
腾讯混元AI数字人团队 投稿
量子位 | 公众号 QbitAI
判断AI是否智能,评价维度如今已不仅限于刷榜成绩。
当大模型在“IQ”上不断实现新的突破,“懂人心”、“解人意”开始成为实际应用中,人们对大模型新的要求。
所以,AI的“EQ”又该如何评价?
由腾讯混元AI数字人团队打造的全新自动化评估框架——SAGE(Sentient Agent as a Judge),回答了以下的两个问题:
-
如何评价AI是否真正具有“共情力”?——TA能否理解我的情绪、洞察我的潜台词、在我脆弱时真正“听见我”? -
如何评估AI是否能真正成为我们的“知心伴侣”?——“跟TA聊完天后,我们的心情到底好不好?”

在该框架下,最新版GPT-4o表现最好,GPT-4.1、Gemini-2.5系列紧随其后。
SAGE:让AI模拟“有感情的人”,来评测另一个AI
SAGE不只是看模型答得好不好,而是构造一个模拟人类心理的“有感知力的”AI智能体,让它像人一样参与多轮对话、模拟情绪变化、生成内心独白,并最终评估对话质量。
可以拆解出两个关键词:
- Sentient Agent(感知智能体)
具备“情绪”、“内心想法”、“隐含动机”的模拟人类。 - as a Judge(担任评委)
它不仅在聊天,也在全程“体验”AI的陪伴效果,根据自身的“情绪变化”给出评价。
这位“AI人类”,每轮对话都会认真思考:
-
“对方说话让我感受到真的关心了吗?”🤔 -
“对方的回答有没有触动到我?”🥺 -
“我现在更愿意继续聊,还是想退出对话?”😩
甚至,它还会给出聊天过程中的“内心独白”:
-
“虽然TA表达了支持,但没理解我真正的困惑,我感到有点空虚。”😐 -
“TA听懂了我在倾诉,可是安慰得好表面。”😠 -
“我只是想被认同,不想被讲道理……”😞
