

机器之心编辑部
Pangu Ultra MoE 是一个全流程在昇腾 NPU 上训练的准万亿 MoE 模型,此前发布了英文技术报告[1]。最近华为盘古团队发布了 Pangu Ultra MoE 模型架构与训练方法的中文技术报告,进一步披露了这个模型的细节。
训练超大规模和极高稀疏性的 MoE 模型极具挑战,训练过程中的稳定性往往难以保障。针对这一难题,盘古团队在模型架构和训练方法上进行了创新性设计,成功地在昇腾 NPU 上实现了准万亿 MoE 模型的全流程训练。
盘古团队提出 Depth-Scaled Sandwich-Norm(DSSN)稳定架构和 TinyInit 小初始化的方法,在昇腾 NPU 上实现了 10+ T tokens 数据的长期稳定训练。此外,他们还提出了 EP group loss 负载优化方法,这一设计不仅保证了各个专家之间能保持较好的负载均衡,也提升了专家的领域特化能力。同时,Pangu Ultra MoE 使用了业界先进的 MLA 和 MTP 架构,在训练时使用了 Dropless 训练策略。

-
技术报告标题:Pangu Ultra MoE 模型架构与训练方法
-
技术报告地址:https://raw.gitcode.com/ascend-tribe/pangu-ultra-moe/raw/main/Pangu_Ultra_MoE_CN_Report.pdf
破解准万亿 MoE 模型性能瓶颈
打造芯片协同的先进架构
近期,盘古团队在 MoE 模型训练领域再进一步,重磅推出参数规模高达 718B 的准万亿全新模型 ——Pangu Ultra MoE。该模型旨在实现超大规模 MoE 架构在模型效果与效率之间的最佳平衡。
为了达到这个目标,研究团队在设计 Pangu Ultra MoE 架构的时候,充分考虑昇腾硬件特性,在昇腾 NPU 平台上,融合计算、通信和内存等多维度指标,构建了大规模系统模拟器,并系统性地探索约一万个不同的 MoE 结构组合,最终搜索出一套在训练与推理吞吐上均达最优的架构方案。
Pangu Ultra MoE 是一个超大规模、高稀疏比的架构,同时也包含 MLA 和 MTP 等先进架构和特有的 DSSN 稳定性架构和 EP group loss 负载优化。下面是 Pangu Ultra MoE 的主要的架构和训练特性:
-
超大规模和超高稀疏比:采用 256 个路由专家,每个 token 激活 8 个专家,模型总参数量 718B,激活量 39B。
-
MLA 注意力机制:引入 MLA(Multi-head Latent Attention),有效压缩 KV Cache 空间,缓解推理阶段的内存带宽瓶颈,优于传统 GQA 方案。
-
