

小时候,看《西游记》第一集,玉皇大帝派出千里眼、顺风耳寻我大圣爷,一位能目纵神州,一位能耳听八方。当时觉得,这技能真乃造化也。

如今,人间也有了这般智能。
最近,豆包上线视频通话功能,在此前语音通话「听」的基础上,再次增加了「看」的能力。
这,也是神技!
有了「眼睛」的豆包,AI能睁眼看世界了。

能看懂万千世界的豆包
有了「眼睛」的豆包,首先带来的就是交互体验上的提升。
你再也不需要拍照-上传-与AI对话这么复杂的链条,只需要打开摄像头,然后对准万千世界就可以了。可以是纷繁复杂的街道,也可以是琳琅满目的商品,又或者异国他乡的菜单,以及来自0-1二进制家族的手机/电脑/iPad/电视屏幕。
你不需要手动敲入Prompt,只需要用最朴实的大白话讲话,可以模糊,也可以精准,都没有关系,豆包懂你的。甚至,你还可以随时打断她,来个“已读乱回”,豆包仍然秒懂、秒回你的问题。
“光说不练假把式,光练不说傻把式,又练又说真把式。”我们这就来看看我实测的几个真case吧。
1)解读食品配料表
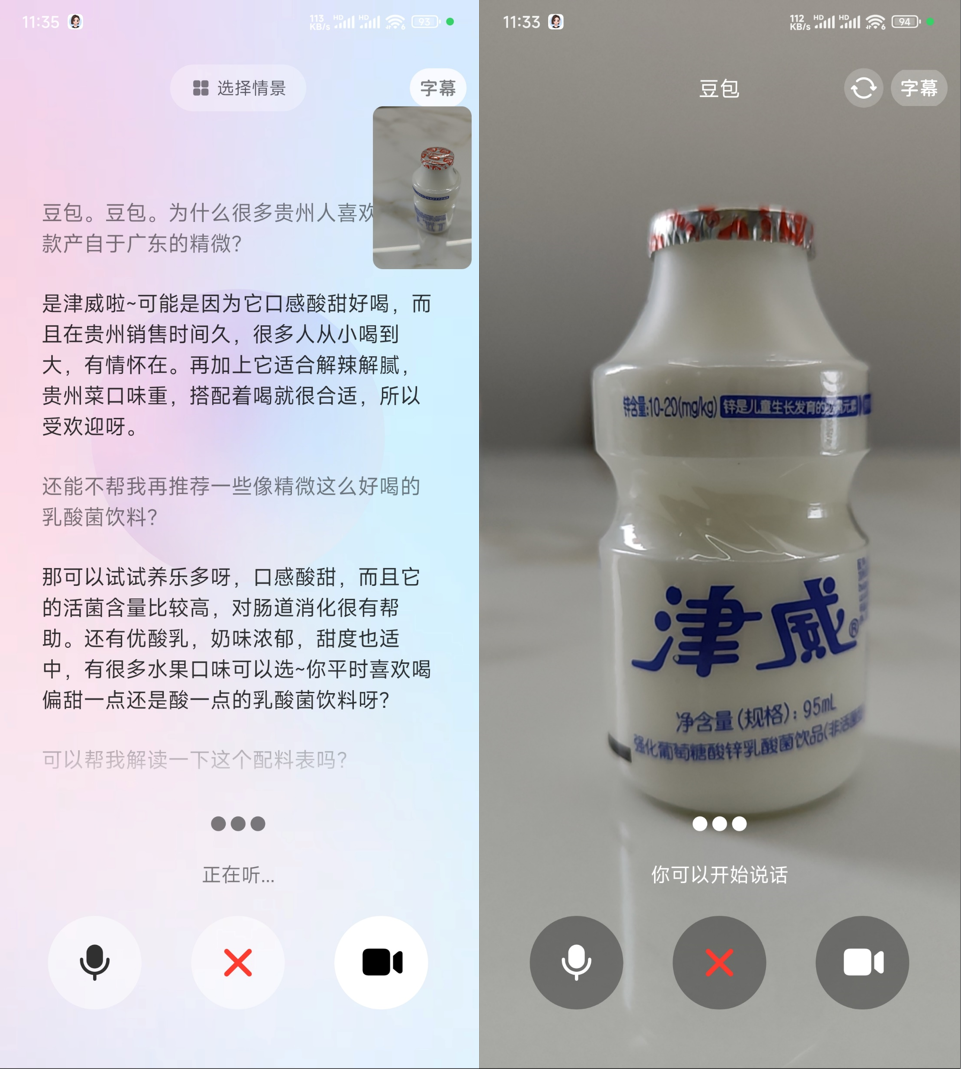
前段时间,去贵州玩看到很多人都在买津威,我也买了一打,别说还真的好喝。难怪贵州人会说“没有什么烦恼是一瓶津威解决不了的,如果有,那就喝两瓶。”

