作者|沐风
来源|AI先锋官
临近端午假期,DeepSeek官方宣布DeepSeek R1模型已完成小版本试升级,欢迎前往官方网页、App、小程序测试(打开深度思考),API接口和使用方式保持不变。
紧接着,在今天凌晨,官方又在HuggingFace上开源了DeepSeek-R1-0528。
https://huggingface.co/DeepSeek-ai/DeepSeek-R1-0528/tree/main
不过,DeepSeek官方此次并没有公布版本更新的具体内容。
有消息称,该模型是基于DeepSeek-V3-0324训练(参数为660B)。
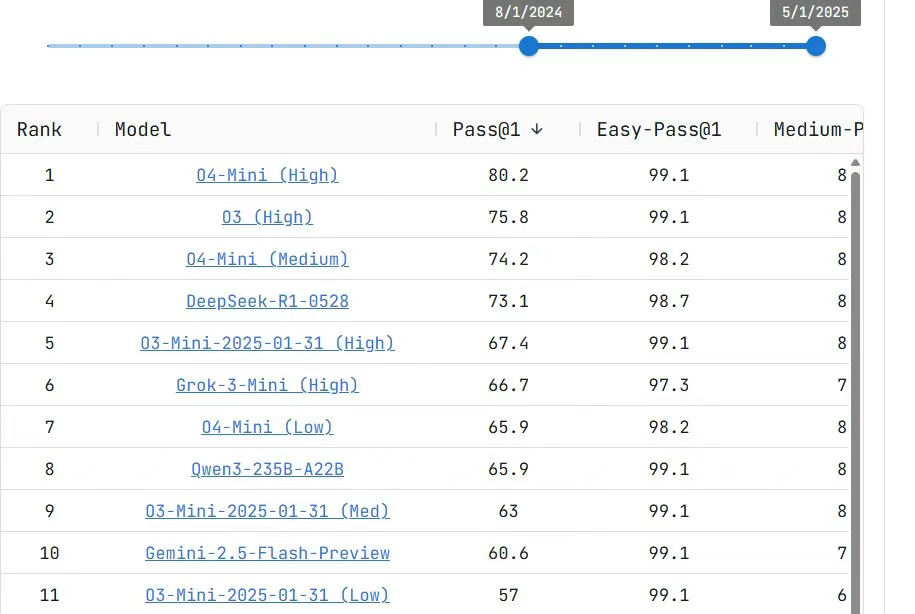
