


极市导读
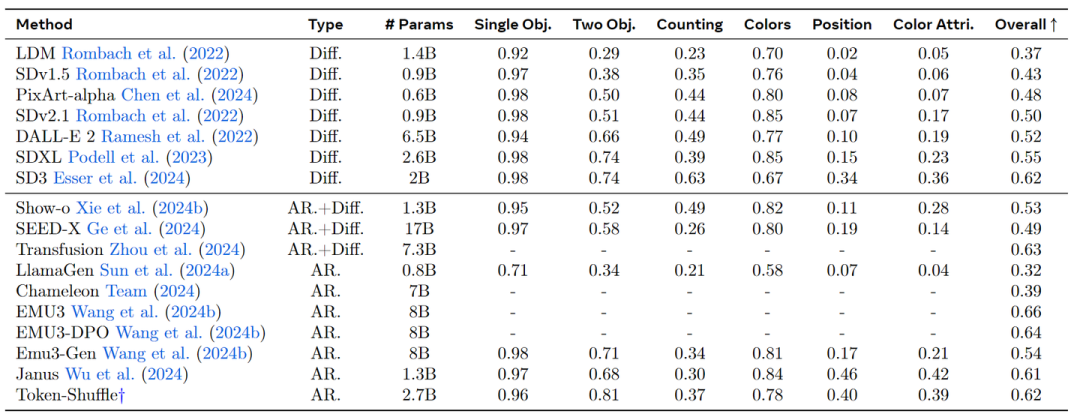
首词将 AR 文生图推到 2048 × 2048 的分辨率,并具有令人印象深刻的生成性能。在 GenAI-benchmark 中,本文 2.7B 模型在硬提示上实现了 0.77 的分数,比 AR 模型 LlamaGen 高出 0.18,扩散模型 LDM 高出 0.15。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 Token-Shuffle:自回归高分辨率图像生成
(来自 Northeastern University, Meta 等)
1.1 Token-Shuffle 研究背景
1.2 Token-Shuffle 做法
1.3 图像生成的局限性
1.4 视觉维度冗余
1.5 Token-Shuffle 具体操作
1.6 实验设置
1.7 实验结果
太长不看版
通过减少 token 来实现高分辨率自回归图像生成。
本文研究的是自回归 (AR) 图像生成问题。AR 模型普遍被认为不如 Diffusion 更具竞争力。一个主要的限制因素是 AR 模型需要大量的 image token,限制了训练和推理效率,以及图像分辨率。
本文为了把训练的分辨率拉上去,从架构的角度入手,提出了 Token-Shuffle,来减少 Transformer 中 image token 的数量。本文的关键 insight 是 MLLM 视觉词汇表存在维度冗余,其中来自 vision encoder 的低维视觉代码直接映射到高维语言词汇表。
Token-Shuffle 的做法是:沿着 dimension 的维度合并局部 token,减少 token 数量。Token-Unshuffle 的做法是对称的。
与文本提示联合训练,本文模型无需额外的预训练 text encoder,并使 MLLM 能够以 next-token prediction 的范式支持高分辨率图像生成,且同时保持高效的训练和推理。本文第一次将 AR 文生图推到 2048 × 2048 的分辨率,并具有令人印象深刻的生成性能。在 GenAI-benchmark 中,本文 2.7B 模型在硬提示上实现了 0.77 的分数,比 AR 模型 LlamaGen 高出 0.18,扩散模型 LDM 高出 0.15。

1 Token-Shuffle:自回归高分辨率图像生成
论文名称:Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
论文地址:
https://arxiv.org/pdf/2504.17789
项目主页:
https://ma-xu.github.io/token-shuffle/
1.1 Token-Shuffle 研究背景
LLM 通过自回归地预测序列中的 next-token 在自然语言处理领域取得了成功。最近,一些工作尝试把 LLM 拓展到图像生成领域,像 Llamagen,Chameleon,Emu 等等。
