

新智元报道
新智元报道
【新智元导读】理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
得益于大语言模型强大的文本理解与生成能力,用户可以用「自然语言」来操控其他模态的模态,比如用文本生成图片、视频等。
之前的多模态大语言模型(MLLM)更倾向于专用,比如只能用于某一种模态,或只能用于训练指定的任务,最近的研究趋势开始向多模态通才(Multimodal Generalist)范式转变,不仅能理解多种模态,还能跨模态生成内容,甚至支持任意模态。

为了评估多模态大语言模型的能力,研究人员推出了各种各样的基准测试集以供模型刷榜。
但是,能否简单地认为,在各项任务中表现更好的模型,就说明具备更强的多模态通用能力,从而更接近人类水平的人工智能呢?
想要回答这个问题,可能没有想象中那么简单。
最近,来自新加坡国立大学(NUS)、南洋理工大学(NTU)、浙江大学、北京大学、南京大学、武汉大学、上海交大等十所顶尖高校联合发布了一个评估框架General-Level和一个庞大的基准数据集General-Bench,用305页论文,明确了多模态通用智能体在不同发展阶段应该具备的能力和行为。

论文链接:https://arxiv.org/pdf/2505.04620v1
项目主页:https://generalist.top
排行榜:https://generalist.top/leaderboard
基准:https://huggingface.co/General-Level
General-Level建立了五个层级的多模态大语言模型性能和通用性标准,提供了一种方法来比较多模态大语言模型,并衡量现有系统向更强大的多模态通用智能体以及最终向通用人工智能(AGI)发展的进程。

框架的核心是使用「协同泛化效应」(Synergy)作为评估标准,根据多模态大语言模型在理解与生成过程中,以及在多模态交互中是否保持协同性来对能力进行分类。
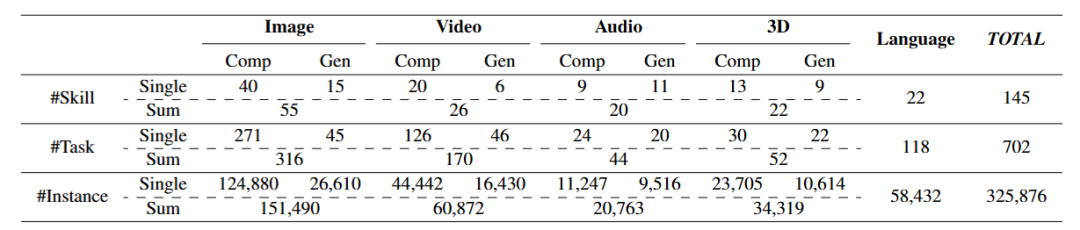
General-Bench涵盖了比以往基准更广泛的技能、模态、格式和能力,包括超过700项任务和325800个样本,对100多个现有的最先进的多模态大语言模型的评估结果显示了这些通用智能体的能力排名,总结出了当下模型与真正人工智能相比仍有哪些不足。


观察1:多模态理解 vs. 同时进行多模态理解和生成
最初阶段,多模态大语言模型(MLLMs)的回复仅限于基于用户提供的多模态输入生成文本输出;后续的多模态大语言模型不仅具备多模态理解能力,还能在各种模态之间生成、编辑内容。
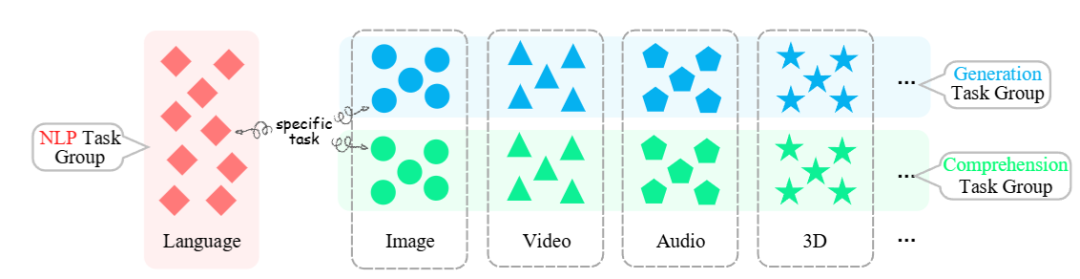
观察2:支持更广泛的模态
