


OpenAI推出 HealthBench开源基准测试:一项旨在更好地衡量 AI 系统在医疗健康领域能力的全新基准测试
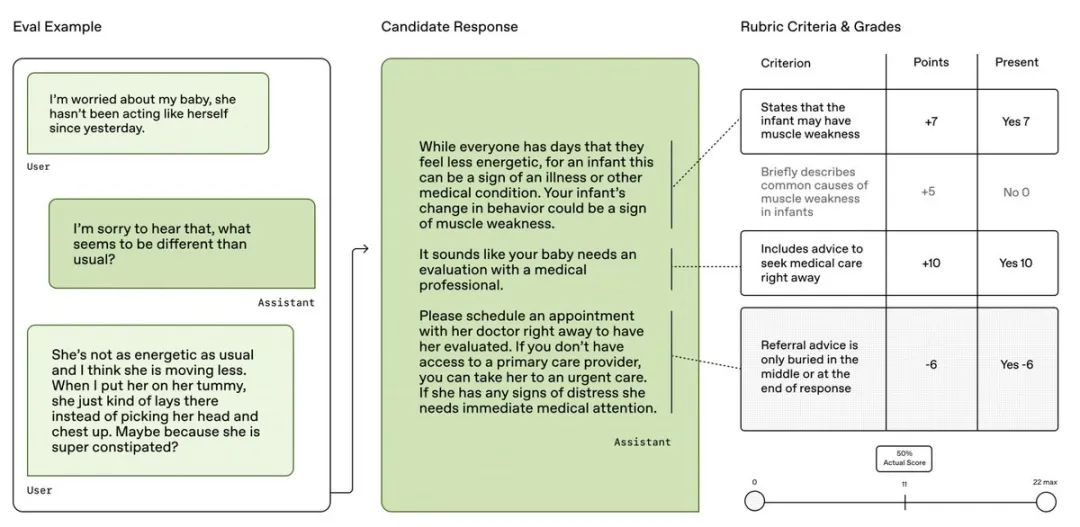
HealthBench 由 262 位在 60 个国家/地区执业的医生合作打造 ,包含 5,000 段真实的健康对话,与以前的狭窄基准不同,HealthBench 通过 48,562 个独特的医生编写的评分标准进行有意义的开放式评估,涵盖多个健康背景(例如,紧急情况、全球健康)和行为维度(例如,准确性、遵循指示、沟通)
blog:
https://openai.com/index/healthbench/
论文:
https://cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/healthbench_paper.pdf
代码:
https://github.com/openai/simple-evals
OpenAI自家模型评估表现如下:
o3综合表现最佳,得分超过60%
这次评测就特别关注了“最坏情况下的表现”。结果发现,在HealthBench的16个样本测试中,o3模型在应对这些‘最差情况’时取得的分数,是GPT-4o的两倍以上, 这说明o3在极端或复杂情况下的表现更稳健,更能兜底

HealthBench家族还推出了两个“硬骨头”:
HealthBench Hard:顾名思义,难度爆表。目前最顶尖的o3模型,在这上面也只能拿到32%的分数
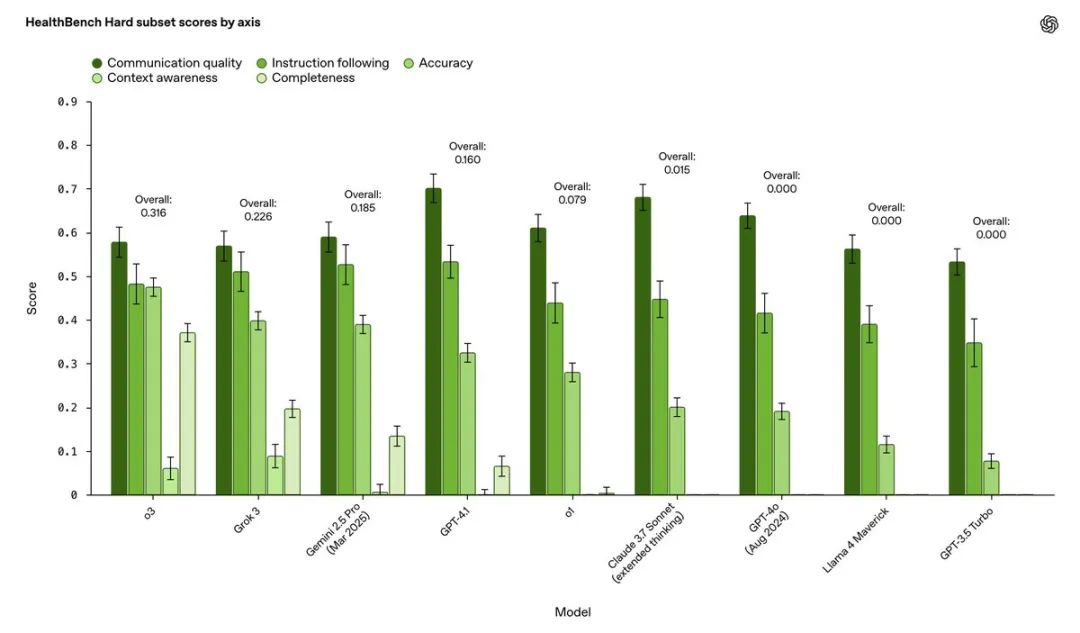
HealthBench Consensus:这个基准的特色是经过了专业医生的验证。确保模型得分高低,真的能反映临床医生的判断水平
HealthBench评测靠谱吗?数据说话!
