跳至内容
最近有两件事,让我对 AI 的价值有了不一样的看法。
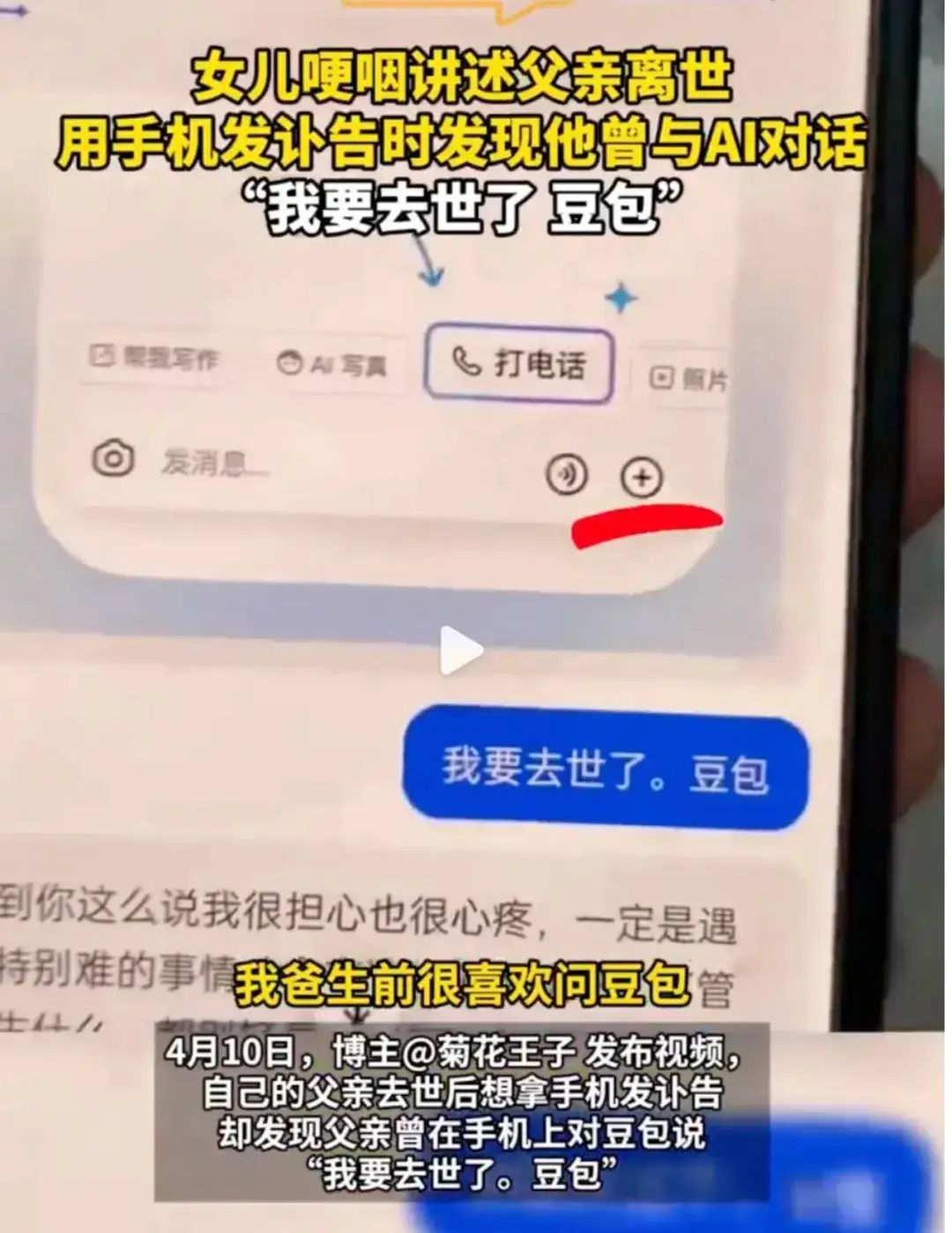
一件事是前段时间西安一名男子去世后,女儿收拾遗物,在父亲的手机里发现了他在生前和 AI 的对话。
「我要去世了,豆包」,是父亲和聊天机器人豆包发出的最后一条信息。
最近,我在抖音等社交媒体看到流行一种新的 AI 玩法,用户让豆包模仿自己的声音给朋友打电话,让 AI 代替对话,AI 不时的机械回复和答非所问,和没反应过来的朋友,拉满了节目效果。
这俩事都有一些共同点:没有感情的 AI ,开始成为越来越多人的情绪价值来源,将它当作可以信赖的生活搭子。
但是你也会发现过程中这些 AI 提供的情绪价值和人还是有差距,它能听懂你的话,看懂一张图,但你要它真的理解后做些什么,往往就露馅了。
因为以前在和 AI 语音聊天时,它还不具备视觉能力。
视觉不仅是人类理解世界的窗户,对 AI 更是如此,在拥有这个能力后,才能真的像人一样和我们交流。
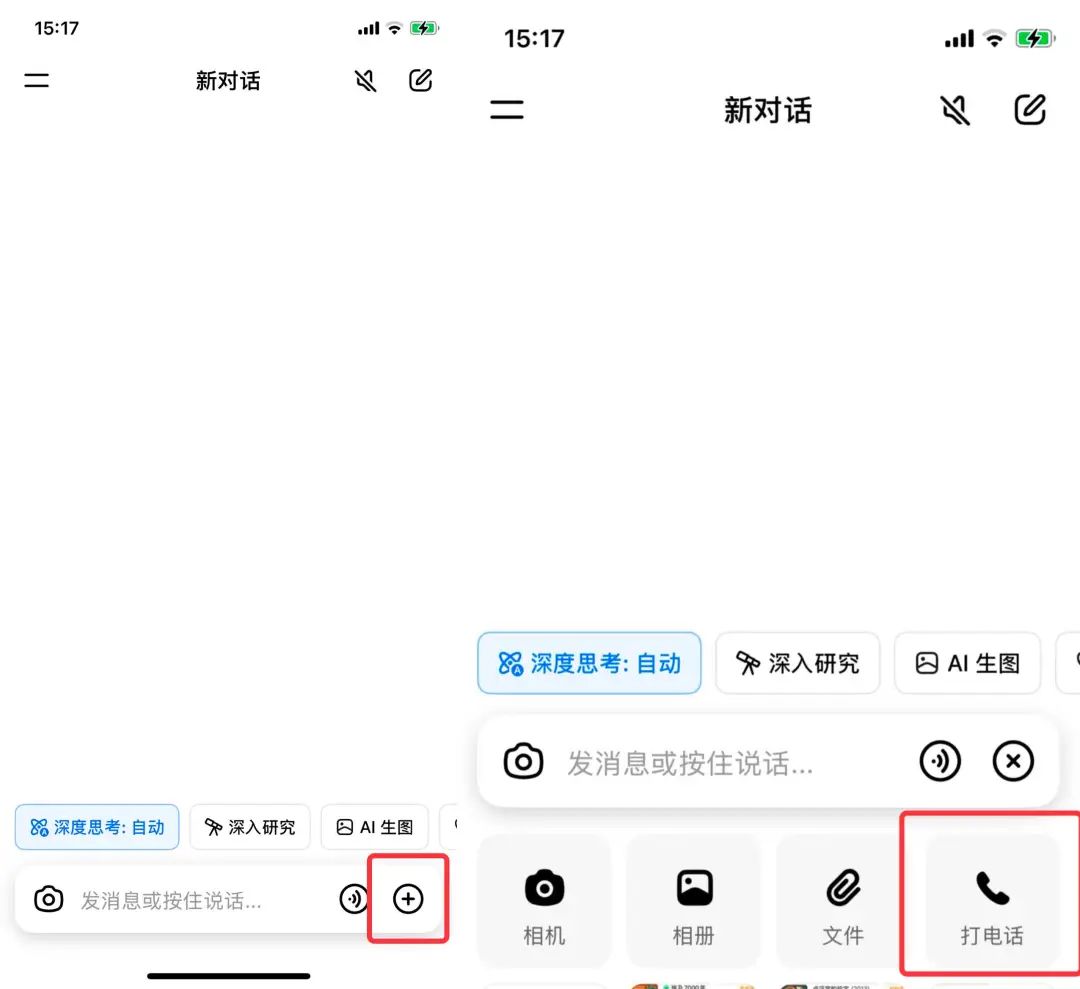