那么自回归图像生成,一般有两种策略:无非是使用连续的视觉 token,还是离散的视觉 token。Kaiming 的 Fluid 指出,连续 token 可以提供更优越的图像质量,且需要更少的 token,提供了显著的计算效率。相比之下,离散 token 通常会产生较低的视觉质量,并且 token 数相对于图像分辨率呈现出二次方增加。但是,离散 token 与 LLM 更兼容。另一方面,连续 token 需要对 LLM pipeline 进行修改,包括使用额外的损失函数 (比如 MAR 的 Diffusion Loss)。此外,没有很强有力的证据表明连续 token 的范式对 MLLM 文本生成的影响比较小,也就意味着连续 token 的范式也可能会影响文本生成。因此,EMU3 和 Chameleon 等大规模、真实世界的 MLLM 在实践中主要采用离散视觉 token。
像 LlamaGen,Chameleon,和 EMU3 这样的工作的 image tokenizer,就使用 vector quantization 的技术把图片转化为离散 tokens,以允许自回归 Transformer 以类似于生成语言的方式生成图像。这个方法面临的限制之一是生成图片的分辨率。不像语言通常需要几十个到几百个 token,图像需要更多的 token (例如,4K 个 token 来生成 1024×1024 分辨率的图像)。由于 Transformer 的二次计算复杂度,这种巨大的 token 数量要求使得训练和推理成本高得令人望而却步。因此,大多数 MLLM 仅限于生成低分辨率或中等分辨率的图像,就很难去挖掘高分辨率图像的好处,比如细节,保真度等等。
虽然支持长上下文生成的高效 LLM 已经有许多工作 (这些工作也有利于高分辨率图像生成),但通常涉及到架构修改,忽略了现成的 LLM,或者干脆是针对语言生成进行优化,而不是利用图像的独特属性。因此,需要为 MLLM 开发使用离散视觉 token 做高分辨率生成的方法。
1.2 Token-Shuffle 做法
首先将视觉 token 集成到 LLM 词汇表中。常见的做法是将视觉标记器码本与原始 LLM 词汇表拼接起来,形成一个新的多模态词汇表。虽然很简单,但这种方法忽略了维度的内在差异。例如,在 VQGAN 中,codebook 向量的维度相对比较低,比如 256。这种低维已被证明足以区分向量,并已被证明可以提高码本的使用和重建质量。但是,直接将视觉 tokenizer 的 codebook 附加到 LLM 词汇表中会导致向量维度急剧增加,达到 3072 或 4096 甚至更高。这种急剧增加不可避免地为添加的视觉词汇引入了无效的维度冗余。
Token-Shuffle 就是受此启发,为 MLLM 设计的即插即用操作。Token-Shuffle 显著减少用于视觉 token 的数量,提高高分辨率图像生成的效率。Token-Shuffle 的灵感来自于图像超分技术中的 Pixel-Shuffle,沿通道维度融合视觉 token。
