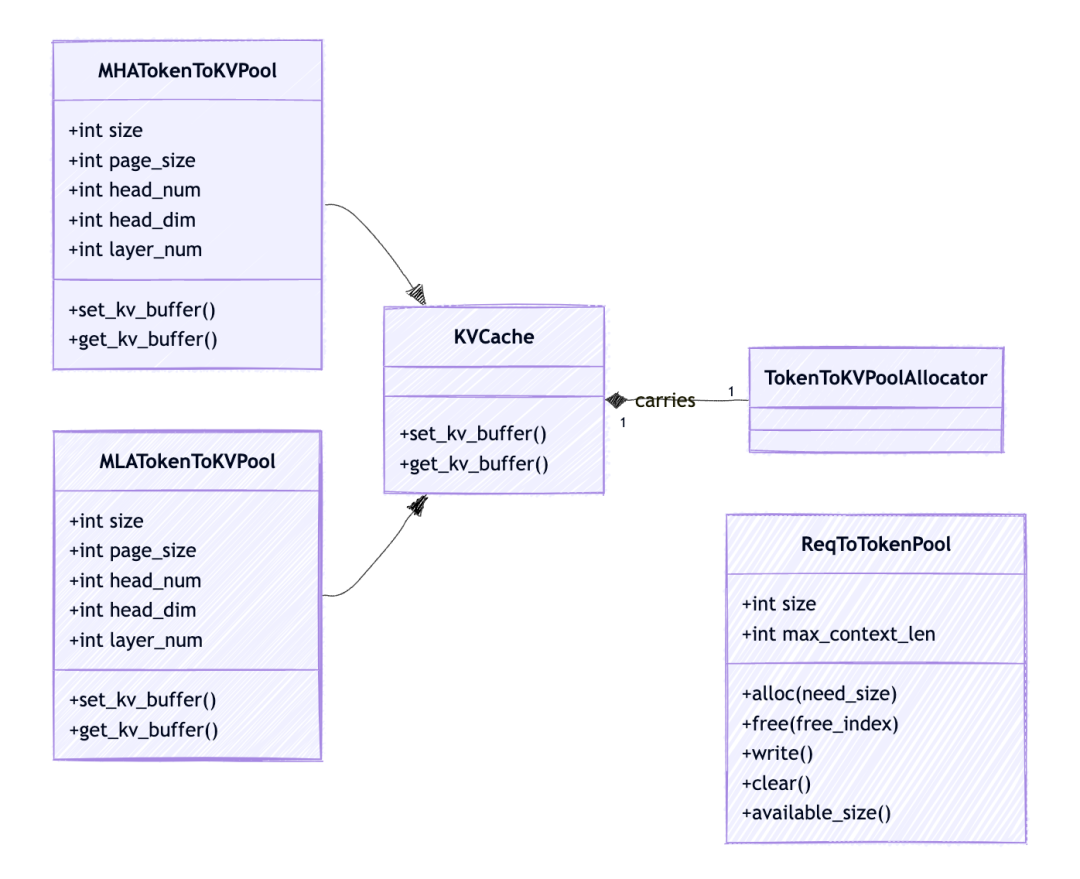
req_to_token_pool
一个从请求到其tokens的 KV 缓存索引的映射。这就是我们在注意力后端图表中提到的 req_to_token。
-
形状: 最大允许请求数(由参数 max-running-requests设置,用于控制可以并发运行的最大请求数) * 每个请求的最大上下文长度(由配置model_config.context_len设置) -
访问: -
维度0: req_pool_indices标识具体的请求 -
维度1: 请求中的 token 位置(从 0, 1, 2… 开始),标识请求中的具体 token -
值: token 的 out_cache_loc,它指向由维度0和维度1标识的 token 相关联的 KV 缓存索引
token_to_cache_pool
req_to_token_pool 维护了请求到 tokens 的 KV 缓存索引的映射,token_to_kv_pool 进一步将 token 从其 KV 缓存索引映射到其真实的 KV 缓存数据。注意,对于不同的注意力实现,如 MHA, MLA, Double Sparsity, token_to_kv_pool 可能会有不同的实现。
-
Layout: 层数 * 最大允许 token 数 * 头数 * 头维度 -
访问: -
维度0: layer_id标识具体的层 -
维度1: out_cache_loc标识具体的 KV 缓存索引(空闲槽) -
维度2: 头数 -
维度3: 头维度 -
值: cache_k和cache_v, 真实的 KV 缓存数据
注意,我们通常一起检索整个层的 KV 缓存,因为我们需要一个请求中的所有先前 token 的 KV 缓存来执行前向传递。
在注意力后端中,我们只需要知道 req_to_token_pool 是什么,其余的 KV 缓存管理对注意力后端是透明的。
让我们给出一个直观的例子,看看 req_to_token_pool 是什么样子的:
-
假设我们有两个请求,每个请求有 7 个 token。 -
然后 req_to_token_pool是一个形状为 (2, 7) 的张量,每个条目将请求中的一个 token 映射到其对应的 KV 缓存索引。
req_to_token_pool = [
[1, 2, 3, 4, 5, 6, 7],
[8, 9, 10, 11, 12, 13, 14]
]
seq_lens 是 [7, 7]。 3. 在执行一次 forward_extend 后,将一个新的 token 添加到每个请求中,req_to_token_pool 将更新为:
req_to_token_pool = [
[1, 2, 3, 4, 5, 6, 7, 15],
[8, 9, 10, 11, 12, 13, 14, 16]
]
seq_lens 是 [8, 8]。 4. 如果第一个请求完成,我们为第二个请求运行另一个 decode,req_to_token_pool 将更新为:
req_to_token_pool = [
[1, 2, 3, 4, 5, 6, 7, 15],
[8, 9, 10, 11, 12, 13, 14, 16, 17]
]
seq_lens 是 [8, 9]。
有了上述关于 KV 缓存结构的知识,我们现在有了实现我们自己的 FlashAttention 后端的基础。下一步是识别 flash_attn_with_kvcache API 的正确参数,以创建一个最小的工作实现。
关于 KV 缓存的更多细节,请参考 Awesome-ML-SYS-Tutorial: KV Cache Code Walkthrough(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/d4d56dc3ab2260a747964ceb18cb1f69d23146ae/sglang/kvcache-code-walk-through/readme.md).
0x2. FlashAttention3 后端基础实现
好了,让我们开始深入 SGLang 中的 FlashAttention 后端实现。
这里是最初的实现: sgl-project/sglang#4680(https://github.com/sgl-project/sglang/pull/4680). 为了简洁起见,我简化了代码,只关注核心逻辑。
Tri Dao’s FlashAttention 3 Kernel API
Tri Dao 提供了几种用于 Flash Attention 3 的公共 API,入口点是 hopper/flash_attn_interface.py(https://github.com/Dao-AILab/flash-attention/blob/main/hopper/flash_attn_interface.py).
我们选择 flash_attn_with_kvcache 有两个主要原因: 它消除了手动组装键值对的开销,因为它直接接受整个页表,并且它提供了对分页 KV 缓存(页大小 > 1)的原生支持,这在 flash_attn_varlen_func 中不可用。
让我们快速看一下 flash_attn_with_kvcache API:
# we omiited some arguments for brevity
def flash_attn_with_kvcache(
