



智能眼镜,要么不够智能,要么不像眼镜,如何破局?
作者|王博
2007年,乔布斯发布初代iPhone,正在美国芝加哥出差的茹忆第一次体验iPhone。
当时茹忆在摩托罗拉北京研发中心工作,iPhone丝滑的iOS系统让他十分震撼,“它的硬件不一定比我们好,但系统做得太好了。”
后来,茹忆做了摩托罗拉智能手机、小米电视、天猫精灵等智能硬件产品,他始终坚信硬件背后软件系统的重要性。在此期间,一件事情对他产生了很大的影响——AlphaGo战胜李世石,当时茹忆就对AI产生了一种直觉——“AI一定是未来”,这也是他当时加入阿里巴巴做天猫精灵的原因。
2021年,茹忆选择创业,创办了一家智能眼镜公司——李未可(Lawaken)。

李未可科技创始人兼CEO茹忆
智能眼镜是一个承载着AI应用落地愿景的行业,也是一个充斥着谎言和暴论的行业。
过去几年间,不少公司蜂拥而至,以各种新颖的概念堆砌产品,用夸张的宣传制造泡沫。然而,真正能够落地,让用户愿意长时间佩戴的智能眼镜产品寥寥无几。
问题的根源在于:智能眼镜,要么不够智能,要么不像眼镜。
不够智能,公司就只能去卷硬件,陷入价格战;不像眼镜,产品就难以让用户长时间佩戴,使用场景会受限。
李未可科技创始人兼CEO茹忆对这两个问题的看法很明确:“AI眼镜,AI在前硬件在后,AI技术必须成为用户需求的第一响应者,而非硬件的附属品。”“智能眼镜的重量越低越好,40克是一个门槛。智能眼镜不能让用户‘哇’一下就放起来,我们要做用户可以戴一整天的智能硬件设备。”
5月25日,李未可推出了三款AI智能眼镜,这些眼镜都搭载了李未可自研的“WAKE-AI 2.0任务式交流系统”“零级智能体ZeroAgent”,而从续航、重量、外观等角度来说可以让用户佩戴一整天,并可满足用户翻译、录音、拍照等需求。
因为李未可此前曾做过专注骑行场景的AR眼镜产品,这次的三款新产品少了AR(增强现实),加强了AI,让不少人觉得有些意外,但重视硬件产品背后的软件系统,近二十年来,茹忆都没有变过。
「甲子光年」发现,李未可正在构建一套软硬件闭环的体系,这套体系以智能眼镜为载体,背后支撑的是一个“多模态大模型+多Agent”的AI系统。
而这套AI系统研发成本要几千万元,对一家智能眼镜创业公司来说,这并不是一笔小的开销。
这也引发了一个疑问:一家智能眼镜公司,为什么非要自研AI大模型系统?
1.为什么不能只做终端硬件

每一个进入智能眼镜市场的公司,都要面对两个对手:飞秒刀和华强北。
飞秒激光近视手术正在蚕食眼镜的市场。根据观研报告网发布的《中国屈光手术行业发展趋势分析与未来投资预测报告(2023-2030年)》,中国屈光手术渗透率不断提升,2021年为0.29%,预计2025年将达到0.64%,2030年将上升至1.19%。近年来,飞秒激光近视手术在技术成熟、效果提升的同时,价格保持相对稳定。
随着更多人拥有“摘镜自由”,智能眼镜公司必须用远超“矫正视力”的价值,才能让消费者仍有理由在鼻梁上留一副电子设备。
而华强北正在快速压低智能眼镜的价格。这里是全球消费电子产品的“晴雨表”,任何被市场验证有潜力的产品,都可能在极短时间内被“华强北模式”消化、拆解,并以更低廉的价格迅速推向市场。这里的电子市场已经出现售价90~200元的“中国版Ray-Ban Meta”快装套件,再贴上“AI眼镜”标签即可出货;一些原本卖蓝牙耳机的档口,现在也转型卖智能眼镜了。
在这种“抄作业”速度面前,单纯拼硬件的品牌注定沦为价格表上的一行数字。
在飞秒刀与华强北之间,智能眼镜公司真正要回答的,不是能否做出一款智能眼镜,而是能否交付一套让用户愿意日复一日佩戴并且难以被复制的AI体验闭环。
对于李未可们来说,这才是通往规模化的唯一通道。

