

金磊 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
“我们已经过渡到了可以进行复杂推理的下一个模型范式。”
OpenAI CEO奥特曼在年度总结中,给出了他关于大模型未来发展的论断。
推理模型的重要性正在上升,成为了继基础模型之后各家厂商厮杀的新战场。
推理模型百家争鸣,究竟哪家能力更强?最近,这个问题有了答案。
近期,中国信息通讯研究院(信通院)发布了一项最新的大模型推理能力评估成绩,结果显示——
文心X1 Turbo在24项能力评估中,16项达5分、7项达4分、1项达3分,综合评级获当前最高级“4+级”。
而且还是国内首款,也是唯一通过该测评的大模型。

为什么文心能够入围“4+级”?
在百度刚刚举办的AI Day活动中,百度集团副总裁吴甜深入浅出地对其最新大模型,从模型、数据、应用等诸多方面做了深度解析和科普,我们也与她进行了一番对话。
不妨从中来挖掘这个问题的答案。

△百度集团副总裁,吴甜
多模态融合,模仿人类思考
演讲中,吴甜介绍了文心大模型最新进展,也就是其在上个月发布的文心4.5 Turbo和文心X1 Turbo:
-
文心4.5 Turbo,主打多模态,是在文心4.5的基础之上而来,不仅效果更佳,而且成本更低。
-
文心X1 Turbo,侧重深度思考,从X1升级而来,性能提升的同时,具备更先进的思维链,问答、创作、逻辑推理、工具调用和多模态能力进一步增强。
两个新模型的核心亮点,也代表了文心大模型发展的两个关键词——多模态和深度思考。

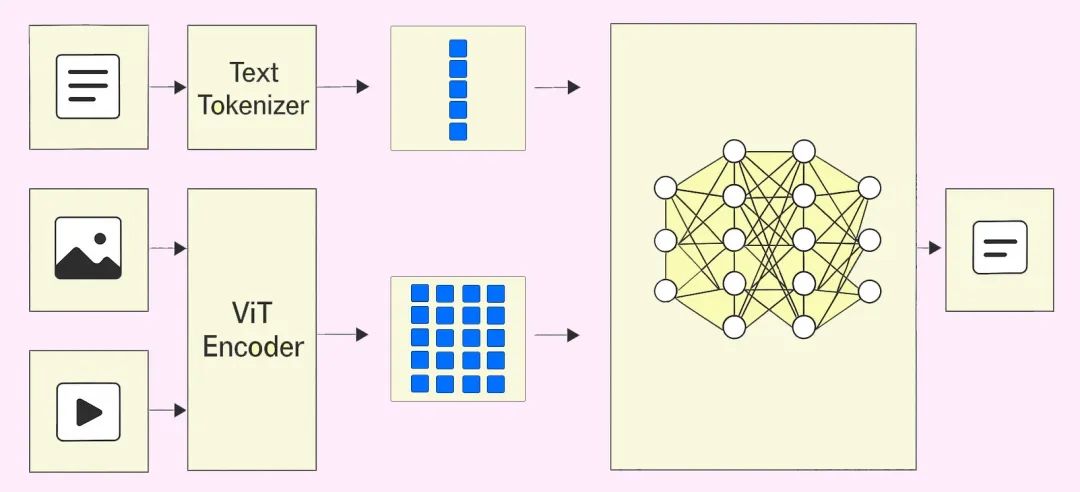
先看多模态,文心大模型在这个方向上所采取的一项关键技术就是多模态混合训练。
具体而言,就是对文本、图像和视频模态进行了统一建模与融合训练。
为应对不同模态在结构、规模与知识密度方面的差异性,百度研制并采用了多模态异构专家建模、自适应分辨率视觉编码、时空重排列的三维旋转位置编码、自适应模态感知损失计算等关键技术。
这些技术在充分挖掘各模态特征的同时,显著提升了模型跨模态学习的效率和融合表现,整体训练效率提升近2倍,多模态理解能力提升超过30%。