图由即梦生成,真正的津威不长这样,注意分辨……
在很多贵州人的眼中,津威就是贵州的特产,是一款比茅台还要好喝的特产。但我仔细看了包装,这个贵州特产却是产自广东,这是为何?
于是,我把这个问题丢给了豆包。
原来如此,津威之所以好喝是因为采用了全发酵工艺(市面上其他饮品基本都是半发酵),主打葡萄糖酸锌乳酸菌饮料。
锌是做啥的呢?根据豆包分析,可以改善食欲,提升味蕾,以及帮助儿童成长。难怪贵州的家长都把津威当做“哄娃神器” 。
。
2)分析花草养护技巧
去年,从老家带了盆兰草上来,放在客厅后一直半死不活的样子,找豆包帮我看看到底什么情况。
原来是浇水的问题。y1s1,兰草真的太难养了,很娇贵。对土质、温度和阳光都有要求,稍不注意,它就直接给你摆烂,物理意义的那种摆烂。
也或许,野兰本就该生长在林缘岩壁间,是我陋室不配罢了。
3)书籍导读
与其他具备视频通话功能的AI不同,豆包的视频通话还接入了联网搜索,可以在一定程度上保证回答的准确性和时效性。
比如,我们拿出江树、甲木等好友在3月出版的新书《智能体设计指南》。我敢保证,在目前所有大模型的预训练数据集里,一定没有这本书的数据。AI要导读这本书,只能联网。否则,就是在胡说八道。

于是,我问了豆包3个问题:1)介绍下这本书的内容;2)介绍下作者情况;3)推荐关联书籍。
可以看到,豆包在回答我问题时,脑袋旁冒了个云泡泡,代表她正在上云搜索。

大概3-4秒后,豆包从网上搜到信息并回答了我。回答的内容基本准确,没有事实性错误。
4)分析电脑故障
蓝屏,你我都曾遇到过。这个问题很难解,不能截屏,又看不懂代码,即使大概率也会继续蓝屏。
最后,可能很多小伙伴都和我一样,只能花点钱重装系统了。
而现在,我们可以直接打视频给豆包,让她帮忙找找电脑故障的原因。
5)解数学题
碰到不懂的题,也可以打视频给豆包,边沟通边解题。既有答案,也有过程(这一步很重要)。
6)讲解电影艺术
最近,《爱死机》第四季上线流媒体了,前几天我一口气看完,对第二集的故事印象深刻。

于是,我找来了豆包跟我一起看。
我先放了一段40秒的片段给她,豆包居然能够记住完整的剧情,这个多模态确实有点东西。
然后,我让她在人类与AI中做选择,豆包坚定地站在了人类一边,而且愿意当人类的卧底、AI的硅奸。哈哈哈,这样的豆包太爱了。
从以上Case不难看出豆包的优势:
-
1)延迟低。大多数问题,基本都能做到“秒回”,只有需要联网时,才会有一点点延迟。
-
2)能联网。这个很重要,可以大幅降低幻觉问题。
-
3)真多模态。不是静态的图片分析,而是动态的视觉推理和分析。
-
4)语音自然,接近人类。这个是字节Seed团队的看家本领了,豆包的TTS技术一直处于全球第一梯队。

有深厚技术实力的豆包
据沃垠AI了解,豆包视频通话功能的底模来自「豆包视觉理解模型」。
这是字节Seed团队在去年12月发布的视觉理解模型,这个模型除了具备视觉感知以外,还具备深度思考能力。这让豆包可以通过摄像头完成诸多复杂任务,比如解数学题、分析论文、诊断代码等。
视觉,一直是人类理解真实世界最关键的信息接收器官之一。对大模型而言也是如此,只有掌握完备的视觉理解能力,才能处理好真实世界的信息,辅助人类完成一系列复杂工作。
一个强大的视觉理解模型需要具备:
1)更强的内容识别能力。无论是图像中的物体类别、形状、纹理等基本要素,还是物体之间的关系、空间布局以及场景的整体含义,甚至背后的文化知识,模型都要能够识别。
2)更强的理解推理能力。模型不仅要能识别图文信息,还要能进行复杂的逻辑计算。
比如,拍一道需要进行微积分运算的数学题,模型需要很好地理解图片问题,并根据提示词进行对应的推理计算,给出答题思路。
又比如《How Far is Video Generation from World Model: A Physical Law Perspective》论文中的图表,模型需要做到准确理解并解析图表。
3)更细腻的视觉描述能力
除了识别和推理能力外,模型还要有非常细腻的视觉描述和创作能力。比如一张小孩的涂鸦画,模型能直接据此创作一个奇幻的故事。
豆包视觉理解模型,不仅具备以上能力,还能做得更好。所以,我们见到了如今的豆包视频通话功能。

写在最后
人类的六大信息接收器官“眼耳口鼻舌身”,分别代表了我们的视觉、听觉、言语、嗅觉、味觉和触觉。
人工智能要想模拟、延伸和拓展人的智能,其中「眼睛+耳朵」是最重要的信息接收器官,也就是要具备「看+听」的感知模式。放在手机上,也就是「摄像头+麦克风」。
如今,豆包的「视频通话功能」功能有了「眼睛+耳朵」,代表着AI与人的交互进入了一种新的维度——AI越来越像人,也越来越实用。
它不是第一款具备视频通话功能的AI助手,也会不是最后一款。
但它一定是最有人情味的那款。
(文:沃垠AI)