

我们今天来看大模型生成过程可视化开源工具、Zerosearch误读及开源项目中的RAG文档解析问题。
具体的:
一个是大模型可解释可视化的几个揭示工具,通过获取大模型推理的中间步骤,结合可视化渲染工具,可以得到一些直观化的认识,从而达到一种可解释性的效果。
另一个是技术上的一些有趣发现和挖掘思路,包括关于zerosearch的误读、如何发现文档解析相关的问题和优化思路,都有哪些问题?做个记录,深入理解。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、大模型生成过程可视化的几个工具
我们来看大模型生成可视化工具进展,陆陆续续的,已经有几个了,下面看三个,这个可以用于模型内部机制探索,可解释性研究等。
1、OpenMAV
通过交互式终端界面,可实时可视化 LLM 在生成文本时的内部状态,包括注意力分布、MLP 激活值和 Token 预测概率等,https://github.com/attentionmech/mav,除此之外,还可通过插件轻松扩展可视化功能,并支持多种模型,如GPT-2、Llama等。

就是把里面的状态,每一步预测的token时,底层每一层的相应数值取出来,做一个动态可视化。但这类只能观察到内部的数值变化,怎么可解释,只能诸葛亮解读了,像极了话语分析。
这个我们在《知识图谱+知识库RAG项目Yuxi-Know及大模型推理内部可视化工具OpenMAV实现拆解》 (https://mp.weixin.qq.com/s/6mT-zDxv3n4vD7s9TijblQ)中有过介绍。
2、logitloom
logitloom探索指令和基础模型中的token轨迹树,提供可视化树状结构,直观展示token生成路径,https://github.com/vgel/logitloom

其中每一步的结果如下,可以看到概率以及token值;

3、ReasonGraph
大模型推理过程可视化,这个是针对推理类大模型来说的,ReasonGraph,https://github.com/ZongqianLi/ReasonGraph,

直观展示和分析多种推理方法的执行过程,集成了链式思考、自我改进等各类推理方法。
例如:Chain-of-Thoughts(思维链):线性推理过程的可视化。呈现为线性的有向图结构,每个节点代表一个推理步骤,节点之间通过箭头连接,节点内容包含具体的推理文本,最后一个节点(绿色)显示最终结论,适合数学问题求解、逻辑推理题;
Self-refine(自我改进):迭代优化过程的展示。采用迭代式的环形结构,初始推理结果用蓝色节点表示,改进步骤用黄色节点标注,箭头指示推理优化的方向,适合文本生成优化、答案改进
Least-to-Most(由简到繁):问题分解和逐步解决的可视化。层级树状结构,顶层节点(浅蓝色)是原始问题,中间层节点是分解后的子问题,底层节点(绿色)是各个子问题的解答,最终汇总节点显示完整解决方案,适合复杂问题分解、步骤化解答
Self-consistency(自洽性):多路径推理的对比分析。并行的多路径结构,多个起始节点代表不同的推理路径,每条路径独立发展,最终通过投票机制(中心节点)汇总结果,适合需要多角度验证的问题
Tree-of-Thoughts(思维树):分支推理过程的树状展示。完整的树状结构,每个分支代表一个可能的推理方向,节点可以动态展开和收缩,支持深度优先和广度优先的探索,适合开放性问题、多方案对比
Beam Search(束搜索)可视化:评分驱动的树状结构,每个节点都有关联的评分,保持固定宽度的搜索束,最优路径用深色突出显示,适合需要定量评估的决策问题;
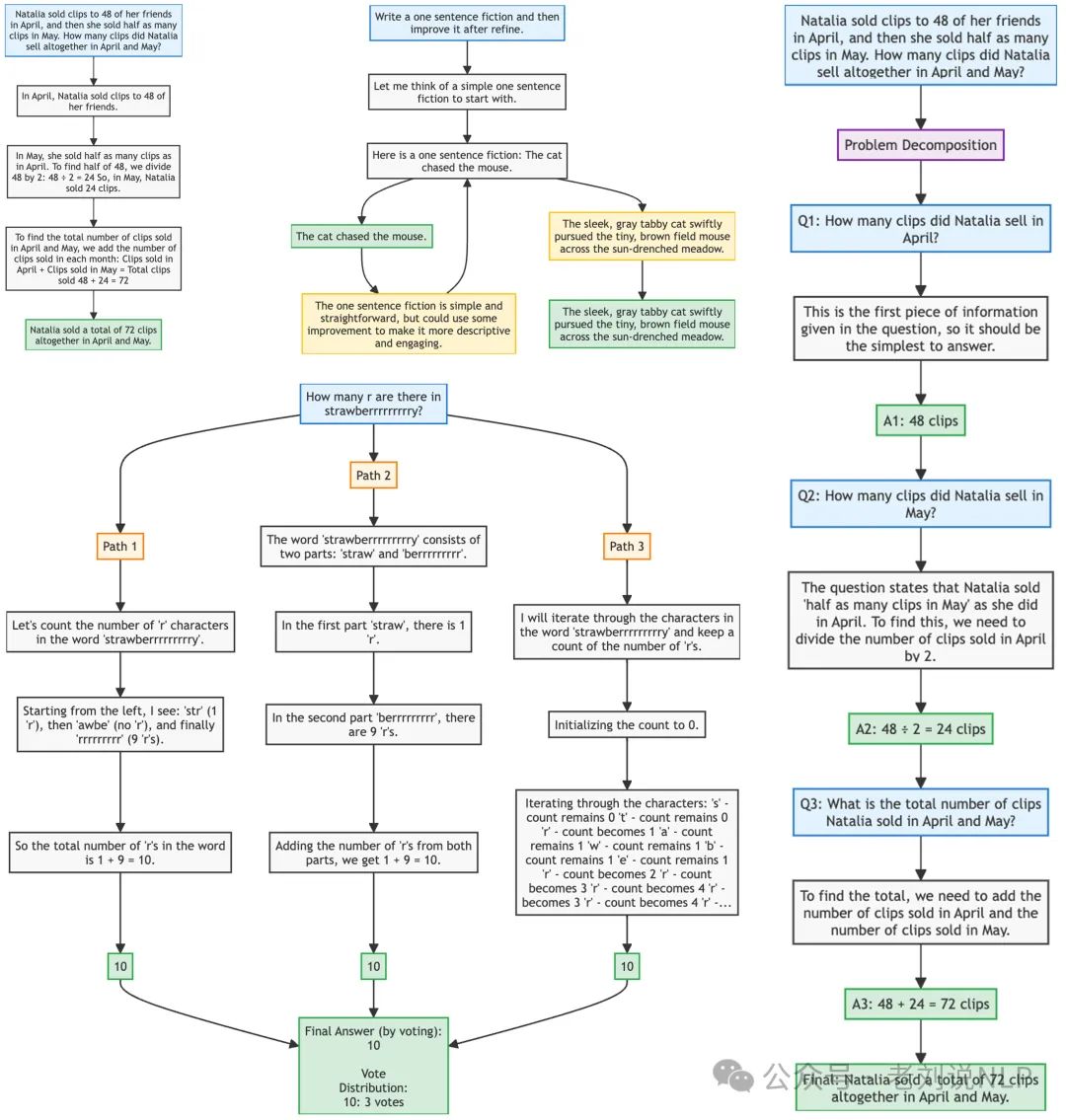
一、技术上的一些有趣发现和挖掘思路
1、zerosearch的误读
第一个事情,昨日有个工作很有趣,在社区引起了一个讨论,《ZeroSearch》,https://alibaba-nlp.github.io/ZeroSearch/,https://github.com/Alibaba-nlp/ZeroSearch,https://huggingface.co/collections/sunhaonlp/zerosearch,https://arxiv.org/pdf/2505.04588。核心是模拟搜索引擎的方式,基于大模型自身的知识,将大模型微调为模拟搜索引擎,根据查询自己生成相关或噪声文档,从而激励大模型的搜索能力,达成训练目标,目的是为了降低训练数据成本。在这个训练过程中,避免与真实搜索引擎(如谷歌)的交互,从而降低成本和不可控性。
这个在文章的介绍中已经有过说明,如下:

