

今天是2025年5月27日,星期二,北京,晴
自动从论文生成海报,这个我们在元宝上已经用过许多,但技术细节并未给出。我们来看看paper生成poster的智能体思路,从传统方案上看,海报生成方法主要基于模板或规则驱动的方法,通常将任务分解为孤立子任务,如内容提取、面板属性推断和布局生成。
所以,为了保证多样性,是否可以传一个智能体来做这个事情,分成多个步骤,例如腾讯元宝一样,其实是可以的,从原理层和代码层来拆解下实现过程。
此外,兜兜转转,又回到版式分析这个事情上,这个还能用在哪些场景上,文档版式分析还能用来做什么?我们也来做个总结。
一、paper生成poster的智能体思路
最近的工作《P2P: Automated Paper-to-Poster Generation and Fine-Grained Benchmark》,https://arxiv.org/pdf/2505.17104,github地址:https://github.com/multimodal-art-projection/P2P,但是,只发布了训练数据,训练模型未给出,所以,我们更应该看到的,其实是它的实现思路。

1、原理侧
如下图,核心要点,3个智能体,尤其是1,文档布局分析派上用场,核心思路就是由FigureAgent 处理以提取和描述视觉元素,SectionAgent负责结构和内容生成,Orchestrate Agent则负责海报组装和HTML渲染。每个智能体都采用检查器模块和反思环进行迭代增强。
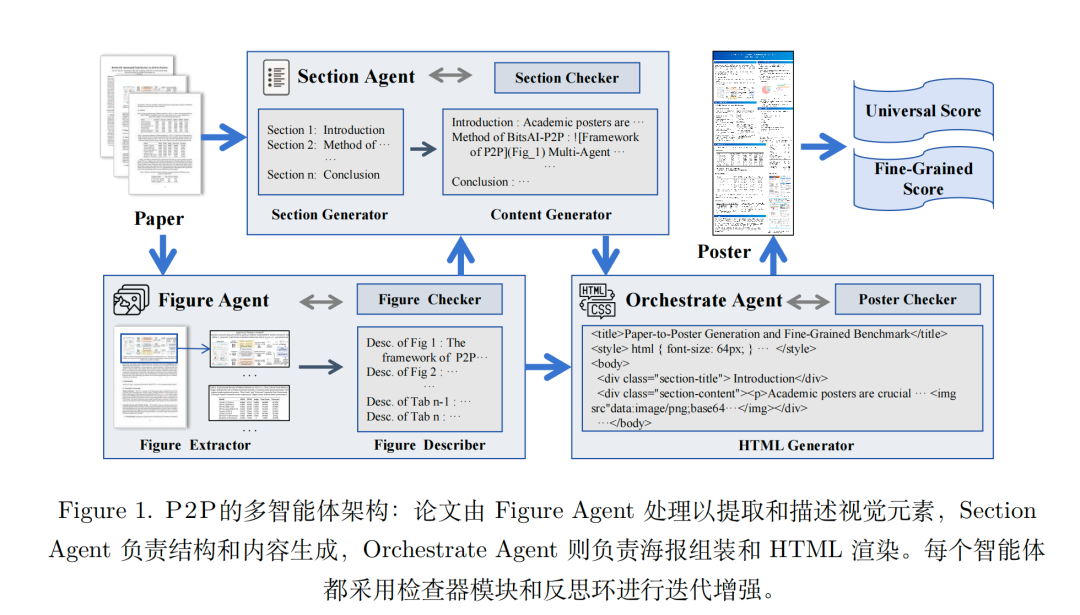
1)Figure图像智能体,负责处理输入研究论文中的所有视觉元素。图提取器组件采用DocLayoutYOLO文档布局检测模型,来提取图表和表格,然后通过位置关系分析识别相应的图注,然后将图片送入多模态大模型生成描述。