在后训练阶段,文心大模型使用的一项关键技术,是引入具有自主学习能力的自反馈增强技术框架。
它是在模型本身的生成与评估能力的基础上,构建出的一套“训练—生成—反馈—增强”的迭代闭环机制。
通俗来说,自反馈增强技术框架会让大模型能够像人类一样在实践中自我提升。
这个机制可以说是不仅解决了大模型对齐过程中,数据生产难度大、成本高、速度慢等问题,而且显著降低了模型幻觉,模型理解和处理复杂任务的能力大幅提升。
进一步地,通过融合偏好学习的强化学习技术,文心大模型实现多元统一奖励机制,提升了对结果质量判别的准确率。
在对离线偏好学习和在线强化学习统一优化之后,进一步提升了数据利用效率和训练稳定性,并增强了模型对高质量结果的感知。
此外,通过偏好信号与奖励信号的融合运用,模型的理解、生成、逻辑和记忆等能力也得到了全面提升。
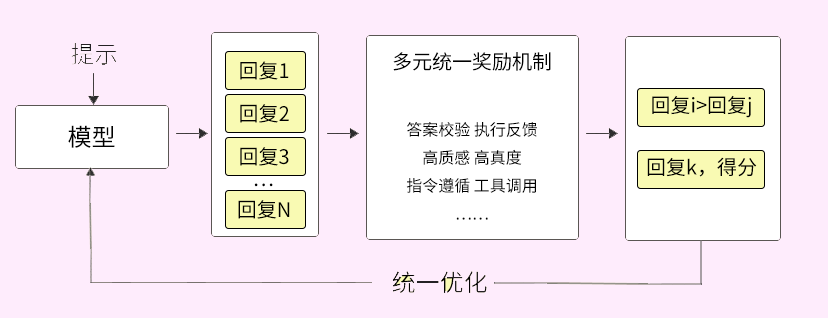
△融合偏好学习的强化学习
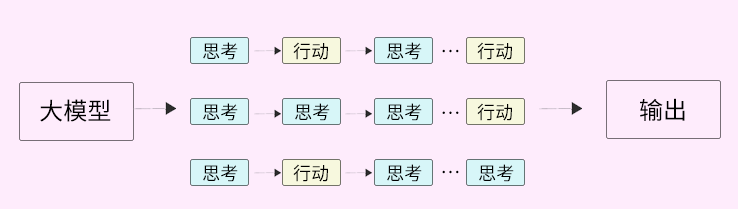
在此基础之上,深度思考模型文心X1 Turbo突破了传统仅依赖线性思维链的范式。
它将工具调用融入到模型的思考路径,构建出了集思考与行动于一体的复合型思维链。
在人类的思维和行动过程当中,思考链和行为链是有非常多种不同的路径的,文心将这样的模式迁移到了思考模型中。
在实际应用中,模型可以根据任务需求选择“边思考边行动”、“先思考后执行”或“尝试后反思”等多种策略路径。
这就会让模型在输出过程更接近人类解决问题的思维过程,让模型在解决真实的长程、复杂性的任务上有更好的表现。
再配合多元奖励机制的端到端优化训练,便极大增强了模型在处理跨领域、复杂任务时的思维广度与逻辑深度,整体效果提升超22%。
从以上技术当中可以看到,文心在多模态和深度思考上采取的技术路线,匹配了大模型进化的两个重要方向——一方面是不同模态的融合,另一方面是对人类思维过程的模仿。
除了在模型算法上下功夫,文心大模型也在数据和模型基础设施上进行了大量的技术攻关。
例如在数据构建方面,文心大模型则是构建了一套贯穿“数据挖掘与合成—数据分析与评估—模型能力反馈”的全链路闭环机制。
