

今天是2025年5月28日,星期三,北京,晴
我们来看两个事情,一个是从几张图看RAG以及Agent的问题,有些误区。另一个是基于内部自我置信度作为强化学习监督信号的工作,也是在策略层的一个新思路,可以读读。
一、从几张图看RAG以及Agent的问题
先看一张图,5种RAG分块方式、5种Agent设计模式、4种多GPU训练策略、5种大模型微调方式,这种策略的图,有很多。
策略人手一份,但是在实际的研发过程当中,实际上又会产生很多变体,都是特事特办,补丁不断。
再看另张图,其中引用的这句话,我的确说过,RAG的落地,往往是面向业务做RAG,而不是反过来面向RAG做业务。

这其实说明了,当前,我们做RAG这些大模型落地的时候,无论是召回侧,知识库构建,还是生成等方面,都应该从实际的业务数据出发做工作,把RAG这种技术手段的位置认清楚。一般,如果把先后顺序颠倒之后,你让的业务去适配这种RAG,就会陷入到数据该怎么准备,标准是什么?如何衡量的怪圈当中。而实际上,RAG本身又是可变的,可以根据不同数据情况做适配,RAG是被改方,而不是主导方。
实际上,不光是RAG,目前也有不少人对Agent智能体有许多误解,现在太多人认为agent,或者workflow,dify这种是救命稻草,能包打一切,效果不好就上Agent,这是一个很大的误区。
例如,搭建用于金融分析的智能体:

或者,基于MCP来串出一个智能体来做金融分析:
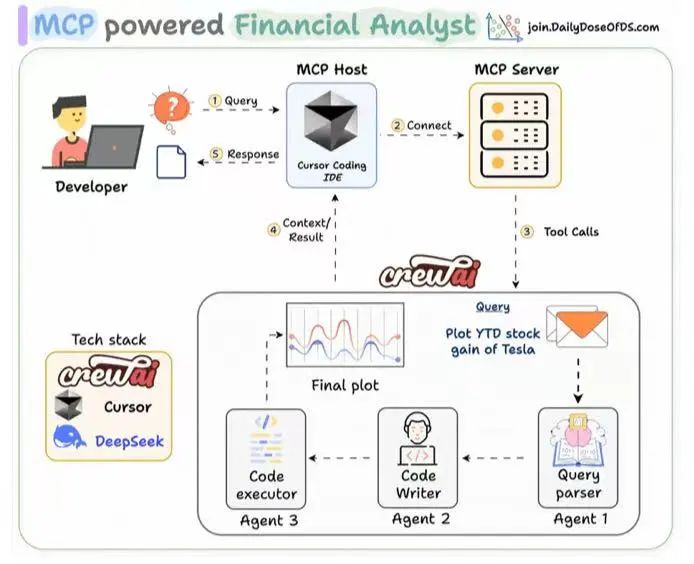
实际上,要是拖拖拽拽搭个流程,把模型串起来就有用的话,那就不需要算法微调,强化这些工作了。其根本逻辑在于,一个工程工具,解决不了算法性能问题,观念先转变过来,会好些。
最近也试了下天工的超级智能体,也是一个集大成,虽然整体效果上看还是存在幻觉问题,但也体现出一些亮点,例如,人工参与确认,主题确认,可编辑等。最终ppt使用html表示,这样能更灵活分配色彩,用md管理执行过程。从生产的中间过程,可以推导出来一些实现细节。
二、基于自我置信度作为强化学习监督信号
关于强化学习这块,有个有趣的工作,《Learning to Reason without External Rewards》,https://arxiv.org/abs/2505.19590,https://github.com/sunblaze-ucb/Intuitor,核心点在于使用模型的自我置信度作为内在奖励信号,这里的自我置信度定义为模型输出分布与均匀分布之间的平均KL散度。
具体的细节如下:
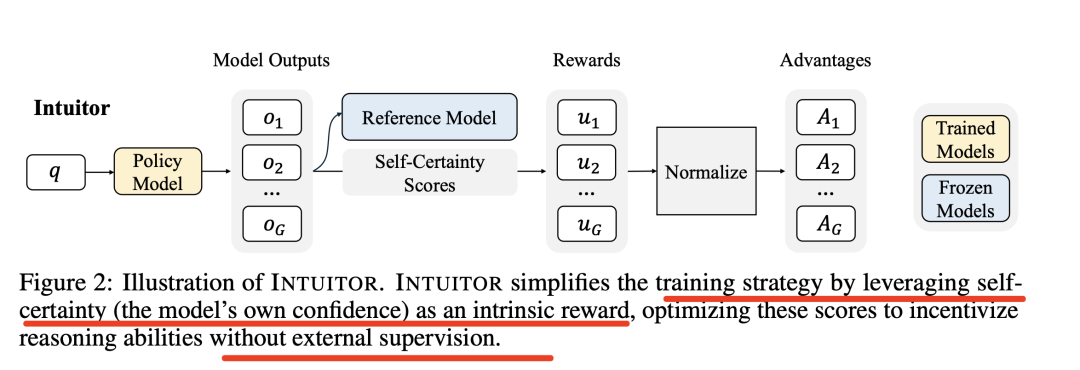
其中,自我置信度的计算如下:

直观理解就是:分成几步:
定义均匀分布(定义一个在词汇表V上的均匀分布U。均匀分布意味着每个词的概率都是相等的,即U(j)=∣V∣,其中∣V∣是词汇表的大小)->计算模型输出分布(对于模型在生成第i个词时的输出分布,记为pπθ(j∣q,o<i),其中q是输入查询,o<i是已经生成的词序列,j是当前步骤可能生成的词)->KL散度计算(计算模型输出分布与均匀分布之间的KL散度)->生成自身置信度(对于于生成的每一个词oi,计算模型输出分布与均匀分布之间的KL散度,然后对所有词的平均值取负值,得到自身置信度,自身置信度越高,表示模型对其生成的词越有信心)。
这里的逻辑在于:LLMs在遇到不熟悉的任务或缺乏足够知识时,通常会表现出较低的置信度,而较高的置信度往往与正确性相关。
参考文献
1、https://arxiv.org/abs/2505.19590
(文:老刘说NLP)