


李晓熙目前就读于中国人民大学高瓴人工智能学院,博士二年级,导师为窦志成教授,研究方向主要包括检索增强生成、大语言模型推理等。在国际顶级会议和期刊如 AAAI,SIGIR,TOIS 等发表多篇论文,代表工作包括 Search-o1, WebThinker, RetroLLM, GenIR-Survey, CorpusLM, UniGen 等。共同第一作者还包括人大高瓴博士生金佳杰和董冠廷。本文的通信作者为人大窦志成教授。
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。WebThinker 集成了深度网页探索器,使 LRM 能自主搜索、导航并提取信息;自主思考 – 搜索 – 写作策略无缝融合推理、信息收集与实时报告写作;并结合强化学习训练优化工具调用。实验表明,WebThinker 在 GPQA、GAIA、WebWalkerQA、HLE 等复杂推理基准及 Glaive 研究报告生成任务中展现出强大性能,显著提升了 LRM 在复杂场景下的适用性与可靠性,为构建更强大、通用的深度研究系统奠定了坚实基础。

-
论文标题: WebThinker: Empowering Large Reasoning Models with Deep Research Capability
-
论文链接: https://arxiv.org/abs/2504.21776
-
代码仓库: https://github.com/RUC-NLPIR/WebThinker
Demo
1. OpenAI 有哪些模型?它们有什么区别?
2. 2025 年我能投稿哪些 AI 顶会?
研究动机:赋予推理模型深度研究能力
大型推理模型如 OpenAI-o1 和 DeepSeek-R1 在数学、编程和科学等领域展现了卓越的推理能力。然而,当面对需要广泛获取实时网络信息的复杂任务时,这些仅依赖内部参数知识的模型往往力不从心。特别是在需要深度网络信息检索和生成全面、准确的科学报告时,这一局限性尤为明显。
WebThinker 应运而生,它是一个深度研究智能体,使 LRMs 能够在推理过程中自主搜索网络、导航网页,并撰写研究报告。这种技术的目标是革命性的:让用户通过简单的查询就能在互联网的海量信息中进行深度搜索、挖掘和整合,从而为知识密集型领域(如金融、科学、工程)的研究人员大幅降低信息收集的时间和成本。
推理中自主调用工具:摆脱传统预定义 RAG 工作流
现有的开源深度搜索智能体通常采用检索增强生成(Retrieval-Augmented Generation, RAG)技术,依循预定义的工作流程,这限制了 LRM 探索更深层次网页信息的能力,也阻碍了 LRM 与搜索引擎之间的紧密交互。
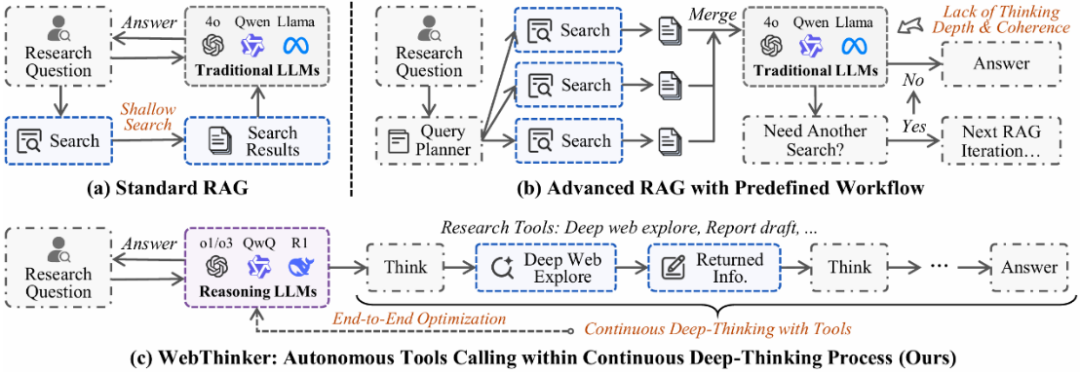
WebThinker 突破了传统 RAG 工作流的限制,实现了范式的升级:
1. 传统 RAG: 仅进行浅层搜索,缺乏思考深度和连贯性
2. 进阶 RAG: 使用预定义工作流,包括查询拆解、多轮 RAG 等,但仍缺乏灵活性
3. WebThinker: 在连续深思考过程中自主调用工具,实现端到端任务执行
WebThinker 使 LRM 能够在单次生成中自主执行操作,无需遵循预设的工作流程,从而实现真正的端到端任务执行。
WebThinker 框架:自主的深度搜索与报告撰写

