

极市导读
在人脸识别领域,闭集标签噪声一直是影响模型性能的棘手问题。本文介绍的RepFace框架,通过辅助样本清洗、鲁棒标签融合和平滑标签矫正三大模块,有效提升了模型对闭集噪声的鲁棒性,显著增强了人脸识别的精度和可靠性,为该领域的研究和应用带来了新的突破。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
题目:RepFace: Refining Closed-Set Noise with Progressive Label Correction for Face Recognition
RepFace:渐进式人脸识别闭集噪声标签矫正框架
作者:Jie Zhang, Xun Gong, Zhonglin Sun
论文创新点
1.辅助样本清洗模块的提出:作者提出了辅助样本清洗模块对标签噪声进行检测,并在模型训练前期通过该模块只训练干净样本,为模型训练后期对标签噪声的检测和矫正提出更加高效的性能。
2.鲁棒性标签融合模块的提出:对于难以识别的噪声样本,作者引入了标签融合机制,充分利用了模型对图片的识别性能,进一步提升了模型的鲁棒性。
3.平滑标签矫正模块的提出:作者采用了更加适合该框架的噪声检测和矫正方法,使模型在矫正标签的同时尽量减少误判的负面影响。
摘要
数据集中的标签噪声,尤其是闭集标签噪声,极大地影响了人脸识别模型的性能。尽管已有许多研究致力于处理标签噪声问题,闭集标签噪声的矫正仍然面临诸多挑战。为此,我们提出了一种鲁棒的标签矫正框架专门针对人脸识别任务。该框架显著增强了模型在训练早期的稳健性,并针对不同置信度的样本制定了个性化的学习策略。具体而言,框架通过生成辅助闭集噪声样本,在训练初期有效识别标签噪声。随后,根据样本与ground-truth中心及最近负类中心的距离关系,将样本分为干净样本、模糊样本与噪声样本,并采用不同的训练策略。对于模糊样本,我们引入了标签融合机制,以提升标签的准确性;而对于噪声样本,则应用标签平滑技术进行矫正。大量实验结果表明,该方法在多个主流人脸数据集上取得了最先进的效果,显著提升了模型的识别精度和鲁棒性。
关键词:人脸识别·标签噪声·标签矫正·标签融合
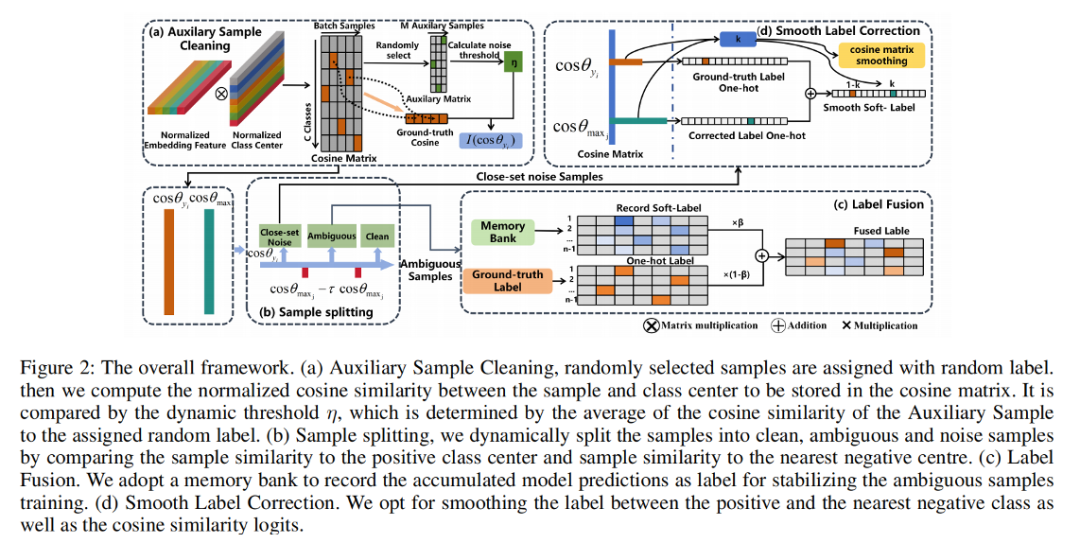
方法
基于样本特征与ground-truth中心及最近负类中心之间的余弦相似度关系,我们将样本划分为干净样本、闭集噪声样本和模糊样本。针对不同类型的样本,我们设计了相应的训练策略,以提高模型的性能与鲁棒性。
辅助样本清洗模块
我们在训练过程中随机抽取 M 个样本,并为它们赋予随机标签,以模拟标签噪声的存在。随后,我们通过计算这些样本与其随机标签对应类别之间的余弦相似度来确定筛选阈值。
其中 表示随机标签对应的余弦值, 表示一个稳定的超参数。然后我们将训练样本的 ground-truth 标签对应的余弦相似度与该阈值进行比较,如果大于该值我们认为是干净样本,如果小于该值则认为是噪声样本。这里我们通过一个指示器来进行筛选。