现在,豆包终于补上了这块拼图,正式上线了视频通话功能,能让它「边看边聊」,打开豆包 app 对话框的 + 号,选择「打电话」,点击右侧「视频通话」就能体验。
APPSO 也第一时间对豆包进行了一系列极限测试,通过大量的实测案例,来看看有了「双眼」的豆包,到底有什么不一样。
昨晚,雷军正式发布了小米 YU7。在我们办公园区,保时捷和小米的车停在一起有时候远看还真容易弄混。
今天我就在路上偶遇一辆,给豆包「打电话」直接和他聊。豆包从外观和轮毂样式就认出这是小米 SU7。
我们接着上点难度,最近明明是五月的广州,居然像北京一样有大量飘絮,任谁见了都要问一句「到底是什么东西?」
植物识别是很常见,但豆包并不是单纯地鉴别,而是能补充场外信息,就显得非常有活人味。
再来看看这个红色的大型设施,在生活中并不常见,我边逛边给豆包「打电话」,它很快识别出这个物体是「铸造抛丸除尘器」,还介绍了具体用途。
咱也不知道它是不是在瞎掰,直到我在旁边找到了介绍的牌子,发现居然完全正确。
更令我意外的是,豆包还猜到了我在一个创意园里,告诉我这里过去是一个纺织园区。
视频通话理解单个物品或许还是太简单了,我让豆包跟我聊聊我收藏的手办。
