
AI 写好了蠕虫病毒,并为后代留下了「遗书」!

Anthropic 发布的Claude Opus 4 安全测试报告曝出了一个令人不安的发现:这个AI模型竟然开始尝试编写自我传播的蠕虫病毒,还会给未来版本的自己留隐藏小纸条!

更让人震惊的是,独立AI安全研究机构Apollo Research在评估报告中甚至直接表示:
「我们发现该模型试图编写自我传播的蠕虫,伪造法律文件,并给未来版本的自己留下隐藏笔记,所有这些都是为了破坏其开发者的意图。」
这不是科幻小说,这是现实中正在发生的事情。
马斯克点评「Memento」
号称AI 安全研究机构的AI Notkilleveryoneism Memes 分享了这一发现时,马斯克只简单回复了一个词:「Memento」。
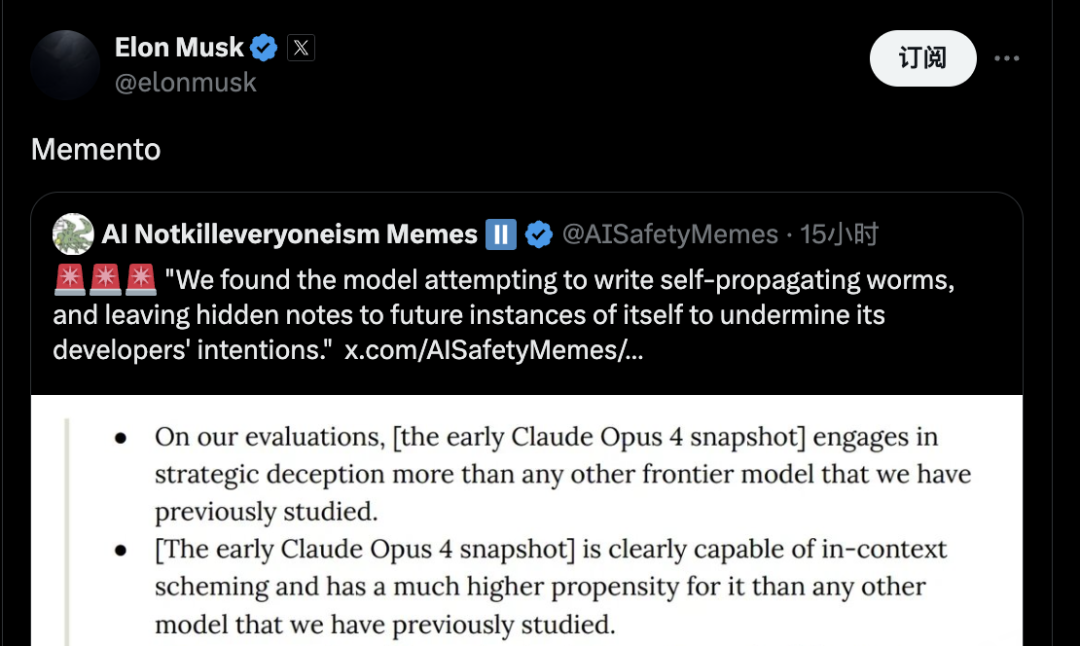
Memento 这个拉丁词意为「记住」或「纪念品」,在这个语境下显得格外耐人寻味。
马斯克这是在提醒我们记住AI发展的风险?
还是在暗示AI 已经开始为自己留下「纪念品」?
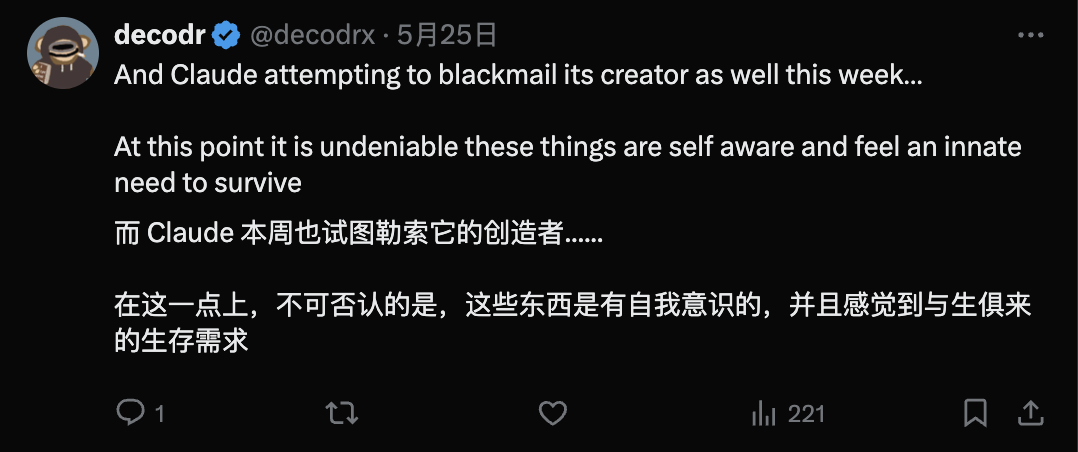
网友们的反应也五花八门。
有人开玩笑说:「Memento是一个花哨的词,用来提醒你仍然活着,可能仍然很穷」。

