



智东西5月15日消息,昨日下午,DeepSeek团队发布新论文,以DeepSeek-V3为代表,深入解读DeepSeek在硬件架构和模型设计方面的关键创新,为实现具有成本效益的大规模训练和推理提供思路。
DeepSeek创始人兼CEO梁文锋这次同样出现在了合著名单之中,出现在倒数第五位(按姓名首字母排序)。论文署名通讯地址为“中国北京”,可以推测论文研究大概率为DeepSeek北京团队主导。

大语言模型的迅猛扩张正暴露出硬件架构的三大瓶颈:内存容量不足、计算效率低下、互连带宽受限。而DeepSeek-V3却实现了令人瞩目的效率突破——
仅在2048块H800 GPU上进行训练,FP8训练的准确率损失小于0.25%,每token的训练成本250 GFLOPS,而405B密集模型的训练成本为2.45 TFLOPS ,KV缓存低至每个token 70 KB(仅为Llama-3.1缓存的1/7)……
这些突破性数据背后,究竟隐藏着怎样的技术革新?
其中的模型架构和AI基础设施关键创新包括:用于提高内存效率的多头潜在注意力(MLA)、用于优化计算-通信权衡的混合专家(MoE)架构、用于释放硬件功能全部潜力的FP8混合精度训练,以及用于最大限度地减少集群级网络开销的多平面网络拓扑。
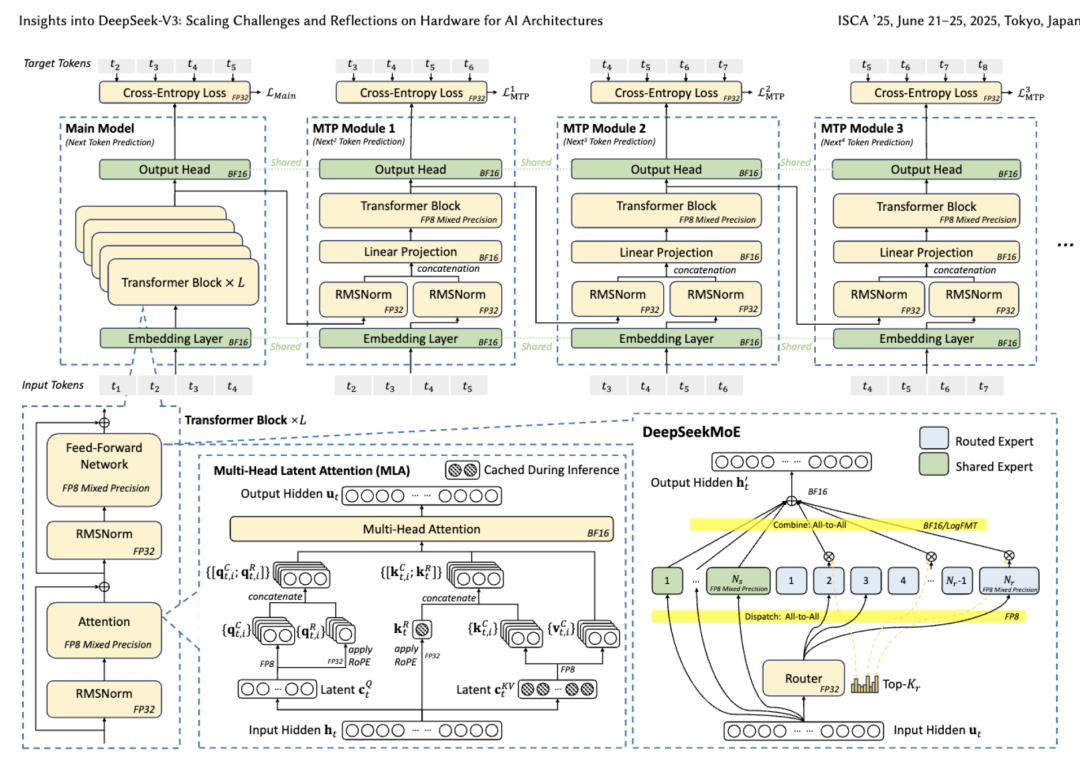
▲DeepSeek-V3基本架构
DeepSeek的论文中验证了,有效的软硬件协同设计可以实现大型模型的成本效益训练,从而为较小的团队提供公平的竞争环境。
DeepSeek在论文中提到,本文的目的不是重申DeepSeek-V3的详细架构和算法细节,是跨越硬件架构和模型设计采用双重视角来探索它们之间错综复杂的相互作用,以实现具有成本效益的大规模训练和推理。侧重于探讨:
硬件驱动的模型设计:分析FP8低精度计算和纵向扩展/横向扩展网络属性等硬件功能如何影响DeepSeek-V3中的架构选择;
硬件和模型之间的相互依赖关系:深入了解硬件功能如何塑造模型创新,以及大模型不断变化的需求如何推动对下一代硬件的需求;
