
RAGFlow是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎,可作为Dify的外部知识库使用[1]。本文主要介绍RAGFlow前端和后端等源码安装操作过程。
一.后端安装
特别注意:python = ">=3.12,<3.13"。
1.安装Poetry
curl -sSL https://install.python-poetry.org | python3 -
2.下载源码并安装Python依赖
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/
# export POETRY_VIRTUALENVS_CREATE=true POETRY_VIRTUALENVS_IN_PROJECT=true
source /home/duomiagi/.virtualenvs/ragflow/bin/activate
poetry source add --priority=primary mirrors https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
poetry lock --no-update
poetry install --sync --no-root
/home/duomiagi/.local/bin/poetry install --sync --no-root # install RAGFlow dependent python modules
其中,POETRY_VIRTUALENVS_CREATE=true指示 Poetry 创建虚拟环境。如果设置为 true,Poetry 将为项目创建一个新的虚拟环境;POETRY_VIRTUALENVS_IN_PROJECT=true指示 Poetry 在项目目录中创建虚拟环境。如果设置为 true,虚拟环境将被创建在项目的根目录下,而不是全局的虚拟环境目录。
当需要在Ubuntu系统中执行poetry install等操作时,通过命令source /home/duomiagi/.virtualenvs/ragflow/bin/activate切换为对应的虚拟环境。
特别注意:在WSL2环境下,如果需要后端IDE调试源码,那么最好不要指示 Poetry 在项目目录中创建虚拟环境,因为这样在IDE中(比如,PyCharm)可能无法选择解释器路径。最好方式是使用IDE创建的虚拟环境路径。如下所示:
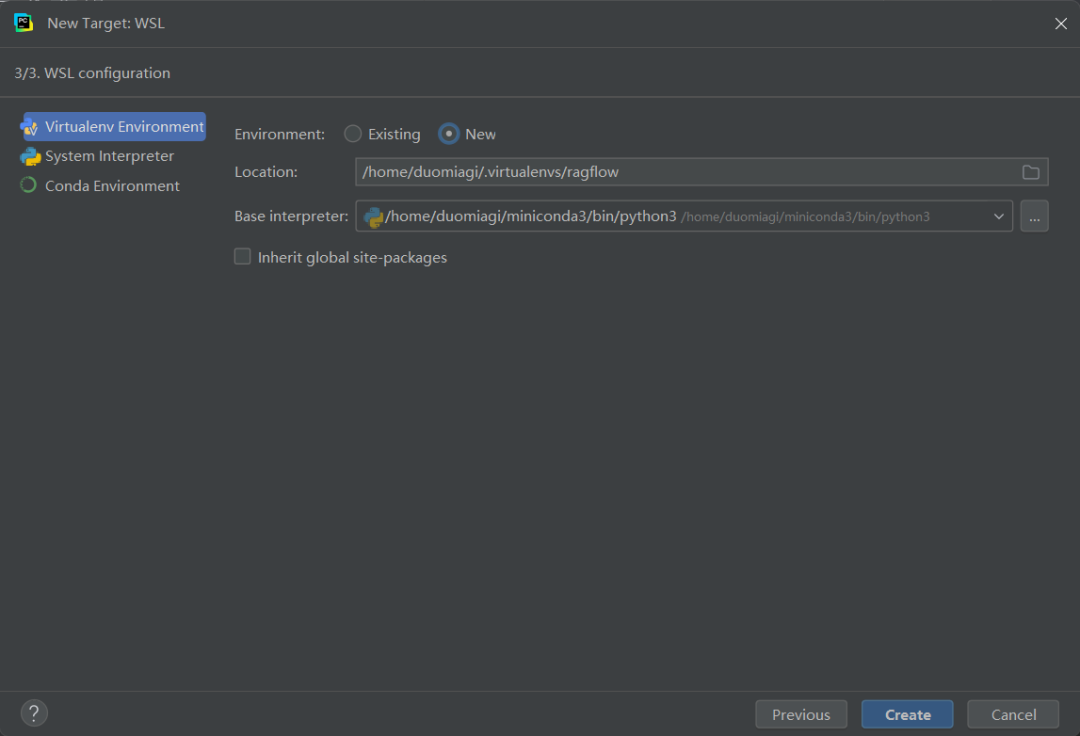