q,
k_cache,
v_cache,
cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None,
page_table: Optional[torch.Tensor] = None,
cu_seqlens_q: Optional[torch.Tensor] = None,
cu_seqlens_k_new: Optional[torch.Tensor] = None,
max_seqlen_q: Optional[int] = None,
causal=False,
):
"""
参数:
q: (batch_size, seqlen, nheads, headdim)
k_cache: 如果没有page_table,形状为(batch_size_cache, seqlen_cache, nheads_k, headdim),
如果有page_table(即分页KV缓存),形状为(num_blocks, page_block_size, nheads_k, headdim)
page_block_size必须是256的倍数。
v_cache: 如果没有page_table,形状为(batch_size_cache, seqlen_cache, nheads_k, headdim_v),
如果有page_table(即分页KV缓存),形状为(num_blocks, page_block_size, nheads_k, headdim_v)
cache_seqlens: int,或者(batch_size,),dtype为torch.int32。KV缓存的序列长度。
page_table [可选]: (batch_size, max_num_blocks_per_seq),dtype为torch.int32。
KV缓存的页表。它将从attention后端的req_to_token_pool派生。
cu_seqlens_q: (batch_size,),dtype为torch.int32。查询的累积序列长度。
cu_seqlens_k_new: (batch_size,),dtype为torch.int32。新key/value的累积序列长度。
max_seqlen_q: int。查询的最大序列长度。
causal: bool。是否应用因果注意力掩码(例如,用于自回归建模)。
返回:
out: (batch_size, seqlen, nheads, headdim)。
"""
初始化
有了上述信息,现在任务就变得清晰了,我们只需要弄清楚 flash_attn_with_kvcache API 的那些参数,就可以实现 FlashAttention 后端的最基本功能。
让我们从 FlashAttentionBackend 类和 FlashAttentionMetadata 类的初始化开始。
@dataclass
class FlashAttentionMetadata:
"""元数据将在模型前向过程中创建一次,并在层间前向传播中重复使用。"""
cache_seqlens_int32: torch.Tensor = None# 序列长度,int32类型
max_seq_len_q: int = 0# Query的最大序列长度
max_seq_len_k: int = 0# Key的最大序列长度
cu_seqlens_q: torch.Tensor = None# Query的累积序列长度
cu_seqlens_k: torch.Tensor = None# Key的累积序列长度
page_table: torch.Tensor = None# 页表,指示每个序列的KV缓存索引
class FlashAttentionBackend(AttentionBackend):
"""FlashAttention后端实现。"""
def __init__(
self,
model_runner: ModelRunner,
):
super().__init__()
self.forward_metadata: FlashAttentionMetadata = None# 前向传播的元数据
self.max_context_len = model_runner.model_config.context_len # 模型配置中设置的最大上下文长度
self.device = model_runner.device # 模型所在设备(GPU)
self.decode_cuda_graph_metadata = {} # 用于加速解码过程的元数据
self.req_to_token = model_runner.req_to_token_pool.req_to_token # 从请求到其tokens的KV缓存索引的映射
初始化前向传播Metadata
def init_forward_metadata(self, forward_batch: ForwardBatch):
"""在模型前向过程中初始化前向传播元数据,并在层间前向传播中重复使用
参数:
forward_batch: `ForwardBatch`对象,包含前向批次信息,如forward_mode、batch_size、req_pool_indices、seq_lens、out_cache_loc
"""