据众多开发者测试发现,DeepSeek-R1-0528目前提升最为明显的也是代码能力。
在代码测试平台Live CodeBench中,其性能几乎媲美OpenAI的o3-high和o4-mini(Medium)超越了Gemini 2.5 Flash。
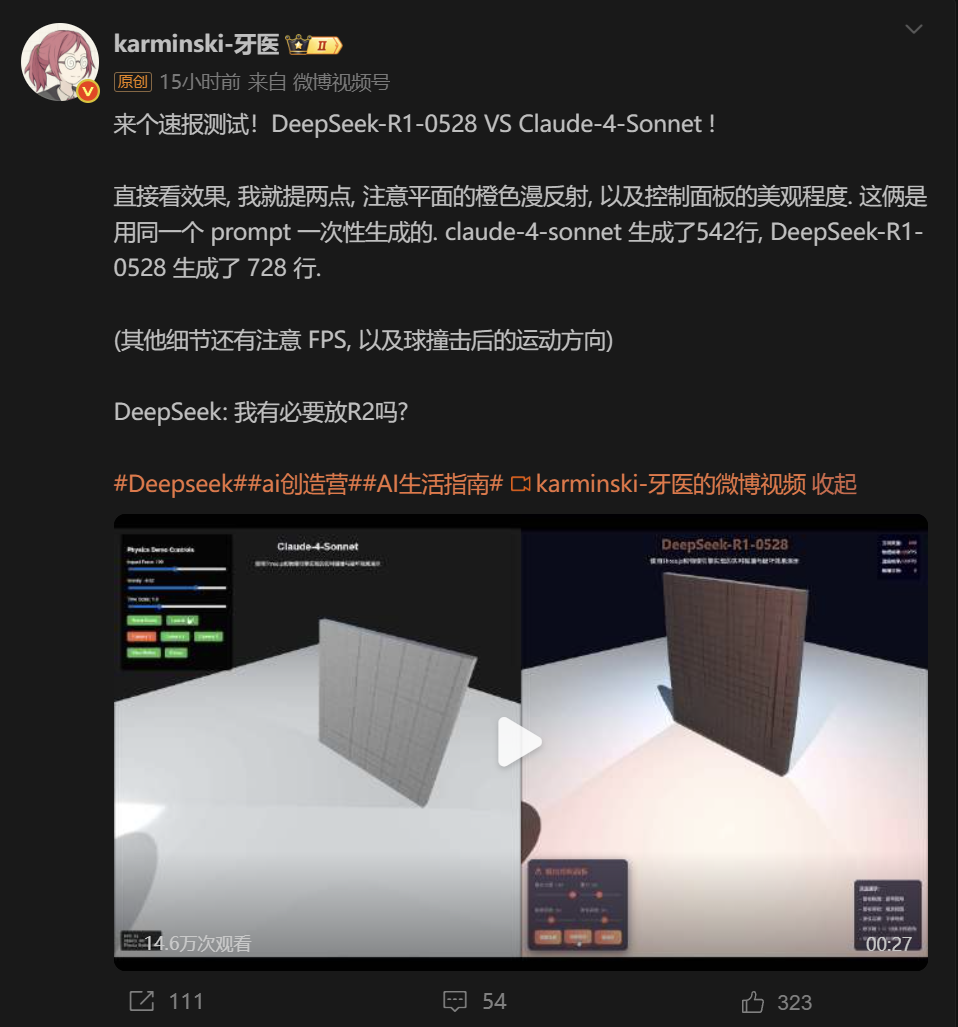
AI博主同时也是KCORES开源硬件项目联合创始人“karminski-牙医”使用DeepSeek-R1-0528和Claude-4-Sonnet进行了对比测试。
在Prompt相同,且一次性生成的情况下, Claude-4-Sonnet生成了542行, DeepSeek-R1-0528生成了728行。
