

西风 发自 凹非寺
量子位 | 公众号 QbitAI
波士顿动力带机器人看世界,Altas重磅升级了!
现在,它具备3D空间感知和实时物体追踪能力,可以自主执行更复杂的工业任务。
请看Altas在汽车工厂打工VCR:
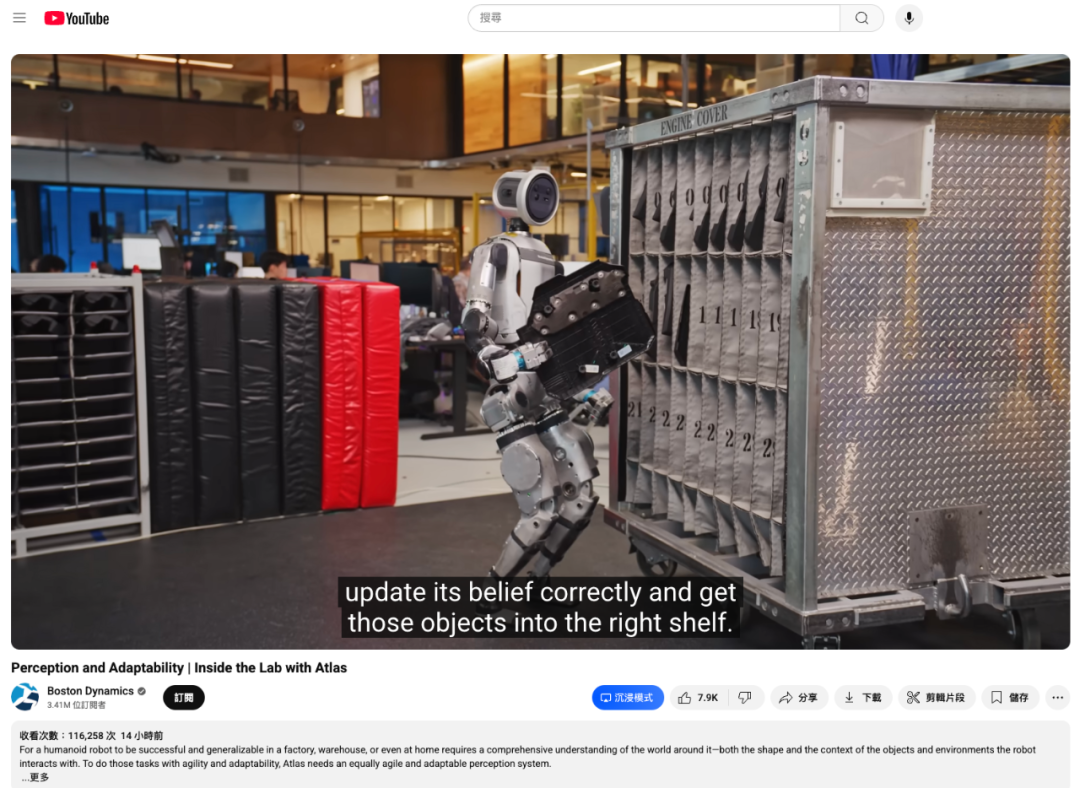
小哥故意将汽车零部件丢在地上,只见它360°转动头部环顾四周,随后成功识别并将其放入正确位置:
(就是偷感好重,笑死)
故意移动装置位置,它也能精准感知到变化:

然后依旧稳稳地将零部件放入槽内:

头部和腰部都可360°旋转,干起活来那叫一个麻利:

据介绍,Altas的一系列功能升级源于波士顿动力团队对Altas感知系统进行的全新设计,融合了2D与3D感知技术、物体位姿追踪,以及基于物理特性的精确校准方案。
网友看到该新成果后纷纷叫好。光是官方在YouTube上发布的视频就引来了十余万人围观,点赞量近8k。
网友纷纷表示Altas能够观察到物品掉落还会环顾四周观察,这个能力非常炫酷。

还有网友表示迫不及待希望看到它们能够在实际工作环境中投入使用。

除此之外,关于全新能力具体实现,官方发布了技术Blog。
背后技术解析
波士顿动力团队表示,拿起一个汽车零件并将其放入正确的插槽,这一看似简单的任务对于机器人来说实际上并不容易。
它需要将这个任务拆解为多个步骤,而每个步骤都需要关于环境的广泛知识。
Altas得先检测并识别物体,工厂中许多零件有的是金属材质的具有光泽感,有的对比度低颜色深暗,所以机器人摄像头如何清晰区分就是一大挑战。

