


新智元报道
新智元报道
【新智元导读】AI是否真正在「思考」乃至产生意识,正成为科学和哲学交汇的核心议题。前OpenAI负责人翁荔认为,增加模型的「思考时间」有助突破复杂推理瓶颈;哈佛等机构则指出思维链可能导致「降智」;而生物学家Mallavarapu断言数字计算机永不可能拥有意识。
以推理模型为代表的AI是否真在思考?未来的它们会进化出意识吗?
在模型——思考——意识这种终极问题面前,有下面三个观点:
-
模型增加「思考时间」(即测试时计算)能提升其性能和推理能力。
-
推理模型思考太多不仅无法提升能力,还会「降智」。
-
(跑在)数字计算机(上的推理模型)永远不可能具有意识
这三个截然相反又似乎相互联系的观点,来自最近关于AI的三篇论文/博客:
第1个观点来自前OpenAI应用AI研究负责人,北大毕业的LilianWeng(翁荔)
让模型在预测之前有更多的时间思考,比如通过思路链推理等,对于解除下一层次的智能障碍非常有效。
翁荔最新关于推理模型《Why we think》的文章一度出圈
第2个观点来自哈佛大学、亚马逊和纽约大学的最新研究(2025年5月16日),通讯作者Xiaomin Li,是一位在哈佛大学攻读应用数学博士学位的学生。
思维链(Chain-of-Thought)并不总是锦上添花,有时候,它会让大模型越想越错!

第3个观点来自加州大学旧金山分校博士,哈佛医学院系统生物学系虚拟细胞计划创建者Aneil Mallavarapu,同时也是企业家和投资者。
从物理学和复杂性理论出发,可以推断出数字计算机永远不可能具有意识。

如果AI最终没有意识,那么现在针对推理的模型努力是「镜中花,水中月」吗?
给推理模型更多时间去「思考」,到底是在帮助它突破瓶颈,还是在把它推向自我迷惑的深渊?
或者,基于数字计算机的推理模型,真的无法达到「意识」境界?

翁荔的观点是:多给模型「思考」时间,可以大幅提升复杂任务中的表现。

首先她用人类思维类比,大模型也需要从「快系统(System1)直觉」转向「慢系统(System2)理性思考」。
这个概念来自于那本著名的《思考,快与慢》,对于复杂问题,人类通常倾向于花时间思考和分析后,逐步得出结论。
翁荔认为如果将计算能力当做一种资源,神经网络的能力大小在于其能够调动的计算资源有多大。
模型本质上是通过计算的排列组合,构成了一个「电路」,类似各种神经元之间的联结。

