

随着 AI 技术的飞速发展,大语言模型在众多领域展现出了巨大的应用潜力。比如Qwen系列语言模型,各项能力非常出色,其部署与应用受到了广泛关注。然而,如何安全、高效地部署并实现 API 鉴权,成为了众多开发者面临的问题。本文将为您详细讲解基于 ms-swift 部署 Qwen – 7B 并实现 API 鉴权的全流程,帮助您快速上手并构建安全可靠的 AI 应用。
一、环境准备与依赖安装
1. 硬件配置推荐
我们对硬件配置进行了如下推荐,以满足不同需求和场景下的部署要求:
| 组件 | 最低配置 |
|
| GPU |
|
|
| 显存需求 | ≥20GB | ≥40GB(支持更高并发) |
| 系统 | Ubuntu 22.04 LTS |
|
-
最低配置:适用于小型开发团队或个人开发者进行初步测试和开发,能够满足基本的模型运行需求,但在处理高并发请求或复杂任务时可能会受到一定限制。
-
推荐配置:适用于企业级应用或对性能有较高要求的场景,能够提供更强大的计算能力、更大的显存容量以及更稳定的系统环境,支持更高的并发量和更复杂的模型推理任务,确保模型在实际应用中能够高效稳定地运行。
2. 核心依赖安装
为了保证后续模型部署和 API 服务的顺利进行,我们需要先安装相关的核心依赖。以下是详细的安装步骤:
# 创建虚拟环境(避免依赖冲突)conda create -n swift python=3.10conda activate swift# 安装 ms-swift 核心组件(集成 vLLM 加速)pip install ms-swift -Upip install vllm
创建虚拟环境的目的是将项目所需的依赖与系统全局环境以及其他项目环境相互隔离,避免不同项目之间的依赖版本冲突,确保项目的稳定性和可维护性。上述命令中 ms-swift 是用于模型部署和管理的核心库,而 vLLM 则为模型推理提供了加速支持,能够提高模型的运行效率和性能。
3. 下载模型权重
模型权重是大语言模型运行的关键部分,我们需要下载 Qwen2.5 – 7B – Instruct 模型的权重文件。执行以下命令进行下载:
modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct该命令通过 modelscope 平台下载指定的 Qwen2.5 – 7B – Instruct 模型,并将其保存到本地的 “/root/autodl – tmp/Qwen/Qwen2.5 – 7B – Instruct” 目录下。下载完成后,我们就可以在本地使用该模型进行部署和推理了。
二、模型部署与 API 服务启动
1. 单卡部署命令解析
以下是单卡部署 Qwen – 7B 模型的命令及其参数解释:
CUDA_VISIBLE_DEVICES=0 swift deploy \--model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct \--infer_backend vllm \--max_new_tokens 2048 \--served_model_name Qwen2.5-7B-Instruct
-
`CUDA_VISIBLE_DEVICES=0`:指定使用第 0 号 GPU 进行模型部署,确保模型能够充分利用 GPU 的计算资源加速推理过程。
-
`–model`:指定模型的本地存储路径,这里填写我们之前下载的 Qwen2.5 – 7B – Instruct 模型所在的目录路径,使 ms-swift 能够找到并加载该模型进行部署。
-
`–infer_backend vllm`:选择 vLLM 作为推理后端,vLLM 是一个高性能的模型推理引擎,能够优化模型的推理流程,提高推理速度和效率,降低推理延迟,从而为用户提供最优质的响应体验。
-
`–max_new_tokens 2048`:设置模型生成文本的最大新 token 数量为 2048,限制了模型一次生成文本的长度,避免模型生成过长的文本导致资源浪费或响应时间过长等问题。
-
`–served_model_name Qwen2.5-7B-Instruct`:为部署的模型服务指定一个名称,便于后续通过 API 进行调用和管理。
当部署成功后,模型会启动一个 API 服务,监听在本地的 8000 端口上,等待接收客户端的请求并返回相应的推理结果。
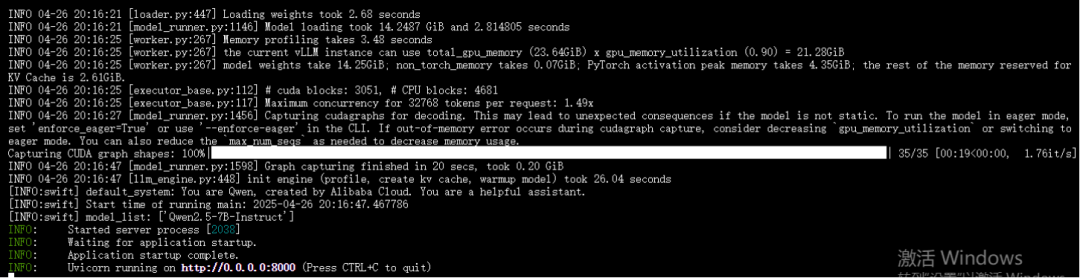
2. 服务验证测试