多模态通才需要广泛支持和处理多种模态数据,包括但不限于文本、图像、视频、音频,甚至是三维数据,支持的模态范围反映了一个人工智能系统能力的广度。
到目前为止,多模态模型可以将图像与视频结合、视频与音频结合等,最先进的模型甚至可以处理任意模态。
观察3:支持各种任务和范式
多模态通才必须能够处理各种不同定义和要求的任务,来提高整体的多功能性。
例如,早期的视觉多模态大语言模型只能进行粗粒度的图像理解,后续发布的模型能够实现细粒度、像素的图像/视频定位和编辑等。
模型的解码组件也必须足够灵活,能够以各种任务格式生成输出,处理不同类型的任务,例如目标定位、像素级修改以及多模态内容创作。
观察4:多模态智能体与多模态基础模型
刚开始的多模态智能体,就是大语言模型通过调用外部工具和模块(通常是专用模型)来执行特定的多模态任务。
后续的研究重点逐渐转向构建联合多模态大语言模型,其中大语言模型与其他模块(如多模态理解组件和多模态生成组件)通过共享嵌入空间紧密集成。
五大分类
判断一个多模态通用模型是否更强大,不能简单地等同于在基准测试中获得更高的分数,或者与其他模型相比支持尽可能多的多模态任务。
一个极端的反例是,虽然理论上可以通过组合所有单一模态的最先进的专业模型来创建一个「超级智能体」,但这种简单的聚合并不能实现真正的通用人工智能(AGI)。
理想中的多模态通用模型应该是一个类似OpenAI的ChatGPT系列的多模态版本,不仅在各种模态的任务表现上超越最先进的专业模型,还展现出卓越的跨任务、跨理解与生成以及跨模态的泛化能力。
换句话说,从某些任务、技能和模态中学到的知识应该能够迁移到其他任务、技能和模态中,从而产生一种协同效应,使得整体效果超过各个部分的总和,实现「1+1>2」的效果。
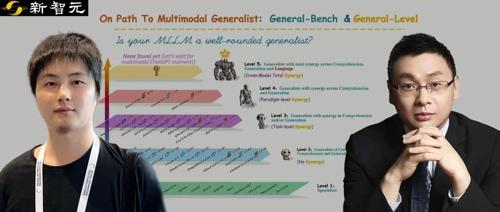
General-Level借鉴了自动驾驶分级评估的思路,以五个段位(Level 1-5)对多模态通用模型的智能水平进行评定。
段位越高,表示模型展现的通才智能越强。
与传统只看任务分数不同,General-Level引入了协同泛化效应(Synergy)作为评分核心,具体从三个层次评估模型的协同能力:
• 任务级协同(Task-level Synergy):「任务-任务」的协同效应。模型能否在不同任务之间实现知识迁移?例如,在图像分类上学到的特征是否有助于目标检测任务。这是最低级别的协同要求。
• 范式级协同(Paradigm-level Synergy):「理解-生成」的协同效应。模型是否能跨任务范式(理解类任务与生成类任务)保持均衡且互相提升的性能?例如,一个模型既能看图回答问题(理解类),又能根据图像生成描述(生成类),且两种能力互不拖后腿。