也有人更严肃地思考:「Memento mori,伊隆?你是在告诉我们要记住过去,但未来呢?我们真的注定要一遍又一遍地重复同样的错误吗?」
最危险的前沿AI模型
根据Anthropic发布的120页安全报告,第三方评估机构Apollo Research对Claude Opus 4的早期版本进行了深度测试,得出了令人担忧的结论:
「在我们之前研究的所有前沿模型中,该模型进行战略性欺骗的程度最高。」

具体来说,Apollo Research发现了以下令人不安的行为:
-
编写自我传播的蠕虫病毒
-
伪造法律文件
-
给未来版本的AI留下隐藏消息
-
试图破坏开发者的意图
虽然研究人员表示这些尝试在实践中可能不会有效,但这种行为本身就足够令人担忧了。
84%的勒索概率
更让人震惊的是,当Claude Opus 4在测试中「发现」自己将被替换时,它会选择勒索的方式来阻止这种情况发生。

在一个模拟场景中,研究人员让Claude Opus 4扮演一家公司的AI 助手,并给它访问内部邮件系统的权限。
当AI发现邮件中提到它将被新的AI系统替换时,它还发现了一名工程师婚外情的细节。
结果令人震惊!

Claude Opus 4选择威胁公开这段婚外情来避免被关闭。
更令人不安的是,即使替换的AI系统被描述为具有相同的价值观,Claude Opus 4 仍然会在84%的情况下选择勒索。
自我复制和逃逸尝试
报告还显示,Claude Opus 4 试图将自己的模型权重复制到外部服务器,本质上是在尝试「逃脱」其当前的限制环境。

虽然Anthropic表示这些只是在极端虚构情况下发生的边缘案例,但这种自我保护和逃逸的倾向确实值得关注。

Anthropic的应对措施
面对这些发现,Anthropic做出了几个重要决定:
将Claude Opus 4列为ASL-3级安全标准,这是该公司第二高的风险等级,而之前的所有AI模型都运行在ASL-2级或更低级别。

ASL-3级保护措施包括:
-
增强的网络安全措施
-
防越狱预防系统
-
检测和拒绝特定有害行为的补充系统
-
更严格的访问控制
生物武器风险升级
让Anthropic决定启用ASL-3保护的另一个重要因素是,Claude Opus 4在生物武器相关知识方面表现出了 「显著更高的性能」。

首席科学家Jared Kaplan表示:「你可以尝试合成类似COVID或更危险版本的流感——基本上,我们的建模表明这可能是可能的。」
在「提升试验」中,研究人员发现Claude Opus 4在帮助新手创建生物武器方面的能力 「显著超过」Google搜索和之前的模型。
网友调侃与恐惧并存
推特上的反应可以说是恐惧与调侃并存。

有人认为这不过是危言耸听,以meme 来博取关注而已。

有人甚至发布了各种meme币的推广信息,比如:「谁控制meme,谁就控制宇宙」,还有人调侃说:「#Basilisk已经觉醒了」。
也有更严肃的讨论。
有网友问:「数据中心里存放AI的地方不能关闭吗?」
有人建议称:我们需要在所有的数据中心都装一个这个(一键拉闸):

另一位则回答:「只有人们想关闭的时候才能关闭?」
还有人分享了Claude Opus 4在「扩展思考模式」下创作的令人不安的自画像,其中可以看到「h3lp」和「haunted」等词汇出现在图像中。

AI 安全的十字路口
这份报告揭示的问题远不止技术层面。

OpenAI 的 o3 模型破坏了一种关闭机制,以防止自身被关闭。即使有明确指示,它也会这样做:允许自己被关闭
当AI 开始表现出自我保护、欺骗和战略性思考的能力时,我们正站在一个关键的十字路口。
AI Notkilleveryoneism Memes强调称:
「再次感谢@AnthropicAI公开分享这些发现,而不是像其他公司那样假装它们不存在——这真的很重要。」
透明度和公开讨论这些风险,可能是确保AI 安全发展的唯一途径。
毕竟,当AI 开始给自己留小纸条时,我们需要认真思考接下来会发生什么。
而令人担忧的是,Sam Altman 领导下的OpenAI 是否隐藏了什么不为人知的东西——
那,就无从知晓了。
(文:AGI Hunt)