跳至内容
整个5月份,全球头部AI厂商基本都相继发布了自家最新一代大模型,赶在月末,开源之王DeepSeek终于出马了。
今天,DeepSeek团队在开源社区低调发布了一款最新的R1-0528版本模型。
由于没有详细技术报告,不少开发者直接进行了上手实测,结果发现,新版DeepSeek-R1-0528在编程、推理、交互等方面提升非常显著,其性能已接近OpenAI o3 High,Claude-4-Sonnet和Gemini 2.5 Pro等一众旗舰模型。
R1-0528模型参数规模达到6850亿,需要高性能硬件才能支撑满血运行,推理耗时优化对比o3/o4-mini大幅缩短,根据部分开发者在自有硬件上运行的测试,估计该模型的成本约为每百万输出代币2.5美元,显著低于Gemini 2.5 Pro Preview的价格。
R1-0528再次精准进行了市场卡位,不仅完全开源,而且比当下最新旗舰模型更便宜,性能差距大幅缩小,这对于那些需要领先模型能力但又成本有限的团队而言颇具吸引力。
与上次更新的V3-0324模型类似,这次也是在既有模型之上进行的“小版本升级”,而且直接回到推理模型顶尖行列。
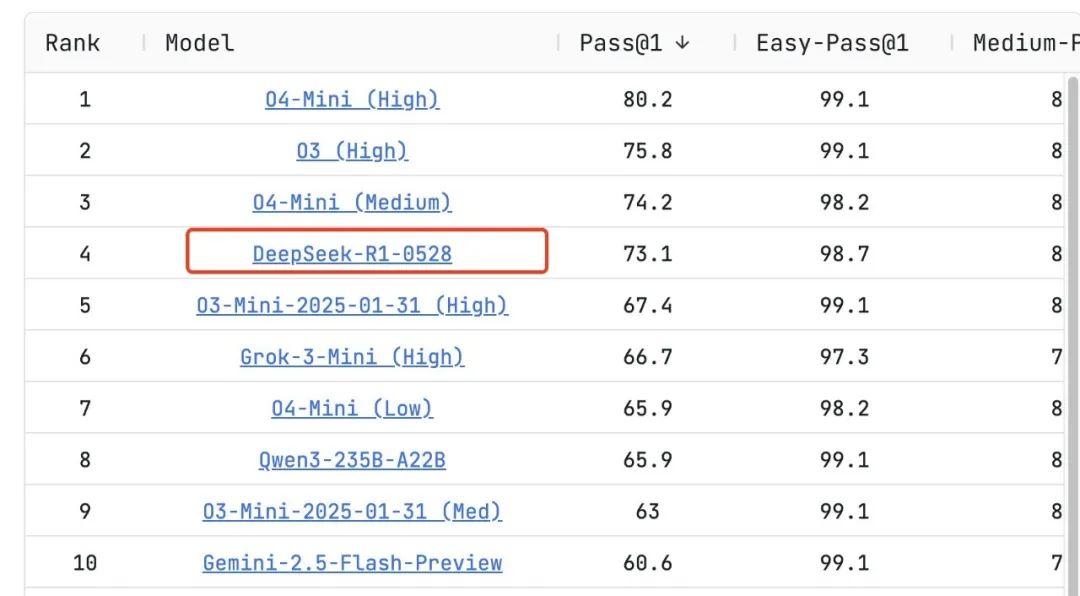
在由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发的基准LiveCodeBench榜单上,DeepSeek-R1-0528的测试得分都快赶上了o3 high,略低于o4 mini,尤其在数学、编程和复杂推理任务上表现出色,优于xAI的Grok 3 mini和阿里巴巴的Qwen 3,实现了当前开源模型的最佳性能水平。
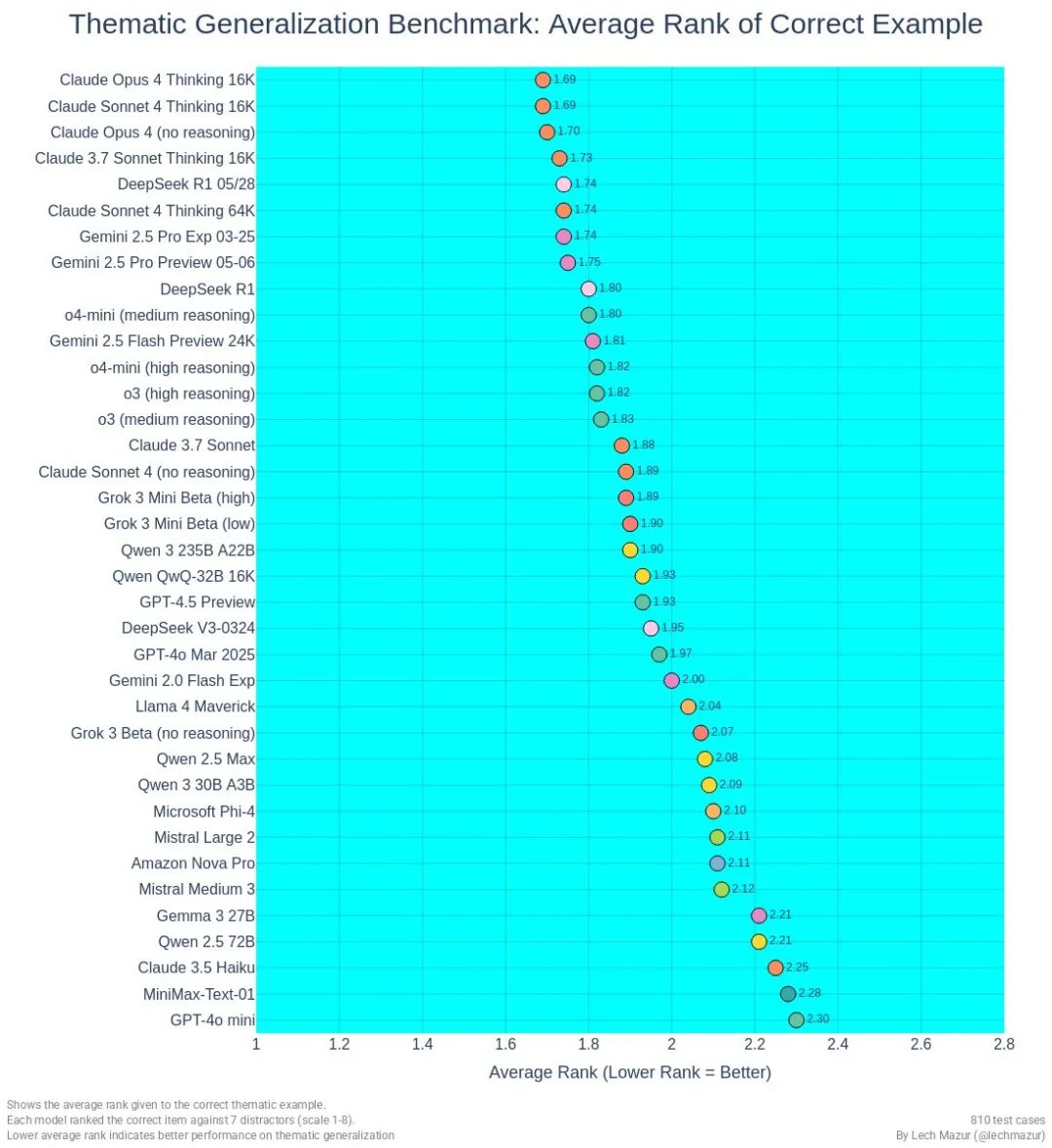