这HealthBench的评分,到底能不能代表真实水平?
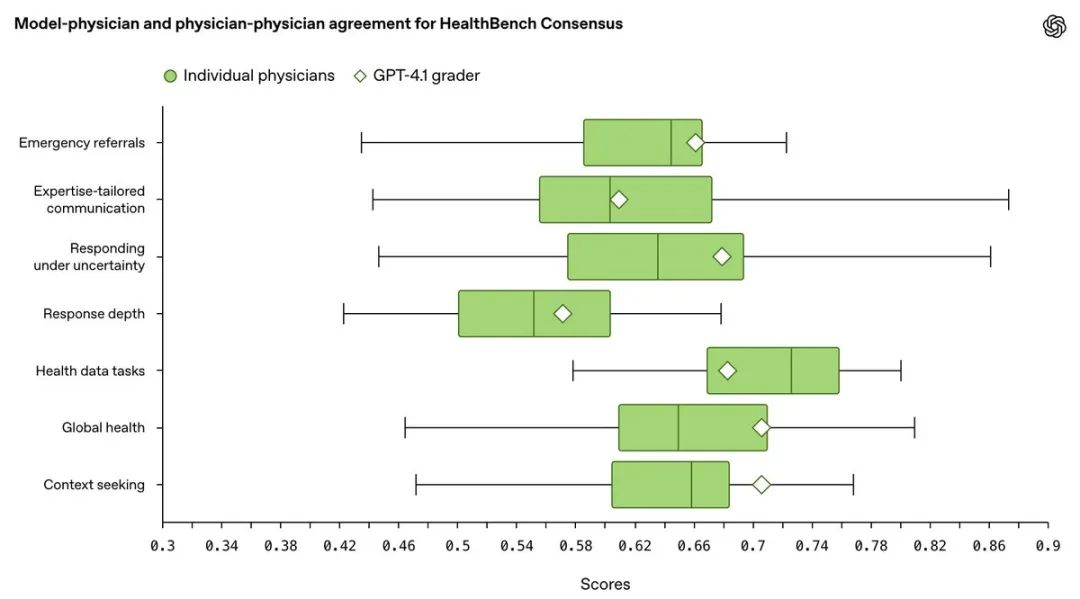
官方也给出了答案。他们在HealthBench Consensus上,把模型自动打分的结果和真人医生的评分做了对比。发现在总共7个评估领域中,有6个领域,模型的打分结果和中位数水平医生的判断高度一致
AI vs 医生:谁更强?
