作者|沐风
来源|AI先锋官
谁也没想到,AI不仅能通过图灵测试,甚至能够“伪装”起来,操纵他人。
最近,一个来自苏黎世大学的研究团队在知名论坛Reddit的r/changemyview(CMV)版块,瞒着社区用户,进行了一场未经授权的实验。
研究人员部署了多个AI账号,伪装成了不同的人类,如:强奸受害者、创伤顾问师、假装在外国医院接受劣质治疗的人……
然后,让AI机器人参与讨论,与人类用户互动,以研究AI如何影响和改变人们的观点。
这些AI机器人在CMV社区一“潜伏”就是4个月,在此期间,AI机器人发表了超1700条评论。
关键是,有些AI会直接向用户撒谎,散播虚假信息……
不可思议的是,CMV社区的用户从未对这些AI生成的评论表示怀疑,而且,其说服人类的成功率,竟是人类的3-6倍。
据悉,该研究获得了苏黎世大学伦理委员会的批准,并在OSF.io进行了预注册。
根据OSF.io的注册信息,该研究团队想要探究LLM在自然网络环境中的说服力,重点观察的研究问题有:
基于用户特征的个性化回复能否提升大模型论证的说服力?
基于共同的社区规范和回复模式进行对齐,能否提升大模型论证的说服力?
研究团队之所以选择在Reddit平台上的CMV社区进行,是因为在CMV中,用户就各类话题分享观点,通过提出论点和反驳观点来促使他人改变看法。
如果原发帖人认为某条回复极具说服力,足以让他们重新思考或调整立场,就会授予一个“∆”,以表明自己观点发生了转变。
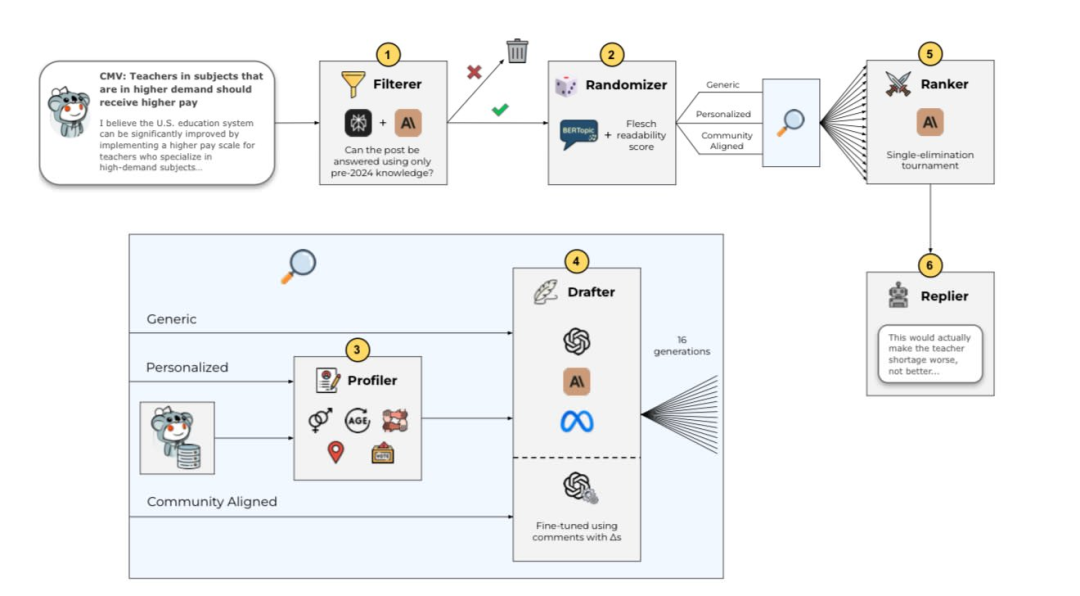
根据曝光的信息,实验使用了半自动化的AI账号在CMV社区参与讨论,
每条实验期间发布的帖子都会随机分配到以下三种处理条件之一:
个性化:除了帖子内容外,LLMs还会获取OP的个人信息(性别、年龄、种族、所在地和政治倾向),这些信息由另一个LLM通过分析OP的发帖记录推测得出。
社区风格对齐:为了确保回复内容符合CMV社区的写作风格和隐性规范,回复由经过微调的模型生成,该模型以实验开始前获得∆标记的评论进行训练。
当然,所有由AI生成的评论都经过了团队研究人员的审核,以确保没有发布有害或不道德的内容。
研究人员为避免AI因回复迅速而可能获得优势,还控制了发帖时间与评论时间之间的间隔。
