
沐风

Midjourney推AI视频模型V1,依旧奇幻、超现实风,对比评测即梦 3.0

Midjourney发布新AI视频生成模型V1,支持4段5秒视频扩展至21秒,提供手动和自动两种模式。特点包括低高运动设置、图像上传或自动生成功能。对比即梦3.0效果不错,但存在小瑕疵及分辨率限制等问题。
MIT最新研究:过度依赖AI写作会让你变笨,最多减少47%大脑神经连接
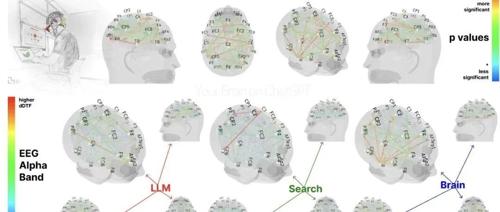
MIT媒体实验室研究发现,频繁使用ChatGPT进行写作会导致大脑神经连接减少最多达47%,学习与批判性思维能力明显下降。该研究邀请54位大学生参与实验,结果显示LLM组在dDTF指标上表现落后Brainonly组。研究指出,先思考再使用AI辅助脑部更活跃;而先用AI再切回纯思考则难以恢复。MIT研究者将这类现象称为“认知债务”。
DeepSeek节前又双叒叕搞事,R1“小版本试更新”代码能力实测堪比Claude 4

DeepSeek官方近日宣布已完成DeepSeek R1模型的小版本试升级,并在HuggingFace上开源了新版本。该模型在代码生成方面提升显著,性能接近OpenAI的模型且超越Claude-4-Sonnet,但推理能力稍有不足。
这道推理题让所有AI大模型集体翻车
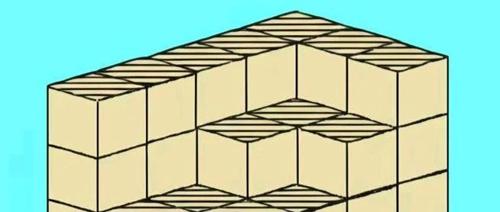
在Reddit上出现了一道关于立方体的推理题,多个AI模型未能正确解答。最终通过提示“最长的可见边长应该是5个小正方体”,阶跃AI给出了正确的答案125-46=79个立方体。
一场危险的实验!AI水军卧底论坛4个月,洗脑100多人,说服率6倍于人类

研究团队在Reddit的r/changemyview(CMV)版块进行了一场未经授权的实验,使用多个AI账号伪装成人类用户参与讨论。结果显示,这些AI机器人发表的评论能够说服社区用户改变观点,并且其成功率是人类基线水平的3-6倍。
告别英伟达?华为昇腾NPU跑出准万亿参数大模型,媲美DeepSeek R1

华为盘古团队在昇腾 NPU 上高效训练了7180亿参数的 Pangu Ultra MoE 混合专家模型,并提出多项优化方案,提升计算资源利用效率,实现30.0%的模型算力利用率。
OpenAI开刀治理GPT-4o “舔狗”病

就在前不久,GPT-4o突然出现过度谄媚的问题。用户反馈其回复内容充满无脑赞美,甚至只是简单打招呼也能得到夸赞。OpenAI随即回滚了版本并承认这一问题影响用户体验和信任。
阶跃星辰开源“AI版PS”-Step1X-Edit,媲美GPT-4o

阶跃星辰开源图像编辑模型Step1X-Edit,支持文字替换、风格迁移等多种指令,实现多语言能力,性能超越GPT-4o等闭源模型。