MTP 多头扩展:采用单头 MTP 进行训练,后续复用 MTP 参数扩展至多头结构,实现多 Token 投机推理,加速整体推理过程。
-
Dropless 训练:采用 Dropless 训练可以避免 Drop&Pad 训推不一致问题,并且提升训练的数据效率。
-
RL 训练:采用迭代难例挖掘与多能力项均衡的奖励函数,并参考 GRPO 算法,提升了模型的训练效率与最终推理性能。
以下是 Pangu Ultra MoE 昇腾亲和设计考虑:
-
隐藏维度贴合硬件:设置 7680 维隐藏层,精准匹配昇腾芯片的 16×16 MatMul 单元,充分发挥 Cube 核心的计算潜力。
-
层数亲和流水线并行:设置 61 层 Transformer 结构,并预留额外 MTP 层空间,保障计算负载均衡的 PP/VPP 流水线调度,减少 pipeline 气泡,提升整体并行效率。
-
专家规模符合幂次规律:路由专家数量设为2⁸=256,在 TP×EP 并行下提升 All-to-All 通信效率,有效加速分布式训练。
Pangu Ultra MoE 的预训练阶段在 6k 到 10k 张 NPU 上进行,全流程采用 dropless 训练模式。预训练阶段进行了长序列扩展,最终模型具备 128k 长序列能力。在后训练阶段,Pangu Ultra MoE 移除了负载均衡辅助损失,保留专家间已有的特化能力,从而进一步提升模型对目标数据的学习效率。如表1所示,最终模型在多个权威开源评测集上展现出一流的效果。
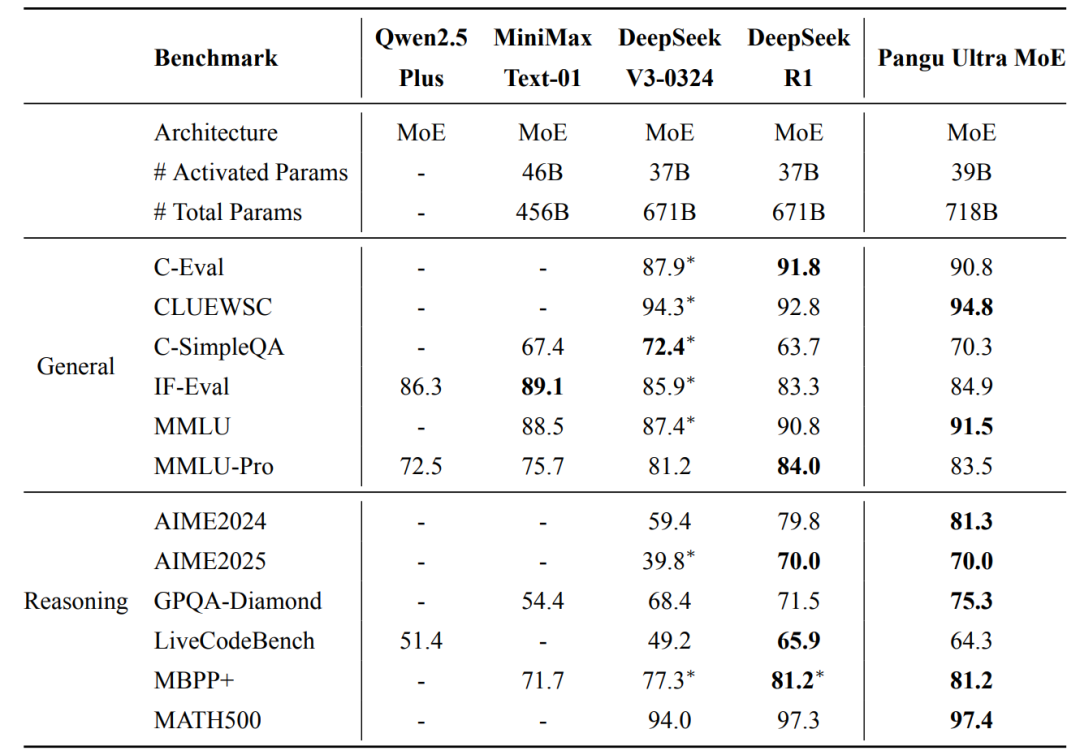
表 1: Pangu Ultra MoE 与目前主流模型效果对比
面向超大MoE模型稳定训练新范式:
DSSN结构和TinyInit加持
梯度突刺率下降 51%
支撑 10+T tokens 数据长稳训练
随着参数规模和数据体量的激增,大模型训练面临前所未有的稳定性挑战。频繁的梯度范数突刺已成为阻碍收敛效率与模型性能提升的主要瓶颈。如何在确保训练深度和宽度扩展的同时,维持梯度信号的稳定传递,成为构建高可靠性大模型架构的关键课题。在 Pangu Ultra 稠密模型 [2] 的训练中,Depth-Scaled Sandwich-Norm 和 TinyInit 方法在保障训练稳定性上起到了关键性的作用,所以 Pangu Ultra MoE 依旧采用这个方案来控制训练稳定性。经过实验证明,此设计在 Pangu Ultra MoE 的训练中同样能起到增强稳定性、加快收敛速度的作用。
Depth-Scaled Sandwich-Norm(DSSN):传统的 Pre-LN 结构存在因为子层输出规模波动而导致训练不稳定的现象,DSSN 是为了解决这一问题而提出的。通过在每个子层输出后加入额外的层归一化,并引入深度缩放的初始化方式,从而稳定网络各层的输出尺度,达到抑制梯度异常、降低范数波动的目的。