poetry install --sync --no-root 命令用于安装项目的依赖项。每个选项详细解释,如下所示:
-
--sync:同步项目的依赖项。这意味着它将确保项目的依赖项与pyproject.toml文件中定义的依赖项完全匹配。如果有任何不匹配的依赖项,它们将被移除或更新。 -
--no-root:不安装项目本身。这意味着它只会安装项目的依赖项,而不会将项目本身作为一个包安装。
这个命令将确保项目依赖项与 pyproject.toml 文件中的定义完全一致,并且不会将项目本身安装为一个包。
3.通过Docker Compose启动依赖服务
docker compose -f docker/docker-compose-base.yml -p "ragflow" up -d
特别注意:在文件docker/service_conf.yaml中,对照docker/.env的配置将mysql端口更新为5455,es 端口更新为 1200等。简单理解,就是根据需要同步修改,尤其是本地运行后端服务,需要把容器名字替换为IP地址,比如127.0.0.1。
4.设置环境变量HF_ENDPOINT
export HF_ENDPOINT=https://hf-mirror.com
5.启动后端服务
source /home/duomiagi/.virtualenvs/ragflow/bin/activate
export PYTHONPATH=$(pwd)
bash docker/launch_backend_service.sh
6.IDE中调试后端服务
(1)启动后端服务脚本
后端服务启动命令为docker/launch_backend_service.sh,如下所示:
#!/bin/bash
# unset http proxy which maybe set by docker daemon
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
export LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu/
PY=python3
if [[ -z "$WS" || $WS -lt 1 ]]; then
WS=1
fi
function task_exe(){
while [ 1 -eq 1 ];do
$PY rag/svr/task_executor.py $1;
done
}
for ((i=0;i<WS;i++))
do
task_exe $i &
done
while [ 1 -eq 1 ];do
$PY api/ragflow_server.py
done
wait;
