出品丨AI 科技大本营(ID:rgznai100)
在多模态视频生成技术逐渐成熟的今天,定制化能力成为衡量系统实用性的重要标准。
5 月 8 日,腾讯混元团队正式推出并开源全新的多模态定制化视频生成框架 HunyuanCustom。该工具基于混元视频生成大模型(HunyuanVideo)打造,支持图像、文本、音频和视频等多种输入模态,提供高度可控且高质量的视频生成能力。
多模态输入 + 主体一致性
解决定制视频「变脸难题」
传统图生视频或文生视频模型虽可合成视觉内容,但通常难以在更换动作、背景、服饰等条件下,保持人物身份不变——比如人物“变脸”、物体“漂移”等问题较为常见。HunyuanCustom 的核心目标正是解决这一挑战。
HunyuanCustom 引入了基于 LLaVA 的图文融合模块,结合时间级联的图像 ID 增强机制,使视频在全程保持“主体一致”。在此基础上,HunyuanCustom 进一步支持音频驱动和视频驱动等多模态控制输入,实现场景中的声音联动、角色替换等更复杂的定制任务。
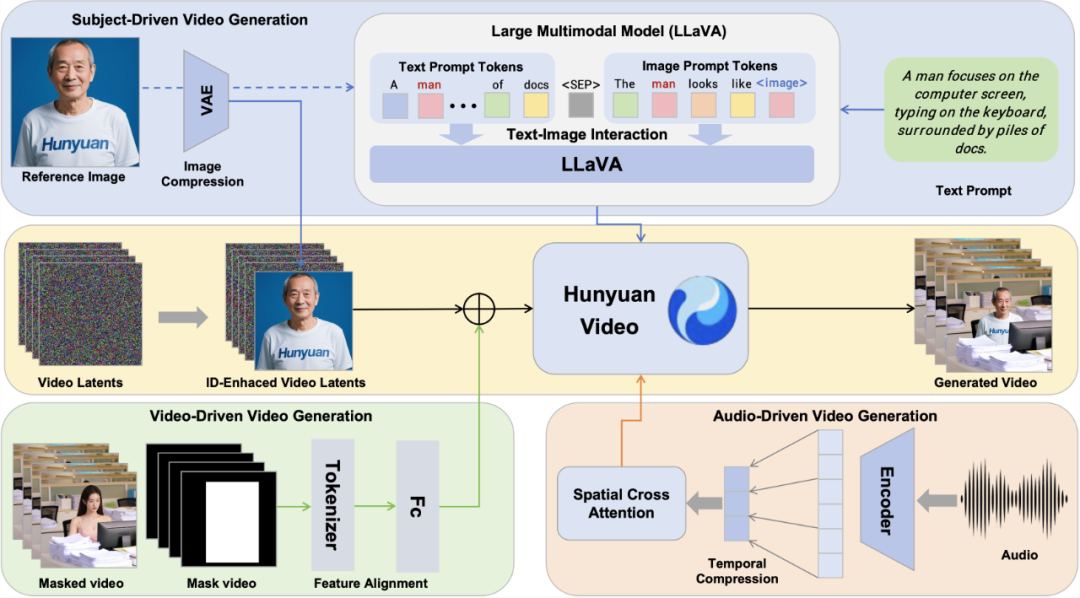
HunyuanCustom 整体框架,支持基于文本、图像、音频和视频等条件生成主体一致性视频
HunyuanCustom 支持文本、图像、音频和视频等多种输入形式。简单来说,你可以上传一张或多张人物或物体的照片,为一个或多个主体生成定制化的视频内容;也可以配上一段音频,让视频中的人物“开口说话”或唱歌。更进一步,它还支持视频输入,能将已有视频中的指定对象,精准替换为用户上传的目标图像,实现个性化内容植入。
在数据构建方面,团队引入了 Qwen、YOLO、InsightFace、GroundingSAM2 等模型协同构建数据标签体系,覆盖人类、动物、植物、建筑、动画等多个主体类型。训练中采用 Flow Matching 框架,结合结构化标注和 mask 增强策略,显著提升了模型泛化能力与编辑灵活度。
此外,为实现可控与一致性的统一,HunyuanCustom 在系统架构上设计了多个关键模块:
-
LLaVA 图文交互模块:引入文本与图像模板融合机制,使描述词与身份图像协同表达;
-
图像 ID 增强模块:利用 3D-VAE 和 RoPE 时间嵌入机制,在时间维度传播身份特征;
-
AudioNet 模块:通过空间交叉注意力实现分层音频对齐,支持多级语音表达;
-
视频驱动注入模块:基于 patchify 的特征对齐网络,实现视频 latent 与身份注入的融合。
上述模块使 HunyuanCustom 可在训练与推理阶段均实现图像、语音、视频等模态的解耦控制,为多模态生成提供了灵活接口。
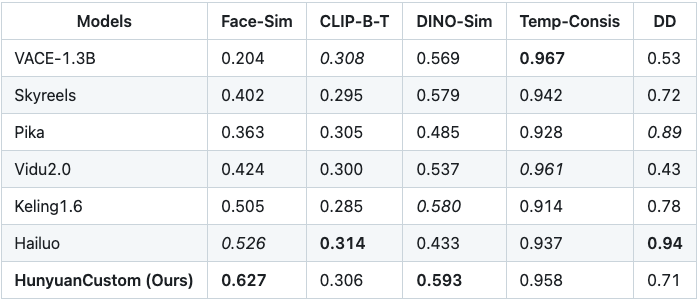
为了验证 HunyuanCustom 的实际效果,腾讯团队将其与多款主流视频定制方法进行了对比测试,包括 VACE、Skyreels、Pika、Vidu、Keling 和 Hailuo 等。评估指标涵盖了 人脸/主体一致性(Face-Sim)、视频与文本的一致性(CLIP-B-T)、图像语义相似性(DINO-Sim)、时间一致性(Temp-Consis)以及整体视频质量打分(DD)。
从测试结果来看,HunyuanCustom 在主体一致性(0.627)方面显著领先其他模型,视频的视觉连贯性和主体特征保留更为优秀。在语义层面,DINO-Sim 得分也达到 0.593,处于当前开源方案中的领先水平。同时,在保持较高时间一致性的前提下,其整体视频质量评分(DD)达 0.71,平衡了稳定性与细节表现。
目前,HunyuanCustom 的单主体生成能力已在混元官网上线,用户可以在“模型广场-图生视频-参考生视频”中体验,其他能力将于 5 月内陆续对外开源。
体验入口:https://hunyuan.tencent.com/modelSquare/home/play?modelId=192
项目官网:https://hunyuancustom.github.io/
代码仓库:https://github.com/Tencent/HunyuanCustom
技术报告:https://arxiv.org/pdf/2505.04512
(文:AI科技大本营)