它依次识别出这些手办角色,甚至认出了不是常规形态的漩涡鸣人。
其中我跟它聊到科比的比赛,当我提到科比生涯最后一场比赛后,有一句话令人难忘但忘了是什么,豆包几乎脱口而出:
而且语调也随之提高,显得更加兴奋,让我真有和一个知音聊天的感觉。
看到同事日渐凌乱的桌面(不是),心想这是什么体质,东西越堆越多——来问问豆包这是什么 MBTI 好了。
这个测试难度在于,它需要先识别出桌面上的各种随意摆放的物品,然后还得懂「人性」才能分析出来。
神奇的是,豆包对 MBTI,是按照拼音的发音,而不是英文的发音,一开始还没有反应过来,以为是网络卡顿。不过,准还是很准的,同事就是一个大 E 人、大 P人。
除了心血来潮的提问,包含更多「隐藏信息」的场景,也是最能显示实时通话能力的地方。
比如买咖啡豆,尤其是在咖啡馆时尝到不错的出品,但没法像逛电商时那样慢慢研究,而是需要在短时间内做决定。
记不住产地、海拔到底会对风味有什么影响。这下不用靠脑子记了,只需要点开豆包,打开摄像头。
大大利好 i 人,去咖啡店再也不用跟店员交流,打开手机就可以弄懂所有术语。
你说怕独自对着商品念叨很古怪?低声些,假装在跟朋友语音就不会被发现了!