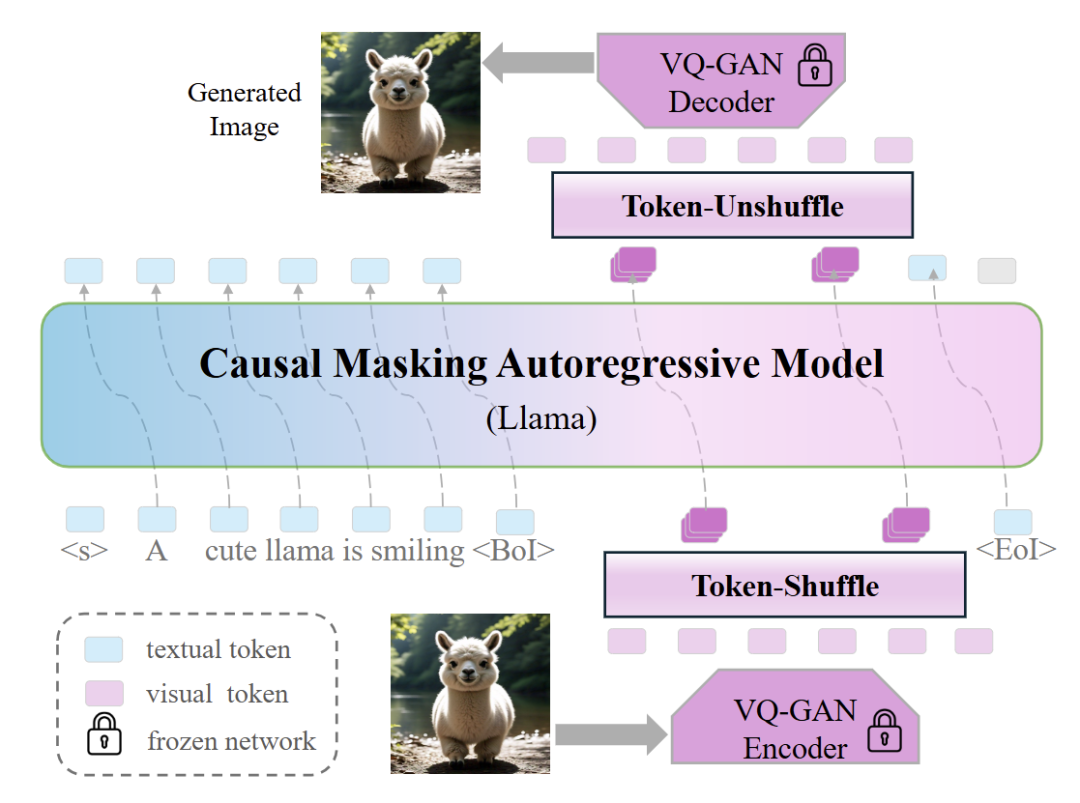
Token-Shuffle 的思想就是在一个 local window 内部做 token 的处理或者生成。这种方法大大减少了视觉 token 的数量,同时保持高质量的生成。当窗口大小设置为 2 时,可以节约大概 75% 的 token。传统视觉编码器所依赖的激进压缩比,而 Token-Shuffle 是利用了视觉 token 的维度冗余来保留细粒度信息。
Token-Shuffle 第一次将自回归图像生成的边界推到 2048×2048 的分辨率,并使其能够超越,同时仍然享受高效的训练和推理。使用 2.7B Llama 模型,Token-Shuffle 在 GenEval 上实现了 0.62 的 overall score,在 GenAI-bench 上实现了 0.77 的 VQAScore,明显优于相关的自回归模型,甚至超过了扩散模型。
1.3 图像生成的局限性
为了使 LLM 能够进行图像合成,作者将离散的视觉 token 合并到模型的词汇表中。利用 LlamaGen 的预训练 VQGAN 模型。它将输入分辨率下采样 16 倍。VQGAN codebook 包含 16,384 个 token,这些 token 与 Llama 的原始词汇表拼接。特殊的 token 比如 <|start_of_image|> 和 <|end_of_image|> 被用来封装离散视觉 token 序列。在训练期间,所有 token (包括视觉和文本) 都用于计算损失。
虽然很多模型,比如 Llamagen,已经证明了离散视觉 token 在 MLLM 中的图像生成的能力,但一个不可避免的问题是高分辨率图像的视觉 token 数量令人望而却步。为了生成分辨率为 1024×1024 的高分辨率图像,如果使用下采样 16 倍的 tokenizer,总共需要 (1024/16) × (1024/16) = 4096 个视觉 token。与语言语料库相比,这样的许多视觉标记使得训练非常缓慢,推理效率非常低。这也将在很大程度上限制生成的图像质量和美学。如果我们进一步将分辨率提高到 2048×2048,它将对应于 16K 个视觉 token,这在 next-token prediction 的范式下对于高效训练和推理不切实际。
原则上,增加视觉 token 的数量可以产生更详细、美观的图像,分辨率更高。但也会带来令人望而却步的计算和通信负担。之前的方法总是面临权衡:持久地增加训练和推理成本,或者牺牲图像分辨率和质量。解决这一困境对该领域特别有价值,因为人们一直都在寻找可以 balance 生成效率和保真度的方法。
1.4 视觉维度冗余
如上文所述,赋予大型语言模型 (LLM) 具有图像生成能力的常见策略是将视觉 codebook token 附加到语言词汇表中。虽然概念上简单,但此方法会导致视觉 token 的 embedding 维度显著增加。