在模型部署成功后,我们需要对服务进行验证测试,以确保模型能够正常运行并满足预期的要求。
(1)bash 命令脚本调用 API
我们可以使用 bash 命令脚本通过 curl 命令向模型服务发送请求,测试接口的响应情况。以下是示例命令:
# 测试接口响应curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen2.5-7B-Instruct","messages": [{"role": "user", "content": "你好"}]}'
执行上述命令后,如果模型服务正常运行,我们将收到模型返回的响应结果,示例如下:
{"model":"Qwen2.5-7B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"你好!很高兴见到你。有什么我可以帮助你的吗?","tool_calls":null},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":30,"completion_tokens":13,"total_tokens":43},"id":"5390490f80b84a70bb0cd0c69705de87","object":"chat.completion","created":1745669835}从返回结果中可以看到,模型正确理解了用户的问候,并给出了友好且符合语境的回复,说明模型服务已经成功部署并能够正常处理请求。
(2)Python 代码调用
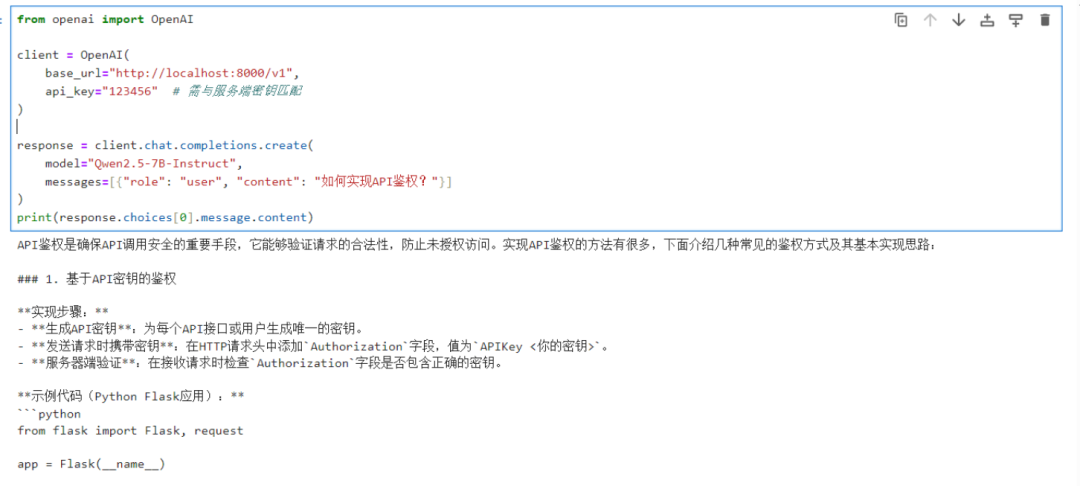
除了使用 bash 命令脚本,我们还可以通过 Python 代码调用模型服务。以下是示例代码:
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1",api_key="123456" # 无需与服务端密钥匹配)response = client.chat.completions.create(model="Qwen2.5-7B-Instruct",messages=[{"role": "user", "content": "如何实现 API 鉴权?"}])print(response.choices[0].message.content)
在代码中,我们配置了一个 api_key(此处 api_key 无需与服务端密钥匹配,因为目前我们尚未启用 API 鉴权功能)。然后,我们调用 chat.completions.create 方法向模型发送请求,请求模型回答如何实现 API 鉴权的问题,并打印出模型返回的回答内容。
三、API鉴权方案设计与实现
为了确保模型服务的安全性,防止未经授权的访问和滥用,我们需要实现 API 鉴权功能。以下是详细的 API 鉴权方案设计与实现步骤:
1. 原生鉴权模块配置
ms-swift 提供了原生的基于 API Key 的访问控制功能,我们可以通过在部署命令中添加 api_key 参数来启用该功能。以下是启用 API 鉴权的部署命令示例:
CUDA_VISIBLE_DEVICES=0 swift deploy \--model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct--infer_backend vllm \--max_new_tokens 2048 \--served_model_name Qwen2.5-7B-Instruct \--api_key "abc@123"
在命令中,我们添加了 `–api_key “abc@123″` 参数,将 API Key 设置为 “abc@123”。这样,当客户端向模型服务发送请求时,必须在请求头中包含该 API Key,服务端会对请求中的 API Key 进行验证,只有验证通过的请求才会被处理,否则将返回 403 禁止访问的错误响应。
2. 客户端调用示例一(失败示例)
为了更直观地展示 API 鉴权的效果,我们提供了以下两个客户端调用示例:
(1)命令行调用示例
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen2.5-7B-Instruct","messages": [{"role": "user", "content": "你好"}]}'
API调用返回如下:
{"message":"API key error","object":"error"}(2)Python 代码调用示例
