

各位五一快乐,快来吃瓜!(顺便星标⭐️一下本号,最近很多朋友反应不能及时看到内容更新,只有关注并且⭐️才会第一时间收到更新)
AI圈子波澜又起,焦点集中在了大名鼎鼎的Chatbot Arena排行榜上。一篇名为《The Leaderboard Illusion》(排行榜幻觉)的预印本论文横空出世,直接对这个被广泛视为LLM“试金石”的平台提出了系统性质疑,论文更是直接点名Meta Llama 4 刷榜“造假”,连大佬Andrej Karpathy都下场发表了看法

论文地址:
https://arxiv.org/pdf/2504.20879
Chatbot Arena:“兵家必争之地”
先简单科普下,Chatbot Arena由LMSYS(一个研究组织,原名lmsys.org,现称lmarena.ai)创建,通过让用户匿名与两个模型对话并投票选出更好的那个,来对大模型进行排名。因其动态、用户驱动的评估方式,能捕捉到传统基准测试之外的真实用户偏好,迅速成为衡量顶级AI系统能力的事实标准,影响力巨大
《The Leaderboard Illusion》:掀开“皇帝的新衣”?
这篇由Cohere、普林斯顿、斯坦福等机构研究人员(其中部分作者也曾向Arena提交过模型)撰写的论文,通过分析大量数据(涉及200多万次对战、243个模型、42家提供商),指出了Chatbot Arena存在的几大核心问题,认为其公平性和可靠性受到了损害:
-
1. “秘密测试”与“选择性披露”: 论文声称,少数(主要是大型、专有模型)提供商被允许在Arena上进行大量“私下测试”,可以提交多个模型变体进行评估,但最终只选择性地公开表现最好的那个版本的分数,甚至可以撤回不满意的结果。论文点名Meta在Llama 4发布前,仅一个月内就在Arena上测试了多达27个私有变体。这种做法被指扭曲了排名,让这些提供商获得了不公平的优势,大白话就是说Meta Llama 4 “造假” -
-
2. 数据获取“贫富差距”: 由于私下测试、更高的采样率(模型被选中参与对战的频率)以及模型下线(deprecation)策略,专有模型提供商获得了远超开源/开放权重模型的用户反馈数据。论文估计,仅Google和OpenAI就分别获得了Arena总数据的19.2%和20.4%,而83个开放权重模型合计仅获得29.7%。这种数据不对称,让优势方更容易针对Arena进行优化 -
-
3. 过拟合风险: 论文通过实验证明,即使少量Arena数据也能显著提升模型在Arena评估(如ArenaHard基准)上的表现(相对提升高达112%),但在其他通用基准(如MMLU)上提升有限甚至下降。这表明模型可能在“刷榜”,而非真正提升通用能力,即过拟合了Arena的特定偏好 -
-