其中 表示 ground-truth 类对应的余弦值。如果该值为 0 则表示不进行训练,为 1 则表示训练。通过辅助样本进行标签噪声清洗,使模型专注于干净样本的训练,从而在后期训练中显著提升对标签噪声的检测和矫正性能。
鲁棒标签融合模块
对于模糊样本,由于无法明确判断它们是干净样本还是噪声样本,我们充分利用了模型的识别性能。如图1中的(c)所示,在训练过程中,我们会将样本的最大余弦值及其对应的类别记录到memory bank中。如果记录的类别与之前存储的类别不同,则直接存储;如果相同,则通过以下公式进行更新:
其中 表示的是记录的最大余弦相似度, 表示最大的余弦相似度。然后我们将记录信息生成的标签与 ground-truth 标签融合。
其中, 表示融合后的标签, 表示记录的信息生成的标签, 表示 ground-truth 标签, 为超参数。通过依赖模型的预测信息进行标签融合,如果样本是干净样本,那么记录的信息生成的标签与 ground-truth 标签一致,融合后的标签将与原标签相同;反之,则起到软矫正的作用。通过这种标签融合策略,我们充分利用模型的识别能力来有效训练这些模糊样本。
平滑标签矫正模块
对于噪声样本,如图1中的(b)所示,我们首先根据样本特征与最近负类和ground-truth标签之间的余弦相似度差值来计算平滑参数 k=sigmoid(10⋅d)。由于数据集中可能存在困难样本,在训练过程中,我们采用了MV-Softmax[7]方法来检测和处理这些困难样本:
其中的参数与MV-Softmax中的参数一致。在标签矫正过程中我们同样会对困难样本进行平滑加权操作:
其中 表示最近负类的加权方式,表示ground-truth标签对应的加权方式,k表示平滑参数。最后,对于标签矫正,我们同样是将样本的标签矫正为最近负类,然后根据平滑参数k对标签进行平滑矫正:
其中 表示平滑矫正后的标签, 表示最近负类的标签, 表示 ground-truth 标签。我们通过平滑标签矫正,能够最大程度矫正噪声样本的同时减小矫正错误带来的风险。我们最终的损失函数如下所示:

其中, 表示在辅助样本清洗模块中计算的指示器, 表示未对余弦矩阵进行平滑的概率, 表示经过余弦矩阵平滑后的概率。通过对样本进行分类并采用针对性的训练策略,我们能够更充分地利用数据集中的样本,同时提升模型对闭集标签噪声的鲁棒性。
实验
Table 1: Verification performance (%) of different methods trained on CASIA-WebFace.
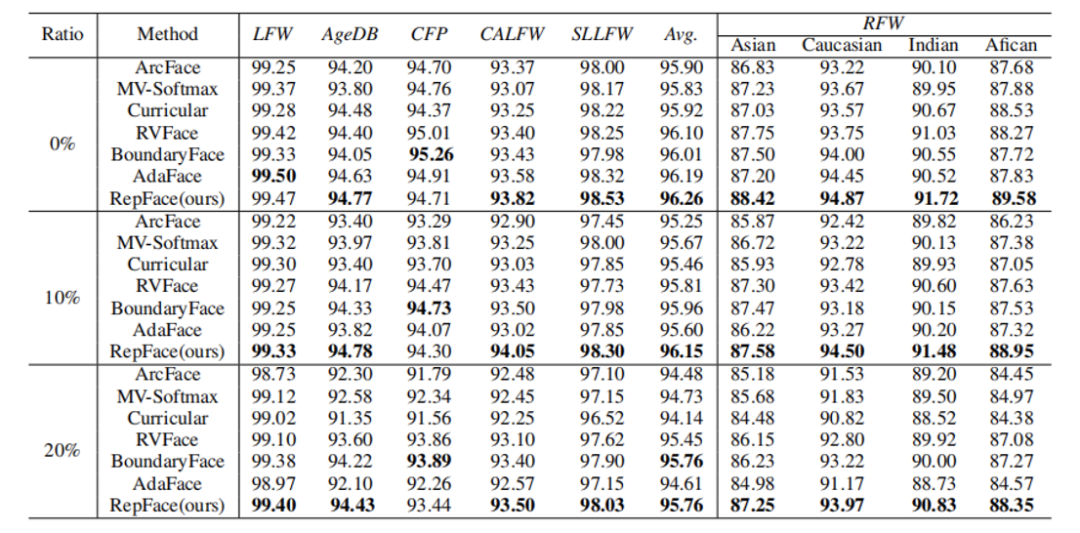
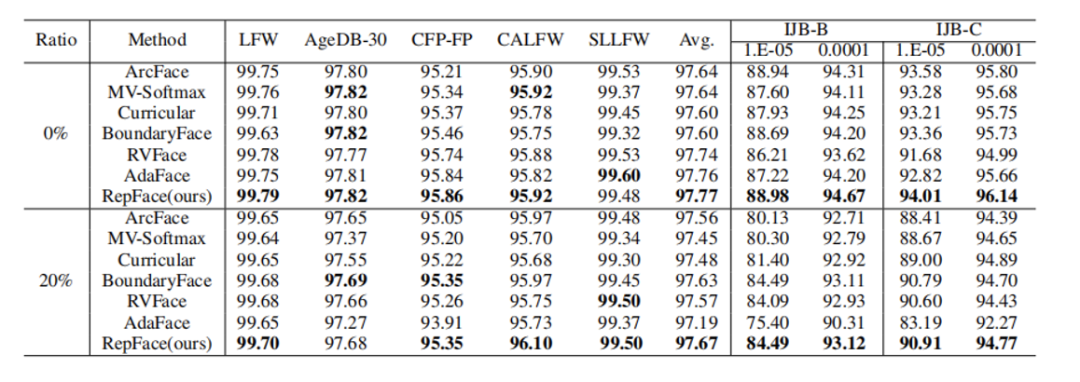
Table 2: Evaluation outcomes for MS1Mv2 Raw Dataset and 20% Closed-Set Noise-Infused Synthetic Dataset.
(文:极市干货)