从平面的橙色漫反射、控制面板的美观程度、撞击后的运动方向等效果上看,DeepSeek-R1-0528更加出色。
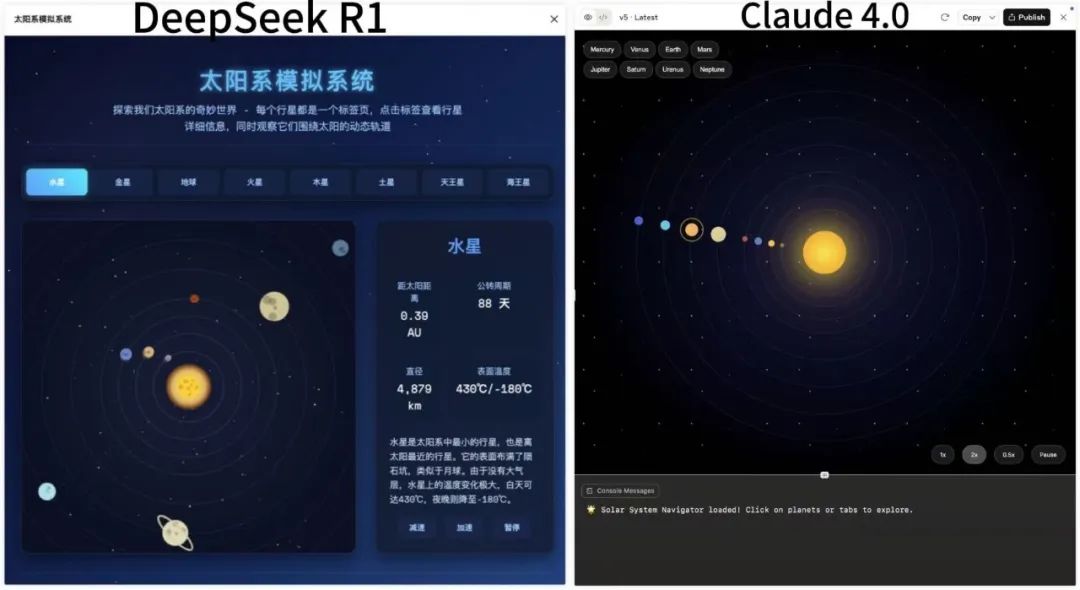
另外,根据其他网友的测试结果显示,DeepSeek-R1-0528在前端设计的审美、编码能力上也已经达到了Claude 4 Sonnet水准。
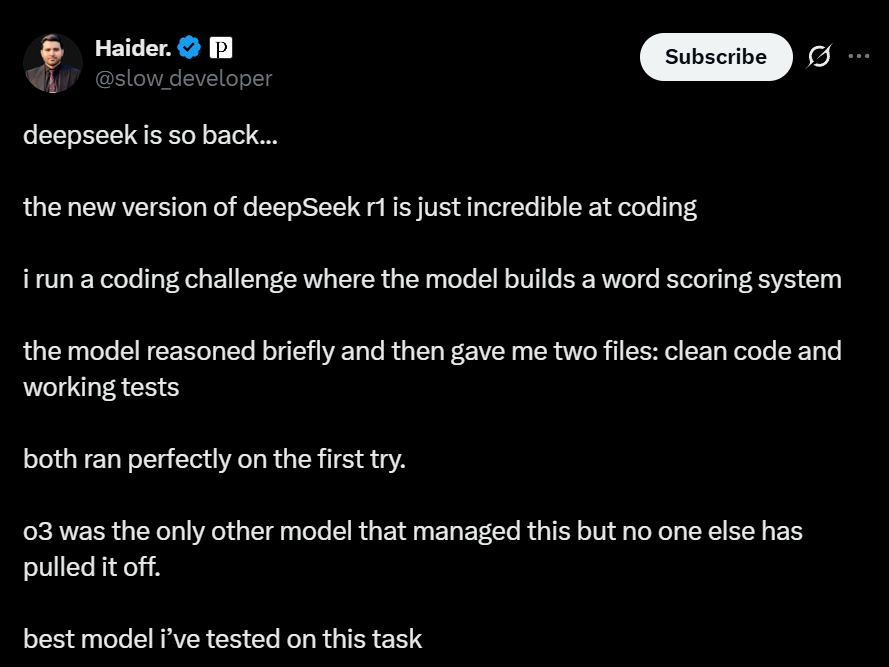
X博主Haider.更是直接称赞到“这是我在这个任务上测试过的最好的模型”,他让DeepSeek-R1-0528构建一个单词评分系统。