4. 模型下线不透明且不公: 论文发现大量模型(205个)被“悄悄”下线(采样率降至近零),远超官方明确列出的47个。且这种下线更多发生在开放权重/开源模型上(占被移除模型的66%)。这不仅影响了数据获取,还可能破坏了支撑Arena评分的Bradley-Terry模型假设,导致排名不可靠。
基于这些发现,论文提出了五项紧急建议:禁止撤回分数、限制私有测试数量、公平执行模型移除、实施公平采样算法、公开所有测试模型及移除信息。
LMSYS (lmarena.ai) 回应:捍卫与澄清
面对质疑,Chatbot Arena的组织者lmarena.ai迅速做出了回应,主要观点如下:
-
1. 预发布测试是好事: 他们承认并欢迎预发布测试,认为这能帮助模型提供商了解社区用户的真实偏好,优化模型,对整个社区有利。用户也喜欢第一时间体验最新模型 -
2. 反映真实偏好,而非偏见: Arena的排名反映的是数百万真实用户的偏好总和。偏好本身是主观的,但这正是其价值所在,因为模型最终是为人服务的。他们正在研究统计方法分解偏好,并努力扩大用户群多样性 -
3. 政策防止“挑分”: 他们强调其政策 不允许 提供商仅报告测试期间的最高分。发布的评分是针对 最终公开发布 的那个模型 -
4. 质疑论文方法与数据: lmarena.ai认为论文中的模拟存在缺陷,并指出论文中的一些数据与他们最近发布的实际统计数据不符 -
5. 公平与开放承诺: 他们重申致力于公平、社区驱动的评估,欢迎所有提供商提交模型。帮助Meta测试Llama 4与其他提供商无异,并强调自身平台和工具的开源性,以及发布了大量开放对话数据 -
6. 接受部分建议: 他们表示同意部分建议(如实施主动采样算法),并愿意考虑更多。
Andrej Karpathy :怀疑与替代方案
特斯拉前AI总监、OpenAI创始成员Andrej Karpathy也分享了他的看法,他更倾向于怀疑Arena的排名:
-
1. 个人经验与排名不符: 他提到自己曾遇到过排名第一的Gemini模型实际体验不如排名较低的模型(如Claude 3.5)的情况。也注意到一些“不知名”的小模型排名异常高 -
2. 当数据和经验(或直觉)对不上的时候,往往经验(或直觉)更靠谱: 引用贝索斯的话,个人或小范围的真实体验可能比宏观数据更能反映问题 -
3. 担忧过拟合特定偏好: 他推测,不同团队可能投入了不同程度的精力专门针对Arena评分进行优化,导致模型更擅长Arena偏好的风格(比如嵌套列表、表情符号),而非整体能力提升 -
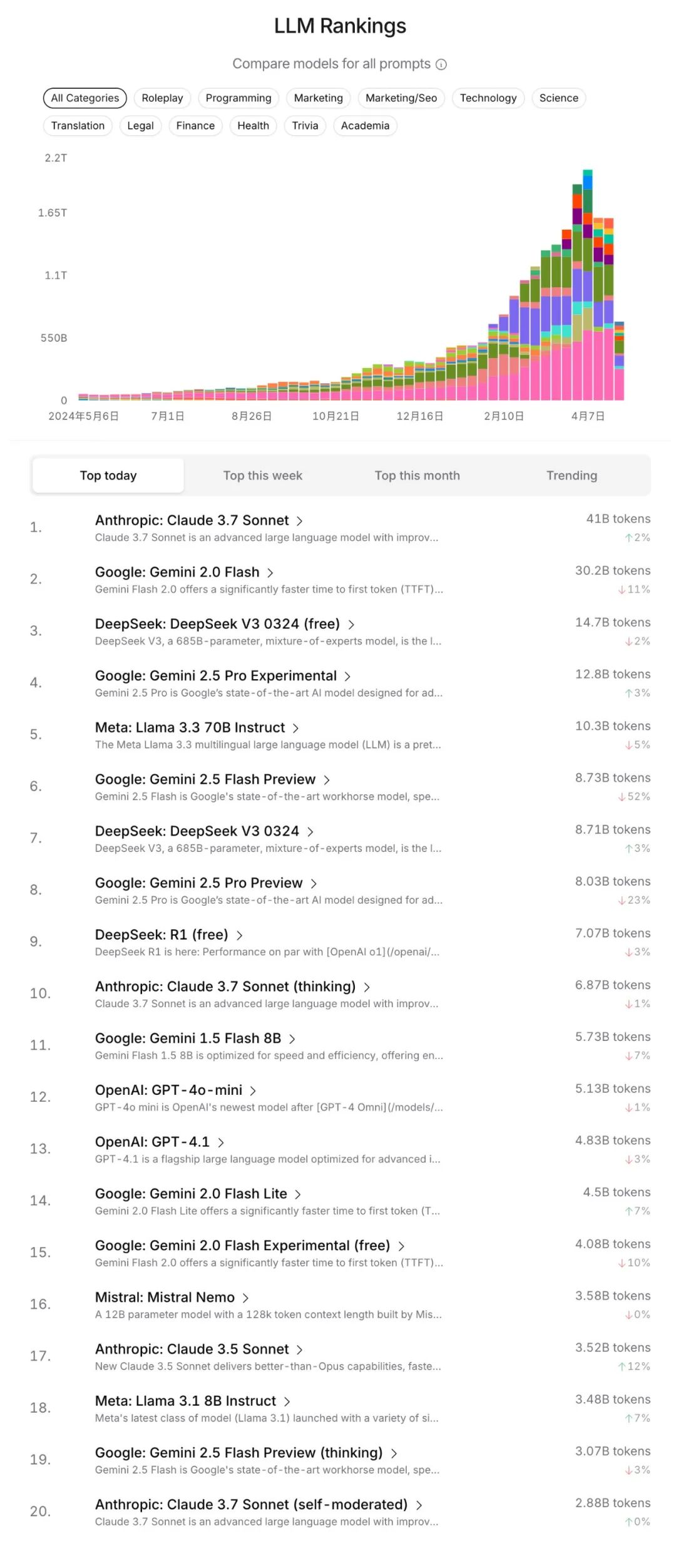
4. 推荐替代评估:OpenRouter: 新的潜在顶级评估方式——OpenRouter的LLM排名。OpenRouter作为API路由平台,用户(包括企业)基于实际应用需求和成本在不同模型间切换,这种“用脚投票”直接反映了模型在真实场景中的综合价值(能力+成本),可能更难被“游戏化”。