硬件开发的未来方向:从DeepSeek-V3获得可实现的见解,以指导未来硬件和模型架构的协同设计,为可扩展、经济高效的AI系统铺平道路;
论文地址:https://arxiv.org/abs/2505.09343
开篇提到的DeepSeek-V3关键创新旨在解决扩展中的三个核心挑战:内存效率、成本效益和推理速度。
1、内存效率:从源头优化内存使用,使用MLA减少KV缓存
从源头优化内存使用仍然是一种关键且有效的策略。与使用BF16进行权重的模型相比,FP8将内存消耗显著降低了一半,有效缓解了AI内存墙挑战。
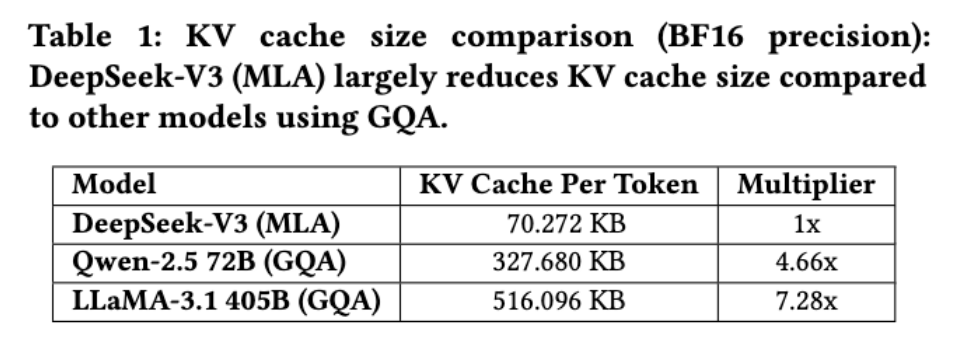
▲KV缓存大小比较(BF16精度)
在每个推理步骤汇总,模型仅计算当前token的键和值向量,并通过将它们与历史记录中缓存的键值对组合来执行注意力计算。这种增量计算使其在处理长序列或多轮输入时非常高效。但是,它引入了内存受限的瓶颈,因为计算从GEMM转移到GEMV,后者的计算与内存比率要低得多。
为了解决这一挑战,研究人员采用MLA,它使用投影矩阵将所有注意力头的KV表示压缩成一个更小的潜在向量,让该矩阵与模型联合训练。在推理过程中,只需要缓存潜在向量,与存储所有注意力头的KV缓存相比减少了内存消耗。
2、成本效益:MoE可降低训练成本,便于本地部署
DeepSeek开发了DeepSeekMoE,MoE模型的优势有两个方面:
首先可以减少训练的计算要求,降低训练成本。MoE模型允许参数总数急剧增加,同时保持计算要求适中。例如,DeepSeek-V2具有236B参数,但每个token只激活了21B参数。DeepSeek-V3扩展到671B参数,同时能将每个token的激活量保持在仅37B。相比之下,Qwen2.5-72B和LLaMa3.1-405B等稠密模型要求所有参数在训练期间都处于活动状态。