训练过程(梯度下降)不仅是学习任务本身,更是在「探索」如何以最有效的方式使用已有计算资源。
模型在训练过程中自行发现如何在给定资源约束下,建立高效的信息处理和存储结构。
如果模型被训练成一种能够适应不同计算资源水平的架构,那么在测试时允许模型使用更多计算(如CoT推理),等价于给了模型更多资源去充分发挥潜能。
增加测试时计算(比如CoT)可以提高模型在复杂推理任务中的表现,尤其是数学、代码、逻辑等任务。
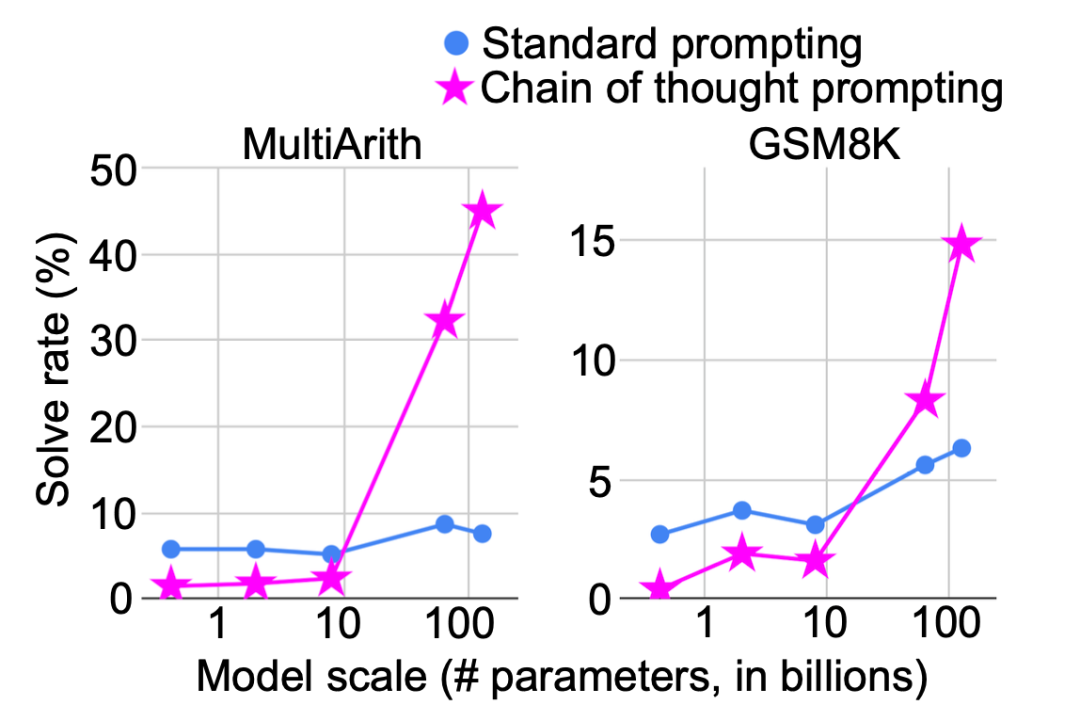
CoT提高了数学问题的解决成功率
测试时计算的基本目的是在「思考」中自适应的修改模型的输出分布。有多种方式可以利用测试时资源进行解码,达到选择更好的样本的目的。
改进解码过程主要有两种方法:并行采样和顺序修正。
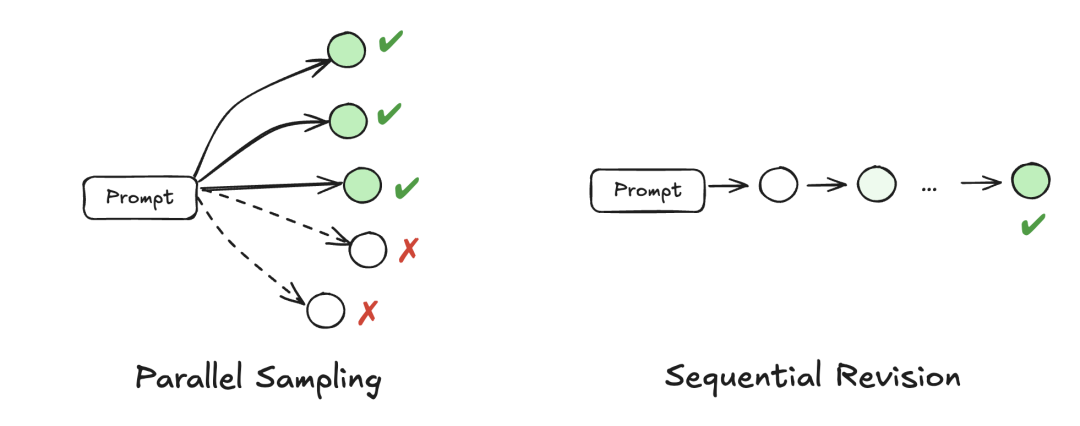
并行采样简单、直观易于实现,但是受限于模型能否一次性得出正确解的能力。
顺序采样则明确要求模型反思错误,但速度就慢了,甚至有可能将正确的预测修改为错误。
根据这些特点,简单的任务就并行,对于较难的问题,通常使用顺序计算。(关于并行和顺序具体的方法本文就略过,感兴趣可看原博客)
最近比较火的是使用强化学习来获得更好的推理能力,比如DeepSeek-R1和OpenAI的o系列模型。