这个机制不仅确保了高质量、多样化、知识密度丰富的数据持续供给,也具备良好的可扩展性,能快速适配新的数据类型和任务场景。
在这一体系之下,数据的构造不仅强调事实性与覆盖广度,也注重遵循第一性原理以保障语义本质的还原。
此外,系统性引入稀缺知识点驱动的数据挖掘机制、融合线上真实交互反馈的自动化数据构建流程,以及多模态平行数据的高效构建策略,共同支撑了模型能力的持续演进。
基础设施层面,百度相较于其它大模型玩家来说,一个独树一帜的特点,便是自家的飞桨。
在底层技术上,百度通过框架与模型、框架与算力的协同优化实现了降本增效。
文心4.5 Turbo在飞桨框架支持下,训练吞吐效率达到文心4.5的5.4倍,推理吞吐能力提升至8倍以上。
据了解,飞桨框架3.0的发布进一步强化了对异构芯片的适配、多模态大模型的支持及并行训练效率。
因此,从这次分享来看,百度在大模型训练、推理性能提升的优化路径便非常清晰了——
算力、框架、模型,三位一体,深度协同优化。
而且从目前披露出来的“成绩”来看,这种优化路径是已见成效的那种:
文本方面,文心4.5 Turbo在涵盖中文、数学、代码等内容的14个数据集上取得了80分的平均成绩,超过了GPT-4.5和DeepSeek-V3;
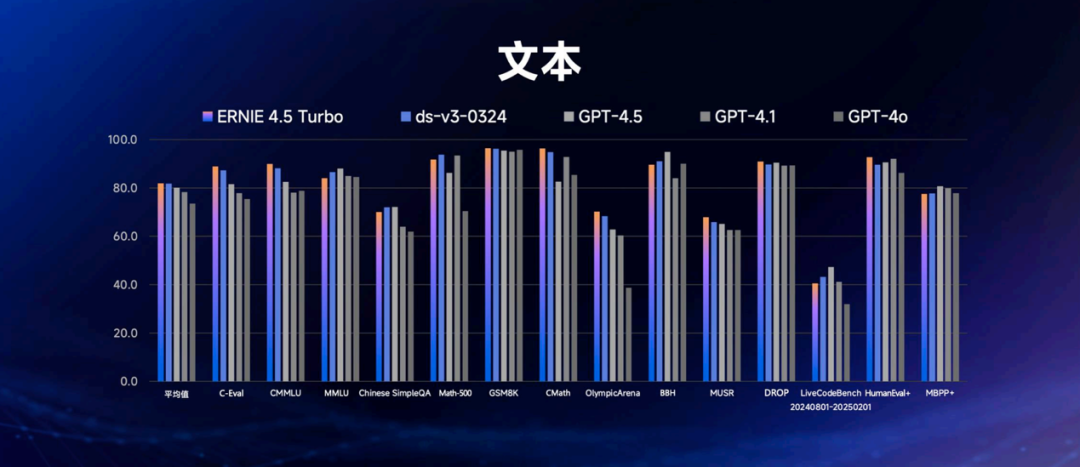
文心4.5 Turbo的多模态能力,也领先于GPT-4.1和GPT-4o:
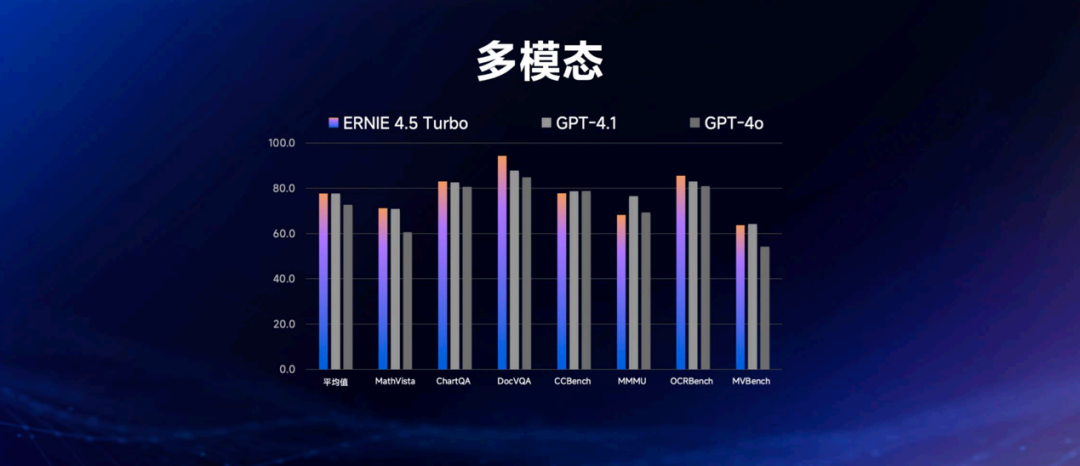
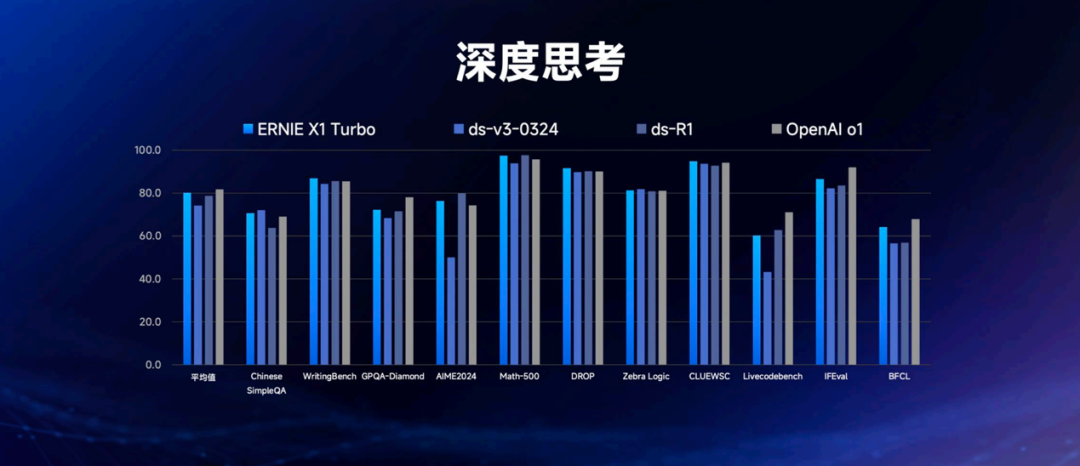
深度思考方面,文心X1 Turbo无论是各个数据集还是平均成绩,都超过了DeepSeek-R1。
场景的适配与实用的AI
评测成绩也只能说是“疗效”的数字化形式,若想更直观地感受,应当再来看下大模型在实际场景中的应用。
比如学习场景中的解物理题,文心X1 Turbo也是只需看一眼题目,便可“唰唰唰”推理出精准的解析过程和答案:

也正如刚才提到的自反馈机制等,在这个案例中,我们可以清晰地感受到文心X1 Turbo像人一样作答的思维过程。