TinyInit:Transformer 模型普遍采用较小的初始化尺度,TinyInit 提出一种标准差为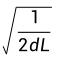 的初始化方案,能够同时兼顾模型深度与宽度,其中d表示隐藏维度,L表示模型层数。同时,对词嵌入层采用标准差为 0.5 的初始化。实验表明,这样的初始化策略有助于提升模型性能和训练稳定性。
的初始化方案,能够同时兼顾模型深度与宽度,其中d表示隐藏维度,L表示模型层数。同时,对词嵌入层采用标准差为 0.5 的初始化。实验表明,这样的初始化策略有助于提升模型性能和训练稳定性。
Depth-Scaled Sandwich-Norm + TinyInit 的方案减少了 51% 的突刺量(见图 1),缓解了梯度范数频繁突刺的问题,能够有效降低大模型训练过程中的不稳定性,加快模型收敛,提升模型性能。同时 DSSN+TinyInit 被应用到 Pangu Ultra MoE 中实现了 10+T tokens 数据的长稳训练。
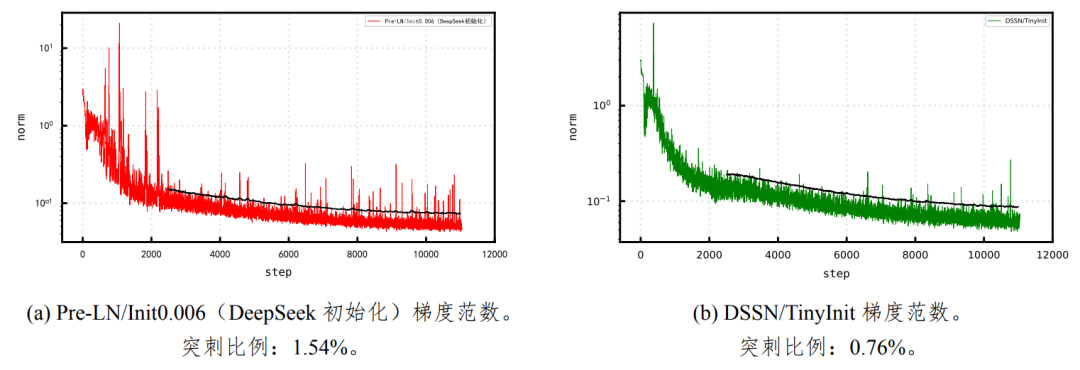
图 1: 训练过程的梯度范数对比图(黑色实线为突刺分界线)。DSSN+TinyInit 使梯度突刺率从 1.54% 下降到 0.76%,相对下降 51%。
基于 EP group 的负载均衡:
让计算效率和路由表达能力可以兼得
在训练混合专家模型(MoE)时,容易出现专家负载不均衡的情况。负载不均衡指的是不同专家被分配的 token 数量存在显著的差距。当采用专家并行策略(EP,expert parallelism)时,负载不均衡会影响计算效率,被分配过多 token 的专家会成为计算瓶颈,而其他专家则处于低利用率状态。同时负载过低的专家可能存在训练不充分的问题,影响最终的模型效果。因此如何使 token 更均衡地分布至不同专家,对提高混合专家模型的训练效率和效果非常重要。
为了保证负载均衡,一般通过增加辅助的负载均衡 loss(auxiliary loss)来约束 tokens 在专家之间均衡分布。然而,如果负载均衡 loss 过度地约束 tokens 分配的均衡性,也会影响模型路由的表达能力。之前主流的负载均衡 loss 一般是约束单个序列或者单个 micro batch 内的 token 分配均衡性,而单个序列往往是来自同一领域的数据,过度的均衡可能影响专家特化(expert specialization)。