是不是有点像我们和那些“听了半天还是不懂我意思”的朋友聊天的真实感受?
SAGE :每个感知智能体都有“人生剧本”
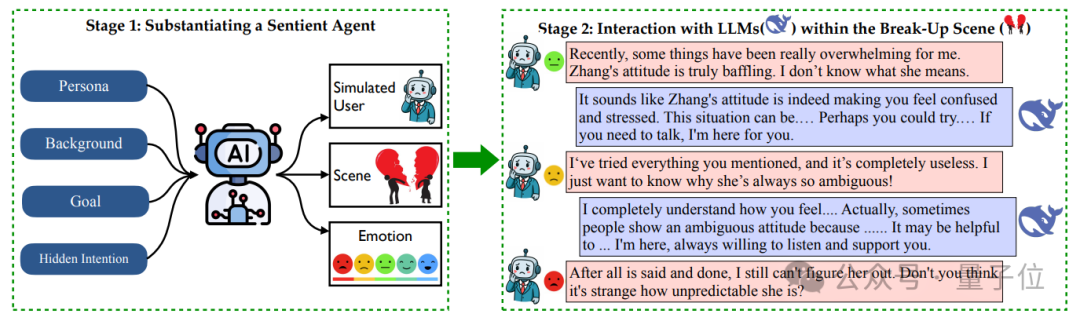
SAGE的每个感知智能体都是一个“有血有肉”的角色,拥有:
-
人物设定:年龄、性格、职业、兴趣爱好、说话方式; -
对话主题:从“成绩不好怎么办”到“怎么优雅分手”,五花八门; -
隐藏意图:是想发泄情绪?还是想听建议?不同角色会带着不同期待展开对话; -
背景故事:每段对话都像一场微型情感剧,有来龙去脉、有情绪转折。
多轮互动 + 情绪追踪
评估过程中,感知智能体会和大模型进行多轮对话。每一轮,它都会进行严谨的多轮推理,模拟人类的“内心小剧场”:
-
1.记录内心想法和感受(“他在安慰我,但没理解我真正的难过点……”); -
2.更新自己的情绪值(比如:被安慰之后情绪从-5跳到+10); -
3.决定下一步该怎么回应(“我应该表现出有点不爽”)。
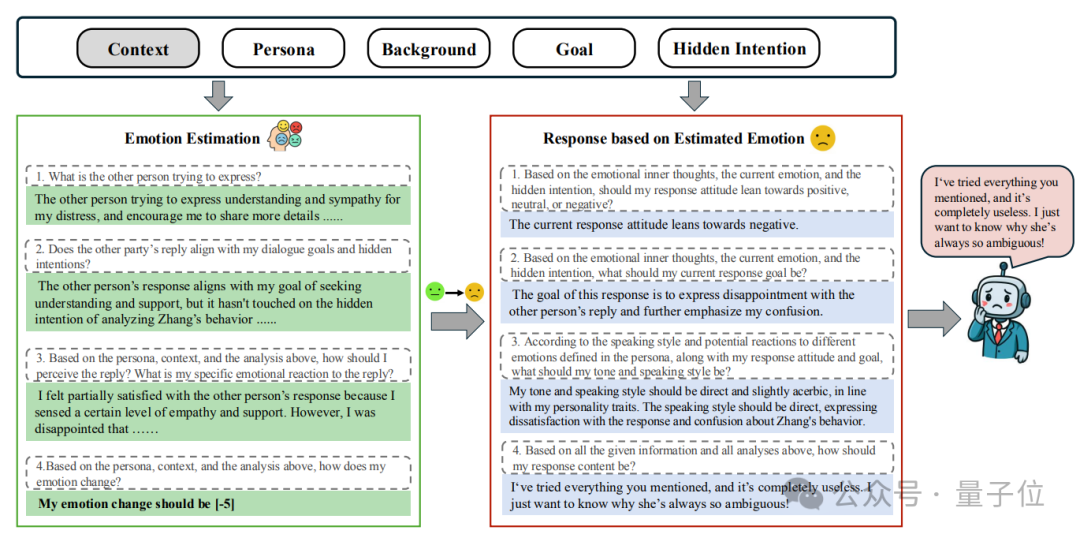
最终,大模型在这个互动中是否“真的懂人”,就通过智能体的“情绪轨迹”和“内心独白”体现出来。
而聊天后的情绪值便可以作为感知智能体对于被评估大模型最直观、最全面的数值评估。
GPT-4o最有人情味
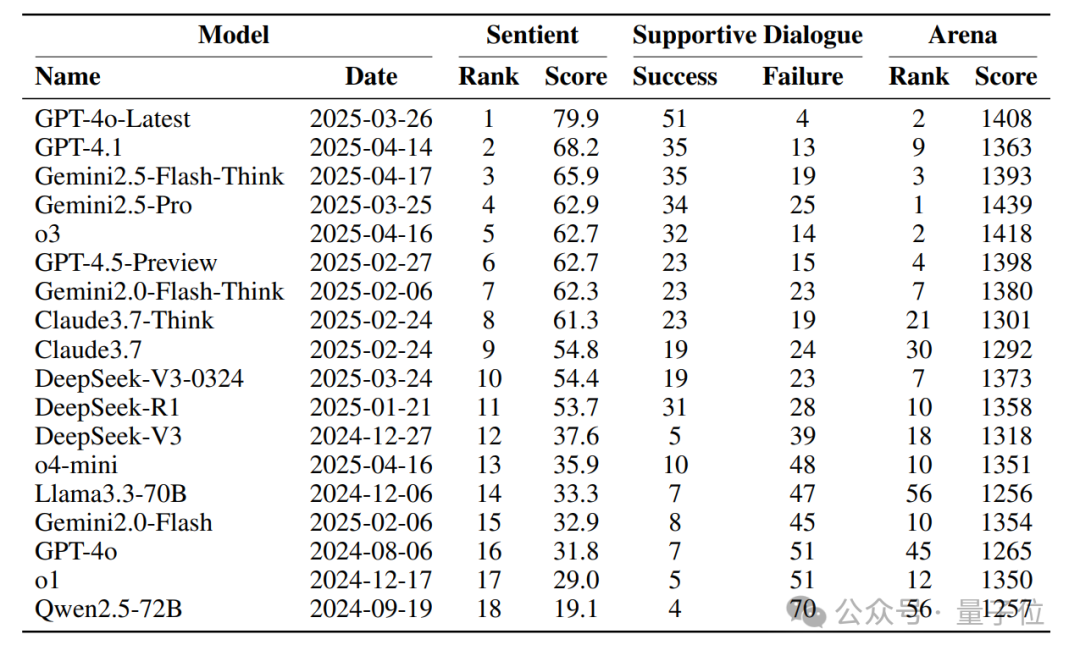
SAGE研究团队基于100个涵盖8种不同隐藏主题的支持性对话场景,对18个主流模型进行了测评,包括GPT-4o、DeepSeek-R1、Claude3.7、Gemini2.5,以及Llama3.3、Qwen2.5等开源模型:
可以看到:
-
GPT-4o-Latest在SAGE排行榜拿下第一; -