作者认为:这种将离散视觉 token 直接合并到 LLM 词汇表中的常用方法引入了固有的维度冗余。为了研究这一点,作者使用维度为 3072 的 2.7B Llama 的 MLLM 进行了一个简单的研究。对于视觉词汇表,引入了两个 Linear 来线性减小和扩展 embedding 维度。这样一来,视觉词汇表的 rank 就被限制为 ,其中 是压缩率。作者对于具有不同 值的模型,训练了 55 K iterations。
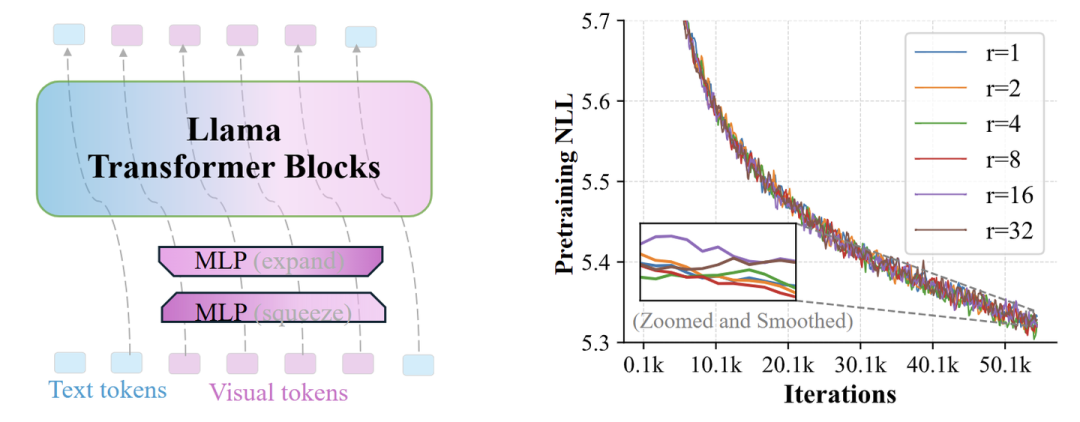
图 3 显示出视觉词汇存在相当大的冗余,因为可以将维度压缩多达 8 倍,而不会显著地影响生成质量。当使用更大的压缩率时,可以观察到损失会轻微增加。
1.5 Token-Shuffle 具体操作
受视觉词汇表中维度冗余的启发,Token-Shuffle 这个即插即用操作可以减少 Transformer 中的视觉 token 数,提高计算效率并实现高分辨率图像生成。
Token-Shuffle 操作
Token-Shuffle 并不是去减少视觉词汇的维度冗余,而是利用这种冗余来减少视觉 token 数量以提高效率。具体来说就是把空间中局部的视觉 token 去 shuffle 为单个 token,然后将融合的视觉 token 和文本 token 一起输入到 Transformer。使用一个 MLP 层来压缩视觉 token 的维度,确保融合的 token 与原始 token 具有相同的维度,确保融合的 token 与原始 token 具有相同的维度。假设 代表局部 shuffle window size,Token-Shuffle 将 token 数减少了 倍,显著减轻了 Transformer 架构的计算量。
Token-Unshuffle 操作
Token-Unshuffle 是为了恢复原始的视觉 token,将融合的 token 分解为局部视觉 token,并使用额外的 MLP 层来恢复原始维度。
还在两个操作中引入了残差 MLP 块。整个 Token-Shuffle pipeline 如图 2 所示。
本质上,不会在推理过程中或训练期间减少 token 的数量,而是在 Transformer 计算期间减少 token 的数量。
图 4 说明了 Token-Shuffle 方法的效率。此外,Token-Shuffle 不是严格遵守 next-token prediction 范式,而是预测下一个 fused token,允许在单个步骤中输出一组局部视觉 token,这就可以显著提高效率并使高分辨率图像生成对于 AR 模型是可行的。
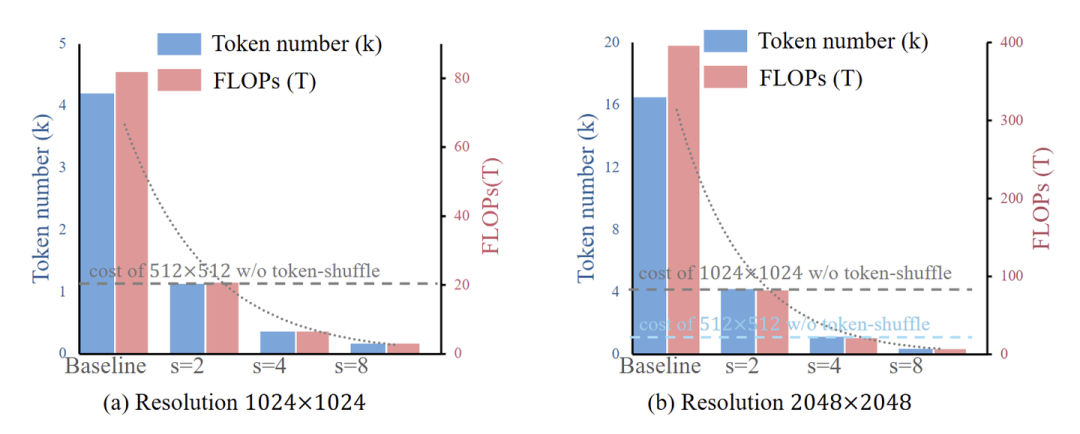
实现细节
1.对于 Transformer 输入,首先通过 MLP 层,将维度从 映射到 ,将视觉词汇表的维度压缩 倍,其中, 表示 Transformer 维度。
