


谷歌的Gemini 2.5 Pro在视频理解领域又有了重磅进展,现在可以一口气处理长达6小时视频了!
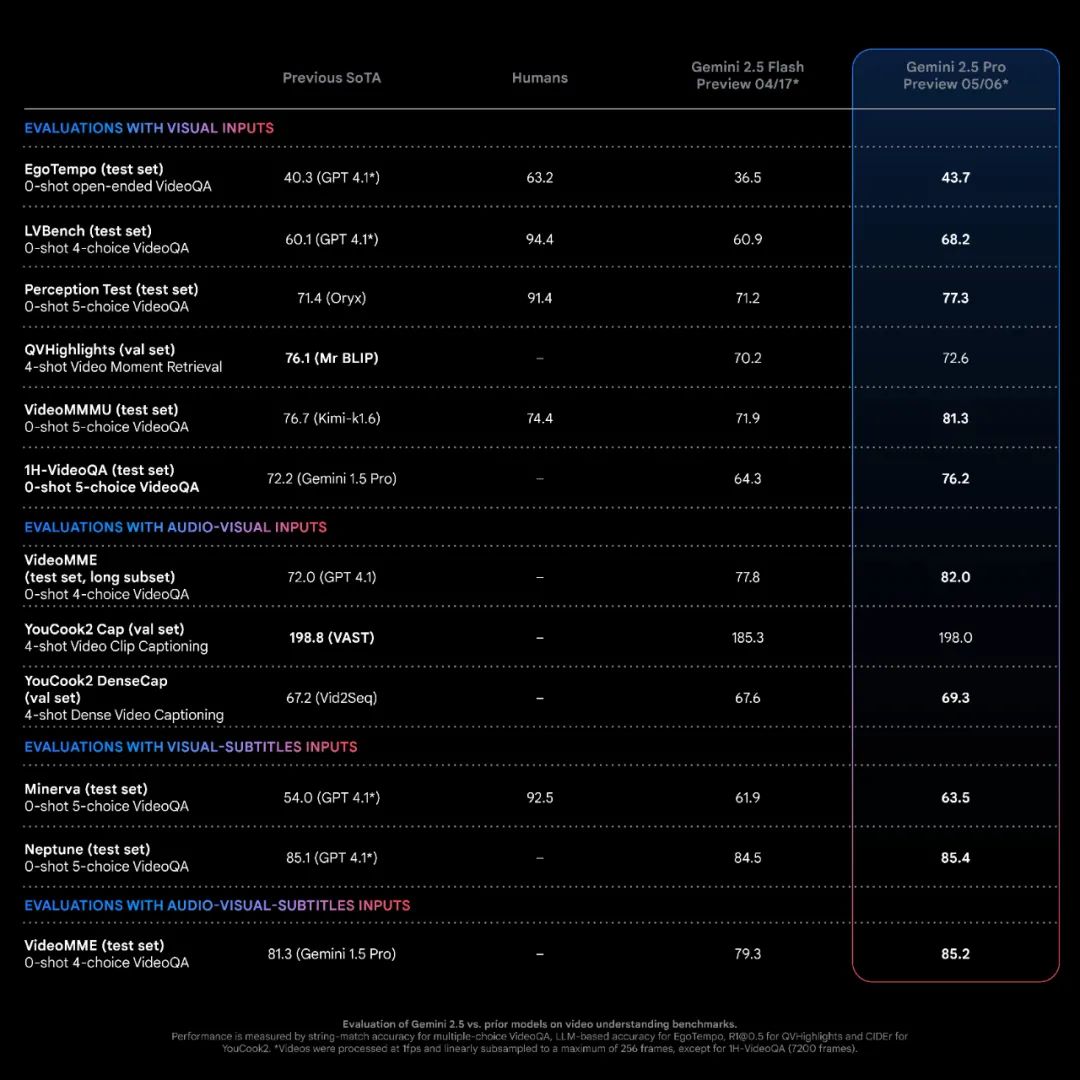
首先,硬实力杠杠的!Gemini 2.5 Pro 在十几个学术视频基准测试中取得了新的SOTA(业界最佳)成绩,而且是在零样本或少样本训练的情况下,直接叫板那些经过精细调优的专业模型。比如在YouCook2密集字幕生成和QVHighlights高光时刻检索这类高难度任务上,表现都相当惊艳
Gemini 2.5首次实现了原生多模态模型能够将音视频信息与代码等其他数据格式无缝结合。不是简单地“看懂”视频,而是能基于视频内容进行更深层次的理解和创造。
Gemini 2.5不仅在传统视频分析上表现卓越,还解锁了许多我几个月前想都不敢想的新玩法,下面几个例子,感受一下Gemini 2.5的的视频理解能力
直接把视频变身网页交互应用
怎么玩? 给Gemini 2.5 Pro一个YouTube视频链接和一段文本提示(比如告诉它如何分析视频)。模型会先分析视频,生成一个详细的“学习应用规格说明书”,提炼视频中的关键点
然后呢? 这个规格说明书再被喂给Gemini 2.5 Pro,它就能直接生成这个学习应用的代码!
实例: 看视频实现“视力矫正模拟器”应用
视频一键生成p5.js动画
想干嘛? 想要快速生成视频的动态摘要,或者进行自动化内容创作?
Gemini 2.5 Pro: 只需一个提示,就能从视频中生成动态动画,并保持与原视频相同的时间顺序
实例:输入一段伦敦地标游览视频 (油管链接:https://youtube.com/watch?v=hIIlJt8JERI),Gemini就能生成p5.js代码,输出一个动态动画效果
精准检索与描述视频片段
痛点: 从长视频里找特定片段太费劲?
Gemini 2.5 Pro: 利用音视觉线索,识别精度远超以往。例如,在一个10分钟的Google Cloud Next ’25开幕演讲视频中,它能准确识别出16个与产品演示相关的不同片段,并给出带时间戳的描述
强大的时序推理能力(计数):
挑战: 不仅要看懂,还要理解时间序列上的微妙关系,比如计数
Gemini 2.5 Pro: 比如它成功找出了主角使用手机的17个不同场景。这对于理解视频中的行为和模式至关重要
最后,还有一个重磅实用更新:低媒体分辨率(low media resolution)功能正式上线!
这个功能现在已经登陆Gemini API,很快也会在AI Studio和Vertex AI上线
它的牛X之处在于,能在性能损失极小的情况下,将每帧视频的视觉token从258个锐减到66个!这意味着什么?在200万token的限制下,以前能处理2小时的视频,现在能处理长达6小时!处理效率大幅提升,成本也下来了!
注意:Gemini 2.5 Pro & Flash视频理解都很强
参考:
https://developers.googleblog.com/en/gemini-2-5-video-understanding/
⭐
(文:AI寒武纪)