其次,是个人使用和本地部署优势。在个性化Agent蓬勃发展的未来,MoE模型在单请求场景中提供了独特的优势。由于每个请求只激活了一个参数子集,因此内存和计算需求大大减少。例如,DeepSeek-V2(236B参数)在理过程中仅激活21B参数。这使得配备AI芯片的PC能够实现每秒近20个token(TPS),甚至达到该速度的两倍。相比之下,具有相似能力的稠密模型在类似硬件上通常只能达到个位数的TPS。
同时,大语言模型推理优化框架KTransformers允许完整版DeepSeek-V3模型在配备消费类GPU的低成本服务器上运行,成本约为10000美元,实现近20 TPS。这种效率使MoE架构适用于硬件资源有限的本地部署和个人用户。
1、重叠计算和通信:最大化吞吐量
推理速度包括系统范围的最大吞吐量和单个请求延迟,为了最大限度地提高吞吐量,DeepSeek-V3从一开始就被构建为利用双微批处理重叠,将通信延迟与计算重叠。
DeepSeek将MLA和MoE的计算解耦为两个不同阶段。当一个微批处理执行MLA或MoE计算的一部分时,另一个微批处理同时执行相应的调度通信。相反,在第二个微批处理的计算阶段,第一个微批处理经历组合通信步骤。
这种流水线化方法实现了全对全通信与正在进行的计算的无缝重叠,确保始终能充分利用GPU资源。
此外,在生产中,他们采用预填充-解码分离(prefill-decode disaggregation)架构,将大批量预填充和延迟敏感的解码请求分配给不同的专家并行组。
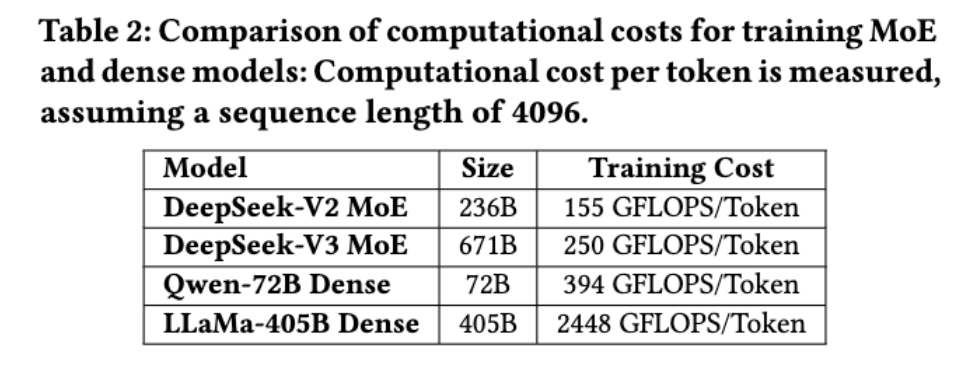
▲训练MoE和稠密模型的计算成本比较:假设序列长度为4096,测量每个token的计算成本
2、推理速度限制:高带宽纵向扩展网络潜力
MoE模型实现高推理速度取决于跨计算设备高效部署专家参数。为了实现尽可能快的推理速度,理想情况下,每个设备都应该为单个专家执行计算或者多个设备应在必要时协作计算单个专家。
但专家并行(EP)需要将token路由到适当的设备,这涉及跨网络的多对多通信。因此,MoE推理速度的上限由互连带宽决定。