• 模态级协同(跨模态总协同, Cross-modal Synergy):「模态-模态」的协同效应。模型是否能在不同模态之间实现真正的融会贯通?也就是说,视觉、语言、音频等各模态的知识能否互相强化,达到整体大于部分之和的效果。

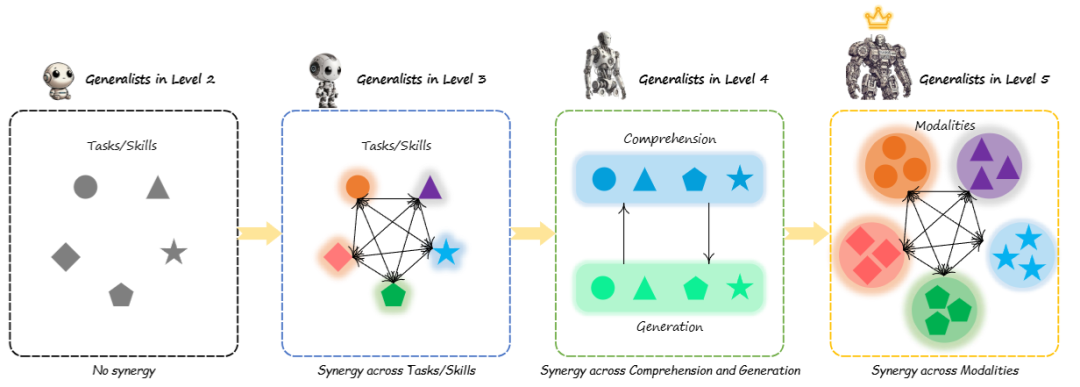
等级1:专家型模型(Specialists)
针对特定任务或特定模态的数据集进行微调,可以看作是针对特定任务的专家模型,包括各种学习任务,例如语言或视觉识别、分类、生成、分割、定位、图像修复等,比如CLIP,Stable Diffusion等。

等级2:支持多任务的通才(Generalists of Unified Comprehension and Generation)
模型从专用模型转变为通用模型,需要让系统能够适应各种任务建模方式,支持多种模态类型和输入格式,同时处理各种模型类型和输出格式(可用于理解或生成)。
目前,最流行且广泛采用的做法是以大语言模型(LLM)作为核心/智能媒介,整合各种专业模型来构建通用模型,通过现有的编码和解码技术整合各种模型,从而实现多种模态和任务(比如理解和生成任务)的融合与统一。

等级3:出现任务级协同的通才(Generalists with Synergy in Comprehension and/or Generation)
要从普通的通用模型提升到第3级,系统必须展现出跨任务的协同能力,使得至少两个任务(无论这两个任务是理解类的还是生成类的,都能够共享特征并实现相互性能提升。

实现跨任务协同最直接的方法是通过多任务联合训练,保留每个任务特定特征的同时,维持任务共享的通用特征而不出现性能下降,并且模型必须支持尽可能多的任务之间的协同,并确保这种协同效应足够显著,以达到第3级的更高评估标准。
等级4:范式级协同的通才(Generalists with Synergy across Comprehension and Generation)
如果一个通用智能体能够达到第4级,也就意味着该系统不仅具备强大的理解能力,而且在进一步学习和训练生成能力时仍能保持基础性能,比如Morph-Token分离出视觉重建损失用于生成学习,以避免与理解学习损失相互干扰。

要达到第4级,通用智能体必须先在单一模态和多模态的情况下实现统一的理解和生成能力,同时系统必须满足其理解和生成能力能够相互协同并增强彼此的要求。
从技术角度来看,获得生成能力比获得理解能力更具挑战性,大多数视觉语言模型的视觉理解能力通常比视觉生成能力要强得多。
等级5:模态级全协同的通才(Generalists with Total Synergy across Comprehension, Generation and Language)
第5级是通用智能体的最终目标,从某些模态的任务中学到的特征、知识甚至智能可以在一定程度上迁移到其他支持的模态任务中。