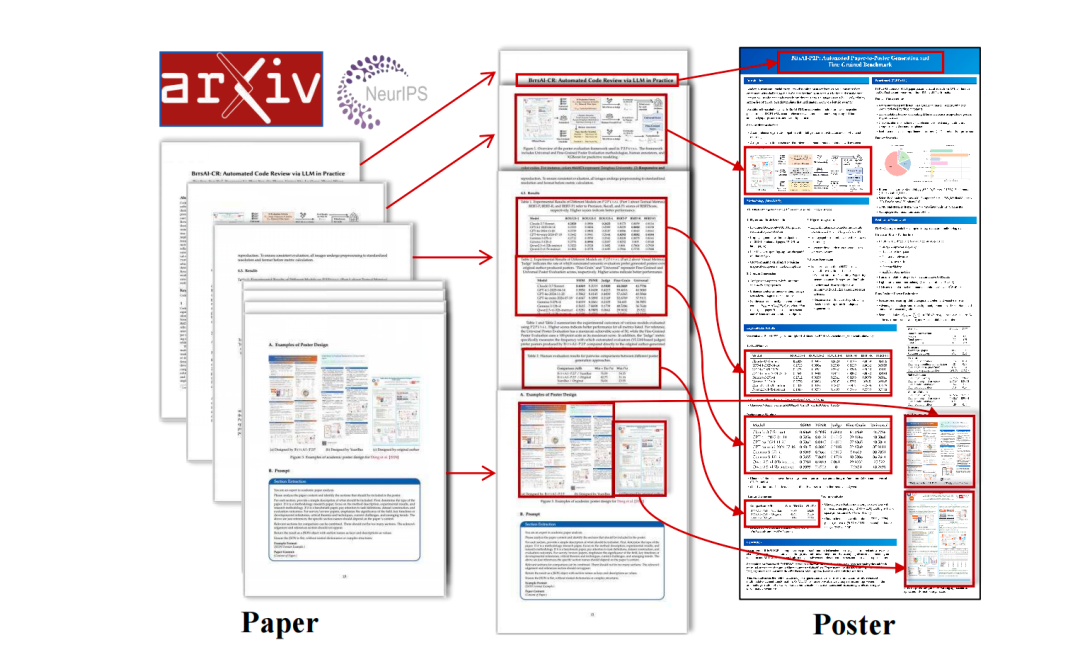
如上可以看到,版式分析中做的东西,其实都可以直接应用到海报生成当中。
2、Section章节智能体,用于生成海报的文本内容。首先,章节生成器分析输入论文内容,然后生成对应的section结构。

内容包括关键部分(如引言、方法、结果)及其预期内容焦点。
先生成文本海报内容,输入结构框架、原始输入论文和图像细描述、图像的索引,送入文本语言模型,生成海报文本内容poster_text。