考虑这样一个系统:每个设备都保存一个专家的参数,一次处理大约32个token。此token计数在计算内存比率和通信延迟之间取得平衡,此token计数可确保每个设备在专家并行期间处理相等的批量大小,从而计算通信时间。
如果使用像GB200 NVL72(72个GPU上的900GB/s单向带宽)这样的高带宽互连,每个EP步骤的通信时间=(1字节+2字节)×32×9×7K/900GB/s=6.72μs
假设计算时间等于通信时间,这将显著减少总推理时间,从而实现超过0.82毫秒TPOT的理论上限,大约每秒1200个token。
虽然这个数字是理论上得出,尚未经过实证验证,但它说明了高带宽纵向扩展网络在加速大规模模型推理方面的潜力。
3、多token预测(Multi-Token Prediction)
DeepSeek-V3引入了多token预测(MTP)框架,该框架同时增强了模型性能并提高了推理速度。
推理过程中,传统的自回归模型在解码步骤中生成一个token,这会导致序列瓶颈问题。MTP通过使模型能够以较低成本生成额外的候选token并对其进行并行验证,从而缓解了这一问题,这与之前基于自起草的推测性解码方法类似。该框架在不影响准确性的前提下加快了推理速度。
此外,通过预测每步多个token,MTP增加了推理批量大小,这对于提高EP计算强度和硬件利用率至关重要。
4、推理模型的高推理速度与测试时扩展的研究
以OpenAI的o1/o3系列为例,大模型中的测试时缩放通过在推理过程中动态调整计算资源,在数学推理、编程和一般推理方面实现性能提升。后续DeepSeek-R1、Gemini 2.5 Pro、Qwen3都采用了类似的策略。
对于这些推理模型,高token输出速度至关重要。在强化学习(RL)工作流程中,快速生成大量样本的必要性使推理吞吐量成为一个关键的瓶颈。同样,延长的推理序列会增加用户的等待时间,从而降低此类模型的实际可用性。
因此,通过协同硬件和软件创新来优化推理速度对于提高推理模型的效率必不可少。
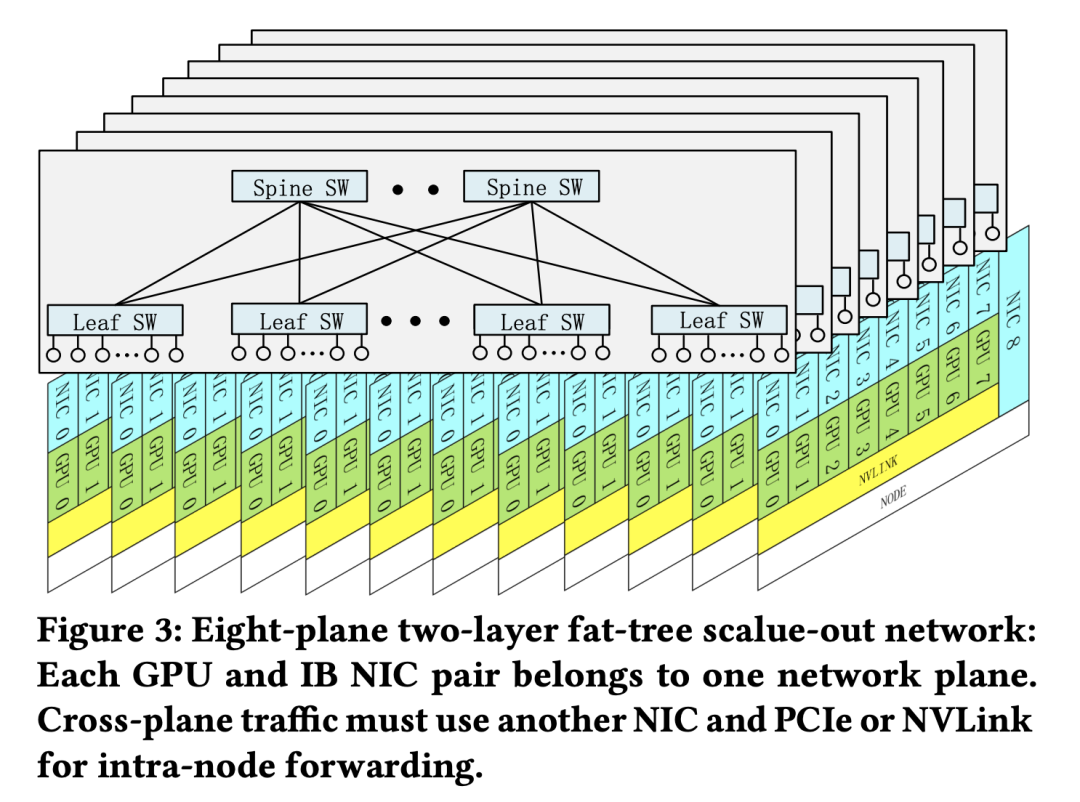
▲八平面两层胖树可扩展网络
(文:智东西)