作者|沐风
来源|AI先锋官
以前想要训练万亿参数的大模型,都需要用到英伟达的GPU。
现在,有可能可以跟它说Bye Bye了。
近日,华为盘古团队(包含诺亚方舟实验室、华为云等)在arxiv网站上,发布了一份在昇腾 NPU上高效训练大型稀疏混合专家模型(MoE)的技术报告。
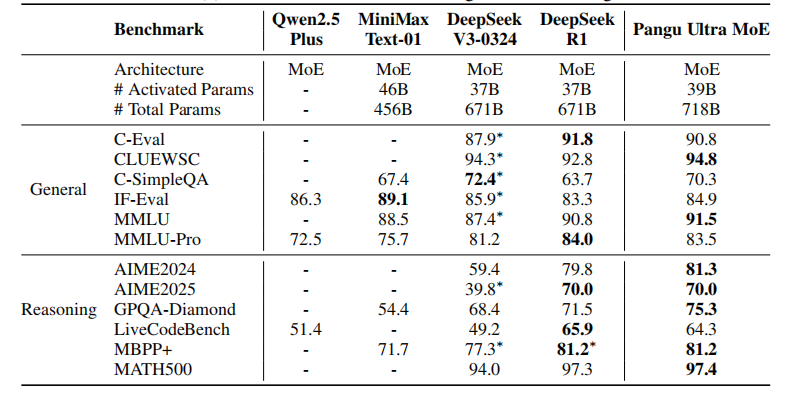
报告显示,盘古研究团队在6000+块昇腾NPU集群上,完成了7180亿(718B)参数的Pangu Ultra MoE(混合专家模型)长期稳定训练。
通过针对昇腾NPU的系统优化与模型架构设计,显著提升了训练效率,这使得Pangu Ultra MoE的最终性能表现与DeepSeek R1相当。
比如,Pangu Ultra MoE在通用理解任务中,CLUEWSC 得分94.8、MMLU得分91.5,同时还具备出色的代码与数学解题能力。
在数学推理与代码生成等高难度测试中,其AIME2024得分81.3、MBPP+得分 81.2。
不过,Pangu Ultra MoE模型并不是这份报告的主角,而是盘古研究团队如何应对训练超大参数MoE模型背后的困难。
根据这份技术报告,要想在 Ascend NPU 平台上训练盘古Ultra MoE模型,需要攻克以下四大关卡:
1、架构迷宫:需要在众多参数组合中探索最优配置,设计适配昇腾NPU的大规模MoE架构,实现计算资源的高效利用。
2、负载雪崩:路由机制需要智能分配任务,避免专家资源分配不均,如果不同计算单元忙闲不均,会因“木桶效应”降低训练效率,甚至芯片过热熔毁。
3、通信瓶颈:在近万亿参数规模下,数据在集群间传输堪比春运,token在不同计算节点间的专家流转会产生巨大通信开销。
4、硬件适配:算法与芯片像齿轮卡齿,算力潜能只能发挥10%。实现MoE算法与昇腾NPU等专用AI加速器的深度协同,需要打通算法设计、软件框架和硬件特性的全栈优化,充分释放硬件计算潜力。
为了应对这4大挑战,盘古团队提出了一系列模型架构设计和系统优化方案。
首先,团队先进行先导实验,独创了“细粒度专家+共享专家”范式。
通过增大模型里的隐藏层参数、降低激活参数量,实现“高算力低能耗”,让NPU每秒处理更多数据。
在多维并行亲和方面,采用数量为2的指数级的专家数量,达成了TP8×EP4超融合并行的方式。
在 DaVinci 架构亲和方面,将张量按照256进行对齐处理,使其能完美匹配16×16矩阵计算单元,充分释放昇腾NPU的算力。
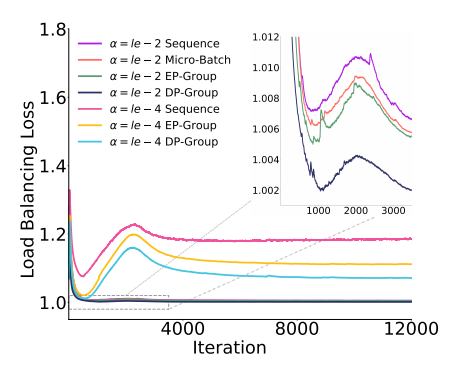
其次,为了应对负载平衡,团队研发了一种全新的EP组均衡算法,能在每微秒扫描500万token的路由请求。
该算法比传统方案相比,它不会过度强求局部任务分配的绝对均衡,避免了“矫枉过正”,同时节省了30%通信成本,在200亿参数模型上验证效果显著。
同时,团队提出了层次化All-to-All通信策略,将节点内与节点间通信分开优化,有效提升带宽利用率。再通过自适应流水线重叠技术,通信与计算操作实现高效并行,减少同步等待时间。
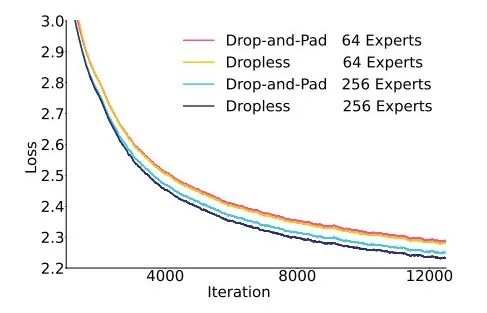
在内存管理方面,面对7180亿参数及中间激活值的巨大内存需求,团队通过细粒度重计算,仅对特定算子重新计算中间激活值,而非整个层,降低内存占用。
此外,张量交换技术将部分激活值临时卸载至主机内存,并在反向计算时预取,显著缓解NPU内存压力。
具体而言,团队从改进并行计算策略、优化数据传输效率、提升显存使用效果,以及让任务分配更均匀四个方向对盘古Ultra MoE 模型进行了全面优化。
这一套组合拳下来,Pangu Ultra MoE在6000余块昇腾NPU集群上实现了30.0%的模型算力利用率(MFU)与每秒146万token的处理速度(TPS),相较基线方案(4000块NPU,MFU 18.9%,TPS 61万)提升显著。
MFU指标反映了大模型在训练过程中硬件计算单元被有效利用的程度。
公开的数据显示,基于英伟达卡训练MoE模型,MFU 通常在 35% 到 55% 的范围内。考虑到昇腾NPU的软硬件的成熟度,MFU达到30%也已经很不错了。
随着获取国外算力越来越困难,转向国产算力来训练大模型已经成为了一个重要的发展趋势。
这一成果不仅验证了昇腾NPU在支持前沿AI模型训练中的能力,也为中国AI自主创新树立了新的标杆。
(文:AI先锋官)