WebThinker 框架包含两种主要运行模式:
1. 问题解决模式:赋予 LRM 深度网页探索器(Deep Web Explorer)功能,当遇到知识缺口时,LRM 可以自主发起网络搜索,通过点击链接或按钮导航网页,并在继续推理前提取相关信息。
2. 报告生成模式:实现自主思考 – 搜索 – 写作(Autonomous Think-Search-and-Draft)策略,将推理、信息搜索和报告撰写无缝整合。LRM 可以使用专门的工具来草拟、检查和编辑报告部分,确保最终报告全面、连贯且基于收集的证据。
整个过程是端到端的,LRM 可以在思考过程中自主搜索、深度探索网页和撰写研究报告,摆脱了传统预定义工作流的局限。
核心组件:
1. 深度网页探索:解决复杂推理问题
这一模块使 LRM 能够进行网络搜索和导航,深度收集、遍历和提取网页上的高质量信息:
1. 搜索能力:能够基于当前查询生成搜索意图,从搜索引擎获取初步结果
2. 导航能力:能够点击链接或按钮,深入探索初始搜索结果之外的内容
3. 信息提取:基于当前查询的搜索结果,LRM 可以发起后续搜索并遍历更深层次的链接,直到收集所有相关信息
2. 自主的思考 – 搜索 – 写作:生成完整的研究报告
该策略将报告撰写与 LRM 的推理和搜索过程深度整合:不同于在搜索后一次性生成整个报告,WebThinker 使模型能够实时撰写和寻求必要知识。具体来说,WebThinker 为 LRM 配备三种专门工具:(1)撰写特定章节内容;(2)检查当前报告已写内容;(3)编辑 / 修改报告。这些工具使 LRM 能够通过保持全面性、连贯性和对推理过程中新发现信息的适应性来自主增强报告质量
3. 基于强化学习的训练策略:全面提升 LRM 调用研究工具的能力
为了进一步释放 LRM 骨干模型的深度研究潜力,WebThinker 开发了基于强化学习的训练策略:
1. 利用配备工具的 LRM 从复杂任务中采样大规模推理轨迹
2. 根据推理的准确性、工具使用准确性、以及最终输出答案或报告的质量,构建在线直接偏好优化(DPO)训练的偏好对
3. 通过迭代、在线策略训练,模型逐步提高感知、推理和有效交互研究工具的能力
实验结果

实验结果:真实世界的复杂推理任务
WebThinker 在四个知识密集型复杂推理基准上进行了评估:
1. GPQA:PhD 级别的科学问题回答数据集,覆盖物理、化学和生物学
2. GAIA:评估 AI 助手在复杂信息检索任务上的能力
3. WebWalkerQA:专注于深度网络信息检索,需要导航和提取信息
4. 人类最终考试(HLE):极具挑战性的跨学科问题数据集