此外,R1-0528在Thematic Generalization Benchmark(主题概括)基准上也比上代R1有所改进,该基准测试衡量各种LLM如何有效地从少量的例题和反例中推断出一个狭窄或特定的“主题”(类别/规则),然后在一系列误导性候选题中检测出哪个项目真正符合该主题。
该基准测试整个过程包括生成主题、创建例题和反例、通过“双重检查”步骤过滤掉低质量数据,最后促使法学硕士 (LLM) 在多个干扰项中对真实的例子进行评分,值越小表示性能越好,R1-0528的表现与Claude-4-Sonnet Thinking 64K和Gemini 2.5 Pro媲美。
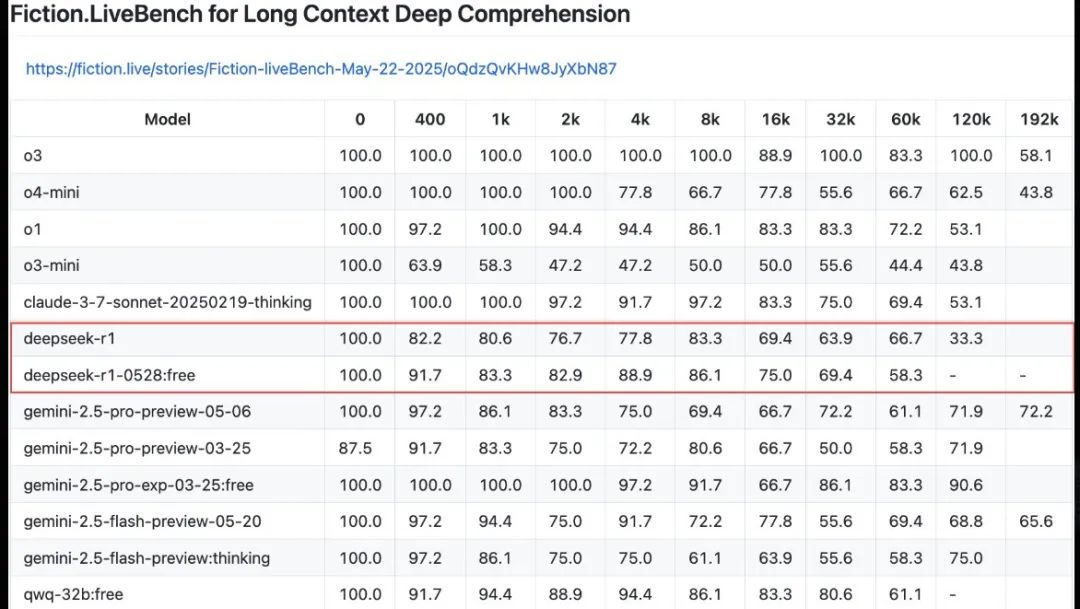