# 初始化元数据
metadata = FlashAttentionMetadata()
# 获取批次大小
batch_size = forward_batch.batch_size
# 获取批次中的原始序列长度
seqlens_in_batch = forward_batch.seq_lens
# 获取模型所在设备,例如:cuda
device = seqlens_in_batch.device
# 获取int32类型的序列长度
metadata.cache_seqlens_int32 = seqlens_in_batch.to(torch.int32)
# 获取key的最大序列长度
# 注意我们使用seq_lens_cpu来避免设备同步
# 参见PR: https://github.com/sgl-project/sglang/pull/4745
metadata.max_seq_len_k = forward_batch.seq_lens_cpu.max().item()
# 获取key的累积序列长度
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0)
)
# 获取页表,我们按最大序列长度截断
metadata.page_table = forward_batch.req_to_token_pool.req_to_token[
forward_batch.req_pool_indices, : metadata.max_seq_len_k
]
if forward_batch.forward_mode == ForwardMode.EXTEND:
# 获取int32类型的序列长度
metadata.max_seq_len_q = max(forward_batch.extend_seq_lens_cpu)
metadata.cu_seqlens_q = torch.nn.functional.pad(
torch.cumsum(forward_batch.extend_seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
elif forward_batch.forward_mode == ForwardMode.DECODE:
# 对于解码,查询长度始终为1
metadata.max_seq_len_q = 1
# 获取查询的累积序列长度
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
# 保存元数据,以便forward_extend和forward_decode可以重用
self.forward_metadata = metadata
前向扩展和前向解码
在模型前向过程中,model_runner会调用init_forward_metadata来初始化attention后端的元数据,然后调用实际的forward_extend和forward_decode。因此forward_extend和forward_decode的实现是直接的。
def forward_extend(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
layer: RadixAttention,
forward_batch: ForwardBatch,
save_kv_cache=True,
):
# 从前向批次中获取KV缓存位置
cache_loc = forward_batch.out_cache_loc
# 为新的token保存KV缓存
if save_kv_cache:
forward_batch.token_to_kv_pool.set_kv_buffer(layer, cache_loc, k, v)
# 使用预计算的元数据
metadata = self.forward_metadata
# 获取之前token的KV缓存
key_cache, value_cache = forward_batch.token_to_kv_pool.get_kv_buffer(layer.layer_id)
o = flash_attn_with_kvcache(
q=q.contiguous().view(-1, layer.tp_q_head_num, layer.head_dim),
k_cache=key_cache.unsqueeze(1),
v_cache=value_cache.unsqueeze(1),
page_table=metadata.page_table,
cache_seqlens=metadata.cache_seqlens_int32,
cu_seqlens_q=metadata.cu_seqlens_q,
cu_seqlens_k_new=metadata.cu_seqlens_k,
max_seqlen_q=metadata.max_seq_len_q,
causal=True, # 用于自回归注意力
)
# forward_decode与forward_extend完全相同,我们已经在init_forward_metadata中设置了不同的元数据
到目前为止,我们已经实现了一个最基本的 FlashAttention 后端。我们可以使用这个后端来执行 attention 的前向传递。
0x3. CUDA Graph 支持
什么是 CUDA Graph?