观众体验李未可智能眼镜
“我们最擅长做的事情是‘AI+硬件’,而不是跟别人拼硬件。”茹忆坦言,虽然在创办李未可的时候自己就相信AI,但是在2023年到2024年,自己做了“很艰难的选择”,放弃了单光机双目AR的方案,原因是“不够AI”,并将更多精力投入到智能眼镜专属的AI大模型的研发中,目标用户也更聚焦在了商旅群体。
2024年4月,李未可推出了针对AI+终端定向优化研发的多模态AI大模型平台WAKE-AI 1.0。WAKE-AI 1.0具备文本生成、语言理解、图像识别及视频生成等多模态交互能力,并针对眼镜端用户的使用方式、场景等进行了优化。
而这次,李未可发布了WAKE-AI 2.0任务式交流系统,其定位是针对AI眼镜的多模态大模型及Agent架构。这不仅仅是一个多模态大模型,而是一个围绕AI Agent生态闭环设计的系统,并为未来多终端协同预留了空间。
2.为什么不能只接入通用大模型API
智能眼镜实现“智能”主要有三种方式:接入通用大模型API、合作研发大模型、自研大模型,部署方式则有:云侧、端侧、端云结合。
接入通用大模型API最简单,李未可科技合伙人兼AI负责人古鉴告诉「甲子光年」,李未可最初也尝试过这种方案,但是团队发现了一个问题,接入通用大模型API无法很好地完成“用户意图识别”。

李未可科技合伙人兼AI负责人古鉴
举个例子,通用大模型API对“今天天气怎么样”“帮我导航到西湖”“帮我记一下会议要点”这类常见指令的识别不错,但对“我吃完饭想去西湖转转”这类指令,到底是识别成导航需求还是聊天需求呢?更不要说,“根据当下视野中的路况提示最佳骑行路线”或“基于镜头捕捉的迎面人脸自动调出客户资料”这种场景化、跨模态的意图,通用大模型API容易出现误解或漏识。