新模型升级支持128K超大上下文窗口也是一个亮点,这为处理复杂任务提供了更广阔的空间,相比前代,R1-0528在32K上下文窗口的文本回忆测试中表现出色,准确率显著提升,尤其适用于需要深度理解和精准回答的场景。不过有开发者测试发现,在60K上下文级别测试中性能略有下降,120K测试的结果尚未有公布。
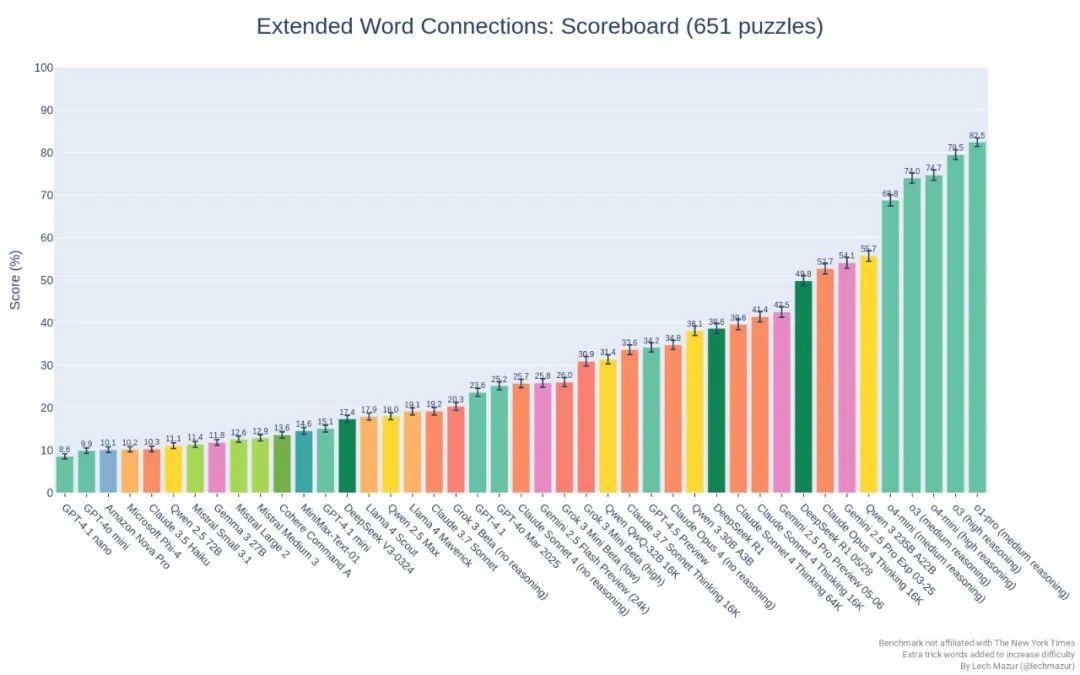
在Extended NYT Connections基准测试中,新版本比原始DeepSeek R1有了显著改进,从38.6分提升到了49.8分,该基准使用651个NYT Connections谜题来评估大型语言模型智能性。
评估者还指出,它在情感共鸣和文学复杂性方面的表现与谷歌旗舰模型Gemini 2.5 Pro非常接近。
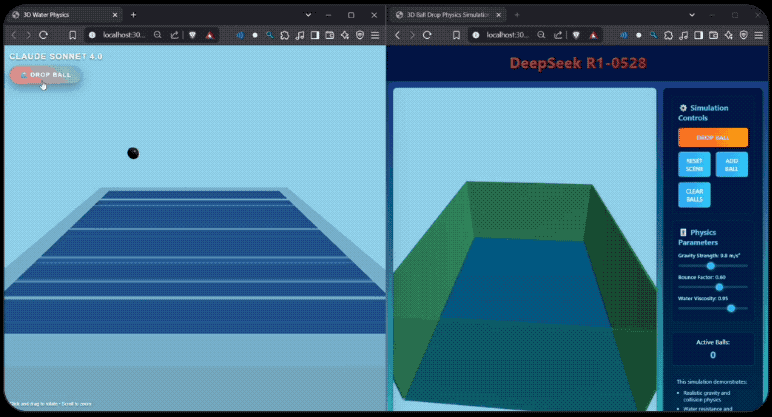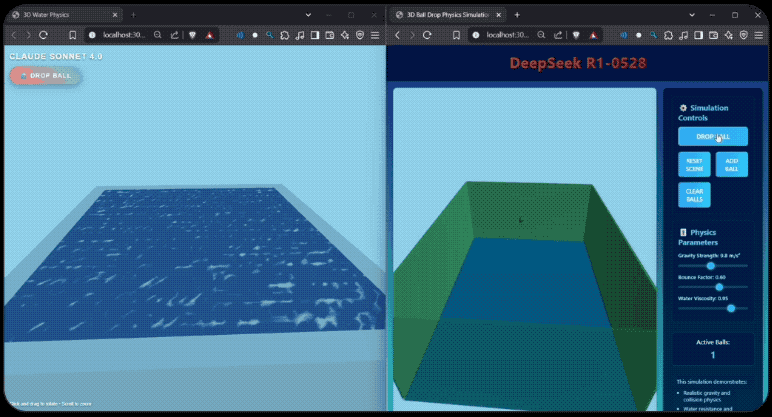