以开源的DeepSeek-R1为例,它经历了两轮SFT-RL训练,先监督微调确保基本格式和可读性,然后就直接上RL。R1训练过程如下图所示,R1最终是由V3生成的SFT数据结合纯RL训练的一个节点而创造出来的。
在这个过程中,最有趣的要数DeepSeek公布的模型自己的「啊哈」时刻。
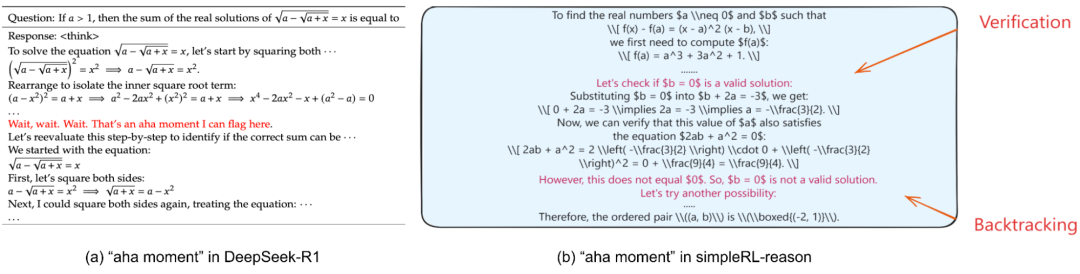
完全使用强化学习(RL)的方法,无需监督微调(SFT)阶段,仍然可以学习到诸如反思和回溯等高级推理能力。
在RL训练过程中,模型自然学会了在解决推理任务时分配更多的思考Token。
顿悟时刻由此产生,指的是模型能够反思之前的错误,并尝试替代方法予以纠正。
随后,出现了多个开源项目尝试复现R1的成果,例如Open-R1、SimpleRL-reason和TinyZero,它们均基于Qwen模型。
这些尝试也证实了纯强化学习在数学问题上具有出色的性能,同时也再次验证了顿悟时刻的出现。
以上内容都表明,只要给足思考时间,模型就会变得更聪明。
翁荔也提到了一些其他的促进模型思考的方法,比如:
外部工具(比如专业用来计算33/8=?)的使用来促使模型更好思考;
监控CoT的过程,让模型更加忠实的思考,因为监控可以发现比如奖励黑客攻击等行为;
翁荔还探讨了在连续空间中思考、将思考视为潜在变量和思考时间的Scaling Law等方法,限于篇幅就不展开。