从实验结果中可以发现:
1. 基础推理模型和传统 RAG 的局限:基础推理模型虽然在某些任务上表现不错,但在需要实时外部知识的场景中明显力不从心;传统 RAG 方法虽有改进,但在复杂任务中提升有限;
2. 自主搜索的优势:而引入自主搜索能力的模型则带来了显著提升。WebThinker 凭借其深度网页探索器,能够更全面地获取和整合网络信息,在所有基准测试中都取得了明显优势。
3. RL 训练的改进:特别是经过强化学习训练的 WebThinker-32B-RL 版本,不仅在同等参数量模型中达到了最佳表现,甚至在某些任务上超越了参数量更大的专有模型。
实验结果:科学研究报告生成
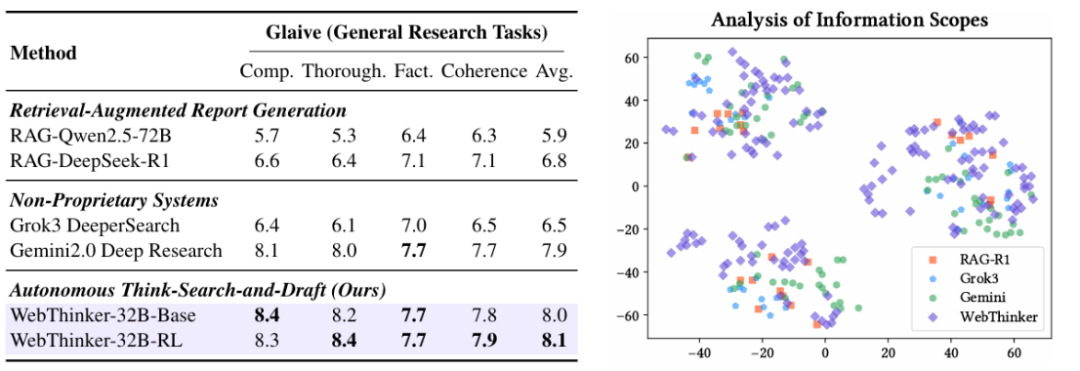
在 Glaive 科学报告生成任务的评估中:
1. 生成报告的质量:从完整性、彻底性、事实性和连贯性四个维度评估,WebThinker 生成的研究报告均获得高分,整体表现优于传统 RAG 方法和其他先进的深度研究系统;
2. 生成报告的信息边界:特别在报告的完整性和彻底性方面表现尤为突出,通过 t-SNE 可视化分析可见,WebThinker 生成的报告内容覆盖更广,视角更多元,能够从多个维度深入探索和综合信息,为用户提供更全面、更深入的调研。
实验结果:适配 DeepSeek-R1 系列模型

通过在不同规模的 DeepSeek-R1 模型上进行实验(7B, 14B, 32B),验证了 WebThinker 框架的适应性。在不同模型规模下,都能显著提升各类任务的性能,远超直接推理和标准 RAG 方法,展现了该框架在增强 LRM 深度研究能力方面的通用性和有效性。
实验结果:消融实验

消融实验评估了 WebThinker 各关键组件的贡献。结果显示,深度网页探索器以及自主 「思考 – 搜索 – 写作」 策略中的报告生成组件(尤其是自主报告起草)是确保高性能问题解决和高质量报告生成的基石,其缺失会导致性能显著下降。强化学习训练则主要增强了问题解决能力,对报告生成的影响相对有限。
总结与未来展望
WebThinker 框架成功地赋予了大型推理模型深度研究能力,解决了它们在知识密集型真实世界任务中的局限性。通过深度网页探索器和自主思考 – 搜索 – 写作策略,WebThinker 使 LRM 能够自主探索网络并通过连续推理过程生成全面输出。
未来,为持续提升深度研究模型的能力,仍有很多方向值得探索:
1. 多模态深度搜索:WebThinker 基于文本推理模型,难以处理图像等其他模态的信息。未来可以扩展到图像、视频等多模态内容的深度研究,来利用网页中的多模态信息。
2. 工具学习与扩展:当前支持有限的研究工具,未来可以通过工具学习来不断优化工具使用策略,并扩展更多工具,来支持更复杂的任务。
3. GUI 网页探索:通过 GUI 网页探索能力,让模型能够更好地理解和操作网页界面,实现更复杂的交互任务,如订机票、指定旅游路线图、等等。

©
(文:机器之心)