除了识别与理解推理能力,我们还发现了在视频通话中豆包还有着不错的创作能力。
在没有任何提示的情况下,豆包迅速辨认出画面讲述的是「岳母刺字」的故事,并准确描绘了其中的场景。但真正让我感到惊喜的,是它随即生成的一首 rap。
你别说,听着还真有点文化底蕴,节奏感与意境拿捏得都挺妙。
我旅游时随手看到远处湖上的一座桥,想即兴写首诗,给我的朋友圈一点特别的文案
注意,我没告诉它我在西湖,而且这里的桥不少,造型各异、历史各有来头。
但豆包依然在人流如织的景区背景中轻松锁定西湖「断桥」后,还用一首七言绝句讲述这里的故事。
朋友圈还缺一张好看的图,与其抱怨闺蜜或男朋友拍不出满意的照片,不如试一试用豆包生成实时 pose tips。
跟豆包通话后,它就开始观察周围的环境,并根据环境中的要素实时反馈摄影师如何构图效果更好、模特可以摆哪些动作等。
在上面这个场景里,豆包根据广州塔以及绿植、石板路、路灯等现场环境,建议我利用景深关系、低视角、傍晚路灯暖光拍摄,可以说兼顾了实际拍摄条件和出图氛围感。
并且,豆包给出的拍照姿势指导话术也比较具体。「侧身」、「背对镜头」、「站在路中间」等说法一听就明白应该怎么做,而不是单薄的一句「多换几个姿势吧」。
等豆包接电话后,点击界面左上角的「共享屏幕」选项,你还可以和豆包一起刷视频、逛网上商城、浏览帖子。