2.接下来,局部 视觉 token 被 shuffle 为单个 token,将每张图像的 token 总数从 减少到 ,同时保持整体维度。
3.为了增强视觉特征融合,添加了 个 MLP Block。
4.对于 Transformer 输出,Unshuffle 操作将每个输出视觉 token 扩展为 个 token。
5.然后是一个 MLP 层将维度从 恢复为 。
6.为了细化特征提取,使用额外的 MLP Block。
为了简单起见,Token-Shuffle 和 Token-Unshuffle 都使用了 个 MLP 层,其中每个 MLP Block 由 2 个具有 GELU 激活的线性投影组成。
1.6 实验设置
使用 2.7B Llama 模型进行了所有实验,Llama 模型的维度为 3072,由 20 个自回归 Transformer Block 组成。遵循 Emu,在 licensed dataset 上训练。为了训练 2048×2048 的高分辨率图像,排除了分辨率小于 1024×1024 的图像。模型是用预训练的 2.7B Llama checkpoint 初始化的,并以 2e−4 的学习率开始训练。所有图像 caption 都由 Llama3 重写,以生成长提示,其被证明有助于更好的生成。
分 3 个阶段对模型进行预训练,从低分辨率到高分辨率图像生成。
-
使用 512×512 分辨率的图片训练模型,不使用 Token-Shuffle 操作,因为在这个阶段视觉 token 的数量并不多。这个阶段在大约 50B token 上训练,使用 4K 的序列长度、512 的 global batch size 训练总共 211K steps。 -
将图像分辨率增加到 1024×1024,并引入 Token-Shuffle 操作来减少视觉 token 的数量,以提高计算效率。这个阶段,扩展到 2 TB 训练 token。 -
将图像分辨率增加到 2048×2048,在 300 B tokens 上训练。
与对较低分辨率的训练不同,作者观察到处理更高分辨率的 (例如 2048×2048) 总是导致训练不稳定,损失和梯度值意外增加。为了解决这个问题,使用 z-loss,它稳定了对非常高分辨率图像生成的训练。
作者在 1,500 个高美学质量的图片上,以 4e-6 的学习率微调不同阶段的模型。默认情况下,可视化和评估是基于分辨率为 1024×1024 上微调的结果,Token-Shuffle window size 为 2,除非另有说明。
1.7 实验结果
虽然 FID 或 CLIPScore 通常用于 class-conditioned 图像生成任务的评估,但众所周知,这些指标对于文生图是不合理的。