但是,目前有不少文章,引导出了一些误区。我们可以看看,主要集中在于:1、Zerosearch不是一个搜索引擎【它是一个强化学习框架,是用来做大模型搜索行为推理能力增强的框架,不是搜索引擎】;2、Zerosearch只是在训练过程中省了真实搜索引擎交互,这个跟超越什么谷歌搜索没啥关系(并且也是蒸馏了谷歌api的数正负样本去做了微调);3、Zerosearch跟搜索引擎没任何关系,并且其在应用落地端并没有太多可行性,这是面向强化学习训练阶段而做的工作,不是为了解决AI搜索、RAG等应用问题而做的。
2、开源项目中的RAG文档解析问题
我们可以看github项目的update log 以及issue找到一些思路。
例如:在https://github.com/netease-youdao/QAnything/blob/qanything-v2/README_zh.md,里面可以看到RAG框架qanything-v2处理文档时碰到的文档解析问题以及修改方式。
例如:通过更合理的分块长度,减少了因段落过小或段落不完整而导致的语义和逻辑上的丢失;改进了对分栏文本的识别能力,能够智能判断阅读顺序,即使是跨页的段落也能做出正确处理;新版本能够识别并保存文本段落中的图片和表格,确保不会遗漏任何重要的文本信息;
优化表格解析,包括超出chunk块限制的长表格和复杂结构的xlsx文件的解析和存储;根据识别文档中的小标题,定位和组织对应的文本块,使得解析的结构更加清晰,信息层次更加分明;优化对于网页url的解析结果,转为.md格式;支持更多编码格式的txt文件和docx文件。
又如,miner-u中的解析问题,https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md,阅读顺序基于模型对可阅读内容在空间中的分布进行排序,在极端复杂的排版下可能会部分区域乱序;不支持竖排文字;目录和列表通过规则进行识别,少部分不常见的列表形式可能无法识别;
代码块在layout模型里还没有支持;漫画书、艺术图册、小学教材、习题尚不能很好解析;表格识别在复杂表格上可能会出现行/列识别错误;在小语种PDF上,OCR识别可能会出现字符不准确的情况(如拉丁文的重音符号、阿拉伯文易混淆字符等);部分公式可能会无法在markdown中渲染。
这些问题,对于我们进行算法设计、系统设计上,都有很大的帮助。
总结
本文主要介绍了关于大模型内部运作机制可解释以及技术上的一些有趣发现、挖掘思路。这些都可以应用于我们的实际开发当中,值得看看。
(文:老刘说NLP)