

中国科学院计算技术研究所(ICTNLP)最新开源了一款类GPT-4o的多模态模型,支持文本、视觉和语音的任意组合交互,生成文本和语音回复。
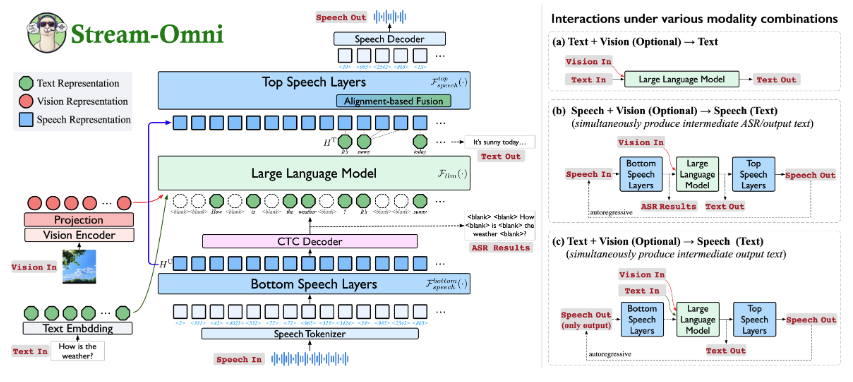
其模型名称为:Stream-Omni,其独特的“边听边看”体验媲美GPT-4o高级语音服务。

核心在于高效模态对齐技术,仅需少量多模态数据(尤其是语音数据)即可训练。
核心功能
-
• 多模态交互:支持文本、图像、语音等输入介质,生成文本和语音输出,适配任意模态组合。 -
• 高效训练:仅需少量全模态数据即可进行训练。 -
• 无缝的“边听边看”体验:在语音交互过程中同时输出中间文本结果(例如,ASR转录和模型响应),就像GPT-4o的高级语音服务一样。
快速入门
Stream-Omni的安装照样还是需要通过Python环境来进行安装部署。
步骤如下:
安装Python虚拟环境,并安装固有依赖包和CosyVoice项目依赖
conda create -n streamomni python=3.10 -y
conda activate streamomni
pip install -e .
pip install flash-attn --no-build-isolation
pip install -r requirements.txt
pip install -r CosyVoice/requirements.txt安装完成后,运行下面的脚本以实现视觉基础语音交互。
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH=CosyVoice/third_party/Matcha-TTS
STREAMOMNI_CKPT=path_to_stream-omni-8b
# Replace the path of cosyvoice model in run_stream_omni.py (e.g., cosyvoice = CosyVoiceModel('./CosyVoice-300M-25Hz'))
# add --load-8bit for VRAM lower than 32GB
python ./stream_omni/eval/run_stream_omni.py \
--model-path ${STREAMOMNI_CKPT} \
--image-file ./stream_omni/serve/examples/cat.jpg --conv-mode stream_omni_llama_3_1 --model-name stream-omni \
--query ./stream_omni/serve/examples/cat_color.wav最终会输出下面的示例信息,确保使用流程上没有其他问题现象。
它支持跨各种模态组合的交互。
使用场景
-
• 实时助手:语音交互生成文本/语音回复,适配智能客服和虚拟助手。 -
• 多模态内容创作:结合图像/视频生成语音解说,适配短视频和教育内容。 -
• 无障碍交互:为视障用户提供语音输入/输出。 -
• 学术分析:解析论文图表+语音提问,秒回分析。
写在最后
Stream-Omni 的开源不仅拓展了国内大模型多模态研究路径,也为低资源多模态对齐训练提供了新范式。
相信未来,开源国产大模型,功能及应用能力也会远超海外闭源巨头。
GitHub 项目地址:https://github.com/ictnlp/Stream-Omni

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)