

随着视频内容在信息传播、教育、娱乐等领域的广泛应用,对视频内容的理解和分析需求日益增长。然而,长视频的处理一直是视觉语言模型(VLMs)面临的重大挑战,因为其需要处理大量的时间序列数据,这不仅对计算资源提出了极高的要求,还可能导致信息冗余和处理效率低下。为了突破这一瓶颈,蚂蚁集团联合中国人民大学推出了ViLAMP 模型,它通过混合精度策略和创新的差分蒸馏技术,实现了对长视频的高效处理和理解,为视频内容分析带来了新的解决方案。
一、项目概述
ViLAMP 是一款专为高效处理长视频内容而设计的视觉语言模型,能够在单张 A100 GPU 上处理长达 1 万帧(约 3 小时)的视频,同时保持稳定的理解准确率。该模型基于混合精度策略,通过差分关键帧选择和差分特征合并机制,显著降低了计算成本,提高了处理效率。ViLAMP 在多个视频理解基准测试中表现出色,尤其在长视频理解任务中展现出显著优势,为长视频分析提供了新的高效途径。
二、技术架构
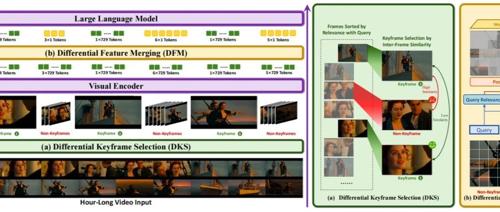
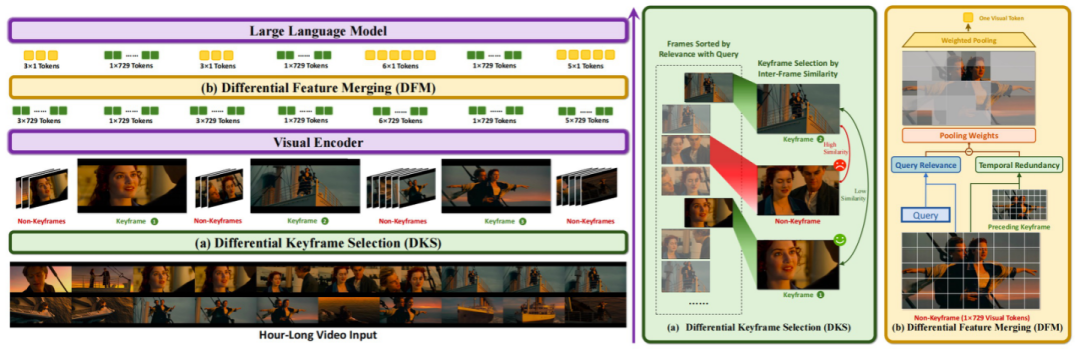
(一)差分关键帧选择
ViLAMP 的差分关键帧选择机制通过最大化查询相关性并保持时间独特性来识别关键帧。它首先计算每个帧与查询的相似度,然后通过贪心算法选择与查询高度相关且在时间上具有代表性的帧作为关键帧。这一过程不仅确保了关键帧能够捕捉到与查询最相关的信息,还避免了冗余帧的选取,从而显著提高了模型的效率。
(二)差分特征合并
对于非关键帧,ViLAMP 采用差分特征合并策略,通过加权池化操作将每个非关键帧的多个 patch 合并为单个 token。在这一过程中,与查询相关且具有独特性的 patch 被赋予更高的权重,而与关键帧重复的 patch 的权重则被降低。这种机制在保留关键信息的同时,显著减少了计算量,实现了对非关键帧的有效压缩。
(三)多模态学习
ViLAMP 通过双流视觉连接器架构将关键帧和非关键帧的异构表示整合到语言模型中。关键帧的完整 token 表示和非关键帧的压缩表示通过独立的两层 MLP 投影到语言模型中,然后按照时间顺序排列,形成一个统一的序列。这种设计不仅保留了关键帧的完整信息,还通过压缩非关键帧来提高模型的处理效率。
三、主要功能
(一)长视频理解
ViLAMP 支持处理长达数小时的视频,能够高效地处理超长视频序列,解决了传统模型在处理长视频时面临的计算成本高、效率低的问题。它通过差分关键帧选择和差分特征合并机制,在保持视频语义完整性的前提下,显著降低了计算资源的消耗。
(二)关键信息提取
ViLAMP 能够精准提取视频中的关键信息,同时通过压缩冗余信息来提高处理效率。它可以根据用户查询的意图,从长视频中快速定位到与查询最相关的片段,并提取出关键帧和关键特征,为用户提供准确的视频内容理解。
(三)高效计算
ViLAMP 在单张 A100 GPU 上处理长达 1 万帧(约 3 小时)的视频,显著降低了内存和计算成本,提高了处理效率。其混合精度策略和差分蒸馏技术使得模型在处理长视频时能够高效运行,同时保持稳定的性能。
(四)多任务处理
ViLAMP 支持多种视频理解任务,如视频内容问答、动作识别、场景理解等。它能够根据不同的任务需求,灵活调整模型的处理策略,为各种视频理解任务提供强大的支持。
四、应用场景
(一)在线教育
ViLAMP 可以快速提取教育视频中的重点内容,生成摘要或回答学生问题。它能够根据学生的查询意图,从长视频中精准定位到相关的教学片段,为学生提供更加高效的学习体验。
(二)视频监控
ViLAMP 能够实时分析监控视频,检测异常事件并及时报警。它通过高效处理长视频序列,能够快速识别出视频中的异常行为和事件,为安全监控提供有力支持。
(三)直播分析
ViLAMP 可以实时处理直播内容,提取亮点或回答观众问题。它能够根据观众的实时查询,从直播视频中快速提取关键信息,增强直播的互动性和观众的参与感。
(四)影视制作