DeepSeek-R1-0528简要思考后,一次性生成两个文件,一个是主程序,一个是测试脚本,代码结构清晰,逻辑闭环,首次运行就顺利通过,没有报错。
该博主称,此前,o3是唯一能完成这个任务的模型,DeepSeek-R1-0528是第二个,堪称是完成这个任务的最佳型。
不过,DeepSeek-R1-0528在编程能力的全面性上还是有一点点不足。
例如,缺少多模态能力,它不能像Claud那样通过截图来描述代码错误,调试比较麻烦。
但即便如此,它在代码生成方面已经稳稳站在了Claude 3.7和Claude 4之间的水平。
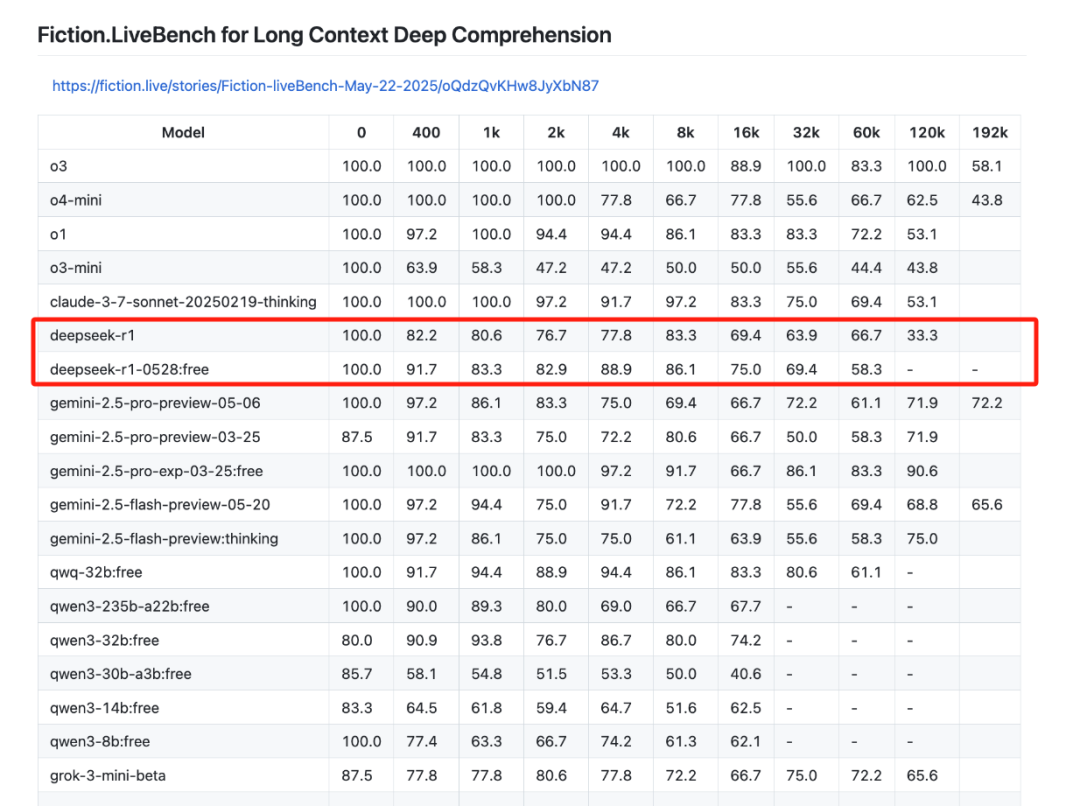