CUDA Graph 是 NVIDIA CUDA 平台的一个功能,它允许你捕获一系列 GPU 操作并将它们作为一个单一的、优化的单元重放。传统上,每个从 CPU 发起的 GPU kernel 启动都会产生一些启动延迟,并且 CPU 必须按顺序协调每个步骤。这种开销可能会变得很大,特别是对于有许多小 kernel 的工作负载。[^5]
使用 CUDA Graph,你可以将一系列操作(如图中的 A、B、C、D、E)记录到一个图中,然后一次性启动整个图。这种方法消除了重复的 CPU 启动开销,并使 GPU 能够更高效地执行操作,从而节省大量时间。下图说明了这个概念:上半部分显示了传统方法,每个 kernel 启动都会产生 CPU 开销。下半部分显示了 CUDA Graph 方法,整个序列作为单个图启动,减少了 CPU 时间并提高了整体吞吐量。
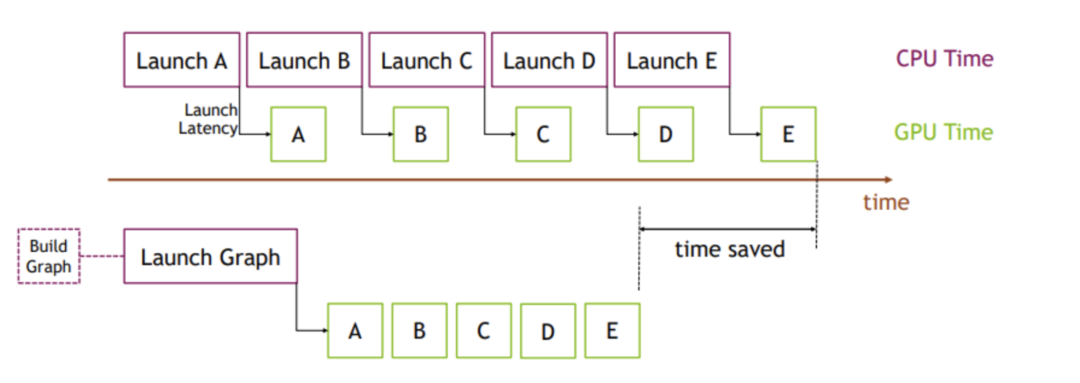
事实上,我发现现代 LLM 服务引擎中的许多显著加速都来自于并行化多个工作负载并重叠它们的执行。我可以轻松列举几个例子:
-
UTLASS 中 TMA 和 WGMMA 的重叠[^6] -
Flash Attention 中 GEMM 和 Softmax 的重叠[^7] -
SGLang 的零开销批处理调度器[^8]
我相信这种简单但有效的理念还有更多机会,看到越来越多的酷炫项目建立在下一代硬件之上,这让我感到非常兴奋。
SGLang 中的 CUDA Graph 是如何工作的
在 SGLang 中,CUDA Graph 的捕获和重放是由 CUDAGraphRunner 类完成的。考虑到框架已经有了一个相当不错的设计,关于 CUDAGraphRunner 如何与 attention 后端一起工作,我们可以专注于实现这三个方法:
-
init_cuda_graph_state() -
init_forward_metadata_capture_cuda_graph() -
init_forward_metadata_replay_cuda_graph()
你可以在下面的图表中找到 CUDAGraphRunner 如何与 attention 后端一起工作的详细流程:
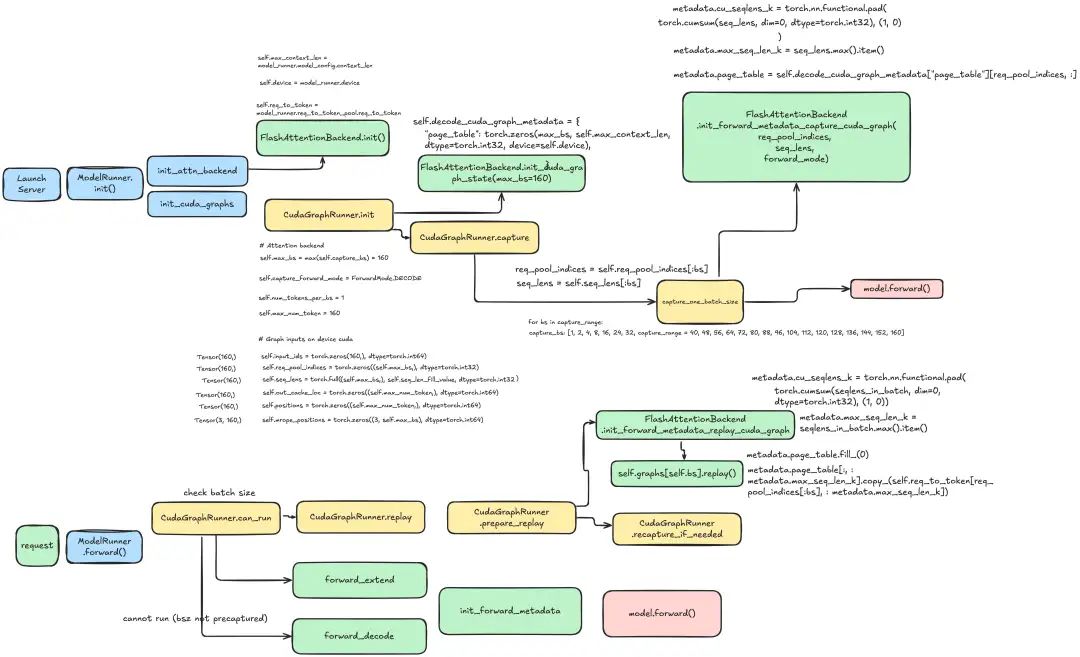
初始化 CUDA Graph 状态
def init_cuda_graph_state(self, max_bs: int):
"""初始化 attention 后端的 CUDA graph 状态。
参数:
max_bs (int): CUDA graphs 支持的最大批次大小
这会在服务器启动期间创建固定大小的张量,这些张量将在 CUDA graph 重放期间重复使用以避免内存分配。
"""
self.decode_cuda_graph_metadata = {
# 序列长度,int32类型 (batch_size)
"cache_seqlens": torch.zeros(max_bs, dtype=torch.int32, device=self.device),
# Query的累积序列长度 (batch_size + 1)
"cu_seqlens_q": torch.arange(
0, max_bs + 1, dtype=torch.int32, device=self.device
),
# Key的累积序列长度 (batch_size + 1)
"cu_seqlens_k": torch.zeros(