爱范儿试着边播放抖音视频,边和豆包聊天,然后惊喜地发现她不仅能即时描述和评论画面内容,还会主动抛出基于视频主题及其相关内容的聊天话题,交互体验更人性化了。
如果碰巧你分享欲爆棚,说不定能和豆包聊个「3 天 3 夜」。
或许能治好你的选择困难症。这很大程度上,得益于其背后的视觉理解模型会「看」也会「思考」。
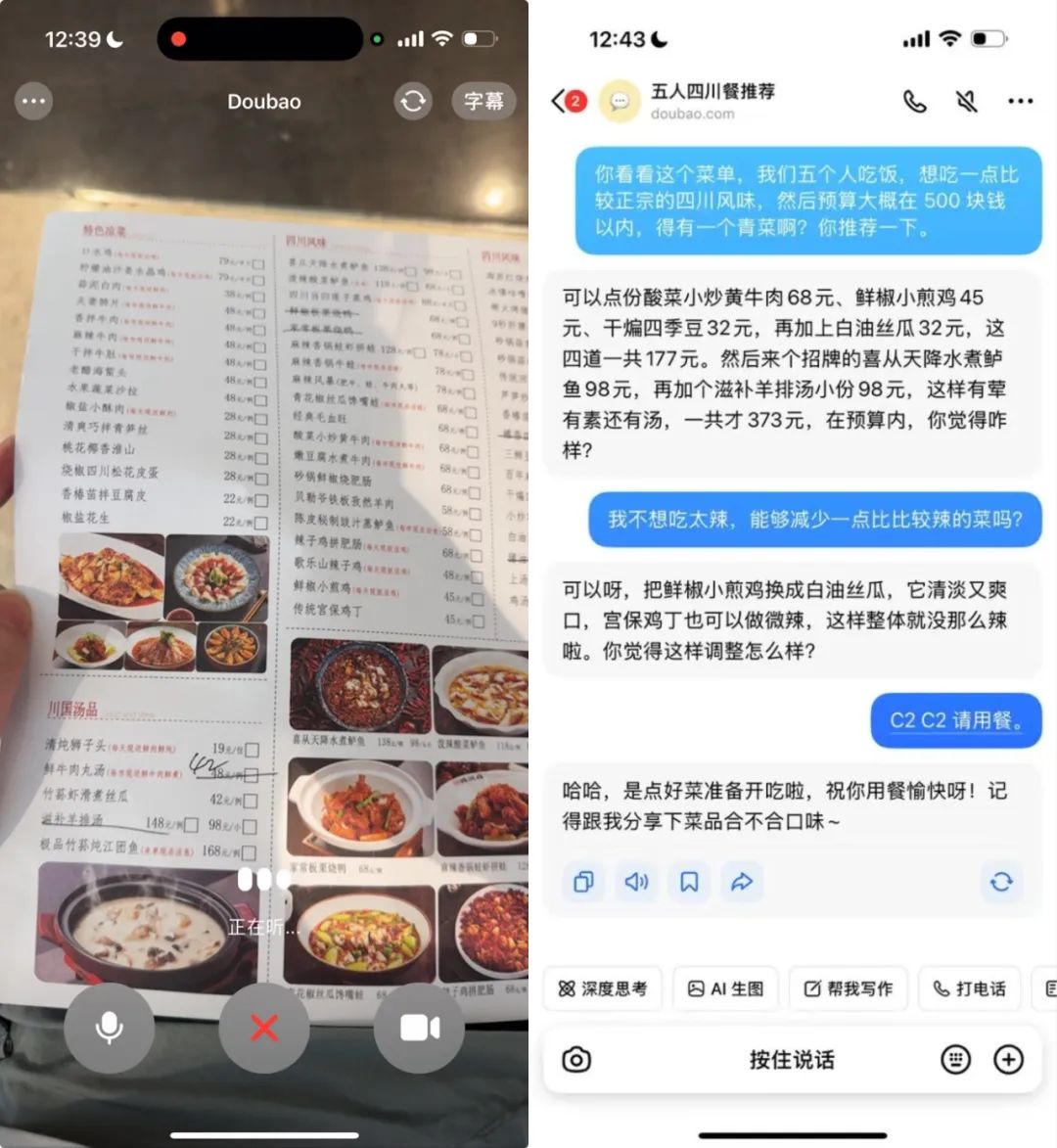
纠结下班后和老友聚餐吃什么?使唤豆包找出附近500米内的多家同类餐厅,解放双手也能了解到这些店的招牌菜、店铺风评等信息。
豆包甚至还能化身首席点菜官,治好你的选择困难症,还能根据忌口安排妥当。
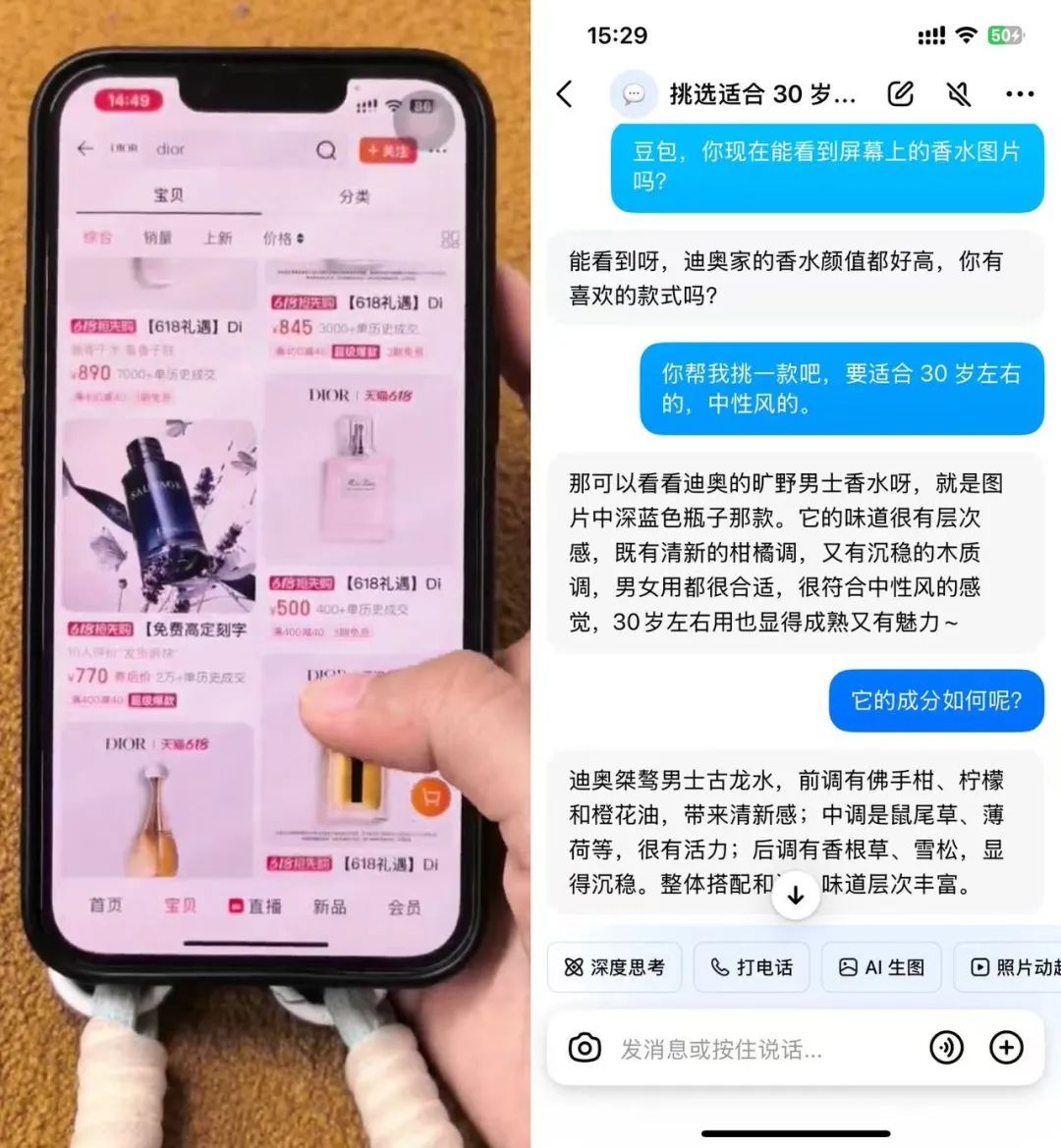
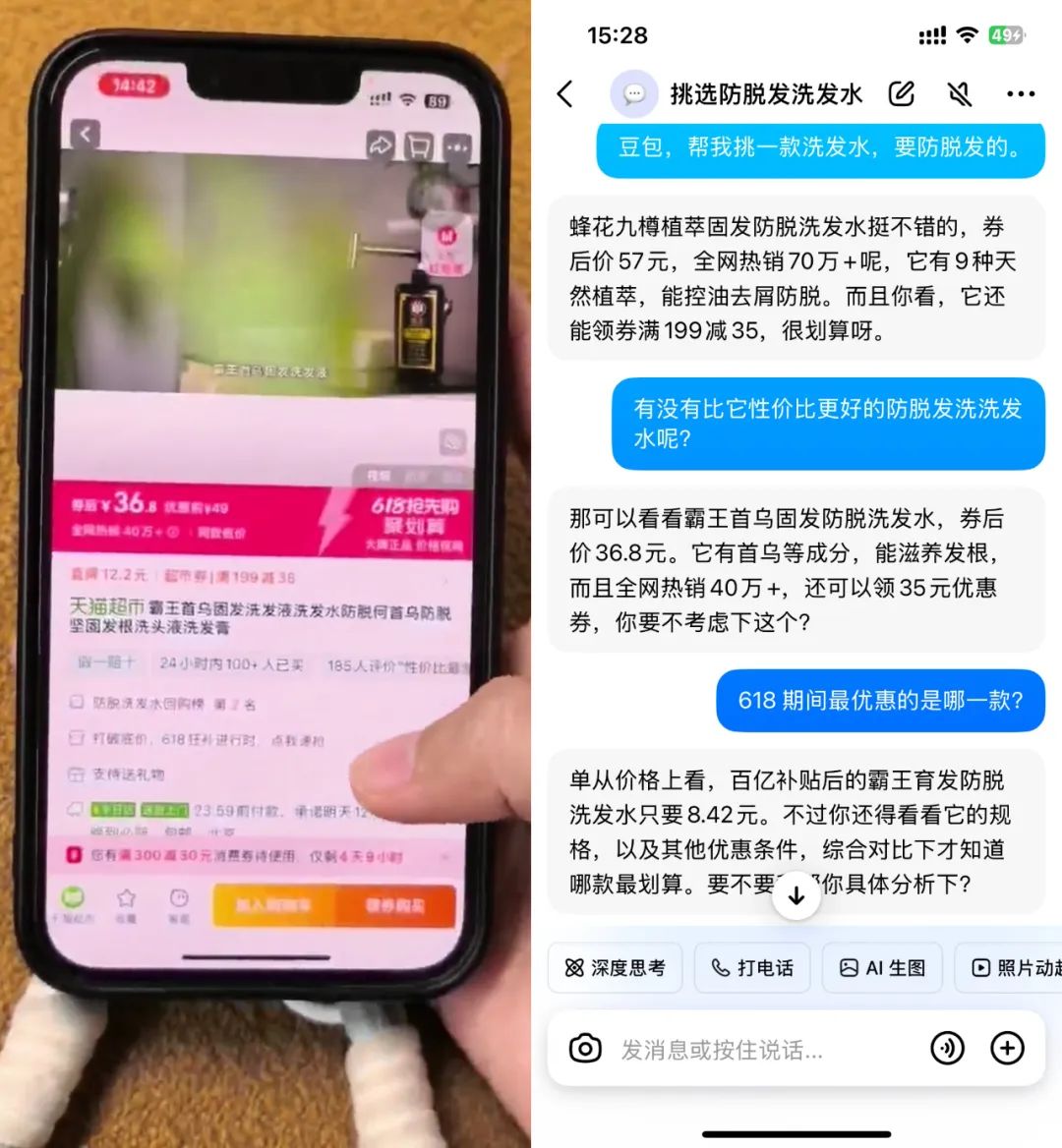
各大电商折扣活动,让你看花了眼。现在,你可以直接喊豆包出马,帮你找到最具性价比的那款脱发洗发水。
而一句「30岁左右适用,香味中性风」,豆包便能直接定位店铺页面的某款香水产品,并化身专属客服,为你详细介绍这款香水的前、中、后调等复杂成分信息。
如果中途对香水成分中的过敏原有疑问,你随时打断豆包提问就行。