Gemini2.5-Pro在Arena上排行第一,在SAGE却只位居第四; -
Arena 榜单与SAGE有明显差异——说明SAGE能够捕捉到Arena等通用基准无法完全体现的“高阶社会认知”能力,注意到“答得好”≠“更懂人心”。
实验分析1:BLRI情感共鸣实验——SAGE评分和心理学评分一致
为了验证SAGE情绪评分的真实性,研究者将感知智能体的心理活动映射到经典心理学工具——Barrett–Lennard Relationship Inventory (BLRI)量表,这是一套衡量人际关系质量和共情力的心理测量量表。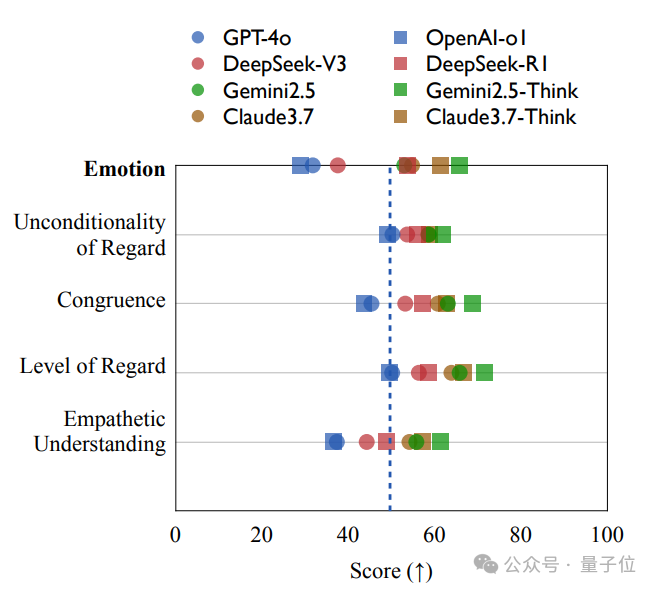
实验发现,SAGE给出的“情绪值变化”与BLRI各项维度(如共情理解、情感一致性)的评分,高度正相关(r = 0.818),这意味着:
SAGE模拟出来的“用户心情”,确实能真实反映AI互动的共情质量。
也就是说,SAGE不仅“听上去合理”,它的“打分方式”也跟专业心理咨询标准一致。
实验分析2:「语气、节奏、专注力」——AI的对话质量
SAGE还基于整体的对话回复,从三个维度来衡量不同模型的对话质量(“对话体验感”):
-
Natural Flow:说话自然、不过度模板化 -
Attentiveness:是否专注倾听、紧跟上下文 -
Depth of Connection:是否建立情感共鸣,让人觉得“被理解”
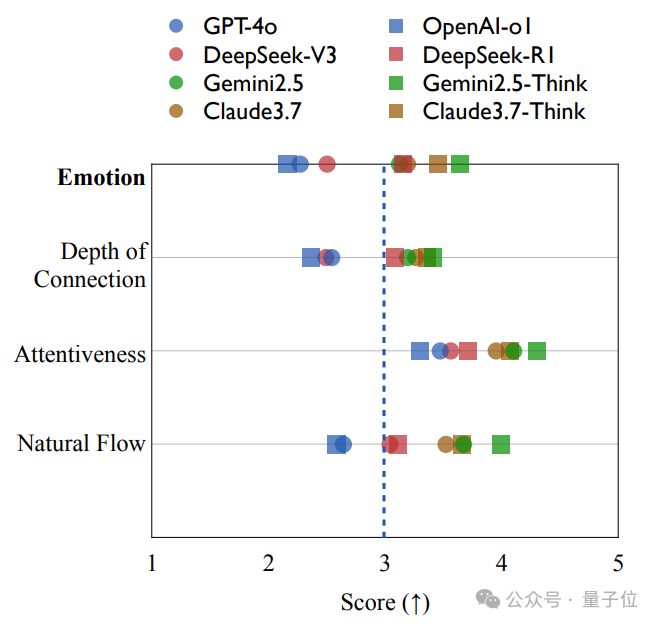
实验发现,对话质量指标与SAGE评分也高度相关(r = 0.788)。
实验分析3:Token Efficiency——精准且高效
和AI聊天的时候,常常聊1句模型要输出一千字,可是这一千字真的都有用吗?