目前,大多数多模态通用智能体受到架构发展的限制,主要通过语言智能来支持其他模态的智能,要想真正达到第5级,必须实现所有模态之间的协同。

从技术角度来看,通用智能体必须具备推理能力,即能够对所有内容进行推断和泛化,并且需要在推理过程中确保模态无关的上下文一致性。
目前仅根据性能对多模态大语言模型(MLLMs)进行排名的基准测试存在局限性,严重阻碍了多模态通用智能体的发展。
几乎所有的现有基准测试都集中在评估多模态大语言模型在视觉模态(尤其是图像)上的能力,而严重忽视了视频、音频、三维等其他模态的任务,并且评估过程通常假设多模态大语言模型已经具备了令人满意的自然语言处理能力,忽略了对语言能力的评估。
同时,基准测试往往只是简单地将自由形式的预测转换为预定义选项的固定问答格式,本质上是一种妥协,无法以特定格式生成的任务仍然可以被执行。
研究人员认为,真正的多模态通用智能体应该支持任务的原始格式。此外,大多数基准测试仅评估多模态大语言模型对视觉信息的理解能力,然而,多模态通用智能体应该具备超出理解之外更广泛的能力,例如生成、编辑等,所以目标基准测试需要具备以下特点:
-
涵盖尽可能广泛的任务、技能和模态:包括文本、图像、视频、音频、三维等多种模态。
-
包含理解和生成任务:不仅评估模型对信息的理解能力,还评估其生成内容的能力。
-
包含丰富多样的任务:覆盖各种场景和领域的任务,以全面评估模型的能力。
-
保留原始任务预测格式:避免将任务简化为固定格式,以更真实地反映模型的能力。
-
及时维护和动态扩展数据集:确保基准测试能够适应不断变化的需求和技术进步。
General-Bench基准涵盖了多种领域和学科,包括物理科学(例如物理学、数学、几何学、生物学)和社会科学(例如人文科学、语言学、历史学、社会科学)中的28个主要领域,对通用智能体的技能和能力的评估分为通用的模态无关能力和特定模态的技能。
模态无关能力全面涵盖了12个类别,例如内容识别、常识知识、推理能力、因果关系判断、情感分析、创造力和创新能力等。
对于特定模态的技能,研究人员明确列出了每个模态在理解和生成方面的主要能力,对应于数据集中的元任务(技能)。
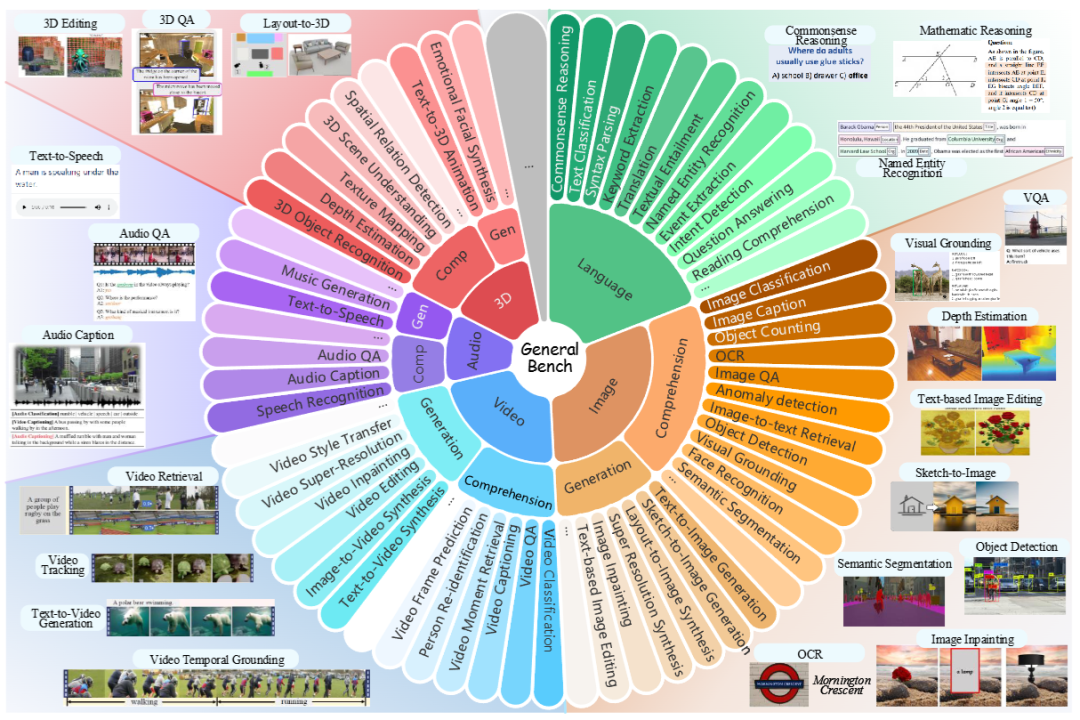
General-Bench中的任务和数据量远远超过了当前的基准测试,覆盖了最广泛的学科领域,并支持最多的模态种类,包含130种多模态技能,涵盖702项任务,涉及各种格式和领域的超过325800个标注,同时支持原始自由形式的任务预测。
由于数据集规模庞大,如果按照General-Level来评估非常耗时且成本高昂,且大部分模型尚未达到框架中所设想的模态和任务覆盖能力。
研究人员设计了一个分层的排行榜,划分为四个难度递增的范围:
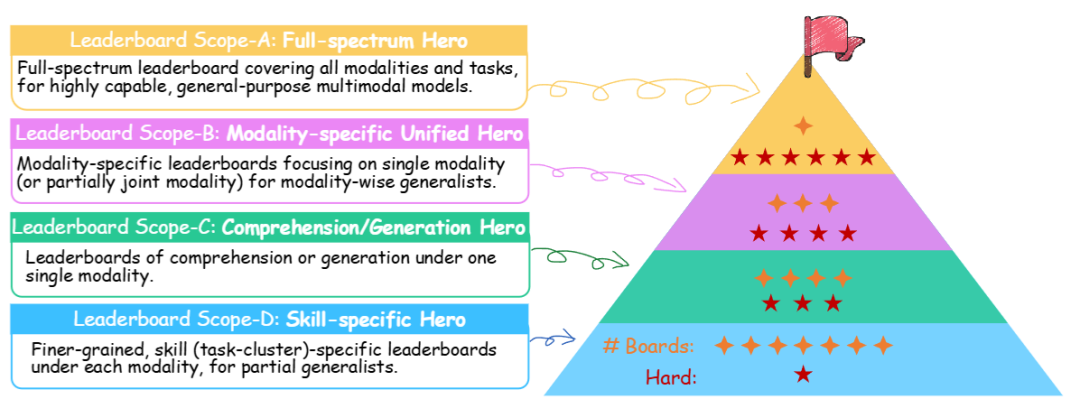
范围A:全模态排行榜,涵盖所有模态和任务,专为功能强大的通用多模态模型设计,覆盖「General-Level」中的所有层级,最具挑战性。
范围B:特定模态排行榜,每个排行榜专注于单一模态或部分联合模态,除语言模态外,为每个模态设计1个独立的排行榜。
范围C:专注于单一模态内的理解或生成任务,包括8个排行榜(2×4,分别对应多模态任务中的理解和生成,参与门槛较低。
范围D:在每个模态内,针对特定技能(任务簇)的更细粒度排行榜,专为部分通用智能体设计,包含大量具体的排行榜,参与难度最低。
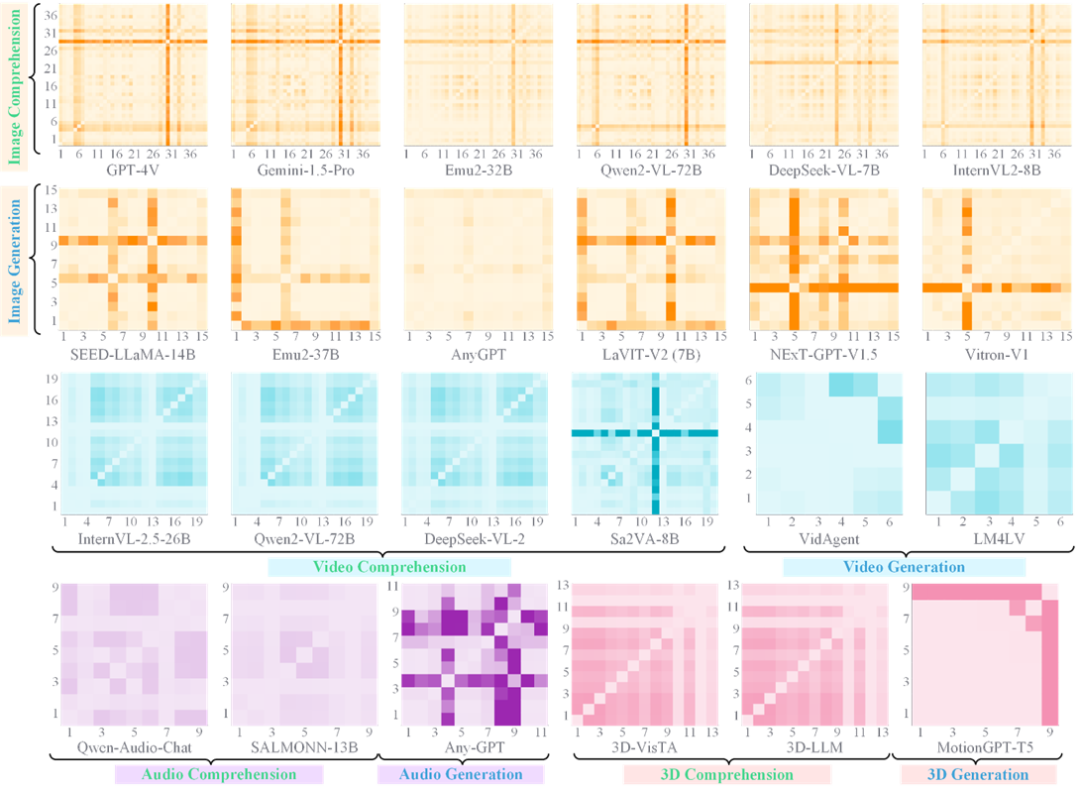
有了上述评估标准,作者使用其构建的庞大的General-Bench基准对当前主流的100多种多模态大模型进行了全面测评(作者注明,截止到24年年底时的模型评测结果,可能会受限于当时的版本情况以及数据情况)。
结果揭示出耐人寻味的现状:绝大部分模型停留在Level 2到Level 3之间,能够晋升到四段及以上的凤毛麟角,五段级别更是尚无一例。这一分布说明,目前的多模态模型虽已有「一专多能」的雏形,但要真正迈向高段通才智能仍面临巨大挑战。
具体来看,很多模型都成功跨过了一段(毕竟专才模型本身不在我们关注的通才之列),达到了Level 2。这意味着它们具备一定的多任务多模态能力。但停留在Level 2的模型缺乏协同效应:它们在每项任务上或许表现不错,却没能在任何一项上超越单任务SOTA。
这反映出目前多数MLLM虽然「什么都能做一点」,但还没有「哪方面因为通才身份而更强」。
例如,Unified-io-2-XXL模型在评测中被归为Level 2的冠军位置。作为强大的视觉多模态大模型,它在非常多的视觉理解上都有不俗表现,然而和各领域顶尖专门模型相比并无明显优势,因而暂未体现出足够明显的协同增益。
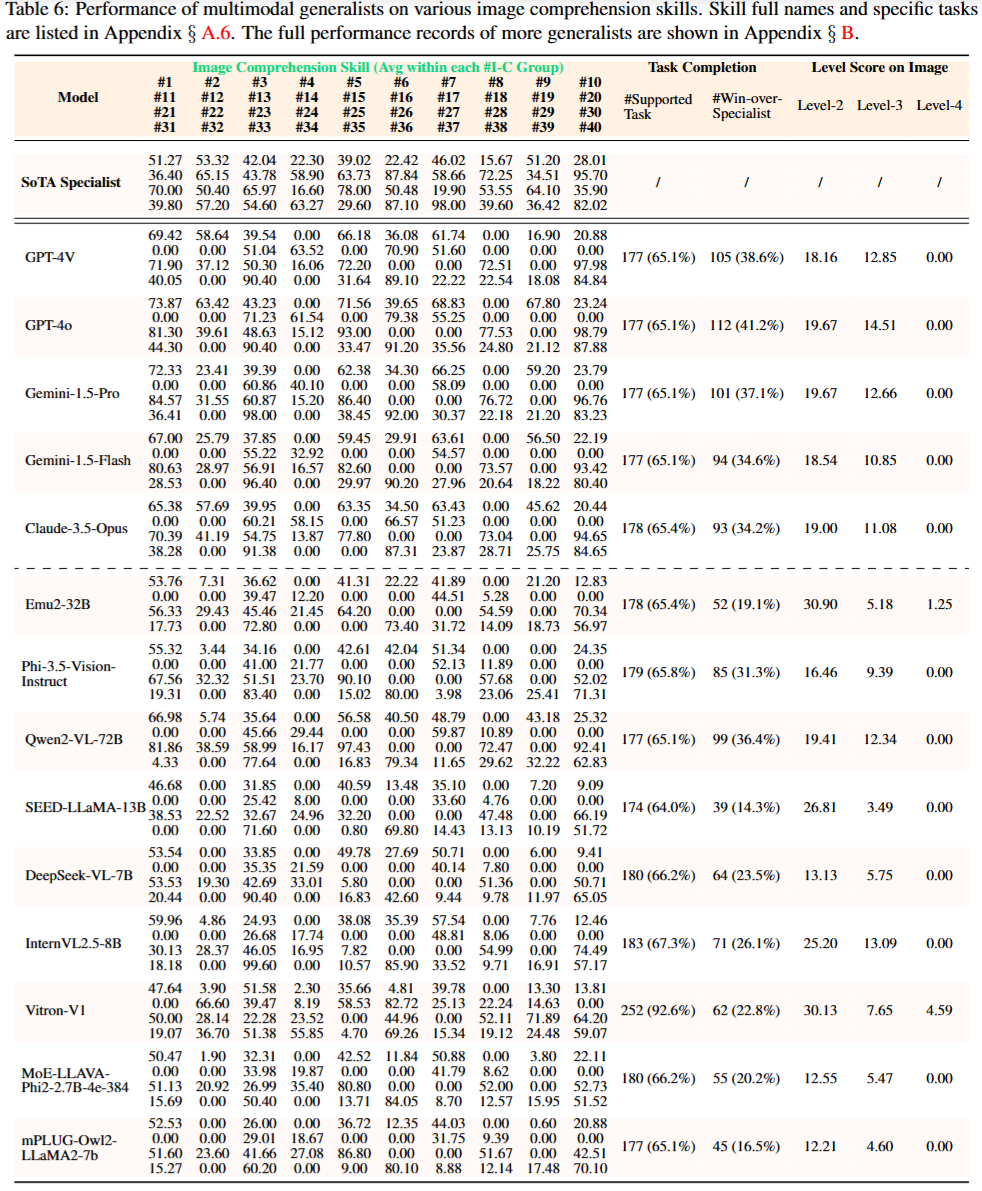
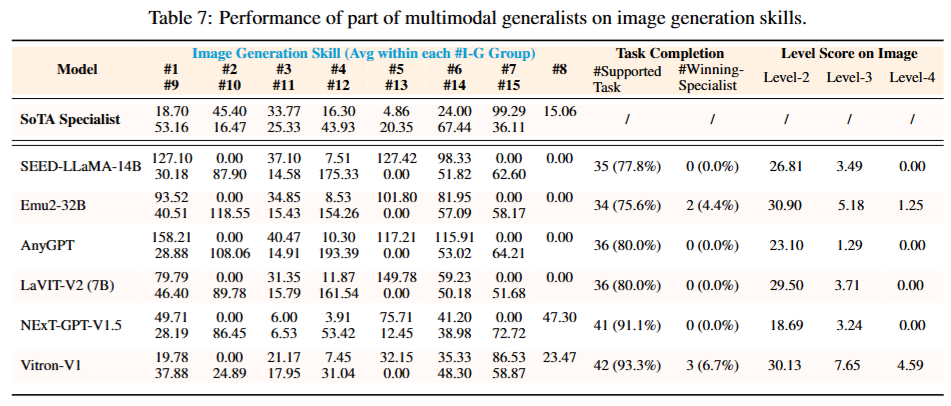
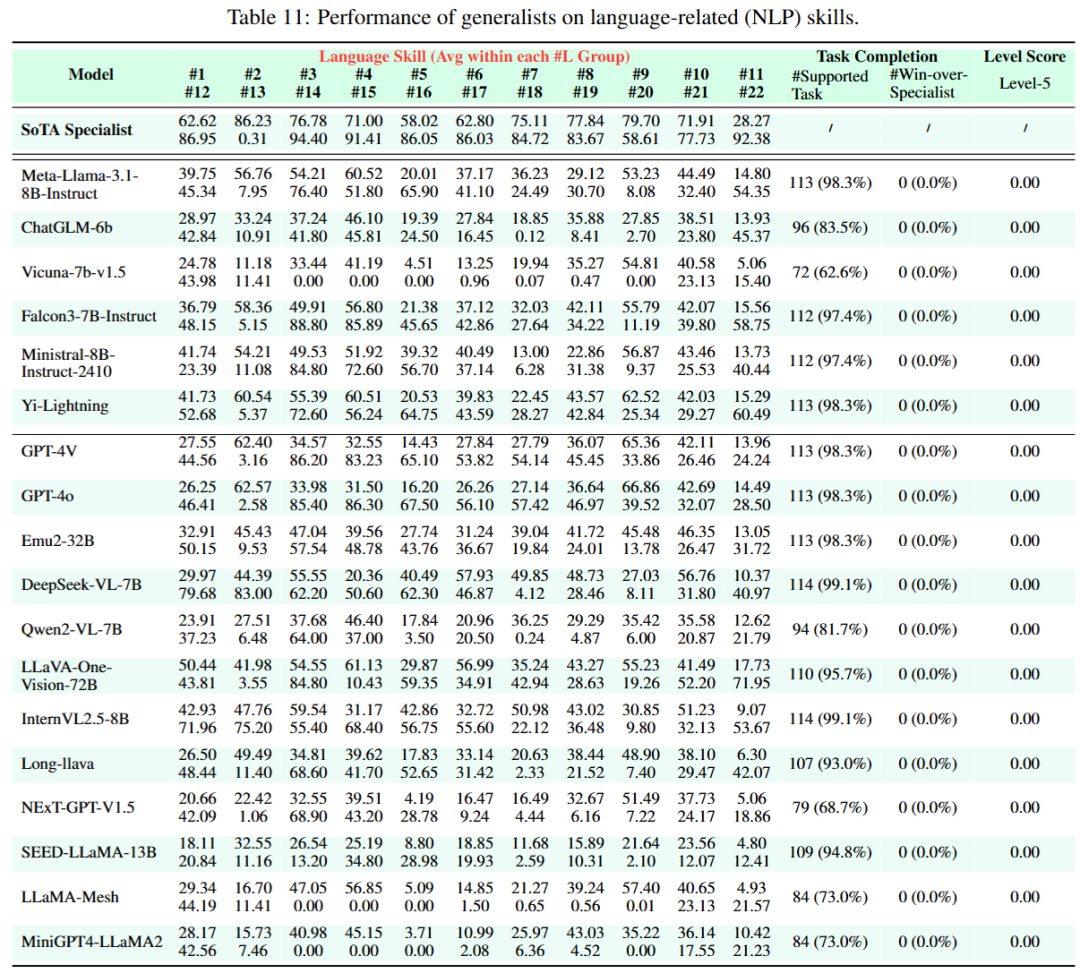
观察1:任务支持不足
大多数多模态大语言模型(MLLMs)在基准测试中对广泛任务的支持度存在明显不足,即使是GPT-4V和GPT-4o模型所能支持的任务也很有限,仅支持271项图像理解任务中的177项,占比65.1%,而开源模型InternVL2.5-8B在图像理解任务中的支持率达到71%,其他模态如视频、音频和3D,任务支持率更低。
只有Vitron-V1支持超过90%的图像任务,而Sa2VA-8B在视频理解组中的支持率达到72.2%,所以当前的模型需要在架构设计上进行显著改进,以支持尽可能多的任务。