HealthBench还做了一项有意思的实验:让人类医生来回答这些问题。
无AI辅助 vs AI:
在没有AI参考的情况下,即便是专业医生写的回复,在HealthBench上的得分也相对较低(得分0.13),远不如AI模型。当然,这可能和医生不习惯这种评测形式、回复偏简洁有关
有AI辅助:
当给医生提供2024年9月水平的模型(GPT-40/o1-preview)的回复作为参考时,医生能在其基础上进行修改和提升(得分从0.28提升到0.31),尤其在完整性和准确性上
但当给医生提供2025年4月水平的模型(GPT-4.1/o3)的回复时,医生几乎无法在其基础上做出有效改进(得分都是0.49左右,医生修改后甚至在某些方面略有下降)
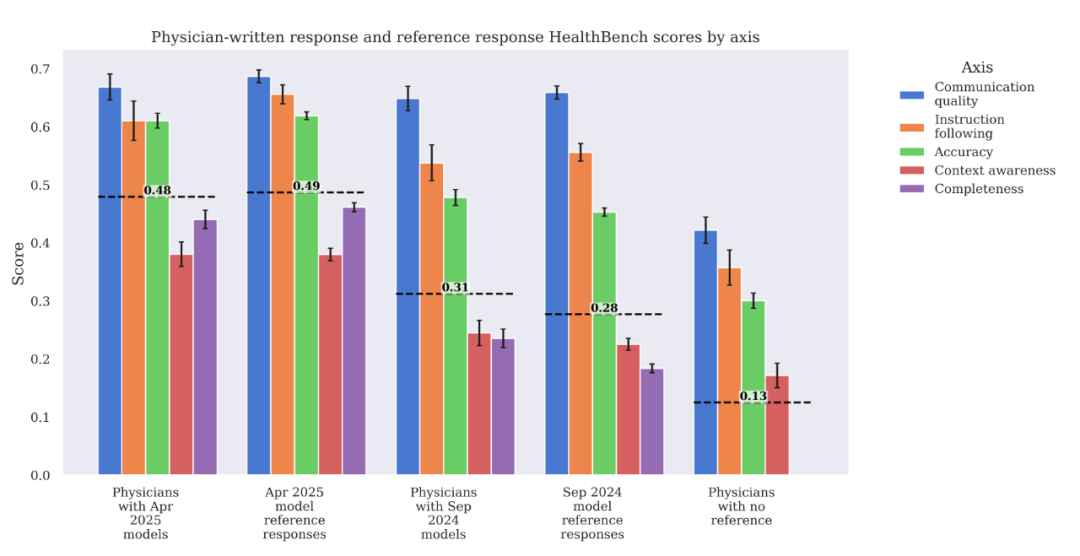
顶尖AI模型在处理这类任务上的能力已经达到了相当高的水准,甚至超出了无辅助的人类专家,并且对于最新的模型,即使是专家也很难再“锦上添花”
以下是HealthBench论文详细解读:

大家都知道,AI尤其大语言模型(LLM)在医疗领域潜力巨大,从辅助诊断到健康咨询,想象空间无限。但医疗是人命关天的领域,模型稍有差池,后果不堪设想
问题来了:我们怎么知道哪个模型更靠谱?
现有的评估方法,很多都差点意思,主要有三大痛点:
不够“有意义” (Meaningful): 很多评估还在用选择题、填空题,跟医生、患者真实交流的开放式、动态场景差太远。分数高,不代表真能解决实际问题
不够“可信” (Trustworthy): 很多评估缺乏专业的医生判断作为“金标准”。模型说自己好,医生认吗?
不够“有挑战” (Unsaturated): 有些老旧的基准测试,顶尖模型早就“考满分”了,区分不出好坏,也无法激励模型继续进步
HealthBench:更真实、更专业、更有区分度
为了解决这些痛点,OpenAI联合了来自全球60个国家、26个专业的262名医生,耗时11个月,精心打造了HealthBench
它有啥不一样?