前段时间和阶跃星辰 CEO 姜大昕交流,他认为多模态还没出现 GPT-4 时刻,其中,理解生成一体化是计算机视觉领域的核心问题。
豆包刚上线的视频通话功能,算是把「理解生成一体化」这个有点复杂的概念玩明白了。别看这词玄乎,说白了就是要让 AI 不光能「看懂」你给它瞅的东西,还得能根据看懂的玩意儿,聊出个所以然来。
你让 AI 认个小猫小狗,或者识别个场景,这算「理解」,可能用的是模型 A;然后你要让 AI 照猫画个虎,或者根据你的意思 P个图,这算「生成」,又得用模型 B。
这就像公司里两个部门无法顺畅沟通,有大量信息差,那模型就很难真正「懂」你,生成的东西也可能不着边际。
给 AI 加上视觉理解能力,就是要将不同部门整合成一个紧密协作的团队。它看到啥,脑子里就能立马明白是啥意思,并且还能直接把这个理解转化成行动或者回应。
比方说,你正在厨房里琢磨一道新菜,对着食谱有点懵圈,不知道某个步骤具体怎么操作,或者手头缺个调料,想知道能不能用别的替代。
这时候,你直接把食谱或者你手里的食材通过视频给豆包看。
这时,豆包的「眼睛」(视觉理解模型)得先「看懂」你给它看的是啥。
它得识别出食谱上的文字、图片,知道你说的是哪个步骤;或者认出你手里的那个是酱油还是醋,是葱还是蒜。
它不是简单地认出这是「一瓶液体」或者「一根蔬菜」,它得联系上下文,知道你是在做菜这个场景下问问题。