在以下 Python 代码示例中,我们故意使用了一个与服务端密钥不匹配的 api_key 来调用模型服务:
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1",api_key="123456" # 随意配置不与服务端密钥匹配的 api_key)response = client.chat.completions.create(model="Qwen2.5-7B-Instruct",messages=[{"role": "user", "content": "如何实现 API 鉴权?"}])print(response.choices[0].message.content)
执行该代码后,由于客户端提供的 api_key 与服务端配置的 api_key 不匹配,模型服务将拒绝处理该请求,并返回以下错误信息:
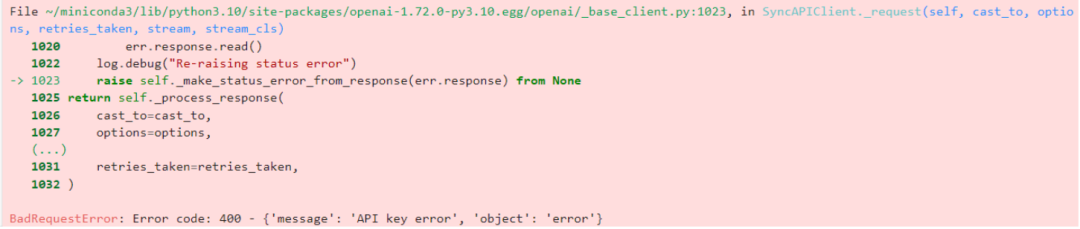
这表明 API 鉴权机制已经成功阻止了未经授权的访问请求。
2. 客户端调用示例二(成功示例)
为了更直观地展示 API 鉴权的效果,我们提供了以下两个客户端调用示例:
(1)命令行调用示例
这里我们通过Authorization传递密钥
curl -X POST http://localhost:8000/v1/chat/completions \-H "Authorization: Bearer abc@123" \-H "Content-Type: application/json" \-d '{"model": "Qwen2.5-7B-Instruct","messages": [{"role": "user", "content": "你好"}]}'
API调用返回如下:
{"model":"Qwen2.5-7B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"你好!有什么问题我可以帮助你解答吗?","tool_calls":null},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":30,"completion_tokens":11,"total_tokens":41},"id":"f06de9b85c204646ab813fd6adf08142","object":"chat.completion","created":1745673594}(2)Python 代码调用示例
接下来,我们在客户端调用中使用与服务端密钥匹配的 api_key,以成功获取模型的响应。以下是示例代码:
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1",api_key="abc@123" # 配置与服务端密钥匹配的 API KEY)response = client.chat.completions.create(model="Qwen2.5-7B-Instruct",messages=[{"role": "user", "content": "如何实现 API 鉴权?"}])print(response.choices[0].message.content)
执行该代码后,模型服务将验证客户端提供的 api_key,确认其与服务端配置的 api_key 一致后,正常处理请求并返回以下结果:
“`
API鉴权是确保API安全的重要措施,常见的实现方式包括但不限于以下几种:
1. **API密钥(API Key)**:这是最简单直接的一种方式。每个开发者或客户端都会分配一个唯一的API密钥,通过在请求中包含这个密钥来验证请求的合法性。
2. **OAuth 2.0**:这是一种开放标准,用于授权应用程序访问受保护的数据。它支持多种授权模式,包括客户端认证、资源所有者密码凭证、授权码等。OAuth 2.0可以提供更细粒度的权限控制,并且更加安全。
3. **Token-Based Authentication**:通过生成一个token,客户端在每次请求时都需要携带这个token。服务器端需要验证这个token的有效性。常见的token实现有JWT(JSON Web Token)、OAuth 2.0 Access Token等。