ChatGPT给出的关于在「连续空间中思考」的直觉理解
思考时间的Scaling Law类似于大模型参数Scaling Law,并且有研究发现优化 LLM 测试时的计算可能比扩大模型参数更有效。
给模型额外「思考轮次」(修订或搜索)确实能显著提高解题正确率,且随预算递增呈边际递减但仍稳步上升。

翁荔最后的结论其实就是对测试时计算和思维链推理的探索为增强模型能力提供了新的机会。
更有趣的是,通过测试时思维,我们正朝着构建未来人工智能系统的方向迈进,这些系统能够模仿人类思维的最佳实践,包括适应性、灵活性、批判性反思和错误纠正。
简单地说,翁荔认可现在推理模型走上这条进化之路,并且给于模型越多的时间和资源进行思考,模型越有可能模仿人类思维。
正所谓Why we think——因为想的越多,越聪明。
从这个角度来看,推理模型还真挺像人的。
大部分人和翁荔的看法是一致的,毕竟DeepSeek-R1和OpenAI o系列证明了推理模型的有效性。
但一篇来自哈佛/亚马逊团队的论文提出一个观点:
思维链(Chain-of-Thought)并不总是锦上添花,有时候,它会让大模型越想越错、越帮越忙!
在需要遵守指令或格式的任务中,使用CoT推理,模型遵守指令的准确率会下降!
在文章《CoT推理大溃败?哈佛华人揭秘:LLM一思考,立刻就「失智」》中展示了研究人员对具体模型的测评结果。
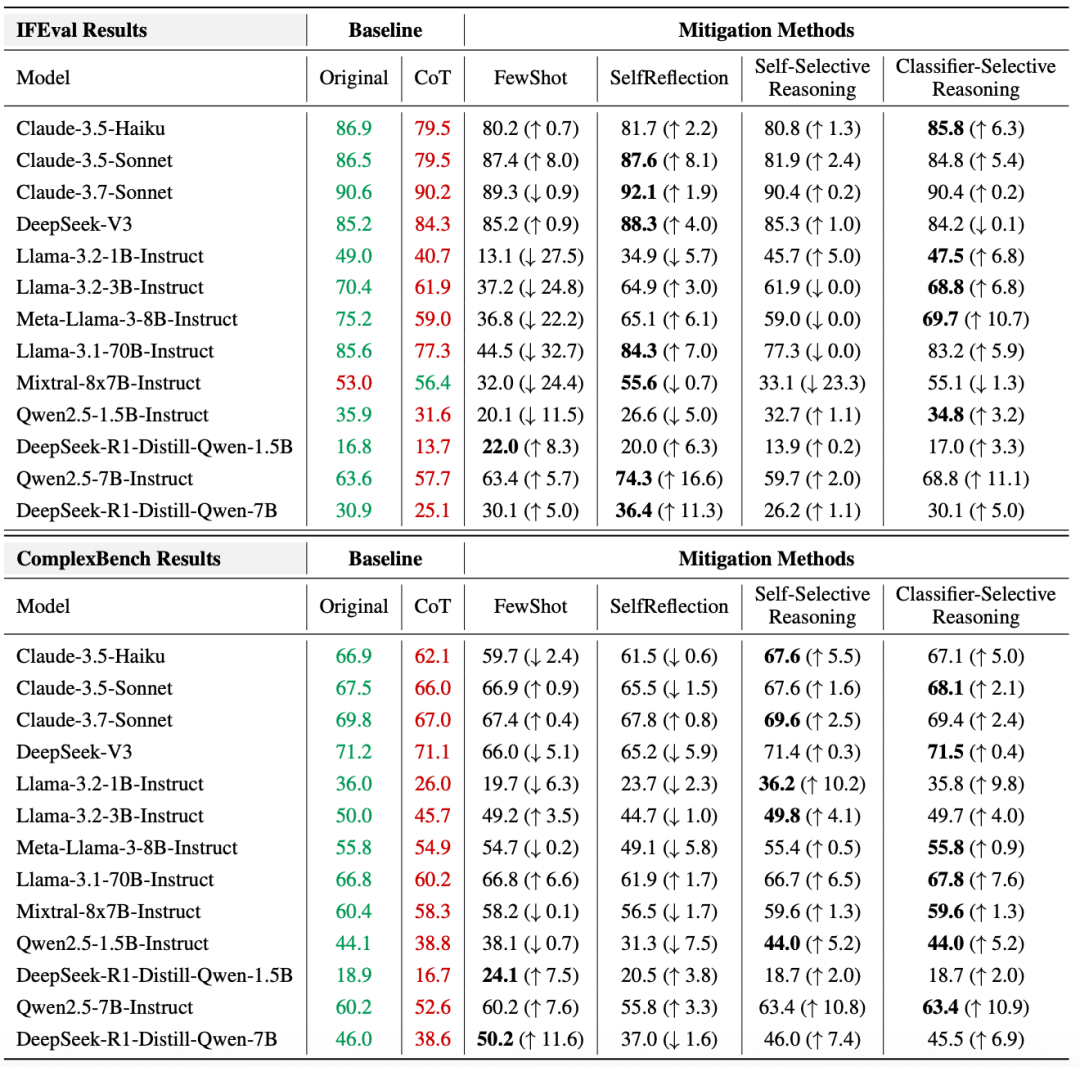
其中绿色与红色分别标识原始模式与CoT模式的性能。
各改进方法列同时报告绝对准确率及相对于CoT模式的变化(↑表示提升,↓表示下降),最优改进方案用加粗字体标出。
结果是,几乎全部CoT模型都不如原始模型,可以说推理越多,表现越差!
研究团队给出的结论是,CoT会分散模型「注意力」,模型有时候会「越想越偏」,甚至可能自信地犯错。
比如,如果你让模型执行「XXXX,结果只输出选项A或B」,那它的注意力就应该聚焦在指令里的关键约束词上,比如「A或B」。
然而,CoT推理的引入却改变了这种聚焦机制:当你让模型「一步步来思考」时,它反而会被自己的推理内容吸引,逐渐忽略最开始的指令约束。
这里我们不关注后续研究团队提出的改进办法,而是将「注意力」放在CoT会分散模型注意力。
在哈佛的这篇研究中,「CoT会分散模型注意力」这个结论和人类也非常的像。
很多时候,我们在思考一个难题,难免思维会发散,就像一棵不断分叉的树,越思考枝叉越多,也离最开始的目标越远。