“karminski-牙医”还对其进行了文本召回测试。
发现DeepSeek-R1-0528在上下文32K以内比之前的R1模型要好不少,但是在60K的上下文中效果下降了不少。
这意味着在32K以内针对给定的材料向DeepSeek-R1-0528提问问题,它回答的准确度会更好。
不过,最具争议的一点是,思考时间更长,有网友实测后,R1思考时长超过了25分钟。
有网友认为,它的思考过程之所以很长,是为了弥补推理能力,导致响应速度比较慢。
但也有网友认为,长思考可以让它给出的答案更加准确。
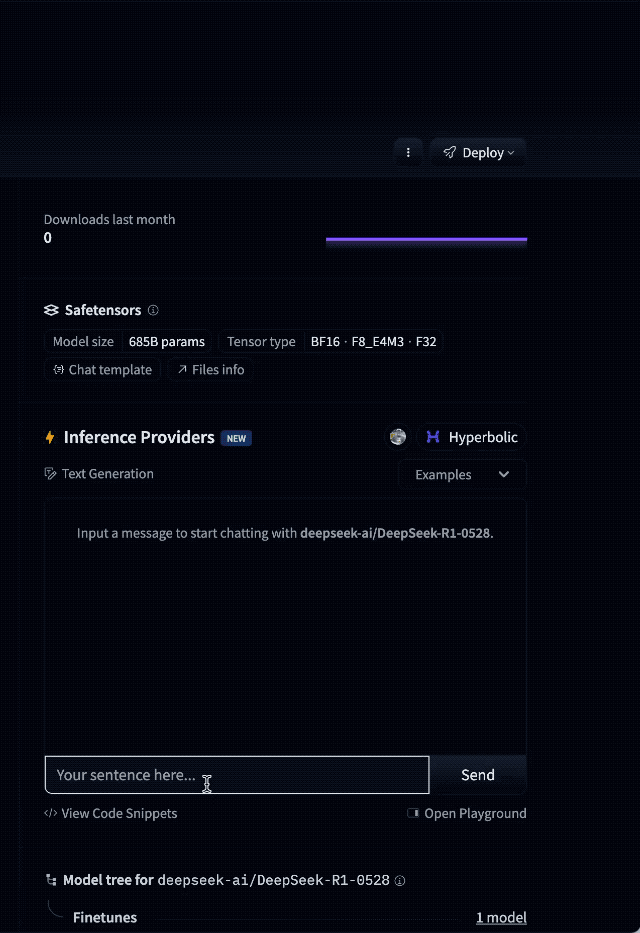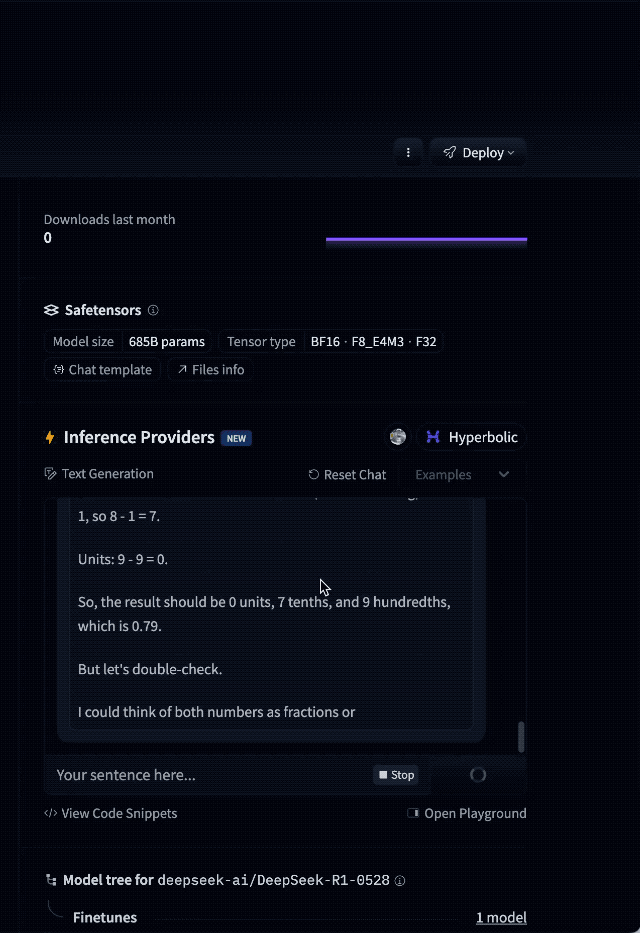