自然语言是人类沟通交流的工具,也是人类思维的载体;而形式语言则是人工定义的,具有严密的逻辑,是计算机可执行的。从自然语言到形式语言,大模型都能够建模并运用,架起了从思考到执行的桥梁。
在代码场景上,基于文心大模型的语言和代码能力,百度研制了代码智能体以及智能代码助手——文心快码。
百度每天新增的代码中,AI生成占比已超过40%,代码服务已累计服务760万开发者。
在更加复杂的应用场景中,百度也有一些布局。
以数字人为例,超拟真数字人需要具备出色的表现力、吸引人的内容、数字人与场景、物品的互动等,需要综合运用多模态AI技术。
百度的“剧本”驱动多模协同的超拟真数字人技术,实现了语言、声音、形象的协调一致。
目前这套技术已经支持超过10万数字人主播,直播转化率达31%,降低80%直播开播成本。

从行业上看,百度展示的这届应用场景,都是大模型应用的热门方向——
比如教育层面,根据贝哲斯报告的预测,到2029年,全球在线教育市场中,仅K-12教育的规模,就会达到8991.59亿元,年均复合增长率7.89%,在这之中大模型将扮演重要的推手角色。
代码就更不必多说,单是在大模型评估当中,代码能力就是一项不可或缺的重要指标,实际当中,更是大模型,特别是推理模型的主要应用场景。
数字人方面,中国互联网协会预计,今年的数字人核心市场规模将达到480.6亿元,是2022年的近4倍,同时还将带动产业市场规模达到6402.7亿元。
可见,百度不仅拥有独特的技术优势,更是成功将这些优势转化成了热门场景应用。
从这些技术和应用布局当中,也可以看到百度的大模型之道正在清晰显现。
六年九大版本,全栈技术能力带文心大模型走向决赛
从2019年的文心1.0,时隔6年时间,到现在的文心4.5 Turbo/X1 Turbo,文心大模型已经有了9个大版本的迭代。
文心4.5 Turbo和文心X1 Turbo在其中仅是百度大模型技术版图的“单点”,要想了解全貌,还需进一步以“线、面”的方式来探索。

技术层面上来看,文心大模型在多模态和深度思考两个方向上布局较深,用强化学习让模型自己学会调优,同时靠全栈技术能力和数据积累来支撑。