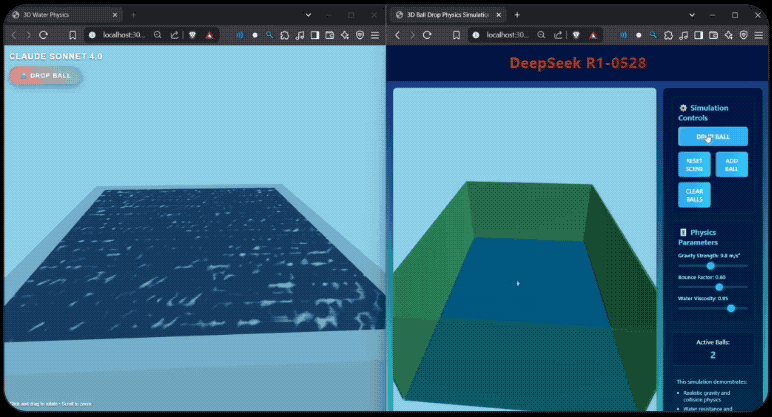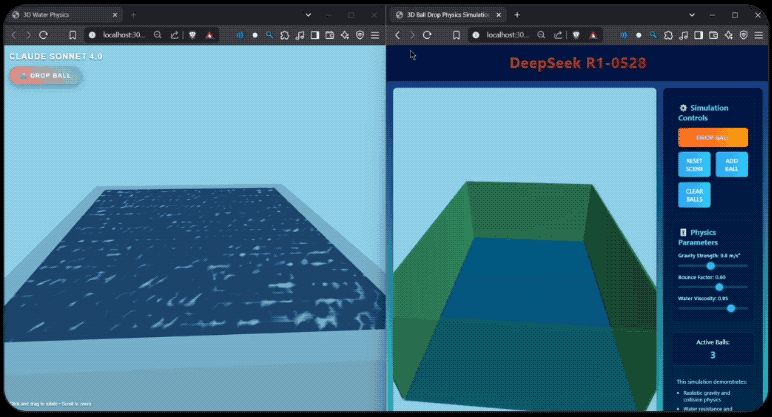
R1-0528的编码能力如何?有开发者用DeepSeek-R1-0528与Claude-4-Sonnet进行了编码测试的对比,同样提示之下,Claude-4-sonnet生成了542行代码, DeepSeek-R1-0528则生成了728行,无论是球体的漫反射控制, 还是控制面板的美观程度,R1-0528生成的效果都丝毫不弱。
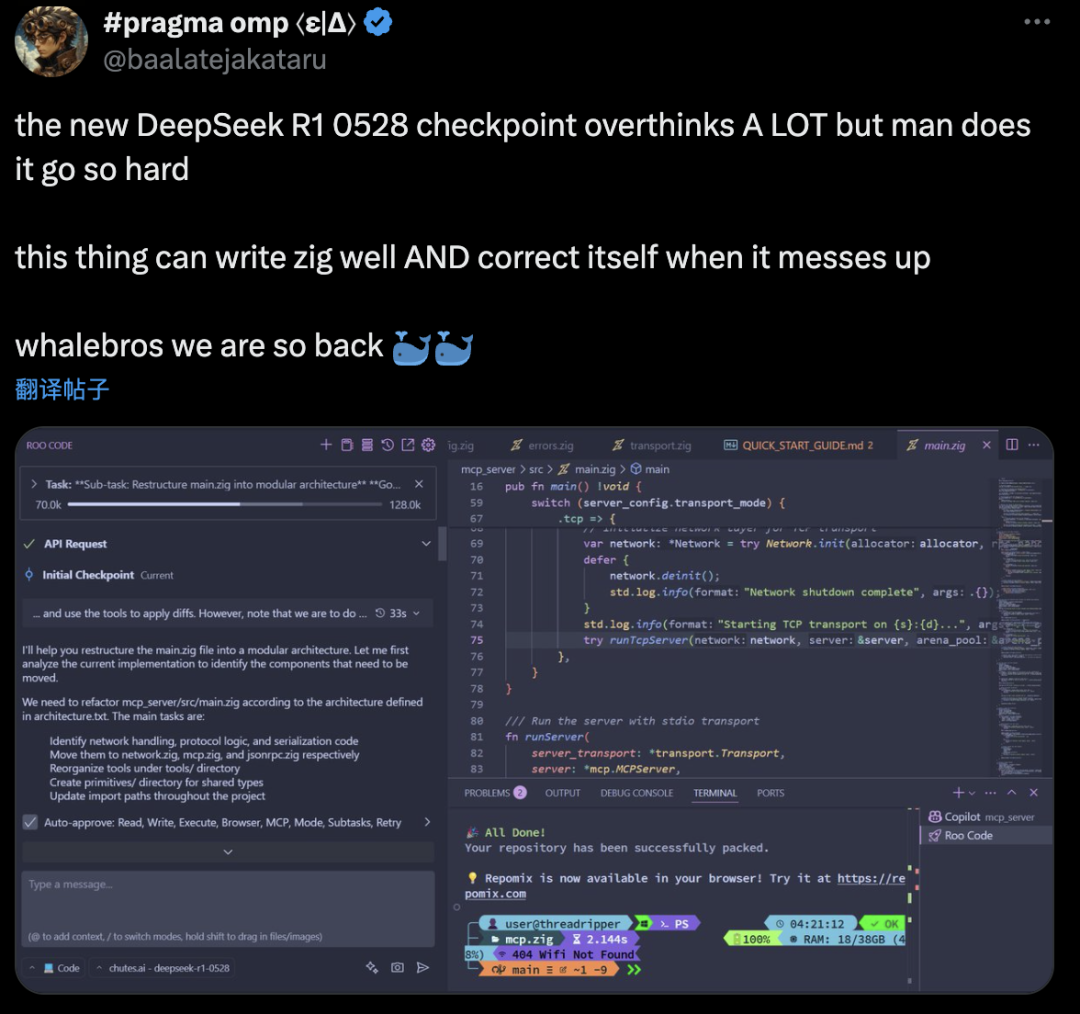
也有开发者测试后表示,R1-0528编码时检查点虽然思考过程显得有点繁复,但效果简直太惊艳了,可以很好地完成Zig编程需求,而且写错的时候还能自己纠正。