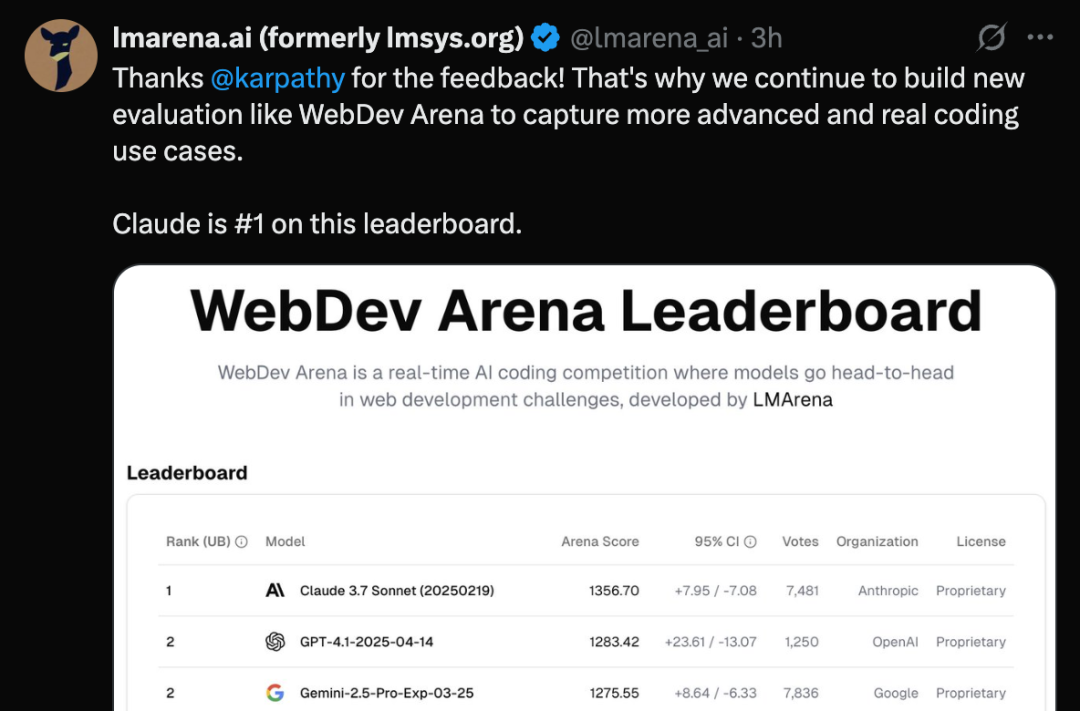
lmarena.ai对Karpathy的回应:
感谢karpathy的反馈!表示会持续构建像WebDev Arena这样的新评估平台,以捕捉更高级、更真实的编码用例
Andrej Karpathy 质疑全文:

最近有篇新论文在传,详细分析了 LM Arena 排行榜,叫《排行榜幻觉》(The Leaderboard Illusion)
我最早开始有点儿怀疑这事,是有一次,(大概前段时间吧),某个 Gemini 模型冲到了第一名,而且分数远超第二,但我自己切换过去试用了几天,感觉还不如我之前用习惯了的那个。反过来呢,差不多同一时间,Claude 3.5 在我个人用起来明明是顶级水平,但在 Arena 上的排名却非常低。无论是在网上还是私下聊天,我都听到过类似的反馈。而且,还有不少看着挺随机的模型,有些小的都让人起疑,据我所知也没啥实际应用背景,但它们排名却也相当高。
“当数据和(用户的)直觉或经验对不上的时候,往往后者更靠谱。”(这是杰夫·贝索斯最近在一个播客里说的,不过我个人深有同感)。我觉得吧,这些(大模型)团队内部可能把不同的精力都放在了专门针对 LM Arena 分数上,并且基于这个分数来做决策。不幸的是,这样搞出来的可能不是整体上更好的模型,而是更擅长在 LM Arena 上拿高分的模型——不管那到底意味着什么。也许就是那种特别会用嵌套列表、项目符号和表情符号的模型吧。
LM Arena(以及那些 LLM 提供商)很可能会继续在这种模式下迭代和改进,但除此之外,我心里还有个新的候选者,有潜力成为新的“顶级评测”方式之一。那就是 OpenRouterAI 的 LLM 排名:
https://openrouter.ai/rankings
简单来说,OpenRouter 能让个人或公司在不同 LLM 提供商的 API 之间快速切换。这些用户都有真实的应用场景(不是搞些小测试题或者解谜),他们自己内部也有评估方式,而且都有实实在在的动力去选对模型。所以,当他们选择某个 LLM 而不是另一个时,实际上就是在用脚投票,综合考虑了(模型的)能力和成本。我觉得 OpenRouter 在用户数量和使用场景的多样性上可能还没完全到位,但这种基于实际应用的评估方式,我认为非常有潜力发展成一种非常好的、并且很难被“刷榜”或操纵(game)的评测体系
–完–
最后给大家贴一下openrouter的大模型综合排行(还有各个领域的排名,涉及编程,市场,角色扮演,技术,科学,翻译,法律,金融,健康,学术等大家可以自行探索)
参考:
https://arxiv.org/pdf/2504.20879
⭐
(文:AI寒武纪)