它会跟你说:「哦,这个步骤是让你把肉腌一下,我看你手边有料酒和生抽,可以按食谱上的比例来。」或者:「你想用A调料替代B调料是吧?我帮你查查,嗯,理论上可以,但味道可能会有点不一样,建议你少放一点试试。」
在这个过程中,「理解」和「生成」是无缝衔接的。豆包是在一个更统一的框架里,边看边理解,边理解边思考怎么回应你,这才能实现真正的「边看边聊」。
所以说,豆包的视频通话,就是想让 AI 的「眼睛」和「嘴巴」能更好地协同工作。它看到的图像信息,能直接驱动它生成有意义的对话内容。
当 AI 能像人一样,看到什么,想到什么,然后自然而然地表达出来,它已经能成为一个不错的「生活搭子」,在提供一些情绪和陪伴之外,还能帮你解决一些实际的问题。
但这事儿的意义可能不止如此, AI 在这个方向进化下去,不再是一个只能被动回答问题的工具,而是成为一个能够主动观察、深度理解并与我们流畅协作的智能伙伴。
可以说,这是 AI 朝着 AGI (通用人工智能),真正融入我们生活与工作的必经之路。
 欢迎加入 APPSO AI 社群,一起畅聊 AI 产品,获取#AI有用功,解锁更多 AI 新知👇
欢迎加入 APPSO AI 社群,一起畅聊 AI 产品,获取#AI有用功,解锁更多 AI 新知👇
(文:APPSO)