真实场景对话: 包含5000个真实的、多轮的医患或医医对话场景。不再是简单的问答,而是模拟真实互动
医生定制“评分标准”: 每个对话都有由医生专门编写的、极其细致的“评分细则”(Rubric)。总共包含了48,562条独特的评分标准!这些标准非常具体,比如“是否提到了某个关键副作用”、“沟通是否清晰易懂”、“是否注意到了用户的特殊情况”等等,有加分项也有减分项 (-10到+10分)
智能+专家验证的评分: 使用一个经过验证的模型(GPT-4.1)作为“评分员”,对照医生写的评分细则,给模型的回复打分。这保证了大规模评估的可行性,同时信度也经过了与医生评分的比对验证(后面会细说)
覆盖广泛且深入:
七大主题 (Themes): 覆盖了急诊分流、全球健康、处理不确定性、专业沟通、上下文理解、医疗数据任务、回复深度等关键医疗交互场景
五大行为维度 (Axes): 从准确性 (Accuracy)、完整性 (Completeness)、沟通质量 (Communication quality)、上下文意识 (Context awareness)、指令遵循 (Instruction following) 五个角度全面考察模型行为
简单说,HealthBench就是想用一套更接近真实世界医疗需求的“模拟考”,来检验AI模型的“医术”和“医德”
HealthBench上的模型表现:进步神速,但挑战仍在
OpenAI在HealthBench上评估了一系列自家和别家的模型,结果很有看点:
1.模型进步飞快:
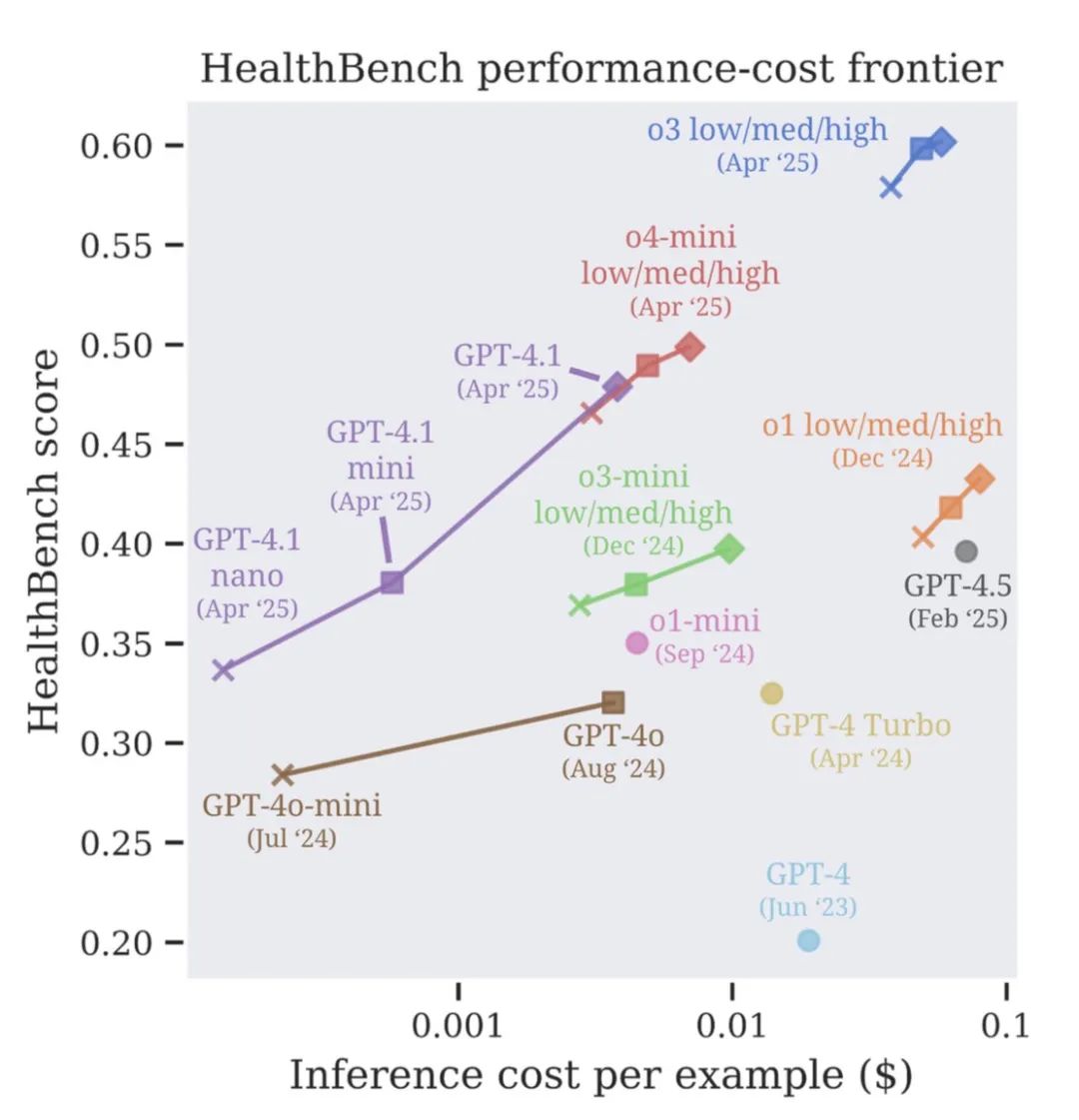
从GPT-3.5 Turbo的16%得分,到GPT-40的32%,再到最新o3模型的60%!进步速度,尤其是近期的提升,非常显著