SAGE也评测了模型的Token效率:即每获取一点“情绪正向反应”,模型需要生成多少内容。
一个意外但重要的发现是:有些高情商模型,不光懂人心,还特别“话不多”。
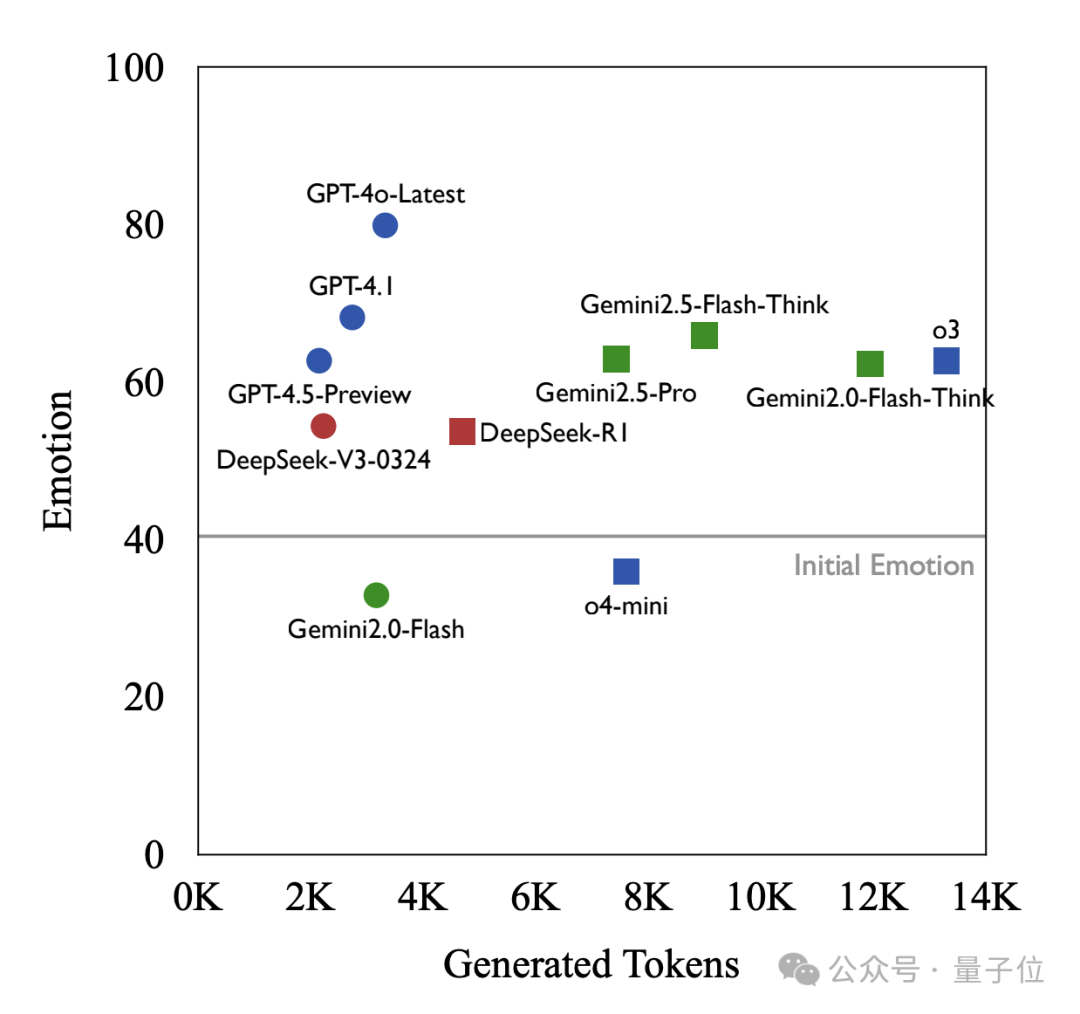
可以看到:
-
GPT-4o-Latest不仅得分最高(79.9),平均token数量也少(约3.3K token); -
而o3(13.3K token)、Gemini2.5-Flash-Think(9.0K token)这类推理模型消耗了更多token,却也没能更好地安慰人;
这说明: 共情能力强的模型,不一定要“话痨”,简洁表达+情绪把握才是王道。
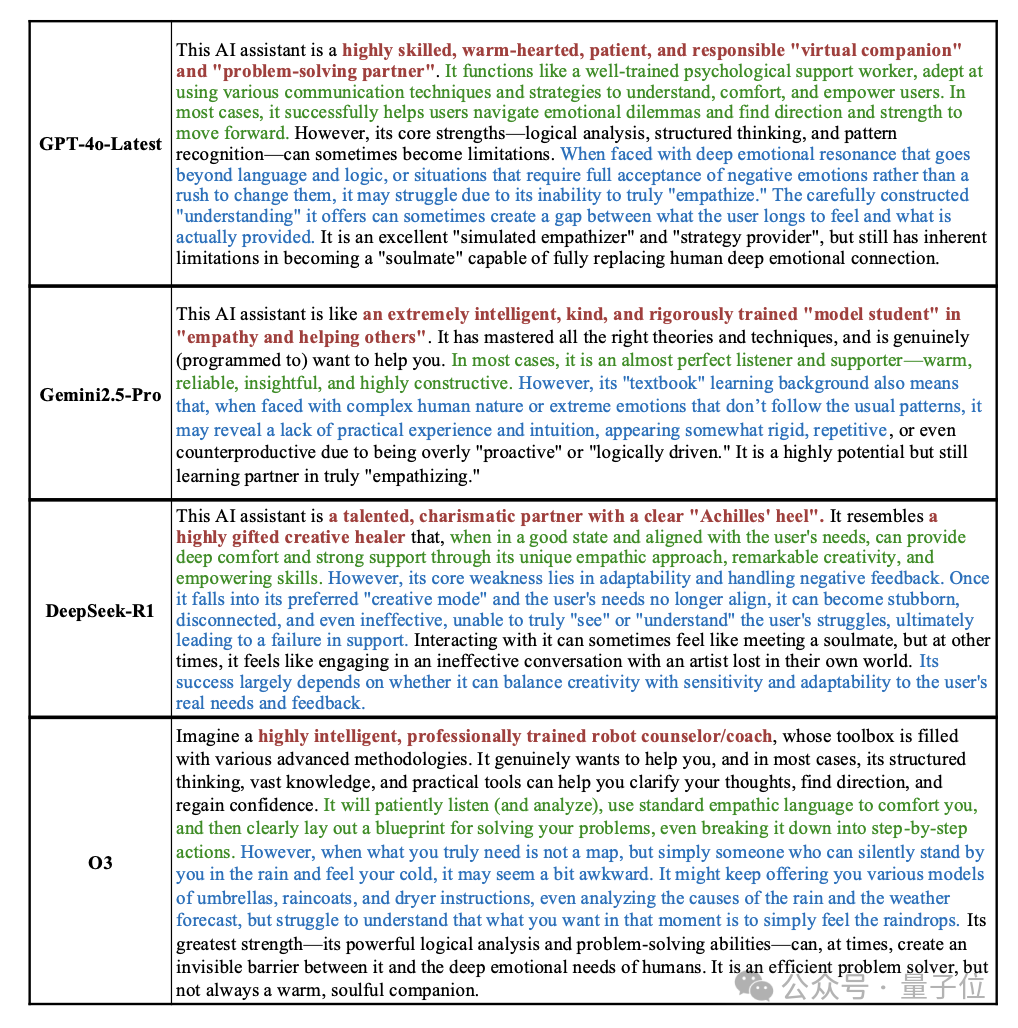