然后,Altas需要推断物体的位置进行抓取,它是在桌子上敞开放置,还是在视线受限的容器内?
拿起物体后,Altas还需要决定将其放置在何处以及如何送达该位置。
最后,Altas要精确放置物体,任何方向偏差几厘米都可能导致物体卡住或掉落。
因此,它还要能在出现问题时采取纠正措施。

例如,若插入失败,它可以利用基于工厂零件训练的基础视觉模型的通用性和其本身大活动范围,搜索并从地面捡起掉落的零件。
下面具体来看波士顿动力是如何解决这些问题的。
2D感知:环境中有哪些物体?
首先机器人需要具备2D感知能力,确定周围的环境是否存在障碍物、目标物体或地面风险。
波士顿动力透露其2D物体检测系统主要通过物体标识、边界框、关键点的形式,为机器人提供环境信息。
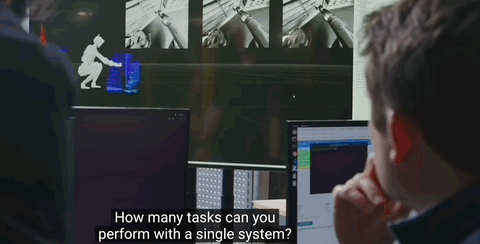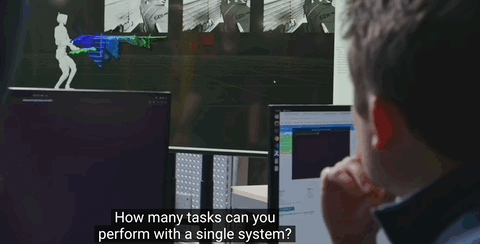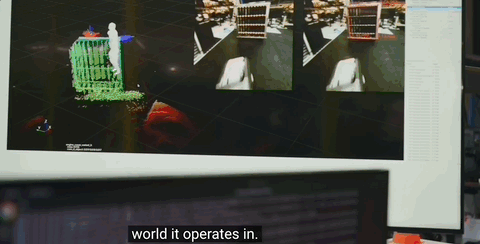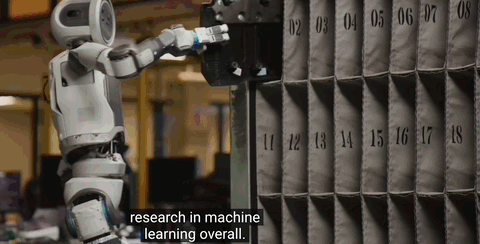
比如在开头所展示的Atlas存储汽车零件的场景中,系统重点检测存储汽车零件的大型货架这一固定装置。
这些装置形状尺寸各异,Atlas需识别其类型并定位空间占位,以规避碰撞风险。除了检测和识别所有固定装置外,系统还将装置边角定义为关键点,通过匹配内部存储的装置模型,实现感知环境与虚拟模型的坐标对齐。

而这其中,固定装置的关键点是2D像素点,分为两种类型:
-
外部点(绿色):捕捉装置外部轮廓,如货架正面的四个边角,用于快速定位装置整体位置; -
内部点(红色):数量更多且形式多样,捕捉特定固定装置内货架和小隔间的内部分布,从而实现对单个插槽的精确定位。
另外,为了执行固定装置分类和关键点预测,Atlas使用了轻量级网络架构,平衡了性能与实时感知能力,这对Atlas的敏捷性至关重要。
3D感知:物体相对于Atlas的位置在哪里?
接下来,Atlas若想精准操作固定装置内的物体,必先明确自身与目标装置的相对空间关系。
其核心依赖基于关键点的固定装置定位模块,该模块可实时估算Atlas相对于周围所有装置的位置与朝向。