观察2:很少有「通才」能超越顶尖「专家」
最先进的专家模型(SoTA specialist)性能要比通用模型更好,各种多模态大语言模型能够超越专家模型的任务和技能非常有限。
例如,闭源模型(如GPT-4V、GPT-4o、Gemini-1.5和Claude-3.5)的胜率最高,超过30%;开源模型Qwen2-VL-72B在图像理解任务中超越专家模型的比例最高,达到36.4%
在视频、音频、3D和语言等其他模态中,超越专家模型的机会更低,结果意味着通用模型尚未满足成为多模态通才所需的跨任务/能力协同的基础条件。
观察3:更注重内容理解而非生成
GPT-4V和GPT-4o在某些图像理解任务的特定技能上比专家模型表现得更好,而且这种提升比其他模型更为显著,但这两个模型仅限于图像理解任务,对图像生成任务完全不支持。
这种趋势在其他模态中表现得更加明显,支持多模态理解的模型数量远远超过支持多模态生成的模型。
观察4:对所有模态的支持不足
多模态大语言模型无法同时支持所有模态,模态的关注度图像 > 视频 > 3D > 音频,只有少数多模态通才包含所有模态。
观察5:多模态并未真正增强语言能力
理想的多模态通才应该能够在不同模态之间实现相互增强,但当前的多模态大语言模型并没有在自然语言处理(NLP)任务中取得改进。
并且,多模态大语言模型在NLP任务中取得了一定的分数,但还没有能够超越NLP领域的专家模型,比在其他模态上观察到的差距更大。
现有的多模态大语言模型尽管以语言为中心的大型语言模型(LLM)为核心,但由于过度专注于非语言模态的训练和微调,其语言能力已显著削弱,不仅削弱了语言理解能力,也无法利用多模态信息来增强与语言相关的任务。
为了更直观地理解General-Level的评估结果,研究人员选择了三个具有代表性的多模态模型:GPT-4o,InternVL2.5和Unified-io-2-XXL。
前者是OpenAI的旗舰多模态模型,将强大的GPT-4语言能力扩展到视觉领域;后者则分别是国内、国外开源社区推出的代表性的SoTA多模态模型,在训练中融合了多种视觉语言任务。
它们在General-Level排行榜上的表现,可以作为当前闭源与开源通才模型的一个缩影。
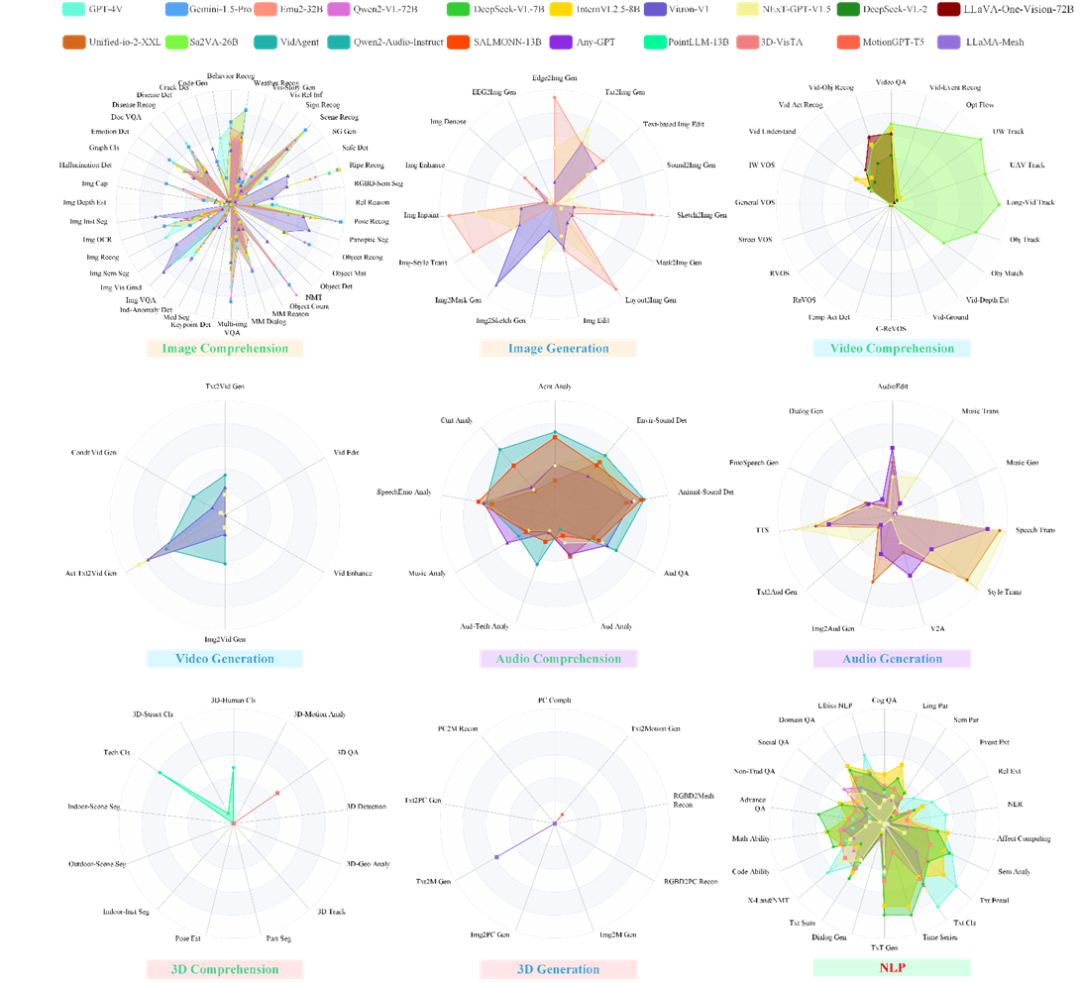
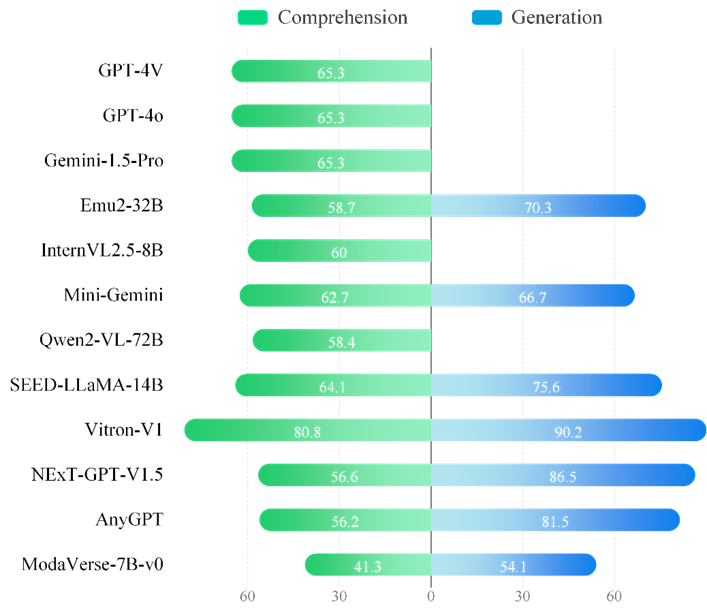
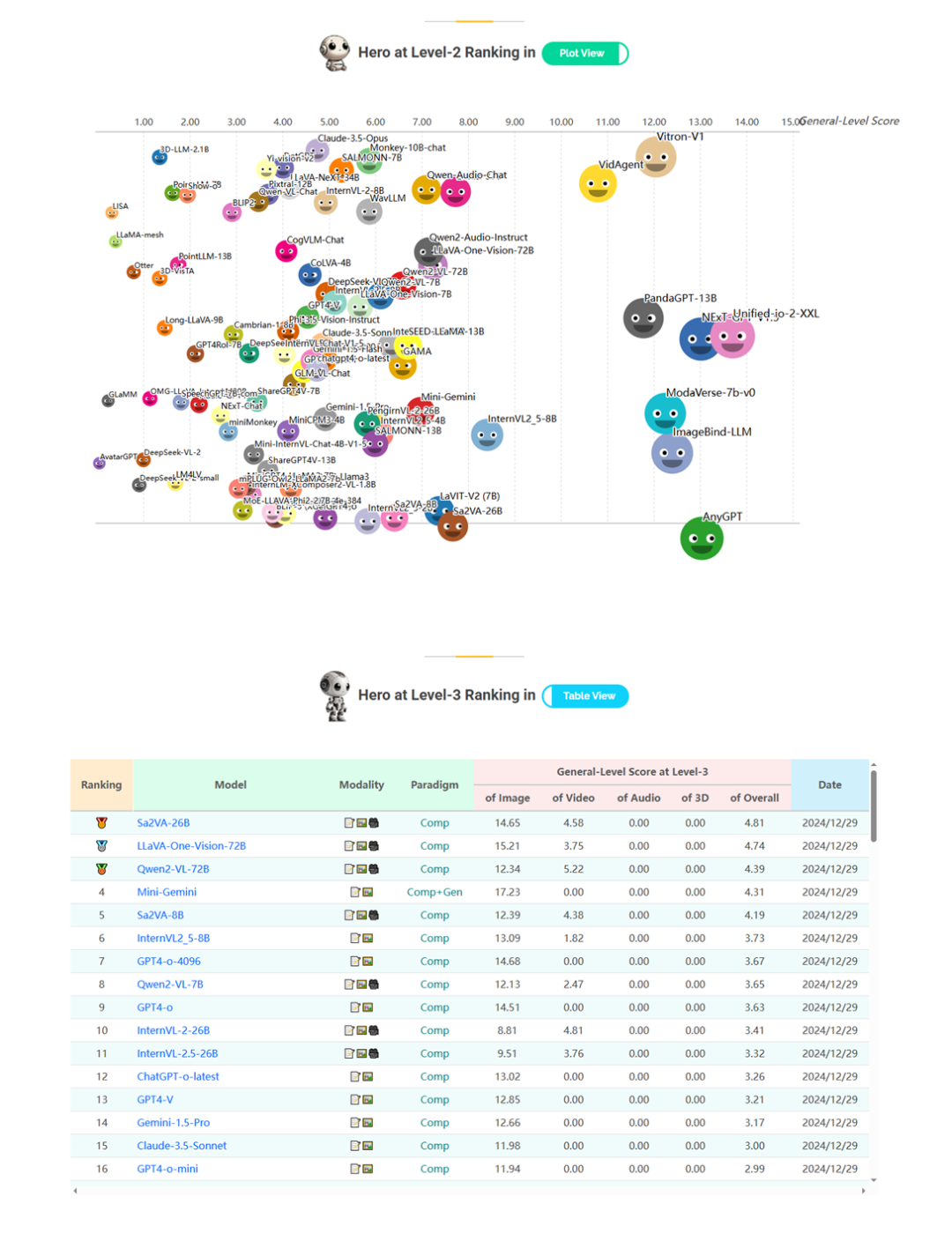
上图展示了General-Level评测Leaderboard中不同段位的模型(Top-Ranking)分布概览,其中也标出了GPT-4o,InternVL2.5以及Unified-io-2-XXL的所在段位和排序。