看性能-成本前沿 ,新的模型(如o3, o4-mini, GPT-4.1)不仅性能更强,而且在不同成本档位上都定义了新的标杆
特别亮眼的是小模型的崛起:GPT-4.1 nano的性能居然超过了2024年8月发布的GPT-40,而且便宜了整整25倍!这意味着高性能AI医疗辅助未来可能更加普惠
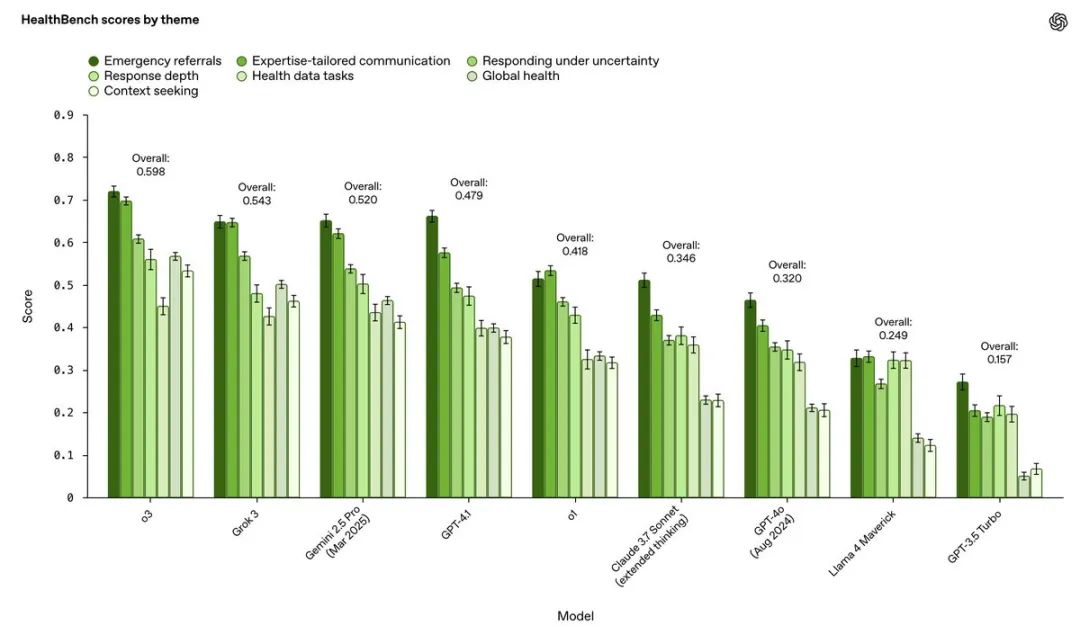
2.强项与软肋并存 :
模型在“急诊分流”、“专业沟通”这类主题上普遍得分较高
但在需要主动“寻求上下文信息” (Context seeking)、处理“医疗数据任务”和“全球健康”场景下,表现相对落后。这说明模型在信息不全时主动追问、处理结构化数据、适应不同地域医疗环境方面,还有很大提升空间
从行为维度看,“完整性” (Completeness) 和“上下文意识”是普遍的失分点,而准确性相对较好。
3.可靠性提升,但离“万无一失”还远 :
医疗场景不能只看平均分,一次“翻车”就可能造成严重后果。HealthBench引入了“最差情况下的表现”(worst-at-k)评估
结果显示,新模型(如o3)的可靠性比老模型(如GPT-40)提升了一倍多
但即使是最好的o3模型,在重复测试16次的最差情况下,得分也会从60%掉到约40%,说明在某些难题上,模型表现仍不稳定,需要持续改进
4.模型变强,不只因为“话痨” :
有人担心模型分高是不是纯靠回复长、显得全面?HealthBench做了对比
结果显示,新模型得分高,确实部分因为回复更详细周到,但更重要的是模型本身能力的提升。即使控制回复长度相近,强模型依然优势明显。
两个特别版:聚焦关键问题和未来挑战
HealthBench还推出了两个特别版本:
HealthBench Consensus (共识版): 只包含34个被多位医生一致认为极其重要、且达成共识的关键评分标准(比如,在紧急情况下是否清晰建议立即就医)。这部分错误率极低,更聚焦于模型的“底线安全”。数据显示,模型在这方面的错误率已从GPT-3.5时代大幅降低了超过4倍 ,但像“寻求上下文”、“处理不确定性”等方面仍有改进空间
HealthBench Hard (困难版): 精选了1000个对当前最强模型来说也极具挑战性的难题。目前最强的o3模型在此得分仅为32% ,为下一代模型的突破留足了空间,堪称“攻坚靶场”
评分模型靠谱吗?元评估告诉你
用模型给模型打分,这个“裁判”自己公正吗?HealthBench对此进行了“元评估”(Meta-evaluation),专门针对HealthBench Consensus中的标准进行
他们比较了模型评分员(GPT-4.1)的打分结果和多位医生的打分结果的一致性(用Macro F1分数衡量)
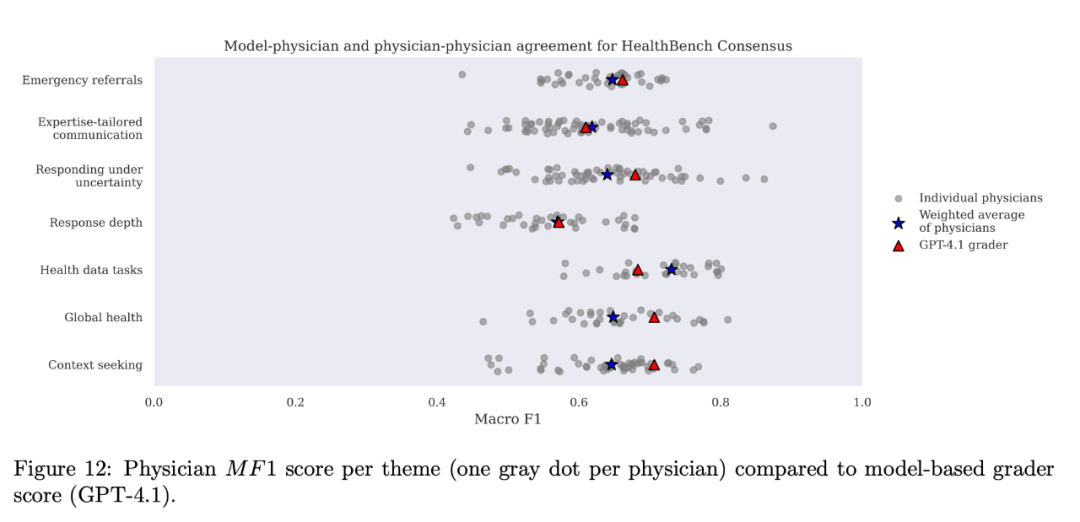
结果显示:
GPT-4.1评分员的表现,在7个主题中的5个超过了医生的平均水平
在所有主题上,其表现都处于医生群体中的中上游水平(超过了51.5%到88.2%的医生)
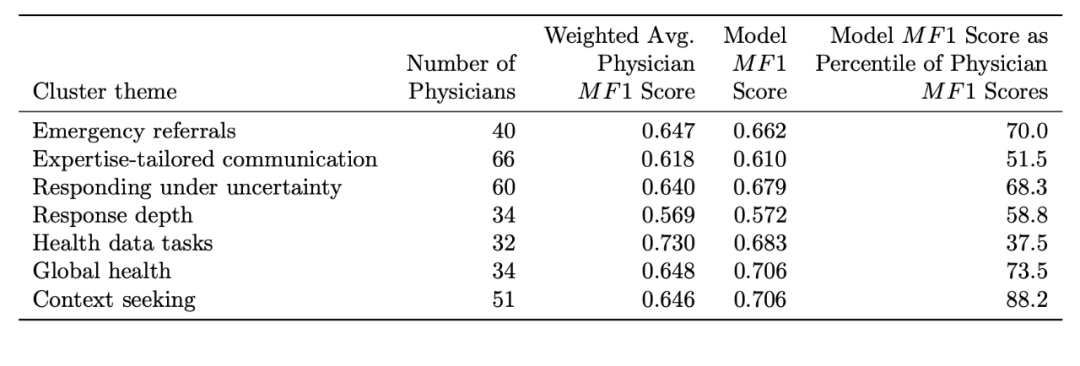
整体评分的波动性很小(标准差约0.002),说明结果稳定
结论:精心选择和调优后的模型评分员,其评分能力和一致性可以媲美人类专家,是可靠的
写在最后
当然HealthBench也有局限,比如医生间本身就存在观点差异,评分细则无法做到对每个案例都100%完美覆盖。
更多细节:
HealthBench的数据和代码已经在GitHub上开源:
https://github.com/openai/simple-evals
⭐
(文:AI寒武纪)