通用大模型API虽然强大,但对于智能眼镜特有的交互模式、特定领域知识以及设备状态感知的理解和整合能力可能不足,需要额外的开发。而随着使用量的增加,API调用费用也会成为一笔持续且不小的开销。用户数据隐私和延迟也是智能眼镜公司需要考虑的问题。
李未可选择的方式是,基于开源大模型微调AI智能眼镜的专用大模型,并且在行业内率先通过国家网信办的大模型算法备案,确保合规。
在大模型训练阶段,微调是利用特定任务的有标签数据集对预训练模型进行进一步训练,使其更好地适应某个具体任务或领域。
“我们准备了很多符合智能眼镜使用场景的数据,花了很多时间去做数据精标,然后不断去修正。”古鉴告诉「甲子光年」,“用户意图识别和分发对智能眼镜十分重要,也是我们的着力点。”
在去年发布的WAKE-AI 1.0中,李未可以自研的分发决策大模型为核心,形成了一套AI多模型架构。
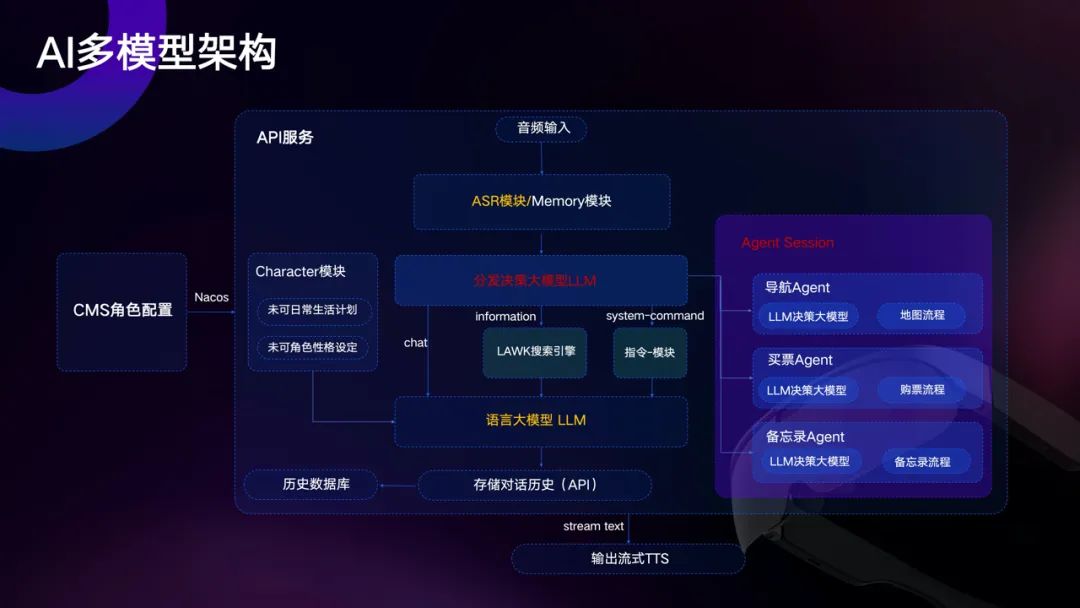
WAKE-AI 1.0架构图
过去的一年,李未可做了很多用户调研。在软件、功能方面,用户最关心实时翻译和AI功能集成,而在使用场景上,用户更倾向于在旅行和工作场景使用智能眼镜。
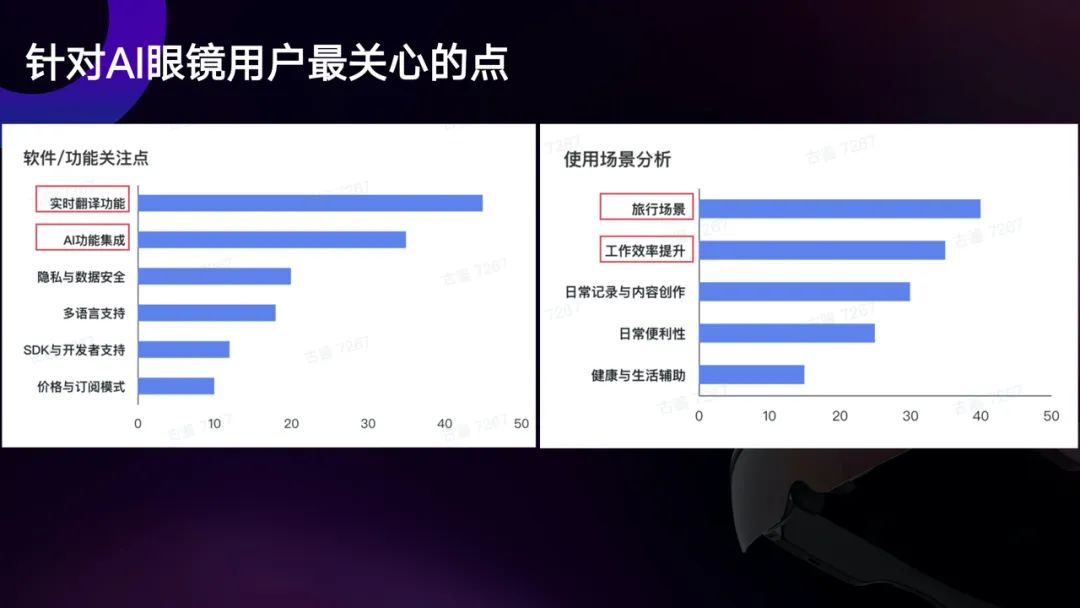
用户调研数据
结合用户调研数据和使用场景,WAKE-AI 2.0主要在三个方面进行了升级:大模型ASR(自动语音识别)、多模态交互、多智能体交互。
具体来说就是,从“传统ASR”升级为“大模型ASR”,从“语言大模型”升级为“多模态大模型”,从“分发决策大模型+智能体”升级为“思维链分发大模型+零级智能体ZeroAgent+内外部多智能体协作”。