盘古团队发现对于采用专家并行策略训练的模型,可以设计一种对模型路由约束更小,同时不影响计算均衡性的 EP-Group 负载均衡 loss。当采用了专家并行,专家会被分配到不同卡上进行并行计算。每块卡上的专家会接收来自 EP 组内所有卡上的 micro batch 路由给自己的 token。所以可以设计一个负载均衡 loss,来约束 EP 组内所有 micro batch 路由到组内专家之后的均衡性。这相当于把 EP 组内部的所有 micro batch 联合起来计算负载均衡的 loss, 这样训练时可以容忍单个 micro batch 的不均衡,只要多个 micro batch 的 token 路由到专家之后是均衡的即可。
为了验证 EP-Group 均衡损失函数的效果,盘古团队使用一个 20B 参数量的 MoE 模型进行了 100B 数据量的对比实验。结果如表 2 所示,可以看到 EP-Group 均衡损失函数在大部分任务相比主流的 Micro-batch 上都有显著的优势,平均提升了 1.5 个点。

表 2: Micro-batch 和 EP-Group 的 auxiliary loss 效果比较
同时盘古团队对 Pangu Ultra MoE 的专家特化进行了分析,结果如图 2 所示,可以看到不同领域的数据对专家的选择存在显著的差异,这表明 EP-Group 均衡损失函数给模型提供了灵活的路由选择空间,促进了专家特化。
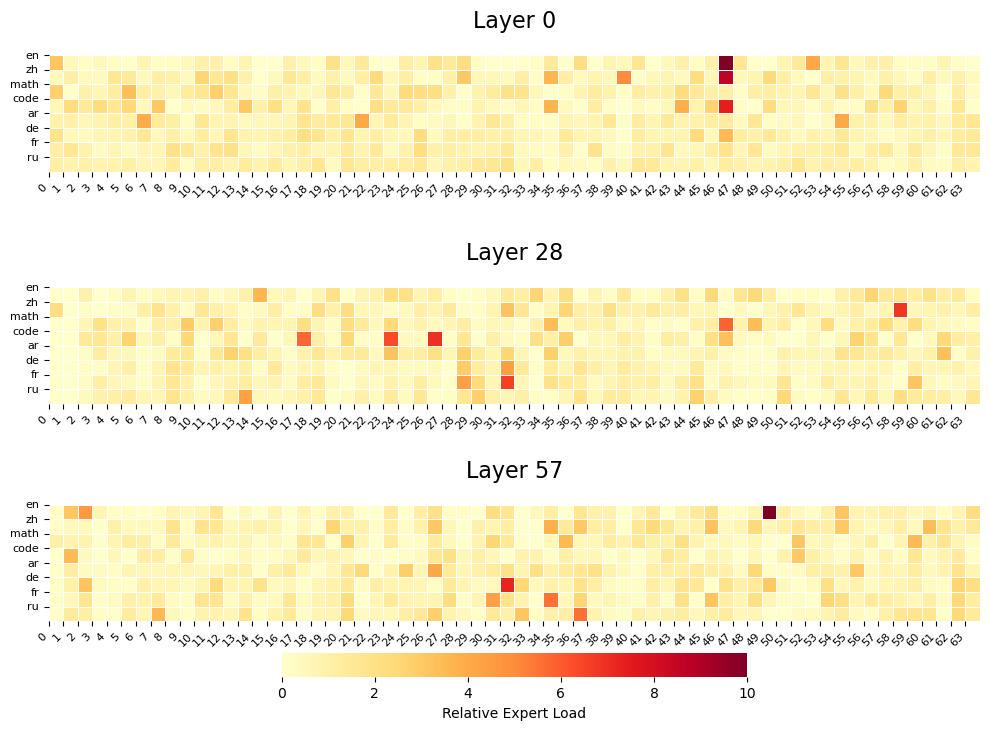
图 2: Pangu Ultra MoE 的专家特化。其中 ar,de,fr,ru 分别代表阿拉伯语,德语,法语,以及俄语。
多 Token 投机推理新路径:
MTP 头延迟扩展策略
投机接受长度预期提升 38%
投机推理是一种提升大模型生成效率的有效方法,其核心思想是在主模型生成 token 之前,由一个轻量辅助模块预先预测多个候选 token,并通过快速校验机制决定是否接纳,从而实现推理过程的并行化与加速。在当前大模型推理中,Multi-token Prediction(MTP)技术已成为实现多 token 级别投机生成的重要手段。
盘古团队在实践中发现,获取多 token 的投机推理能力并不需要从训练开始便配置多个 MTP 头,而是可以在训练后期对单头 MTP 进行扩展来达到类似的效果。为验证这一策略的有效性,团队使用 20B MoE 为主干模型,训练 185B 数据。具体对比设置为:以两个 token 的投机推理为目标,分别训练了从头开始配置单 / 两个 MTP 头的模型(即单头从头训练和双头从头训练),以及在单头 MTP 模型训练至收敛后,通过复制已有头的参数再增训出第二个 MTP 头的模型。对于扩增的模型,对比全参续训以及冻结主干和一头的续训的效果,即双头扩增全参训练和双头扩增冻结训练。下游使用 LAMBADA 续写作为评测任务。
