



模型架构
-
密集模型架构:包含6个密集模型,架构与Qwen2.5相似,包含GQA、SwiGLU、RoPE以及带预归一化的RMSNorm等,移除了QKV-bias,在注意力机制中引入QK-Norm,以确保训练稳定性。
-
混合专家模型架构:包含2个混合专家模型,与密集模型共享基础架构,沿用Qwen2.5-MoE的架构,加入细粒度专家分段设计,共128个专家,每个token激活8个专家,舍弃共享专家模块,采用全局批次负载均衡损失技术促进专家专业化。


预训练
-
预训练数据:与Qwen2.5相比,预训练token数量是之前的两倍,涵盖的语言数量达到其三倍以上,数据集包含119种语言和方言,总计36万亿tokens,涵盖多个领域的高质量内容,通过多种方式扩展预训练语料库,包括使用Qwen2.5-VL模型对文档进行文本识别、利用Qwen2.5模型优化文本、合成多种形式的文本token等。
-
三阶段预训练:
-
通用知识学习阶段:使用4,096 tokens的序列长度,对超过30万亿tokens的数据进行训练,聚焦于语言结构、语法、常识与通用世界知识的学习。
-
推理能力强化阶段:增加STEM、编程、推理和合成数据的比例,使用约5万亿高质量tokens进行进一步预训练,加速学习率的衰减。
-
长上下文扩展阶段:构建专门的高质量长上下文语料库,序列长度最高达32,768个tokens,使用ABF技术提升RoPE的基频,引入YARN和双块注意力机制,提升推理过程中的序列长度容量。
-
预训练结果评估:Qwen3系列的基础语言模型在通用知识、推理能力、数学水平、科学知识、编程能力以及多语言任务等方面表现优异,优于之前的先进开源模型,且在激活参数和总参数较少的情况下,Qwen3的MoE基础模型和密集基础模型均展现出良好的性能。

后训练
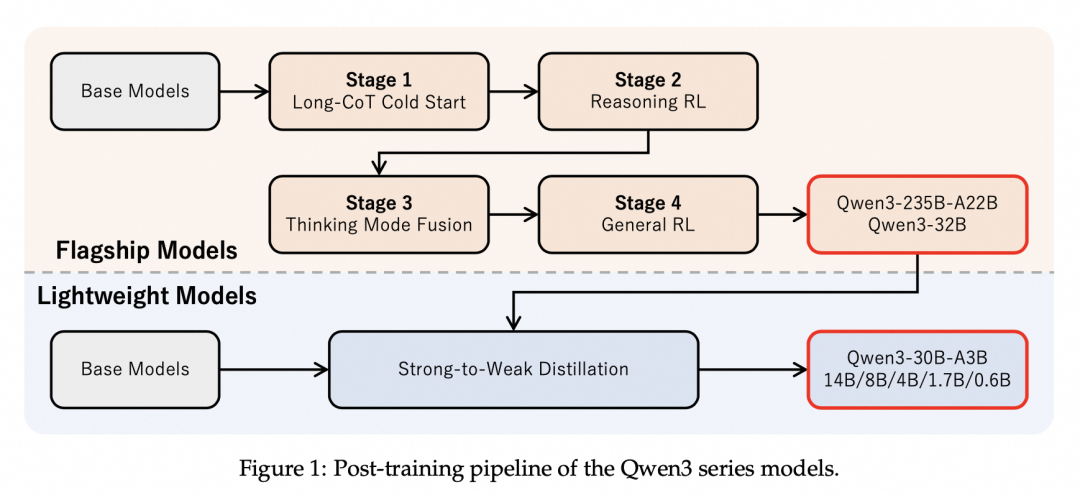
-
四阶段训练:
-
长链式思维冷启动阶段:构建包含数学、代码、逻辑推理和STEM问题的高质量数据集,进行严格的两阶段过滤流程,建立模型的基础推理范式。
-
推理强化学习阶段:收集查询-验证对,采用GRPO方法更新模型参数,通过控制模型的熵值平衡探索与实用之间的关系,提升模型的推理能力。
-
思考模式融合阶段:对推理强化学习模型进行监督微调,设计对话模板融合“非思考”能力,使模型能够在不同思考模式下作出响应,并处理中间情况。
-
通用强化学习阶段:建立复杂的奖励系统,覆盖多种任务,使用三种不同类型的奖励机制,全面增强模型在各种场景下的能力与稳定性。
-
从强到弱蒸馏:涵盖5个密集模型和1个MoE模型,分为Off-policy蒸馏和On-policy蒸馏两个阶段,提升轻量级模型的推理能力,赋予其稳健的模式切换能力。
-
后训练结果评估:旗舰模型Qwen3-235B-A22B展现出当前开源模型中最先进的整体性能,与顶尖闭源模型具有高度竞争力;旗舰密集模型Qwen3-32B在推理能力上优于之前的模型,且在非思考模式下表现出色;轻量级模型在性能上持续优于参数量相近甚至更大的开源模型,验证了强到弱蒸馏方法的有效性。


报告下载:https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
(文:PaperAgent)