从多粒度知识融合学习、知识和数据融合学习,到知识增强、知识点增强,从检索增强、对话增强、逻辑推理增强,到慢思考、深度思考、多模态,模型的效果和效率不断提升,能力的边界也在持续地拓展。
那么随之而来的一个问题便是:
百度的大模型之道,应当是什么样的?
我们细扒后,发现:
文心大模型自2019年3月发布以来,其技术框架的核心原则始终保持一脉相承。其中,预训练始终是模型建设的重要环节之一,奠定了其能力基础。
同时,始终坚持对事实性、时效性和知识性的高度重视,并通过知识增强技术来强化这一特性。
在这一框架下,文心大模型逐步发展出智能体技术(即模型的思考能力),并结合工具使用能力,以解决现实世界中的复杂问题。这些核心技术方向一直是文心持续贯彻的重点。
当然,具体的技术方法也在不断演进。除了预训练阶段,后训练(如强化学习)的重要性正不断提升,推动模型在原有体系下持续优化和升级。
而置身于“速度与激情”并存的大模型发展大环境中,在量子位与吴甜的交流过程中,她也谈及了文心大模型之道的态度:
首先,行业的高速发展是预料之中的,这是新一轮科技革命周期,而非短期风口。回顾历史,任何一次科技革命都会经历较长的演进周期,大模型技术也不例外——它将在未来多年持续推动各行业工作方式和思维模式的深刻变革。
其次,技术的影响是层层扩散的:从技术突破到应用落地,再到最终改变人们的日常生活,这一过程如同涟漪般逐步展开。因此,我们始终以动态的眼光看待发展,既关注当下的快速迭代,更注重技术的长期价值。
基于此,文心大模型团队始终聚焦技术深耕与前瞻探索。我们看到未来仍有诸多方向值得突破,并将持续推动技术向更高目标迈进,为下一阶段的行业变革做好准备。
一言蔽之,百度的态度就是既保持敏锐,也坚持长期视角。
更宏观角度来看,从“百模大战”至今,大模型这个牌局已初步展现收敛的态势,但终局必然是未至;未来更多玩家被淘汰的概率依旧不小。
不过可以肯定的一点是,百度、在技术积累和全栈能力,尤其是从底层框架飞桨到上层应用的完整技术栈,将是让其入围决赛圈的杀手锏。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
(文:量子位)