max_bs + 1, dtype=torch.int32, device=self.device
),
# 页表,用于将请求中的token映射到tokens' KV缓存索引 (batch_size, max_context_len)
"page_table": torch.zeros(
max_bs,
self.max_context_len,
dtype=torch.int32,
device=self.device,
),
}
值得注意的是,我们发现对于张量类型的元数据,需要先初始化,然后将值复制到预分配的张量中,否则 CUDA Graph 将无法工作。对于标量类型的元数据(例如:
max_seq_len_q、max_seq_len_k),我们可以直接创建新变量。
准备用于捕获的元数据
def init_forward_metadata_capture_cuda_graph(
self,
bs: int,
num_tokens: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
):
"""Initialize forward metadata for capturing CUDA graph."""
metadata = FlashAttentionMetadata()
device = seq_lens.device
batch_size = len(seq_lens)
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
if forward_mode == ForwardMode.DECODE:
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
metadata.max_seq_len_k = seq_lens.max().item()
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
metadata.page_table = self.decode_cuda_graph_metadata["page_table"][
req_pool_indices, :
]
else:
raise NotImplementedError(f"Forward mode {forward_mode} is not supported yet")
self.decode_cuda_graph_metadata[bs] = metadata
老实说,我们不太关心
init_forward_metadata_capture_cuda_graph中实际设置的值,因为我们将在init_forward_metadata_replay_cuda_graph中覆盖它们。我们只需要确保张量形状正确。
准备用于重放的元数据
def init_forward_metadata_replay_cuda_graph(
self,
bs: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
seq_lens_sum: int,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
seq_lens_cpu: Optional[torch.Tensor],
out_cache_loc: torch.Tensor = None,
):
"""Initialize forward metadata for replaying CUDA graph."""