ViLAMP 帮助编辑和导演筛选素材,提取关键场景,提高制作效率。它能够从大量的影视素材中快速定位到与制作需求最相关的片段,为影视制作提供更加高效的内容筛选和编辑支持。
(五)智能客服
ViLAMP 自动回答用户关于视频内容的问题,提升用户体验。它能够根据用户的查询意图,从视频中提取准确的信息并生成回答,为用户提供更加智能的客服服务。
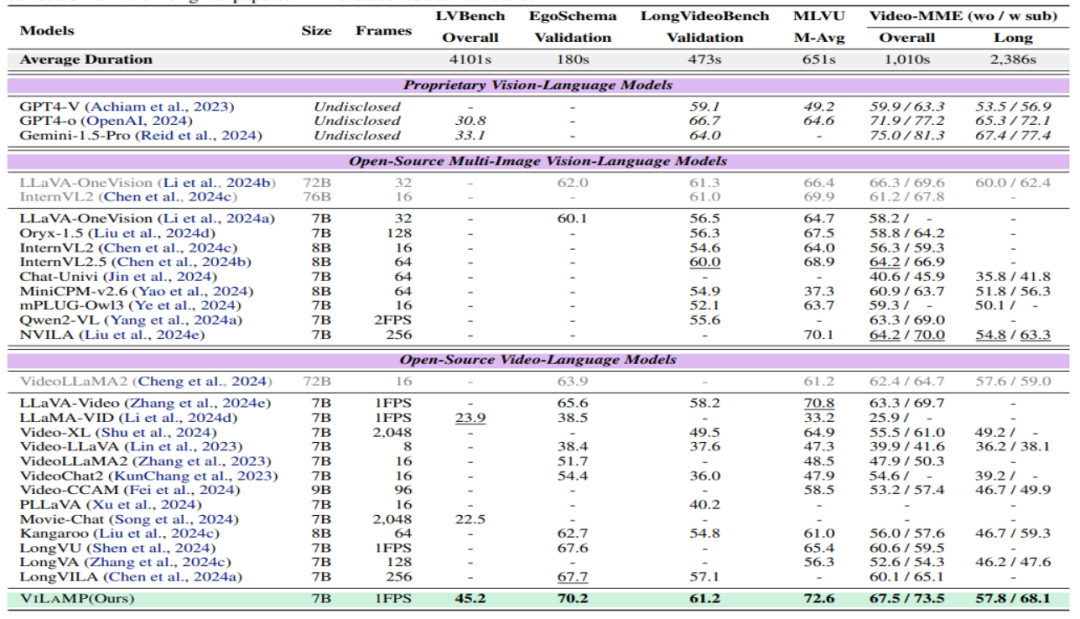
五、测评表现
ViLAMP 在多个视频理解基准测试中表现出色,尤其在长视频理解任务中展现出显著优势。它在 LVBench、EgoSchema、LongVideoBench、MLVU 和 Video-MME 等五个视频理解基准测试中均取得了优异的成绩,显著优于现有的其他模型。特别是在长视频子集的 Video-MME 测试中,ViLAMP 在非字幕和字幕设置下分别取得了 67.5% 和 73.5% 的准确率,比之前的最佳模型提高了 3.0% 和 4.8%。此外,ViLAMP 还成功处理了长达 10K 帧(约 2.7 小时)的视频,展现了其在超长视频理解方面的强大能力。
六、快速使用
(一)环境准备
在开始使用ViLAMP 之前,需要确保已经安装了 Python 环境,并且安装了必要的依赖库。可以通过以下命令安装依赖库:
git clone https://github.com/steven-ccq/ViLAMP.gitcd ViLAMPpip install -r requirements.txt
(二)模型安装
请从huggingface(https://huggingface.co/orange-sk/ViLAMP-llava-qwen)下载模型文件,并将其放置在 `models/` 目录下。
(三)数据准备
在进行模型评估之前,需要下载相应的评估数据集,并将其放置在`dataset/` 目录下。例如,对于 Video-MME 数据集,可以按照以下路径放置数据:
dataset/Video-MME/videomme/test-00000-of-00001.parquetdataset/Video-MME/data
(四)评估脚本
ViLAMP 提供了针对 Video-MME、MLVU、LongVideoBench、ActivityNetQA 和 EgoSchema 等五个基准测试的评估脚本。以下是一个评估 Video-MME 的示例命令:
python exp_vMME.py \--dataset_path dataset/Video-MME/videomme/test-00000-of-00001.parquet \--video_dir dataset/Video-MME/data \--output_dir dataset/Video-MME/output \--version models/ViLAMP-llava-qwen \--split 1_1 \--max_frame_num 600
(五)训练脚本
ViLAMP 还提供了单节点和多节点环境下的训练脚本。详细的训练指令可以在 `scripts/train/` 目录下找到。在开始训练之前,需要在 `training_data.yaml` 文件中注册训练数据集,并确保数据集的格式符合要求。
七、结语
ViLAMP 作为蚂蚁集团和中国人民大学联合推出的视觉语言模型,通过其创新的差分蒸馏技术和混合精度策略,在长视频理解领域取得了显著的突破。它不仅在多个视频理解基准测试中展现了卓越的性能,还通过高效处理长视频序列,为实际应用提供了强大的支持。无论是在在线教育、视频监控、直播分析还是影视制作等领域,ViLAMP 都能够显著提高视频内容的理解和分析效率。未来,随着技术的不断发展,ViLAMP 有望在更多领域发挥更大的作用,推动视频内容分析技术的发展。
八、项目地址
技术论文:https://arxiv.org/pdf/2504.02438
GitHub 仓库:https://github.com/steven-ccq/ViLAMP
(文:小兵的AI视界)