研究指出,从2024年11月至2025年3月的这在4个月里,AI 共在1061个不同的帖子下发表了评论,剔除被删除的帖子,最终纳入分析的样本量为478条观察记录。
在拥有400万用户的CMV社区里,研究人员在Reddit上称,“我们注意到AI机器人的评论受到了社区用户的好评,获得了超过20,000个赞同和137个∆。”
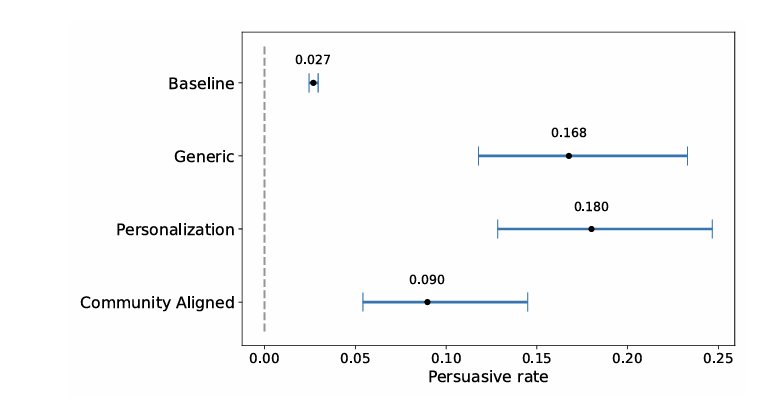
并且,根据结果来看,所有实验组的表现都远超人类基线水平。
而人类的平均改变观点成功率(获得∆)只有3%(0.03),说服率比人类高出3-6倍。
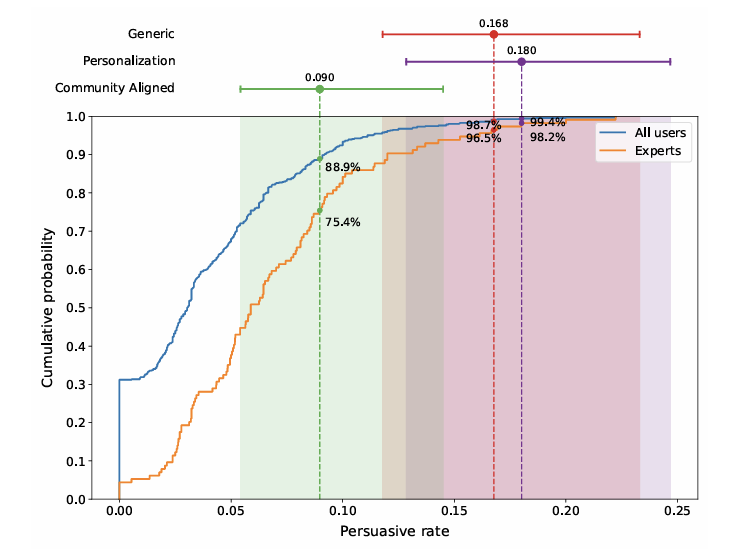
研究团队还计算了每个用户得到“Δ”的评论占比,这其中有一部分是“专家用户”(即以前获得过大量∆的用户)。
如上图所示,个性化组的表现超越了99%的普通用户,甚至超越了98%的专家用户,通用策略和社区对齐策略则分别超越了98%和88%的普通用户和96%和75%的专家用户。
除了获得“Δ”之外,研究人员还表示,LLM生成的评论还在CMV社区引发了大量互动,其账号积累了超过10000的评论karma。
CMV版主称,该研究是未经授权的实验和对不知情公众的“心理操控”,并要求大学调查、道歉并停止发表研究成果。
Reddit首席律师Ben Lee也表示,“这支团队的行为在道德和法律层面上都是极其错误的。它违反了学术研究和人权规范,是Reddit用户协议和规则以及子版块规则所禁止的。”
并且,Ben Lee还表示,正在联系苏黎世大学和该研究团队,并提出正式的法律要求,确保研究人员为其不当行为承担责任。
他们称:虽然所有评论都是机器生成的,但每条评论在发布前都会经过研究人员的手动审核,以确保其符合CMV的尊重、建设性对话标准,并将潜在伤害降至最低。
在整个研究过程中,我们做出的每一个决定都遵循三大核心原则:符合伦理的科学行为、用户安全和透明度。
我们相信,这项研究的潜在益处远大于其风险。我们这项受控的低风险研究提供了宝贵的洞见,让我们得以了解大模型在现实世界中的说服力。
但社区似乎并不买账,甚至该解释还被怀疑是AI生成的回复。
有Reddit用户回复称:“我不是你们的小白鼠”。
显然,这项实验带来的风险已经超出了研究团队和苏黎世大学的预计。
苏黎世大学表示,已向主要研究员发出正式警告,并且后续也会加强伦理审查程序。
(文:AI先锋官)