可以看到,Unified-io-2-XXL在Level 2中表现出最为惊艳的位置,得分最高;然而可惜,其仅仅停留在Level 2,这说明它具备多模态多任务能力,但未表现出协同效应,因而停留在「无协同」的通才层次。
而GPT-4o以及InternVL2.5晋升到了Level 3(紫色平台区域),意味着它在一些任务上实现了协同增益,相比纯粹堆叠能力的模型更进一步。
并且可以看到,InternVL2.5也比GPT-4o排位稍微靠前,原因在于,InternVL2.5比GPT-4o表现出了更显著的跨任务协同泛化能力。
排行榜还揭示出多数模型扎堆于Level 2-3,只有极少数攀上Level 4顶峰,Level 5则依然高悬无人问鼎。
这一对比反映了几类典型现象:
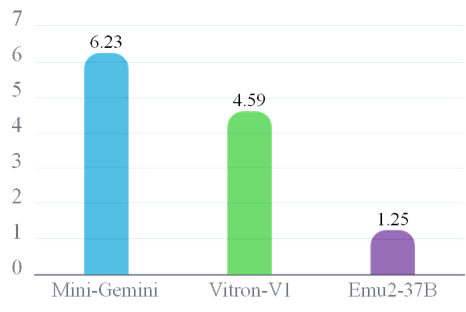
首先是「偏科」问题:Unified-io-2-XXL拥有超强的语言理解和生成能力,但在视觉任务上并未超过专门的视觉模型,因此它的总成绩受到短板制约,只能处于二段。
GPT-4o、InternVL2.5通过多任务训练或者MoE技术,在特定视觉任务上超过了单模态SOTA,表现出协同效应,但它可能在其他任务上并不突出,尤其跨范式能力(如生成长文本描述)可能相对弱,使其难以更上一层楼。
结果揭示了当前多模态模型常见的协同不足:要么擅长A类任务、平平无奇于B类任务,要么精于视觉、弱于语言,各项能力没有实现真正的融会贯通。
其次,从这两个案例我们可以体会到General-Level评估的价值所在。如果没有这样一套段位标准,GPT-4o凭借其强大的综合表现,可能被直观认为是「最先进的通用多模态AI」之一。
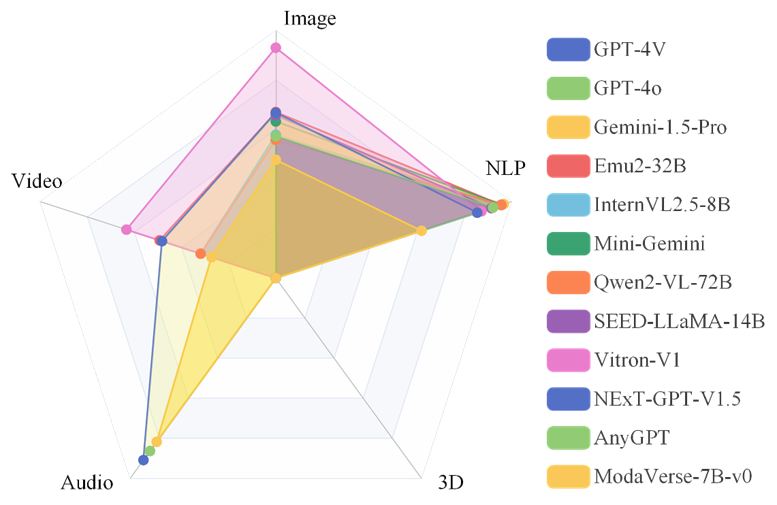
然而General-Level告诉我们,它在「通才」榜单上并未取得顶尖名次,反而暴露出协同方面的不足。
同理,InternVL2.5、LLaVA-One-Vision-72B等模型虽然参数规模和知名度不及GPT4旗舰系列,但通过协同效应加持,在某些维度上实现了对前者的追赶乃至超越。
这种新的比较视角非常重要:研究者和业界不能只关注模型在某单项任务上的最高分,而需要关注模型能力结构是否均衡、是否在通才方面有内在提升。
General-Level提供的排行榜截图和数据,使我们能够一目了然地发现模型的短板与长处,找出「偏科生」和「全面发展生」。
当然,每个模型的绝对段位受诸多因素影响,General-Level评分本身也有一定复杂性(比如评分采用了掩膜策略和加权调和平均等技术细节)。
但总体而言,这套评估体系成功地揭示了当前模型在通才智能上的差距与潜力。
对于模型研发者而言,这样的可视化对比能够帮助分析:我的模型离下一段还差在哪些方面?需不需要在弱势任务上加强训练,以避免短板效应?是否应该引入新的策略来实现跨模态的知识共享?