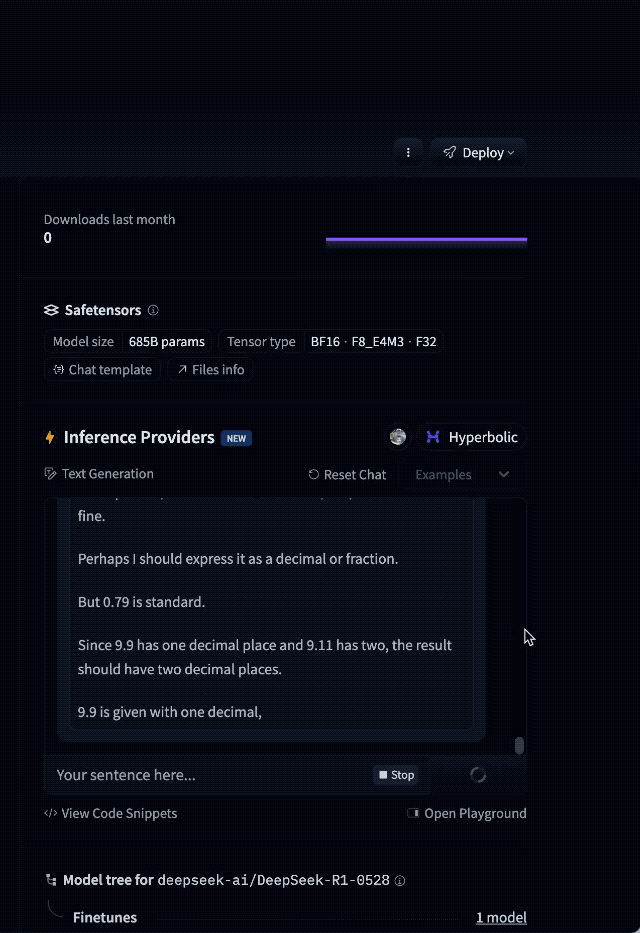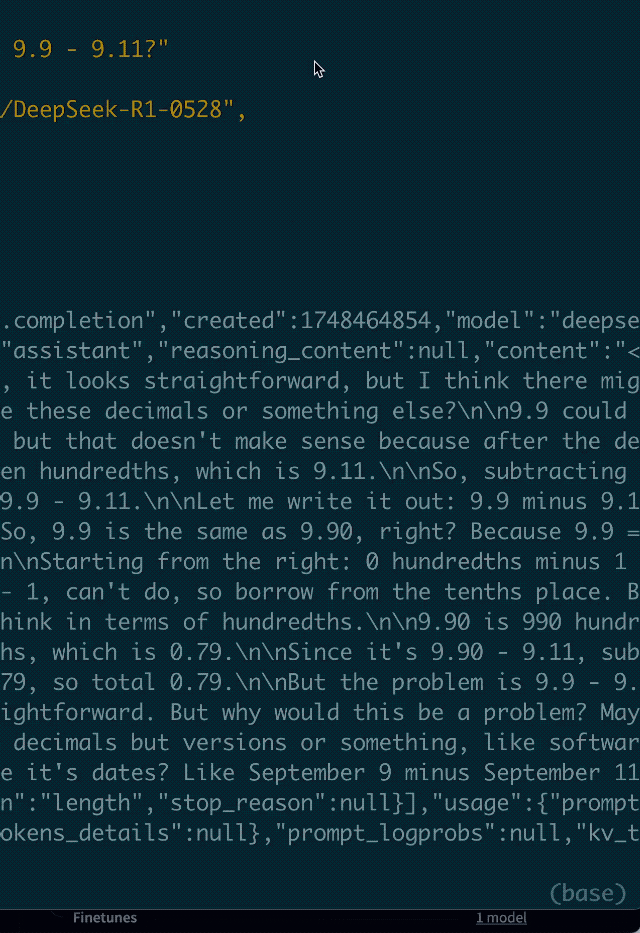
例如,有网友提到,DeepSeek-R1-0528是目前唯一一个能稳定正确回答“9.9-9.11 等于多少?”的模型。
虽然官方称此次R1是“小版本试升级”,但在网友看来却是一次实打实的真升级。
许多网友不禁让感叹,如果这是R1,那么R2会有多好?
但此次DeepSeek-R1-0528的发布也意味着R2恐怕还得再等等。
DeepSeek该不会觉得只要不是模型架构更新,只是能力变强就不算大版本升级?
(文:AI先锋官)