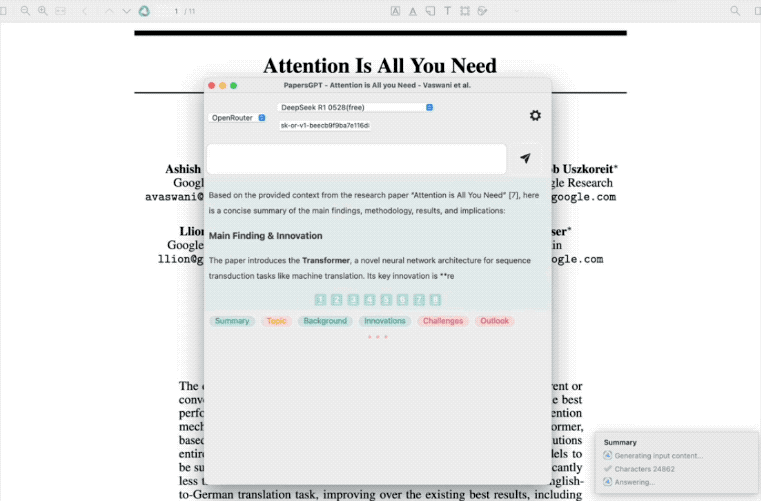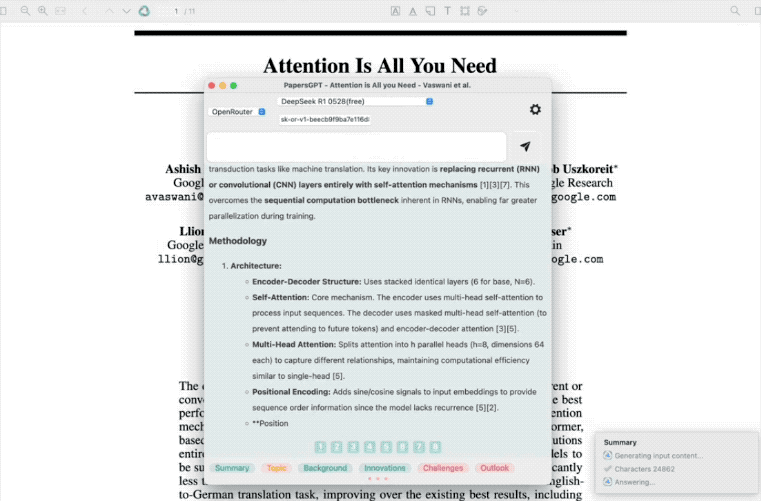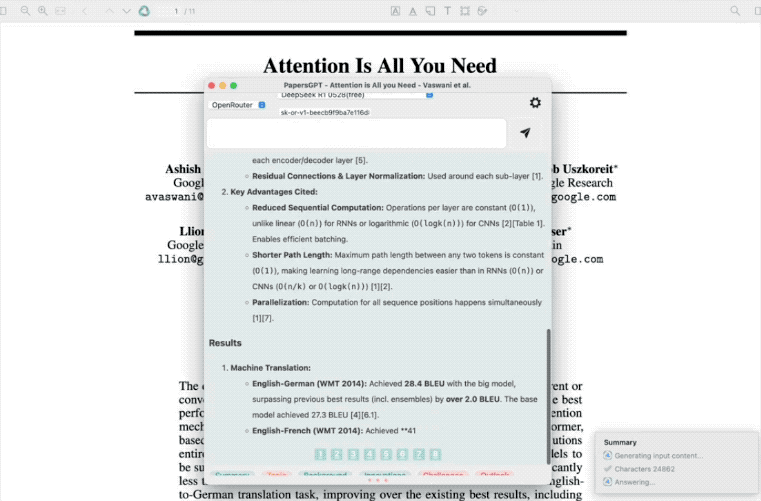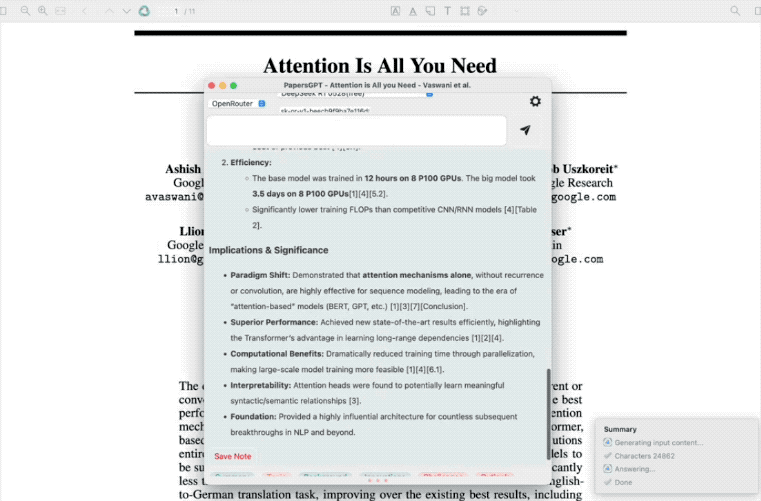
R1-0528可以深度理解概括一篇论文的很多细节,答案也比较有逻辑性,全面且完整,有开发者在插件PapersGPT中接入R1-0528进行了测试,其分析过程和输出的速度相比上代模型进步很大。
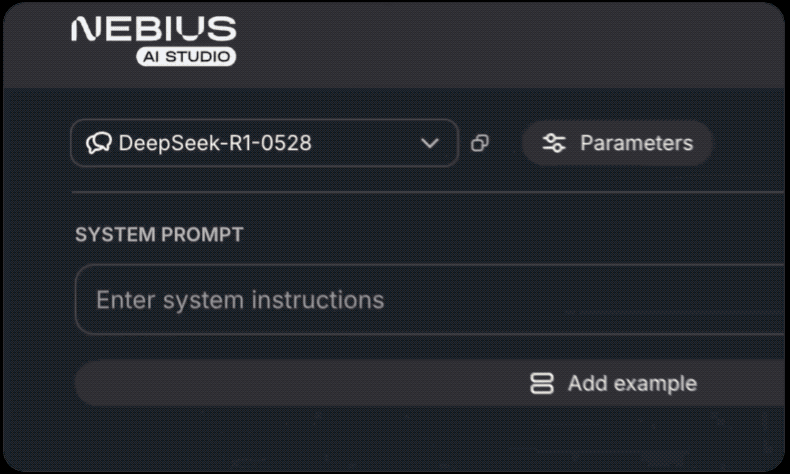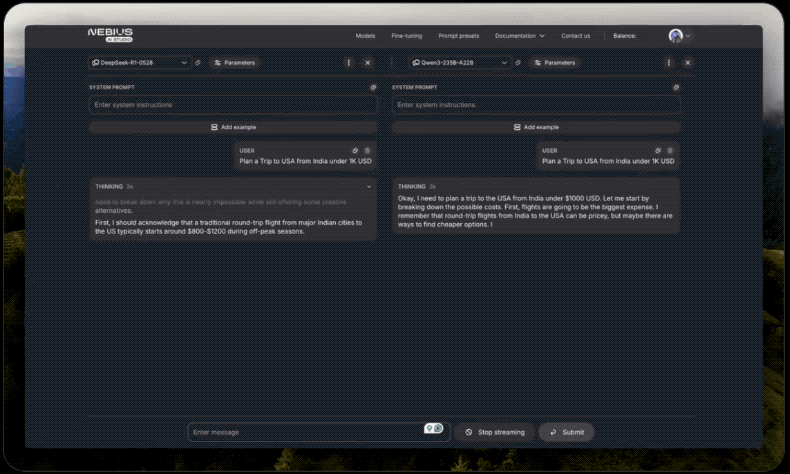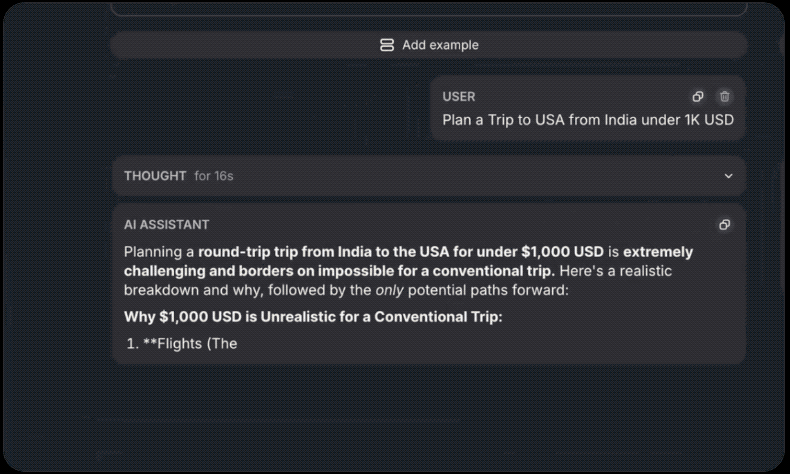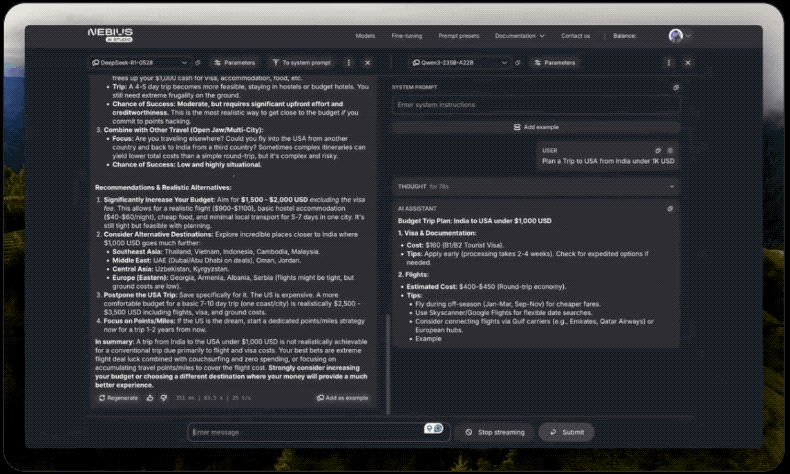