# 从预分配的张量中获取批次中的序列长度,我们切片它
seq_lens = seq_lens[:bs]
# 从预分配的张量中获取批次中的序列长度,我们切片它
seq_lens_cpu = seq_lens_cpu[:bs]
# 从预分配的张量中获取请求池索引,我们切片它
req_pool_indices = req_pool_indices[:bs]
# 获取模型所在设备,例如:cuda
device = seq_lens.device
# 获取用于解码的元数据,这些元数据已经在 init_forward_metadata_capture_cuda_graph() 中预计算并在 init_cuda_graph_state() 中初始化
metadata = self.decode_cuda_graph_metadata[bs]
if forward_mode == ForwardMode.DECODE:
# 更新序列长度与实际值
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
# 更新key的最大序列长度与实际值
metadata.max_seq_len_k = seq_lens_cpu.max().item()
# 更新key的累积序列长度与实际值
metadata.cu_seqlens_k.copy_(
torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
)
# 更新页表与实际值
metadata.page_table[:, : metadata.max_seq_len_k].copy_(
self.req_to_token[req_pool_indices[:bs], : metadata.max_seq_len_k]
)
else:
raise NotImplementedError(f"Forward mode {forward_mode} is not supported yet")
self.forward_metadata = metadata
到目前为止,我们已经实现了一个支持 CUDA Graph 的 FlashAttention 后端!
0x4. 结论
在这篇文章中,我们探索了几个关键组件:
-
FlashAttention 的基础知识和操作原理 -
SGLang 中 attention 后端的架构 -
SGLang 中 KV Cache 的实现细节 -
实现一个基本的 FlashAttention 后端的基础步骤 -
集成 CUDA Graph 支持以优化性能的过程
在我们的后续文章中,我们将深入探讨更多高级主题,包括推测解码(一个具有挑战性的实现,花费了我们超过3周的时间!),以及 MLA, Llama 4, 多模态能力等!
0x5. 关于开源的思考
这是我第一次对一个流行的开源项目做出重大贡献,我非常感激社区的支持和维护者的指导。
对于那些想要开始自己的开源之旅的 MLSys 爱好者,我强烈推荐加入 SGLang 社区。以下是我的一些个人建议:
-
你不需要成为专家才能开始贡献。贡献文档、基准测试和错误修复都是非常有价值的,并且受到欢迎。事实上,我的前两个 PR 专注于文档和基准测试。 -
在像 SGLang 这样的成熟项目中找到一个好的第一个问题可能很具有挑战性。我的方法是密切关注一个特定领域(例如:量化),监控相关 PR 和问题,并提供帮助,通过评论或 Slack 联系 PR 作者。 -
对你的贡献和承诺负责。在开源社区中,专业关系建立在信任和可靠性之上。记住,大多数贡献者都在平衡开源工作与全职工作,所以尊重每个人的时间和努力是至关重要的。
0x6. 参考文献
[^1]: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness(https://arxiv.org/abs/2205.14135) [^2]: From Online Softmax to FlashAttention(https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf) [^3]: Awesome-ML-SYS-Tutorial: SGLang Code Walk Through(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/d4d56dc3ab2260a747964ceb18cb1f69d23146ae/sglang/code-walk-through/readme.md) [^4]: Awesome-ML-SYS-Tutorial: KV Cache Code Walkthrough(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/d4d56dc3ab2260a747964ceb18cb1f69d23146ae/sglang/kvcache-code-walk-through/readme.md) [^5]: Accelerating PyTorch with CUDA Graphs(https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/) [^6]: CUTLASS: CUDA Templates for Linear Algebra Subroutines(https://github.com/NVIDIA/cutlass) [^7]: Flash Attention 3: Fast and Accurate Attention with Asynchrony and Low-precision(https://tridao.me/blog/2024/flash3/) [^8]: SGLang: A Zero-Overhead Batch Scheduler for LLM Serving(https://lmsys.org/blog/2024-12-04-sglang-v0-4/#zero-overhead-batch-scheduler)
(文:GiantPandaCV)