4. **签名认证**:通过在请求中加入一些参数(如时间戳、随机数等),并使用特定算法(如HMAC、RSA等)对这些参数进行签名,然后将签名也发送到服务器。服务器收到请求后,会根据同样的算法重新计算签名并与客户端提供的签名对比,以此来判断请求是否有效。
5. **基于IP地址的限制**:虽然这种方式不够灵活,但可以通过限制API只能被特定的IP地址访问来增加安全性。
6. **其他自定义方案**:企业可以根据自己的需求开发定制化的鉴权机制,比如基于角色的访问控制(RBAC)、基于策略的访问控制(PBA)等。
实现API鉴权时,还需要考虑以下几个方面:
– **安全性**:确保使用的鉴权方式足够安全,能够抵御常见的攻击手段。
– **灵活性**:不同的应用场景可能需要不同的鉴权策略,选择易于扩展和修改的方案。
– **性能**:鉴权过程不应成为系统性能瓶颈,尤其是在高并发场景下。
– **用户体验**:尽量减少不必要的复杂性和用户负担,使API的使用尽可能便捷。
具体实现时,可以根据项目的需求和条件选择合适的方法,并结合使用多种鉴权方式以提高系统的整体安全性。
“`
从返回结果中可以看到,模型详细地回答了如何实现 API 鉴权的问题,这说明当客户端提供了正确的 api_key 时,模型服务能够正常接收请求并返回准确的响应,API 鉴权机制在保障服务安全的同时,并未对正常用户的访问造成影响。
3. 高级安全策略(企业级方案)
除了基本的 API Key 鉴权方式外,对于企业级应用,我们还可以采用更高级的安全策略来进一步增强 API 的安全性。
(1)自定义鉴权中间件
如果默认的 API Key 鉴权方式不能满足企业的特定需求,我们可以自定义鉴权中间件。以下是自定义鉴权中间件的实现步骤和代码示例:
# 自定义鉴权中间件(需修改 swift 源码)from fastapi import HTTPException, Requestasync def auth_middleware(request: Request):api_key = request.headers.get("Authorization")if api_key not in valid_keys:raise HTTPException(status_code=403, detail="Invalid API Key")return await call_next(request)# 可基于 /swift/llm/infer/deploy.py 中的源码修改定制app.add_middleware(auth_middleware)
在上述代码中,我们首先定义了一个名为 auth_middleware 的异步函数,该函数接收一个请求对象作为参数。在函数内部,我们从请求头中获取 Authorization 字段的值,即客户端提供的 API Key,然后将其与预先定义的有效 API Key 列表 valid_keys 进行比对。如果 API Key 不在有效列表中,则抛出一个 HTTPException 异常,状态码为 403,表示禁止访问,并返回详细的错误信息。如果 API Key 验证通过,则继续调用 call_next(request) 处理后续的请求流程。
(2)安全增强建议
为了进一步提升 API 的安全性,我们提出以下安全增强建议:
-
定期轮换 API 密钥(建议每月更新):定期更换 API 密钥可以降低密钥泄露后被恶意利用的风险,即使旧的密钥被窃取,在下次轮换后也会失去效力,从而保护了 API 服务的安全性。
-
结合 Nginx 配置 IP 白名单限制:通过在 Nginx 服务器上配置 IP 白名单,限制只有特定 IP 地址的客户端能够访问 API 服务,进一步缩小了攻击面,降低了未授权访问的可能性。
-
启用 HTTPS 加密通信(使用 Let’s Encrypt 免费证书):启用 HTTPS 协议可以对客户端与服务器之间的通信数据进行加密,防止中间人攻击和数据窃听,保护 API 请求和响应内容的安全性。可以使用 Let’s Encrypt 提供的免费 SSL/TLS 证书来实现 HTTPS 加密,操作简单且成本较低。
四、总结
本文详细介绍了基于 ms-swift 部署 Qwen – 7B 模型并实现 API 鉴权的全流程。从环境准备与依赖安装,到模型部署与 API 服务启动,再到 API 鉴权方案的设计与实现,包括原生 API Key 鉴权、自定义鉴权中间件以及高级安全策略等内容,为开发者提供了一套完整、实用的技术指南。希望本文能够为您的 AI 项目开发提供有价值的参考和帮助。
(文:小兵的AI视界)