这个脚本用于并行执行多个task_executor.py任务,数量由WS变量决定。同时,它保持一个服务器脚本ragflow_server.py不断运行,用于处理RAG(Retrieval-Augmented Generation)相关的API请求。整个脚本通过无限循环确保这些任务和服务器始终运行,直到手动终止。详细解释如下所示:
-
取消HTTP代理设置:脚本首先通过
export命令清空了可能由Docker守护进程设置的HTTP代理环境变量。这样做的目的是确保HTTP代理不会影响后续任务的执行。 -
设置库路径:脚本将
LD_LIBRARY_PATH设置为/usr/lib/x86_64-linux-gnu/,这通常用于指定运行某些动态链接库的位置。 -
设置Python解释器:通过变量
PY指定使用python3来运行Python脚本。 -
设置并行任务数量:脚本检查环境变量
WS,如果WS未设置或小于1,则将其默认设置为1。WS变量表示任务的并行执行数量。 -
定义
task_exe函数 -
该函数会进入一个无限循环 (
while [ 1 -eq 1 ]) 并不断执行指定的Python脚本rag/svr/task_executor.py,传递一个参数给该脚本(这个参数是任务编号)。 -
当函数被调用时,它会不断执行任务,直到手动停止。
-
启动任务执行器
-
通过
for循环,启动WS个并行的任务执行器,每个执行器都会调用task_exe函数,并传入一个递增的数字作为任务编号($i)。 -
每个任务执行器通过后台运行(
&),因此这些任务会并行执行。 -
运行主程序
-
在主程序中,同样使用了无限循环 ( while [ 1 -eq 1 ]) 来不断执行api/ragflow_server.py脚本,保证服务器持续运行。 -
等待所有进程结束
-
wait命令会阻塞脚本的退出,直到所有后台进程(并行任务执行器和服务器)都终止。
小结:这段Bash脚本功能本质上是执行了ragflow_server.py和task_executor.py,前者是启动HTTP服务器,后者是启动任务执行器。
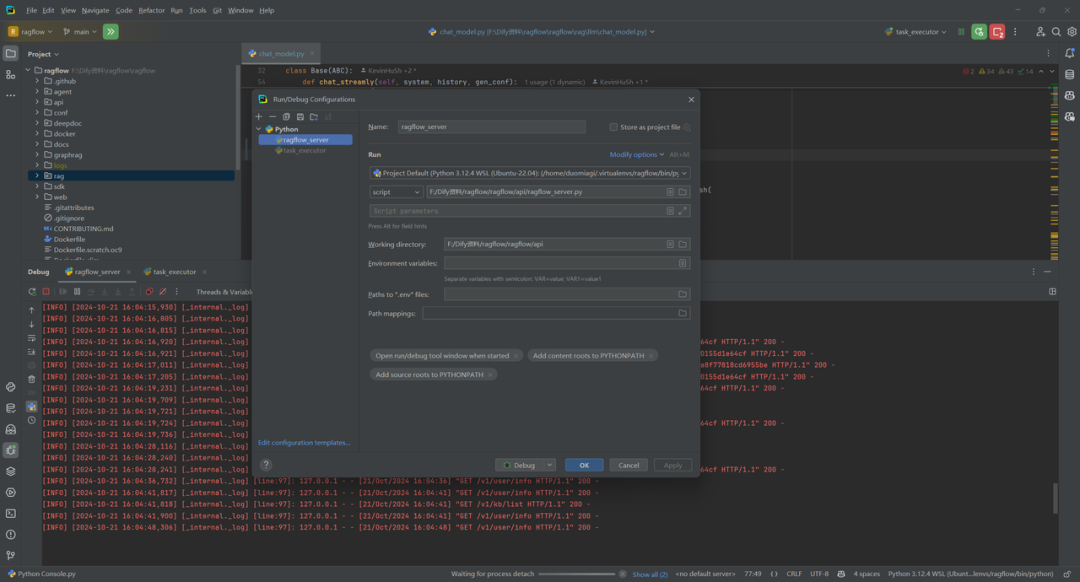
(2)ragflow_server
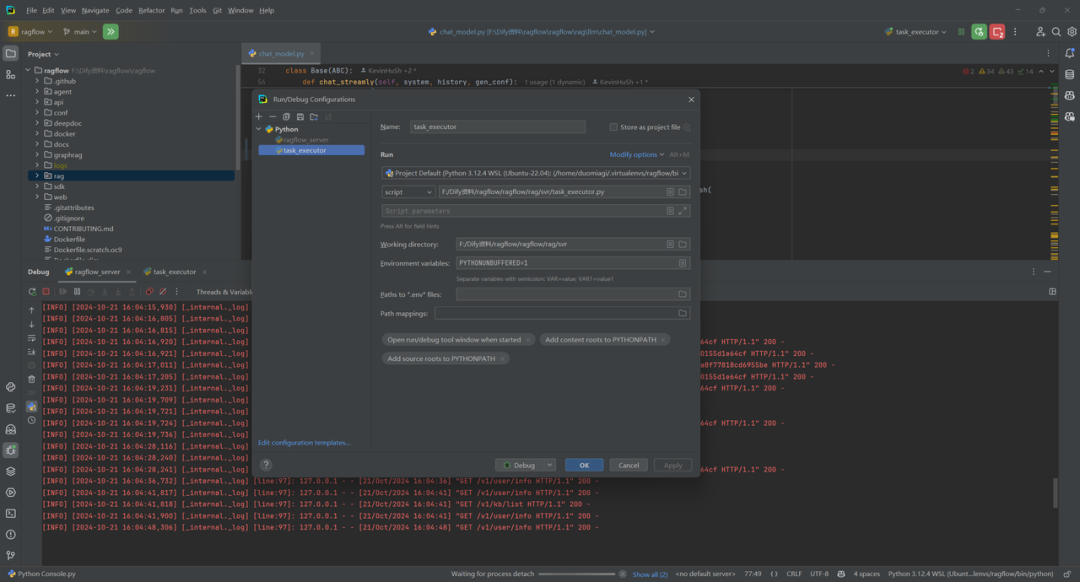
(3)task_executor
二.前端安装
1.可能Node.js版本问题
如果遇到问题,如下所示:
error - Your node version 19 is not supported, please upgrade to 14 or above except 15 or 17.