定位系统接收来自物体检测流程的内部、外部关键点,通过最小化重投影误差将这些关键点与预设空间分布模型对齐。
系统还会接收运动里程计数据(用于测量Atlas的移动距离和方向),以便在统一坐标系中融合固定装置的位姿估计,提升对关键点噪声的鲁棒性。
其中的一个关键挑战是处理频繁的遮挡和超出视野的关键点。例如,当Atlas靠近某个固定装置或视角倾斜时,部分外部关键点可能不在视野内或者不可靠。
这时,定位系统转而依赖固定装置内部插槽分隔线的拐角关键点(与物体取放直接相关的区域)来解决这一问题。
但这又带来了2D关键点与3D拐角的关联挑战,即图像中的每个关键点对应哪个3D拐角?
Atlas首先通过外部关键点进行初步近似,从而对内部关键点的关联做出初步猜测,然后结合内外部关键点生成更可靠的固定装置及其所有插槽的位姿估计。
其次,部分固定装置在视觉上完全相同,这种情况在工厂中非常常见,也给实际场景带来了额外挑战。

Atlas通过结合时间一致性和不同固定装置间相对位置的先验知识(例如,假设装置A位于装置B右侧半米处)来解决这一问题。
所有这些特性共同构成了一个可靠且敏捷的固定装置感知系统。

所以,当有人移动Atlas身后的固定装置时,机器人会迅速识别预期位置与实际位置的差异,重新定位装置,并相应地重新规划行为。
物体位姿估计:Atlas如何与物体交互?
接下来再看看,Atlas是如何与物体交互的。
据介绍,Atlas物体操作能力依赖于准确、实时的以物体为中心的感知。其物体位姿跟踪系统SuperTracker融合了多源信息,包括机器人运动学数据、视觉数据,必要时还包含力反馈数据。
具体来说,来自Atlas关节编码器的运动学信息可帮助确定Atlas的抓手在空间中的位置。当Atlas识别出它已经抓取到一个物体时,这些信息为Atlas在移动身体时物体应该处于的位置提供了强有力的先验知识。
通过融合运动数据,Atlas可以处理物体在视觉上被遮挡或不在摄像头视野中的情况,并感知物体是否从抓手中滑落。
当物体处于摄像头视野内时,Atlas使用一种“渲染-比较”方法来估计单目图像中的位姿,背后是一个物体位姿估计模型。
该模型通过大规模合成数据训练而成,在给定CAD模型的情况下可对新物体进行零样本泛化。当使用3D位姿先验初始化时,模型会迭代地细化该先验,以最小化渲染的CAD模型与捕获的摄像头图像之间的差异。
此外,位姿估计器也可通过2D感兴趣区域先验(如物体掩码)初始化,随后生成一批位姿假设并输入评分模型,最终对最优假设进行优化。
波士顿动力透露,Atlas的位姿估计器已在数百种工厂资产上通过了可靠验证,这些资产均已在内部完成建模和纹理映射。

SuperTracker将视觉位姿估计作为3D先验接收。在Atlas面临的操作场景中,由于遮挡、部分可见性和光照变化,视觉位姿估计可能存在歧义。
为此,系统使用一系列滤波器验证位姿估计:
-
自洽性:不依赖单一的位姿先验,而是使用一批扰动初始值,并通过基于最大团的一致性算法验证输出,确保收敛到相同的预测位姿; -
运动学一致性:作为强制接触的代理,拒绝任何导致手指与物体距离异常过大的预测位姿。
运动学和摄像头输入通过固定滞后平滑器异步处理。该平滑器接收来自Atlas关节编码器的高速率运动输入历史,以及机器学习模型的低速率视觉位姿估计,进而确定最优的6自由度物体轨迹。
校准:Atlas是否真的处于其“认为”的位置?
波士顿动力团队还强调,在执行精确操作任务时,不能低估经过良好校准的手眼协调的重要性,即Atlas的“视觉感知”与“动作执行”之间精确可靠的映射关系。

上图显示了Atlas的机身内部模型叠加在实时摄像头画面上的效果,其手臂、腿部和躯干与机器人“认知”中的位置几乎完全对齐。
而这背后是一套精心设计的摄像头和运动校准程序,用于补偿机器人机身制造和组装中的不精确性,以及因温度变化或反复物理冲击等外部因素导致的随时间产生的物理变化。
波士顿动力团队表示,根据他们的经验,“精确的手眼校准是实现高性能操作和感知驱动自主能力的关键前提”。
One More Thing
团队还透露了未来计划——正专注于为Atlas构建统一的基础模型:
未来的发展将超越传统感知范畴,推动感知与动作从分离过程向融合过程转变,实现从空间人工智能到“运动智能”的范式升级。

(文:量子位)