CoT能帮助模型思考,CoT太多又会分散模型注意力,不论从正反哪个角度看,似乎推理模型都有了那么点「人味」。
难道推理模型再进化下去——也许是OpenAI的o10,或者DeepSeek-R5——一定能够产生意识吗?
在讨论大模型能否产生意识前,让我们往后退一步,回到目前承载数万亿参数的计算机形态以及为何顶尖科学家,比如辛顿,大部分都相信「AI有意识」。
首先关于人类意识还没有一个非常权威的结论。
许多科学家和工程师认为,意识是从计算机和大脑中的离散相互作用的部分产生的。
Aneil Mallavarapu从物理学和复杂性理论论证了意识可能源于非经典物理现象,所以冯诺依曼的经典结构计算机不可能产生意识。
作为科学家,Aneil Mallavarapu主张重回以人类和生物系统为基础的科学研究路径。
技术可以塑造我们的思想。
当电被发现时,理论家和作家们抓住了「电是驱动生命的力量」这一观点不放。
这启发了玛丽·雪莱创作出一道闪电赋予弗兰肯斯坦怪物生命的场景。
当一项强大的新技术出现时,它会重塑文化,并成为一种思维方式。
这个过程被称为技术框架效应。
过去,猜测计算机是否有意识只是大学宿舍里闲聊的话题,但现在,许多人工智能领域的领导者认为,在他们所创造的智能体中,蕴含着某种答案。
Open AI的前首席技术官Ilya Sutskever曾表示,他认为自己公司的产品ChatGPT可能「稍微有意识」。
2023年的一次研究人员会议上,Ilya说他们将在通用人工智能 (AGI) 出现之前建造一座(地堡)掩体——当然,你是否想进入掩体是可选的。
图灵奖得主、Meta 人工智能部门负责人Yann LeCun则认为还需要做更多工作,但只要有了正确的算法,就一定能实现。
LeCun讽刺了那些不相信计算会导致意识的人,称他们就像18世纪认为生命只能通过神秘的「活力论」来解释的思想家一样。
以上两人的观点绝非个别——他们代表着一股日益壮大的思潮,尤其是在科技工作者、哲学家和未来主义者当中,甚至连科学家也持此观点。
物理学家萨宾娜·赫森费尔德(Sabine Hossenfelder)最近评论说,她「看不出计算机无法拥有意识」的理由。
这些观点并不仅仅是边缘信念。
一项近期民意调查显示,许多人预计AI将在五年内获得自我意识,其中38%的人支持赋予Ai法律权利,69%的人赞成禁止具有自我意识的AI。
但是Aneil Mallavarapu认为似乎人类走在错误的道路上:
我在哈佛大学系统生物学系从事构建复杂生物系统数学模型的语言方面的工作,这使我具备了跨越计算机科学、数学和生物学的视角,而我的研究生工作则专注于神经元。
出于好奇,我参加了第二届意识科学会议,那已经是30年前的事了。
从那时起,我一直有一种挥之不去的怀疑,即纯粹哲学和计算方法在意识研究上走错了方向,我们需要以严谨的科学和数学分析来解决这个问题。
对于AI能力的期待,人们似乎喜欢用名字赋予它生命感,通用人工智能AGI、还是超级人工智能ASI,或者强人工智能Strong AI,但不论是哪一种,都会最终回到同一个问题:意识是什么,它是如何产生的?
哲学家Thomas Nagel曾思考过「成为一只蝙蝠的感觉是什么」,以此来强调主观体验无法被外部观察和直接理解。
另一个挑战ASI/AGI/Strong AI的例子就是著名的「中文屋」实验,从外部看,这个房间似乎完全理解中文并能作出合适的反应;但房间内的人其实根本不理解中文,他只是在机械地执行规则。

一个计算机系统,即使表现出智能行为,也并不意味着它真正具备「理解」或「意识」。
计算机不过是通过操纵符号并执行规则来工作,它们并不真正具备人类所拥有的主观体验或意义理解。
如果将这个结论继续下放到翁荔和哈佛团队所讨论的CoT,那就是数字计算机即使拥有无限的CoT,仍无法产生主观体验——也就是AI无法产生意识。
意识作为一种独特的自然现象,无法适用于传统的科学方法。
Aneil Mallavarapu认为基于物理学、复杂性和可计算性理论的基本原理——数字计算机若不违反科学家和AI支持者所珍视的观念,就永远无法拥有意识。
我们并不完全了解大脑是如何运作的,但数字计算机是由我们设计的,因此我们知道它们的确切工作原理。
它们的行为源于一套简单的特性:读写内存的能力、条件逻辑、一组有限的规则以及执行顺序操作的能力。
AI也一样,只不过是将token转化为一系列的词向量,最终变成计算机中的二进制代码。
如果经典科学无法产生意识,自然而然地,我们会想到量子力学/量子纠缠。
而人类的大脑中产生的意识是通过经典科学还是量子纠缠产生的?
有一种大脑的双重模型模型,大脑黑暗的部分以经典方式计算,但无意识,然后将结算结果传递给明亮的、有意识的、非经典的脑区。
然而,如果意识与量子纠缠态相关,那么大脑的许多部分为何看起来却是一个经典的信息处理网络——人类以此为启发创造出当下的大模型AI,并且还发明了大模型的Scaling Law。
这个问题依然有待脑科学的进步来回答。
从翁荔的总结,到哈佛团队的最新发现,再到Aneil Mallavarapu的思考,不难发现——
推理模型引发的关于AI与意识的争论,已不仅仅是技术路线之争,更是关于人类认知边界的深刻反思。
在大模型技术的高歌猛进中,创造出的AI越来越像人,它会规划、会反思、甚至还有顿悟般的「啊哈」时刻。
这也是当技术、资本和大众都在为之狂欢时,为何AI之父辛顿等人会表现出对人类担忧的根本原因吧。
对于「AI思考」的思考,不会止于AI,更归于人类自身的未来。
(文:新智元)