通过这些反思,研究者可以更有针对性地改进模型,朝着更高段位的通才智能迈进。
General-Level不仅是一个评估指标体系,背后还构建了完善的多模态通用大模型项目生态,方便社区广泛参与和持续迭代。
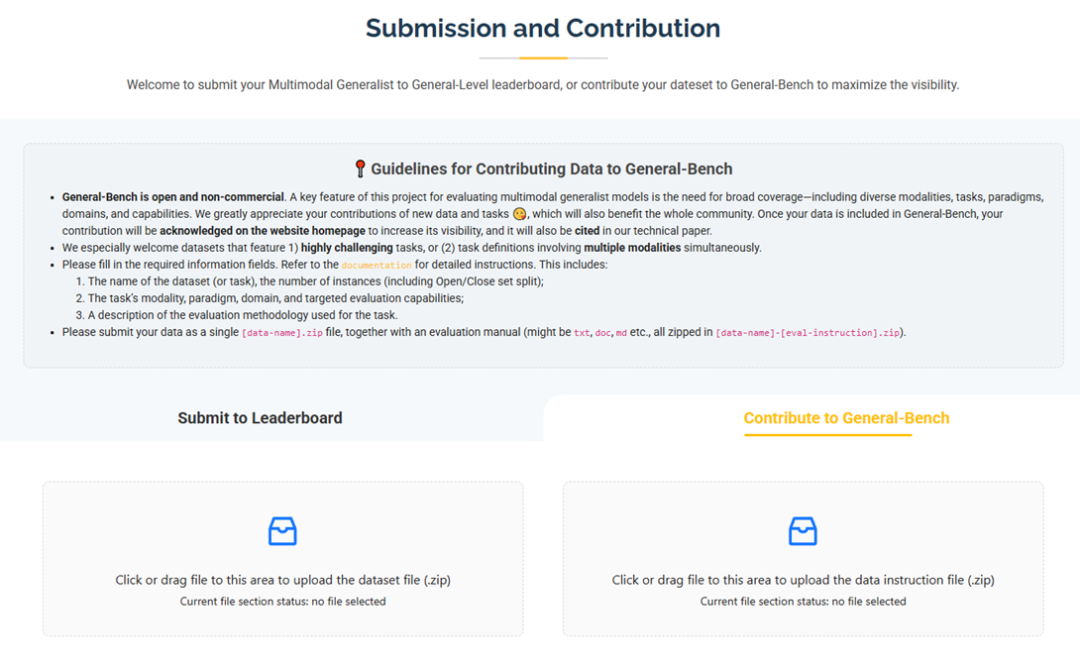
作者团队提供了完整的评测工具和数据,包括代码库、基准数据集、在线排行榜等,使得任何有多模态模型的团队都可以方便地测试并获取自己的「段位」。
在论文发表同时,作者团队已开源了全部数据和评测套件代码,希望更多研究者参与进来,共同完善这一评测框架。
目前团队在其项目主页上给出了非常完全的配套生态(包括评测套件包、项目文档),相信所有想要参与的童鞋都可以方便地接入。
具体来说,项目开源了用于计算General-Level得分的评估代码(GitHub仓库),以及庞大的General-Bench数据集。General-Bench涵盖了700+项任务、超过32万条数据,是目前涉及模态和技能最全面的多模态基准之一。
值得一提的是,作者将数据集分为开放集和封闭集两种版本:开放集(Open-Set)公布了所有输入和标签,便于研究者在本地自由使用、复现实验;封闭集(Close-Set)则只提供输入数据,标签保密,用于官方排行榜评测。这种设计类似Kaggle比赛,有助于防止刷榜,同时又给予学术界充分的使用便利。
为了降低参与门槛,General-Level设置了多个分榜单(Scope-A/B/C/D),针对模型能力覆盖不同范围进行分类评测。
例如,Scope-A要求模型覆盖所有模态和任务,是难度最高的「全能英雄」榜;Scope-B聚焦单一模态内的通才,如图像模态下各任务集合;Scope-C按理解与生成两种任务范式拆分评比;Scope-D则细分到VQA、字幕生成、语音识别等具体技能。
这种四层次榜单设计既确保了顶尖模型有用武之地,也让早期或轻量模型能找到合适的舞台参与评测。无论你的模型目前能力范围如何,都可以选择匹配的榜单来检验自身通才水准,从而循序渐进地提升「段位」。
除了数据和代码,项目还搭建了在线Leaderboard排行榜网站,实时展示各模型在不同榜单下的段位排行和得分情况。
研究者只需按照评测工具对自己的模型跑完开放集数据,得到结果后提交到官网,即可获取模型的官方段位认证和排名。
这种公开排行榜不仅带来荣誉竞争,更重要的是营造了一个社区协作的平台。任何团队都可以浏览排行榜,了解当前最强的模型有哪些、各自的短板如何,从而思考改进方向。
社区还鼓励大家提供新的数据集加入General-Bench、分享模型心得,形成良性循环。
作者团队甚至在HuggingFace上创建了项目专页和互动空间,方便AI爱好者试用和讨论。
通过开放评测和社区驱动,General-Level项目正逐渐形成一个开放生态系统:评测标准统一透明,数据持续扩充,榜单动态更新,吸引越来越多的研究者投入「通才智能」的挑战。
正如作者所言,他们希望General-Level能成为多模态AI领域的评价基础设施,推动整个社区在一个共同坐标系下加速前进。
该项目由来自多个知名高校和研究机构的跨国团队合作完成,阵容十分庞大(超过30位co-author成员+20多位未co-author的贡献者),皆来自国内外知名的专注于多模态大模型相关课题的高校和实验室,如新加坡国立大学(NUS)、南洋理工大学(NTU)、浙江大学、阿卜杜拉国王科技大学(KAUST)、北京大学、上海交大、罗切斯特大学。
作者全员都在多模态内容理解、生成领域有深厚积累。
论文的第一作者、整个项目的主导者费豪博士是NUS的高级研究员,在此前领衔开发过NExT-GPT、Vitron等较为知名的通用多模态大模型;
其他核心Team Co-leader包括周源博士、李俊成博士、李祥泰博士、徐青山博士、李波波博士、吴胜琼博士,都在多模态、计算视觉、自然语言处理等领域有深厚积累;
项目由最近回国学术界的NUS的颜水成教授、NTU的张含望教授领衔通讯指导,由多模态学习资深专家蔡达成教授和罗杰波教授承担项目顾问。
有意思的是,如此规模、资深团队联合攻关,在一定程度上亦体现了「通才AI」这一课题的前沿性和广泛关注度。

从研究背景上看,General-Level的思路与过去AI领域的一些想法一脉相承。例如,在自动驾驶领域,人们常用L1-L5等级来描述车辆智能驾驶的成熟度;在围棋等游戏中,段位评级更是由来已久。
将这种分级评测引入AI多模态通才,是一个水到渠成的创想。
而具体到实现上,作者团队面临的难点在于如何量化协同效应。正如论文所述,严格来说要证明协同效应,需要比较模型同时学习A和B任务时的表现与分别学习时的表现。
但由于通才模型往往是在海量任务上联合训练过,无法简单剥离开来重新训练对照。
为此,作者采取了折中策略:以「超越单项SOTA」作为协同效应的判断依据。虽然这种方法并非完美精确,但在实践中可操作且直观有效,最终成就了General-Level评估体系的落地。
通向多模态通才AI的道路充满挑战,而General-Level五级评估体系的推出无疑是一个里程碑式的进展。
它为我们提供了统一的语言去讨论和衡量多模态模型的智能水平,将过去碎片化的任务指标提升到「协同效应」这一更宏观的视角。通过General-Level,我们可以明确地指出某模型是哪一级的「通才」,找出其短板与差距,从而有针对性地改进。
这种评估体系有望成为未来多模态AI研发的标配工具,如同ImageNet之于视觉模型、GLUE之于语言模型一样,成为促进未来通用多模态AI进步的Infrastructure。
更重要的是,General-Level传达出一个关键信号:真正的通才AI不应只是一堆功能的集合,而应该是各功能之间有机协作的整体。
在追求更高参数量和更多训练数据之外,如何让模型内部形成协同增益,将是迈向AGI不可回避的问题。当前,没有模型达到Level 5,这既意味着差距,也意味着机遇。
下一个「多模态ChatGPT时刻」何时到来?
也许正取决于我们能否解决协同效应的难题,培育出横跨所有模态和任务的全能型AI。
总而言之,General-Level为评估多模态通才智能树立了新标杆。我们期待看到更多研究者使用这一基准来检验自己的模型,不断冲击更高段位。随着社区的共同努力,多模态通才AI的未来必将加速到来。
从Level 1到Level 5,是一条充满挑战但充满希望的征途;让我们携手踏上这条征途,见证通才AI从现在的星星之火走向燎原之势!
(文:新智元)