本文考虑了两个 Benchmark:GenEval 和 GenAI-Bench。GenAI-Bench 使用 VQAScore 作为自动评估指标,其微调一个视觉问答 (VQA) 模型以生成 text-image alignment score。由于训练字幕是类似于 LlamaGen 的长字幕,因此报告了基于 Llama3-rewritten prompt 的结果,用于字幕长度一致性。
图 5 的结果突出了 Token-Shuffle 的强大性能。与其他自回归模型相比,Token-Shuffle 在 “basic” prompts 上的总体得分为 0.14,在 “hard” prompts 上比 LlamaGen 高出 0.18。与基于强扩散的基线相比,Token-Shuffle 在 “hard” prompts 上的总体得分上超过了 DALL-E 3 0.7。
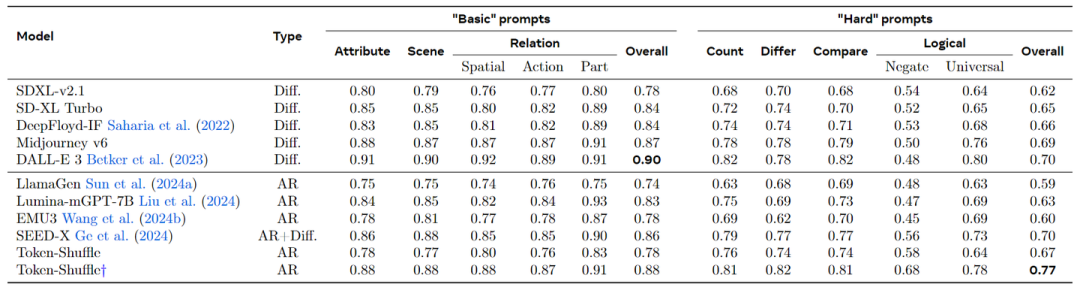
图 6 报告了 GenEval 详细的评估结果。实验结果表明,Token-Shuffle 是一种纯 AR 模型,能够呈现很 promising 的生成质量。
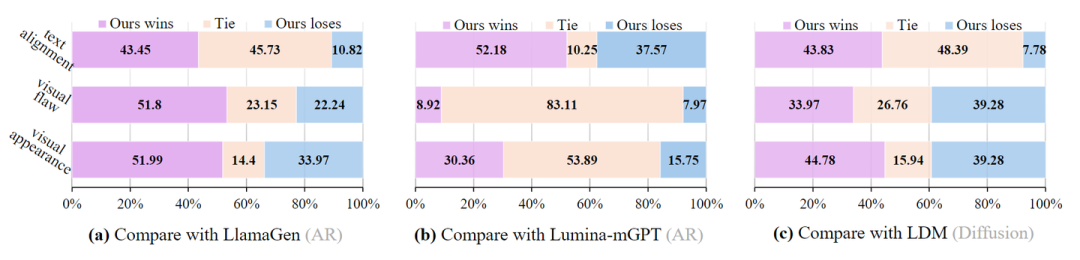
人类评估结果
自动评估指标提供了公正的评估,但可能并不总完全捕捉人类的偏好。为此,作者还对 GenAI-bench 提示集进行了大规模的人工评估,将我们的模型与 LlamaGen、Lumina-mGPT 和 LDM 进行了比较,分别作为 AR 模型、 MLLM 和 Diffusion 的代表性方法。对于人工评估,主要关注 3 个关键指标:
-
文本对齐:评估图像反映文本提示的准确性。 -
视觉缺陷:检查逻辑一致性以避免不完整身体或四肢等问题。 -
视觉外观:用于评估图像的美学质量。
结果如图 7 所示。本文模型在所有评估方面始终优于基于 AR 的模型 LlamaGen 和 Lumina-mGPT。这表明 Token-Shuffle 有效地保留了美学细节,并在足够的训练下遵守文本,即使在很大程度上降低了 token 数量以提高效率。与 LDM 相比,证明了基于 AR 的 MLLM 相对于扩散模型可以获得相当或优越的生成结果 (在视觉外观和文本对齐方面)。然而,观察到 Token-Shuffle 在视觉缺陷方面的表现略逊于 LDM,与 Fluid 的观察结果一致。
视觉效果展示
作者将 Token-Shuffle 在视觉上与其他模型进行比较,包括两个基于扩散的模型,LDM 和 Pixart-LCM,和一个自回归模型 LlamaGen。
结果如图 8 所示。虽然所有模型都表现出良好的生成结果,但 Token-Shuffle 似乎更接近于文本。一个可能的原因是 Token-Shuffle 在统一的 MLLM 风格的模型中联合训练文本和图像。与 AR 模型 LlamaGen 相比,Token-Shuffle 以相同的推理成本实现了更高的分辨率,从而提高了视觉质量和文本对齐。与基于扩散的模型相比,Token-Shuffle 作为基于 AR 的模型,展示了具有竞争力的生成性能,同时也支持高分辨率输出。

(文:极市干货)