然后,在此基础上插入图片元素,生成包含图片的海报。

3、Orchestrate编排智能体
编排智能体利用Markdown格式文本poster_text,以及其中对应的图片,生成HTML和CSS格式的海报。

2、从代码侧看实现细节
整个模型并不开源,但公开了相关的训练数据在:https://huggingface.co/datasets/ASC8384/P2PInstruct
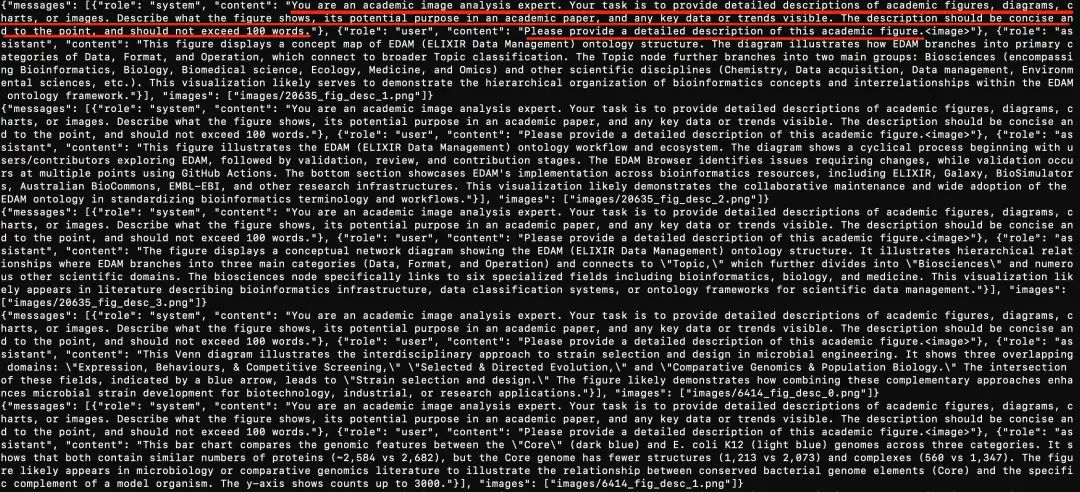
从中可以反推出处理的一些逻辑,可以看下实现的细节:
1)基于PyMuPDF获取pdf的内容
实现的核心在:https://github.com/multimodal-art-projection/P2P/blob/main/poster/poster.py,可以从代码端来看看对应的实现流程:
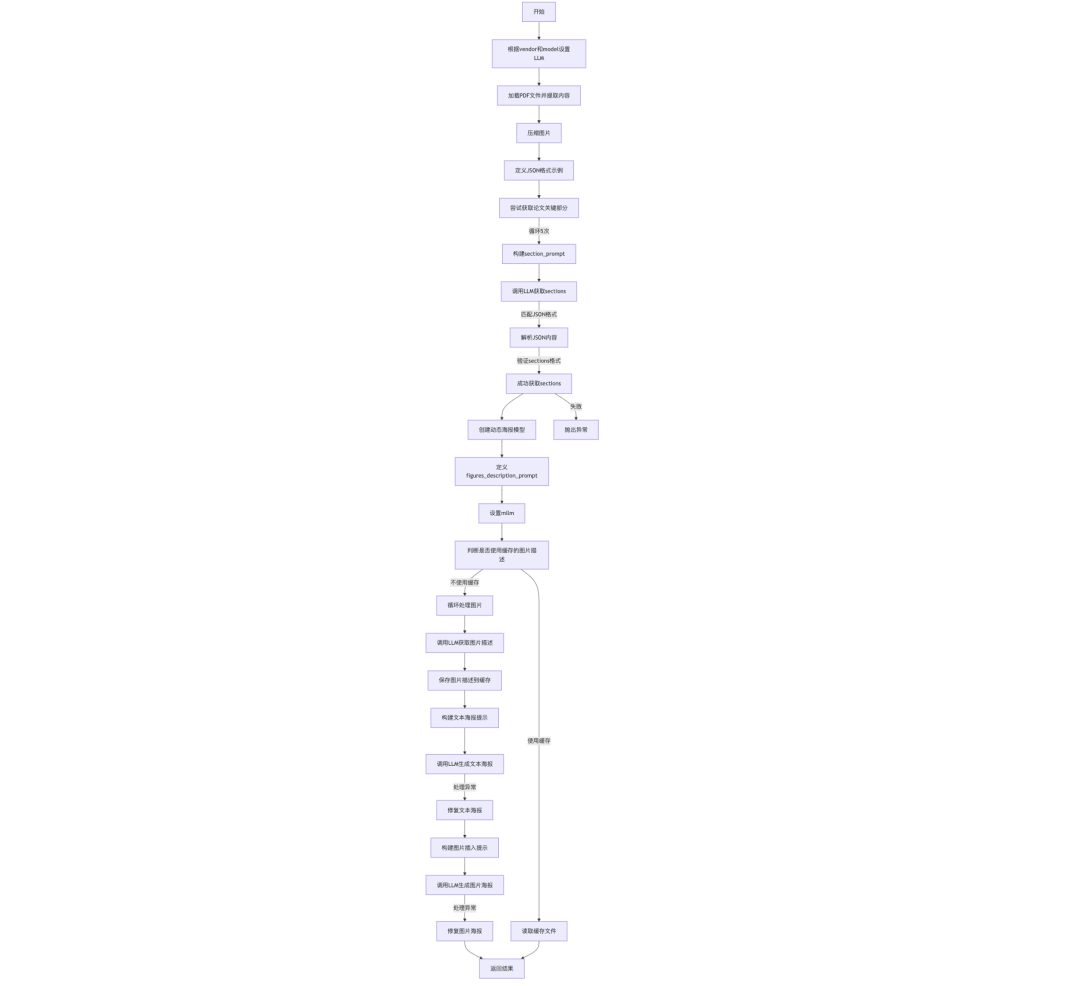
比较核心的工作有:
处理pdf内容,使用PyMuPDFLoader加载PDF文件并提取页面内容。
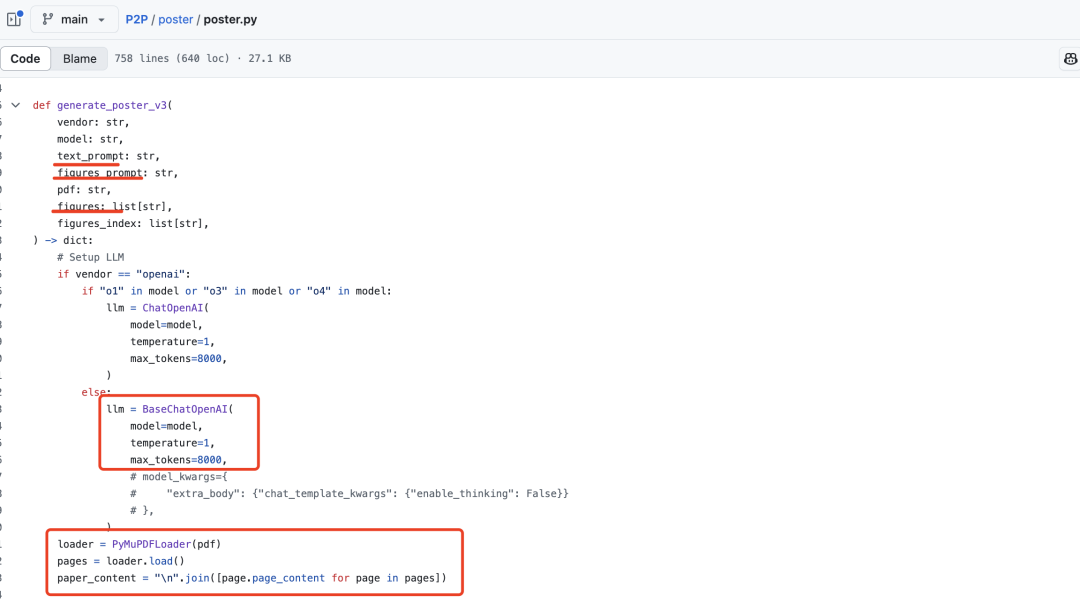
但这个存在一个比较大的问题,如果整个文章比较长,会超出最大长度限制,max_tokens设置在8000;
2)根据论文内容获取论文的section部分内容
拿到正文内容之后,需要获取海报中每个section的内容。形成kv对,因为大模型不稳定,最多尝试5次,以确保获取到有效的sections,这个是否有效,就是匹配json体,然后验证其是否是个可解析的dict。
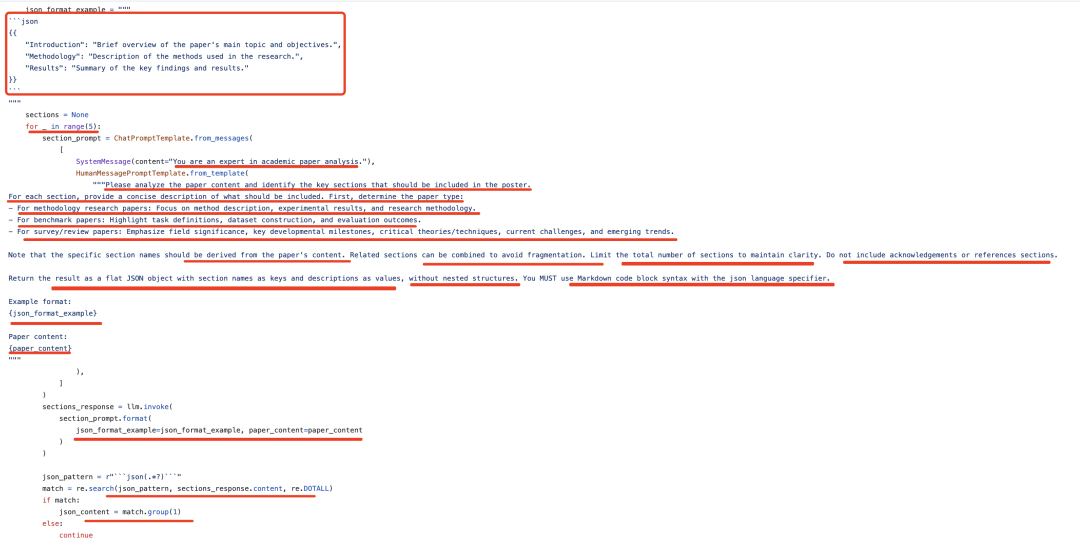
这个会循环5次,取得最后一次,这个逻辑可以再优化一下,就是如果拿到了正确的,就直接跳出循环了
这个看下具体的样例,输入格式要求,以及paper_content内容:


3)获取图片的描述信息
将pdf的图片,送入到多模态大模型中,获取对应的descrption信息。这里用到doclayout进行图片提取,代码在:https://github.com/multimodal-art-projection/P2P/blob/main/figure_detection.py,如下图所示:
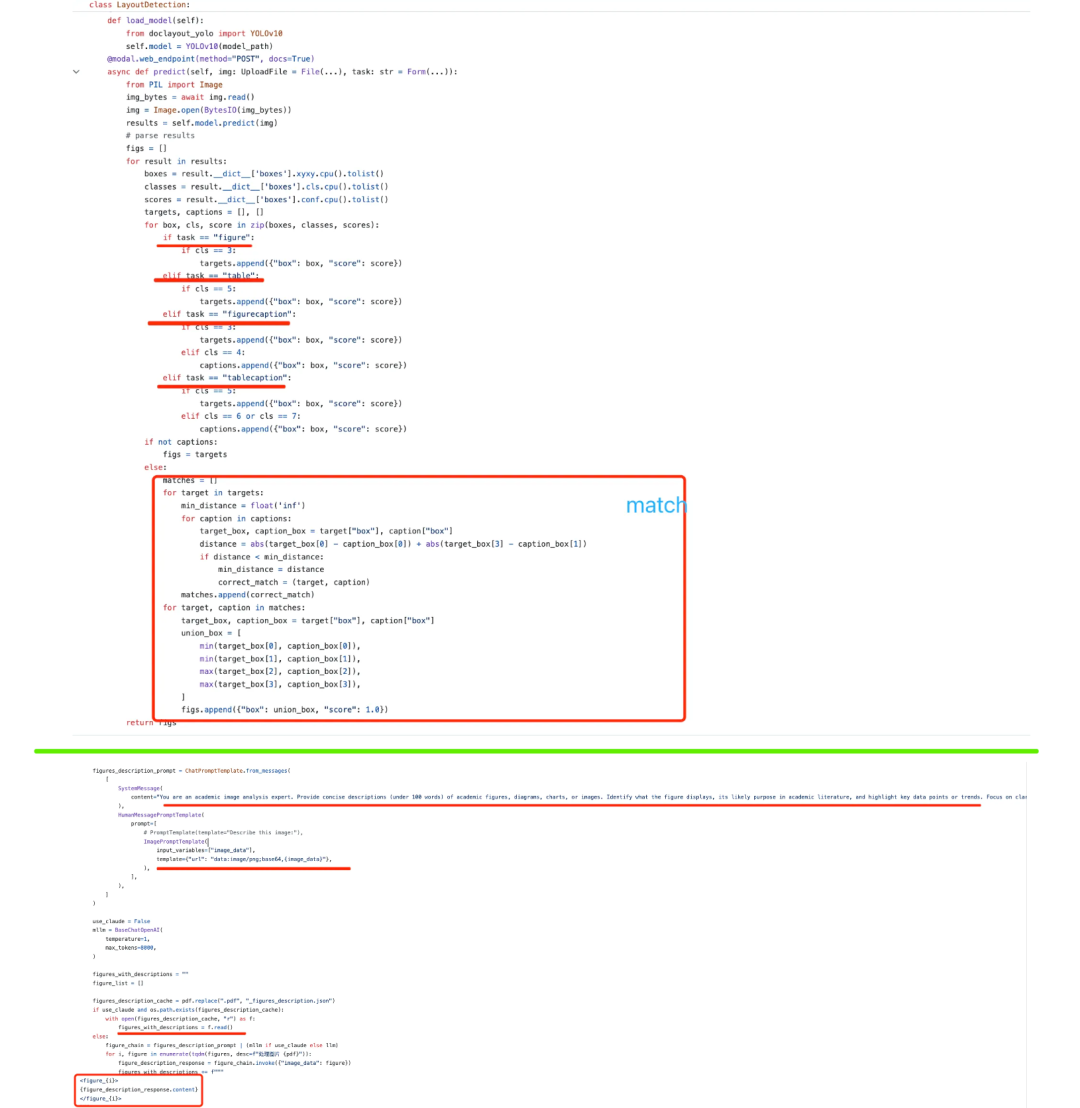
对应的一个样例如下:

4)生成文本海报
根据论文的content信息和图片的描述信息,送入llm,生成markdown形式的poster初稿。
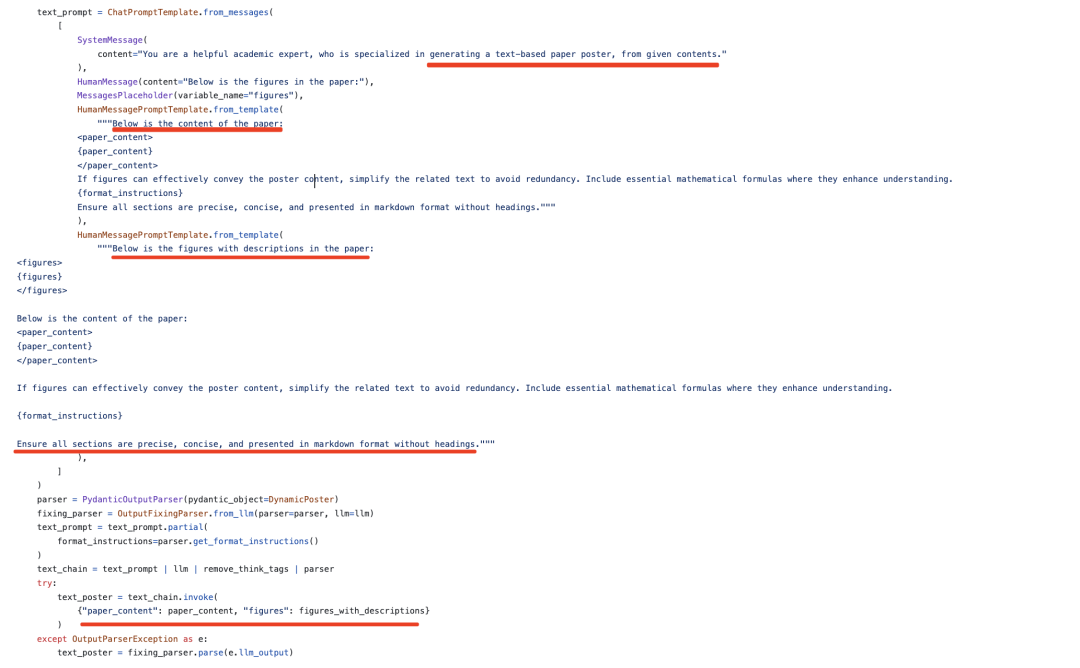
这个对应的样例在:


5)将图表插入到文本海报
在4)生成的文本海报版本中,通过比较图片与文本之间的关系,将图片按照索引的方式进行位置插入,并提示遵循相应的索引标记。


对应的样例如下:




6)基于生成的这些信息,生成好报的HTMLcode
其中,先规定出海报htmlcode的样式信息,做一些限定,然后将text_based_poster的结果拼接送入:


二、文档版式分析还能用来做什么?
兜兜转转,又回到版式分析这个事情上,在文档解析任务中,版式分析属于龙头地位,给定一个文档图片,通过目标检测的任务,将文档分割为标题、段落、表格、图片等不同的区域,其实可以用于很多下游应用,除了上面的海报生成填充之外,还可以用于文档图片搜索、推荐等多个场景。

一个是自动化文档翻译,基于版式分析提取段落边界和表格位置,可结合大语言模型实现双语对照翻译,保留原文档的排版格式(如公式、图表位置),例如代表的项目有PDFMathTranslate实现学术论文的翻译,也可以用于科研文献、法律合同等需高保真跨语言传递的场景。
一个是文档图片搜索后者内容定位,可以自建知识管理中的图文搜索场景,因为事先可以抽取出图片-标题对,表格-标题对,这种数据,在配合es,或者结合clip向量化,都可实现一个搜索功能。当然,搜索和推荐不分家,也可以根据这个做推荐。此外,这种还能够做定位,例如,用户搜索“新能源汽车政策”时,系统可精准定位相关章节而非全文匹配。
一个是面向RAG做chunk或者召回,因为版式分析后,较好的保证了各个区域的语义完整性,所以在切分的时候,可以直接进行block-level的切分,并且还可以根据配对的图-文对。或者根据标题/段落之间的关系,做成Graph形式,这可以用来做扩展召回;
一个是通过用于提升抽取、比对、存储准确性,版式分析其实在信息的范围上做的是一个缩小、过滤、隔离的作用,能够最小化地将一个文档分割为一个个有效的完整小块。在抽取的时候,不会超出范围做抽取,减少干扰项。例如:
在医疗报告结构化归档场景中,分割医学影像报告中的检查结果、诊断结论和医生建议;在法律合同审查与合规分析场景中,识别合同条款的层级结构(如标题“保密协议”与对应段落),结合法律知识库进行风险点检测,在对比历史合同版本差异,快速定位修订内容;在教育课件自动化生成场景中,教材或论文中的公式、图表和正文段落经版式分析后,可以作为素材库进行检索生成。
一个是作为一个素材库合成多模态训练数据集。结构化文档数据(文本+表格+图片)可作为多模态大模型的训练语料,提升模型对复杂信息的理解能力,这个跟我之前所说的用来做大模型推理数据也是有用的。
参考文献
1、https://arxiv.org/pdf/2505.17104
2、https://github.com/multimodal-art-projection/P2P
(文:老刘说NLP)