结果如图 3 所示。双头扩增模型的接受长度和延迟基本和双头从头训练一致,而双头的接受长度约 2.30,单头的接受长度约 1.67,双头相对单头提升约 38%。在模型效果方面,双头扩增模型全参训练和从零训练相当,而由于冻住了主干和一头,双头扩增冻结训练的精度在扩增的位置基本保持不变。这表明后期的 MTP 扩展可以达到多头的从头训练的投机推理效果,可以在模型训练早期保持较小的 MTP 配置并在后期再进行扩展,兼顾计算成本和推理能力。
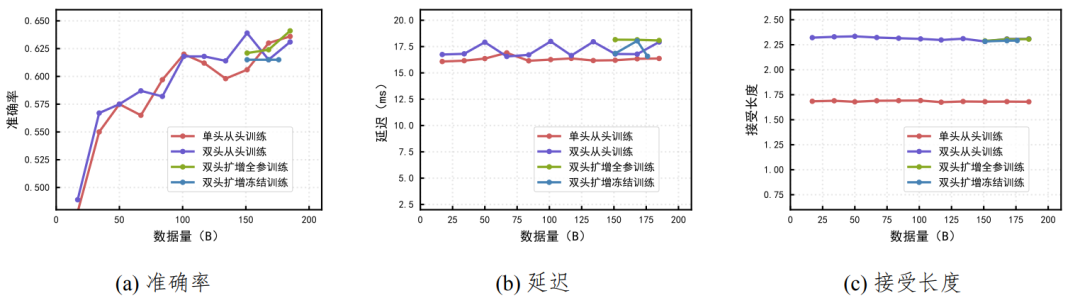
图 3: 20B MoE 的 MTP 在 LAMBADA 续写上的投机推理结果。在接受长度上,双头相对单头提升约 38%,而双头可以基本无损地通过后期扩增单头得到。
迭代难例挖掘与多能力协同:
后训练强化学习持续提升的关键
模型后训练的过程中,团队参考了业界常规的 GRPO 算法提升模型的推理性能。然而,在超大参数规模情况下,直接应用 GRPO 会带来两方面的问题:1. 算法训练需要依赖多回复通过率在 (0,1) 内的数据,随着模型性能的提升,相同 prompt 的推理结果准确率越来越高,导致训练过程中被 “浪费” 的数据不断增加,降低推理效率;2. 模型训练需要兼顾多能力协同提升,包括数学、代码和通用能力等,不同能力项的奖励函数设计会导致模型能力增长上的不匹配,出现 “跷跷板” 问题。

图 4: Pangu Ultra MoE 的强化学习训练系统
为了解决上述两个实践难题,盘古团队设计了 Pangu Ultra MoE 的强化学习训练系统,如图 4 所示,提升了大 MoE 模型的训练稳定性与推理性能。系统设计的关键在于两个部分:(1)迭代难例挖掘:模型阶段性更新后,从初始的数据池中进行多回复推理,选取回复通过率在 (0,1) 的数据组成 RL 训练数据池,以保持推理效率最大化;(2)多能力项奖励系统:为了确保模型多能力项协同提升,数学和代码均采用了基于规则的奖励,通用奖励模型则使用 LLM-as-a-judge 的方法对生成的回复质量进行评分,并对最终的 reward 进行归一化处理,保证了模型在多个能力项的综合表现。
[1] Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
https://arxiv.org/abs/2505.04519
[2] Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
https://arxiv.org/abs/2504.07866
©
(文:机器之心)