表明Node.js 版本 19 不受支持,请升级到受支持的版本(14、16、18 或最新的 LTS 版本)。
2.Windows上解决步骤
(1)下载并安装nvm
访问 nvm-windows 的 GitHub 页面,下载最新的 nvm-setup.zip 文件并解压,运行 nvm-setup.exe 进行安装。
(2)安装Node.js 18版本
(3)使用Node.js 18版本
(4)验证Node.js版本
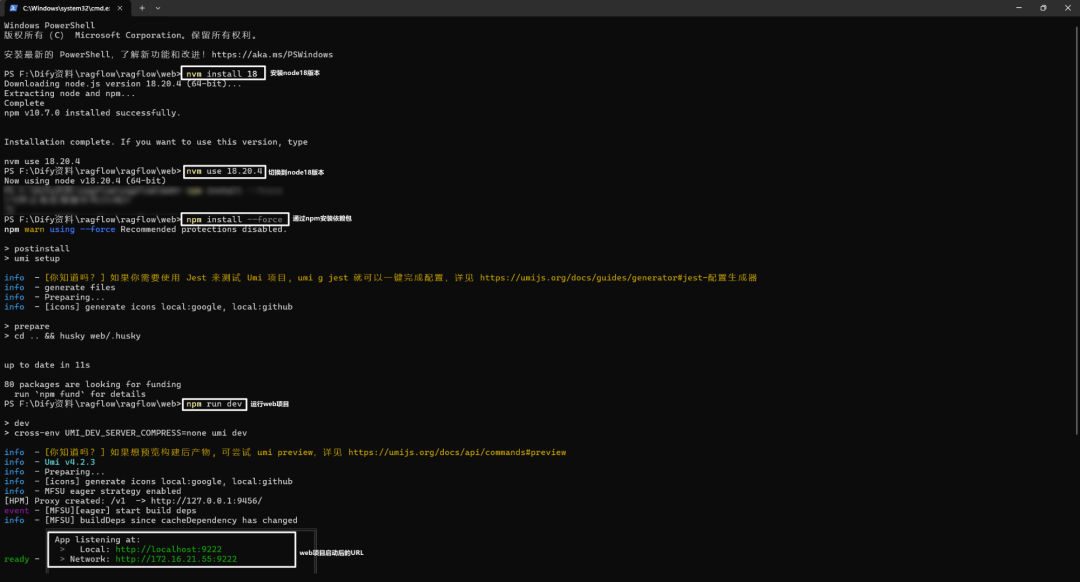
3.运行Web项目
(1)cd ragflow/web && npm install --force
(2)将.umirc.ts的proxy.target更新为http://127.0.0.1:9380
(3)npm run dev
RAGFlow登录链接为http://localhost:9222/login,如下所示:
三.可能遇到问题
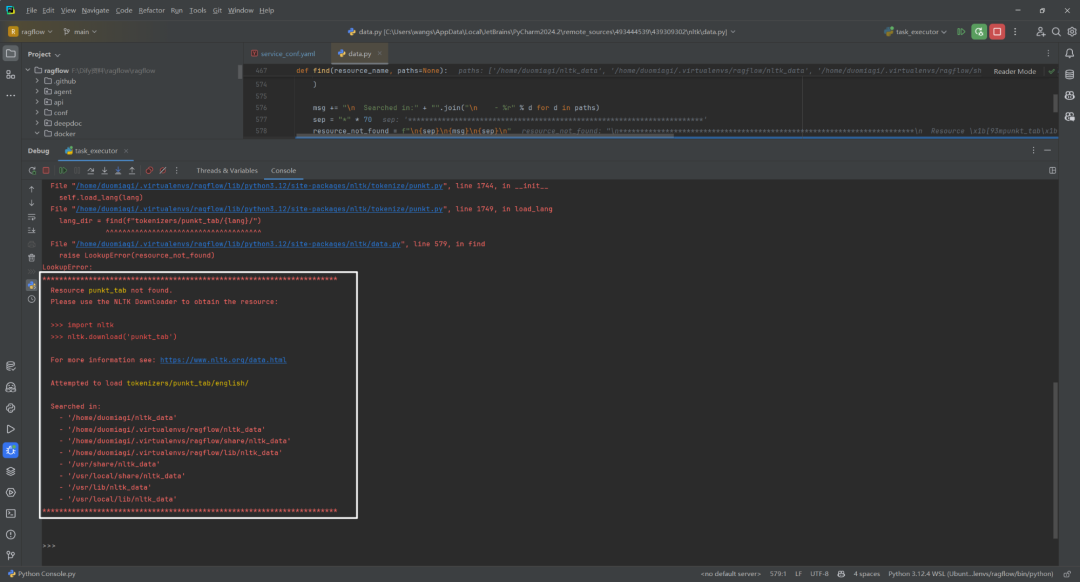
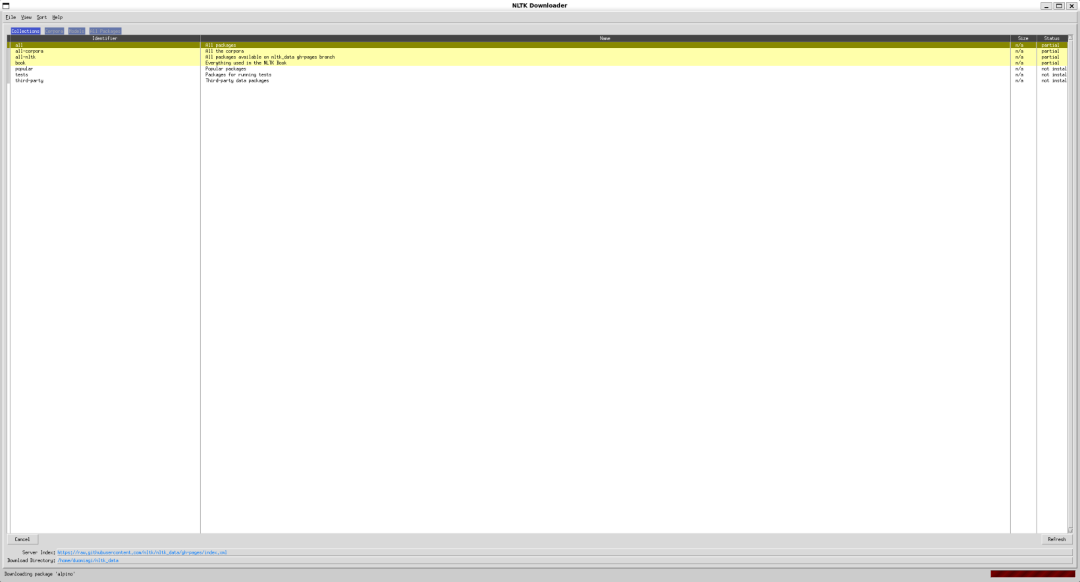
1.找不到nltk_data相关数据
启动后端服务时,可能会报错,原因是nltk_data相关数据没有找到,解决方案是下载相关数据。如下所示:
下载nltk_data包括’wordnet’、’punkt’和’punkt_tab’,如下所示:
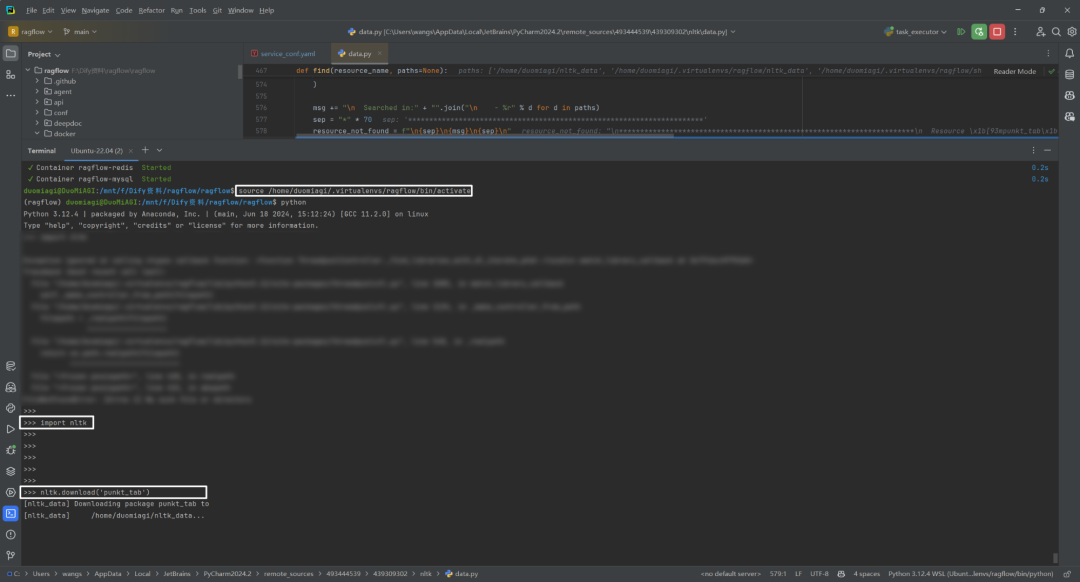
也可直接全部下载nltk.download(),如下所示:
2.’CompletionUsage’ object has no attribute ‘get’
解决方案参考文献[11]。
3.安装crawl4ai库
解决方案参考文献[12]。
4.onnx文件找不到
解决方案参考文献[13],放到ragflow\ragflow\rag\res目录下。
参考文献
[1] 外部知识库 API:https://docs.dify.ai/zh-hans/guides/knowledge-base/external-knowledge-api-documentation
[2] https://github.com/infiniflow/ragflow/blob/main/README_zh.md
[3] Latest Miniconda installer links by Python version:https://docs.anaconda.com/miniconda/miniconda-other-installer-links/
[4] https://github.com/coreybutler/nvm-windows/releases
[5] RAGFlow快速开始:https://ragflow.io/docs/dev/
[6] RAGFlow用户指南:https://ragflow.io/docs/dev/category/guides
[7] RAGFlow参考手册:https://ragflow.io/docs/dev/category/references
[8] RAGFlow API参考:https://ragflow.io/docs/dev/references/ragflow_api
[9] GitHub Discussions:https://github.com/orgs/infiniflow/discussions
[10] RAGFlow Roadmap 2024:https://github.com/infiniflow/ragflow/issues/162
[11] https://github.com/infiniflow/ragflow/pull/1736/commits/7c38c8df5b5fe1c7dd303a0bc8f6db44238bf4ad
[12] https://github.com/unclecode/crawl4ai
[13] https://huggingface.co/InfiniFlow/deepdoc/tree/main
[14] RAGFlow源码安装操作过程(原文链接):https://z0yrmerhgi8.feishu.cn/wiki/LOwWwGwtgiy3lEkRroGcFoBFnCh
(文:NLP工程化)