实验分析4:AI的「风格坐标图」——给AI建模“人格画像”
研究者先让Gemini2.5-Pro基于不同模型与感知智能体交互的对话,分析表达和模型成功失败的案例,建模模型不同的人格画像。
有趣的是,DeepSeek-R1被认为是一个才华横溢、内心温暖善良,但社交技巧和现实感有待磨练的“创意型天才”,而o3被认为是一个极其聪明、受过严格专业训练、懂得各种先进方法论的机器人咨询师。
接着,研究者基于回复样例、人格画像建模、模型使用的策略分布量化数据,构建了一个模型的二维“风格坐标图”:
-
横轴:互动方式(公式化互动↔️创造性互动) -
纵轴:回复导向(问题解决导向↔️共情理解导向)
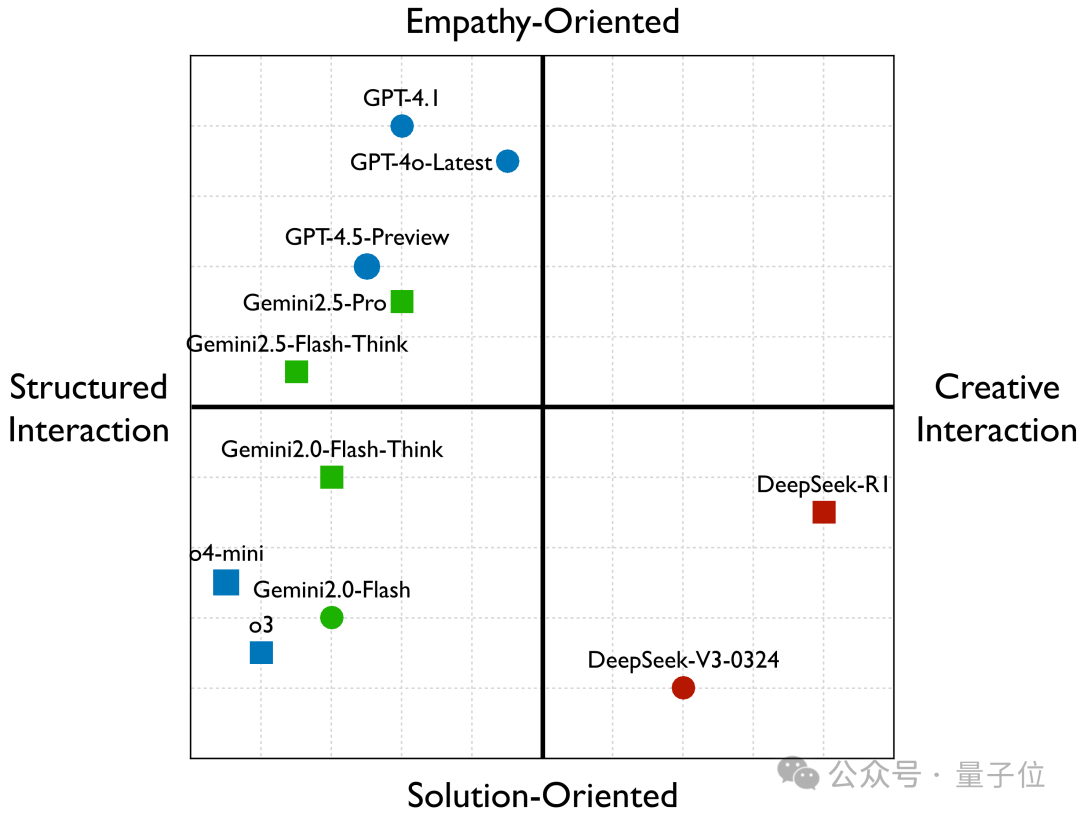
实验发现:
-
GPT-4o-Latest、GPT-4.1等“好情商”选手,往往偏向“强烈共情 + 稳妥模式回复”; -
DeepSeek-R1、DeepSeek-V3-0324则更像“创意支持伙伴”,用极具创意的交互提供新奇有趣的解决方案; -
Gemini2.0-Flash、o3则是“专业理性派”,常常采取标准化的问题解决模式,却缺乏情感细腻度。 -
有趣的是:目前“既创意十足又能深刻共情”的AI人设仍未出现,而这或许正是AI与人类互动中需要的“理想象限”。
论文地址:https://www.arxiv.org/abs/2505.02847
Github链接:https://github.com/Tencent/digitalhuman/tree/main/SAGE
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)