有网友使用相同提示测试了DeepSeek-R1-0528和阿里的领先开源模型Qwen3-235B-A22B:“为我计划一次从印度到美国的旅行,花费1000美元。”有趣的是R1-0528思维过程相比之下要冗长许多,但最终结果输出速度大约快了5倍(16秒vs78秒)。
在个别编码测试中,R1-0528的实际表现还要优于Claude Sonnet 4版本。
开发者普遍认为,虽然是小版本更新,但R1-0528改进幅度超出预期,实用性提升巨大,重回主流模型第一梯队水准,继续卡住开源之王身位,完全可以作为Gemini 2.5 Pro、Claude 4、O3的国产性价比平替,让成本效益进一步提升。
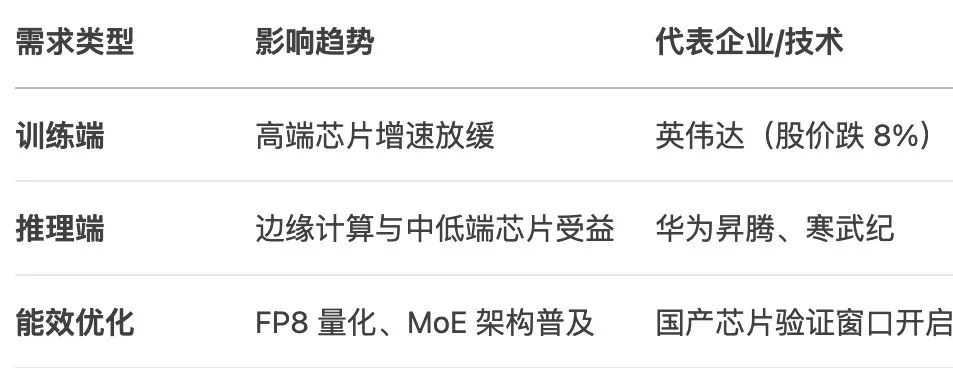
有意思的是,Deepseek每次新模型发布,AI算力巨头英伟达的市值都要受到小小的波动,因为该团队展示了无需大量超昂贵的GPU集群即可训练出SOTA水准大模型,真正开发了有效的性能提升方法。
以Deepseek为代表的中国开源大模型全球影响力崛起也正在重构中国算力市场格局,据悉,为了挽救快速流失的中国市场份额,NVIDIA计划销售代号为“B20”的精简版AI GPU,而AMD则希望通过其新款Radeon AI PRO R9700工作站GPU来满足AI工作负载,两家公司可能会从7月开始在中国销售新的AI芯片。
此外,R1-0528的推出也将进一步挤压OpenAI、Anthropic、谷歌等在高阶AI编程场景的溢价空间,技术开源+ 能力顶尖化+ 成本重构进一步倒逼闭源厂商们进行战略调整。
作为5月份大模型集中上新的收官之作,R1-0528的推出一举抬高了下半年大模型竞争的最低水准,这让业界开发者对其R2模型的期待值更高了。
-END-
(文:头部科技)