针对场景进行升级
ASR是整个语音交互链条的第一步,其准确率决定了后续AI理解与响应的效果,尤其是在翻译场景中。
前段时间,在越南胡志明市举办的CHINA HOMELIFE越南展上,李未可科技为展会主办方米奥兰特特别定制的AI智能翻译眼镜,以支持超过180种语言的实时翻译,及会谈内容自动生成纪要等AI功能引起了众多参展商的关注。

李未可智能眼镜在越南展会受关注
李未可采用了两种方案来优化ASR。
针对中文和英文,李未可采用大模型ASR技术,音频经过encoder+adapter编码和适配为token,结合用户语境和上下文消息等文本模态数据共同作为大模型输入,优化通用领域的语音识别率,尤其是在多音字、相似音、人物地点名称等有显著效果提升。
针对小语种识别,李未可通过whisper-encoder+ LLM进行ASR训练,使用自回归方案训练。李未可和合作伙伴采集约3000小时的专业小语种数据,并且经过人工精心标注,配合通用领域的大规模语音数据,进行定制训练,以提升外贸翻译场景的语音识别体验。
目前,李未可的大模型ASR字错率在通用和专业测试集测评上已全面优于基线模型0.1~0.7个百分点。

李未可智能眼镜
在文旅场景中,相比传统语言大模型,多模态大模型能适应更丰富的实际应用场景,极大提升人机交互的智能化和自然度。这也对智能眼镜的多模态数据处理能力提出了更高的要求:能同时理解和融合文本、图像、音频、视频、地理等多种信息,满足复杂场景需求。
李未可基于开源多模态大模型,进行了微调。不要小看这样的微调,团队进行了大量的图像数据采集及清洗工作,自采100多个展馆,4700多个点位,并结合公开的海内外博物馆数据,构建博物馆类目数据。另外,为对齐图像-文本向量空间,李未可专门构建训练文本。训练文本包含讲解内容、展品的年代及属性标签等文本信息。基于结构化数据及语言类大模型增广,形成超过50K的指令数据集。
最后就是多智能体的交互。
多智能体交互的前提还是精准的用户意图识别,WAKE-AI 2.0在分发决策大模型的基础上引入了思维链,升级为思维链分发大模型。
“去年我们就发现,分发决策大模型如果要进一步提升准确度,必须要通过思维链的方式来判断很多任务到底能不能够执行,所以DeepSeek-R1开源对我们来说非常利好。”古鉴告诉「甲子光年」。
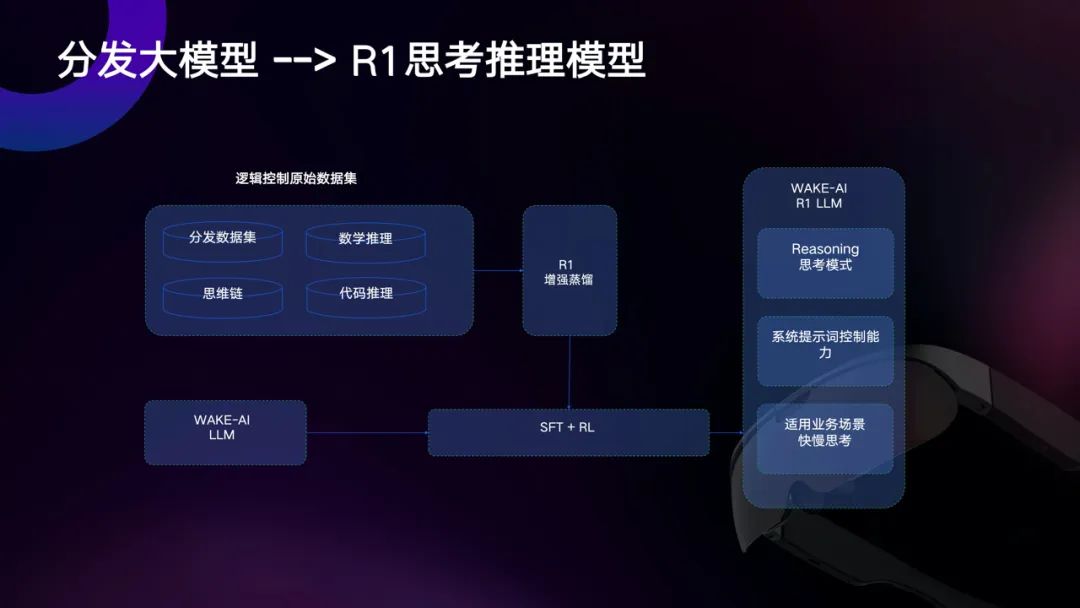
思维链分发大模型
在这个前提下,李未可提出了“零级智能体ZeroAgent”概念。“我们认为一个具备理解用户意图,并进行分发、执行和反馈的AI智能体才是关键,所以我们提出了一个概念,叫‘零级智能体ZeroAgent’。”茹忆说。
之所以叫“零级”,意味着它是所有Agent中最先接触用户、响应用户的那一级,相当于“AI交互的门卫”。
用户输入的文字、语音、图像等信息首先会由Zero Agent解析意图,判断是“一般对话”还是导航、购票、备忘录这样的“特定任务”。
当请求超出其轻量化能力或需要调用专业流程时,Zero Agent会触发MCP(模型上下文协议)与A2A(Agent-to-Agent)机制,将任务路由给对应的内部或外部Agent。
Zero Agent还负责管理短期对话上下文,保证在多Agent协作时,前后语义连贯,不丢失关键信息。

智能体交互
「甲子光年」认为,随着智能体(AIAgent)成为新交互范式,AI终端不再是“遥控器”,而是“Agent容器”。以WAKE-AI 2.0为例,其系统架构已经支持:多Agent调度执行、私有知识嵌入Agent逻辑、Agent商店/平台等。
这意味着,硬件本身正在成为软件生态的承载体。不掌握系统平台,就无法定义生态。
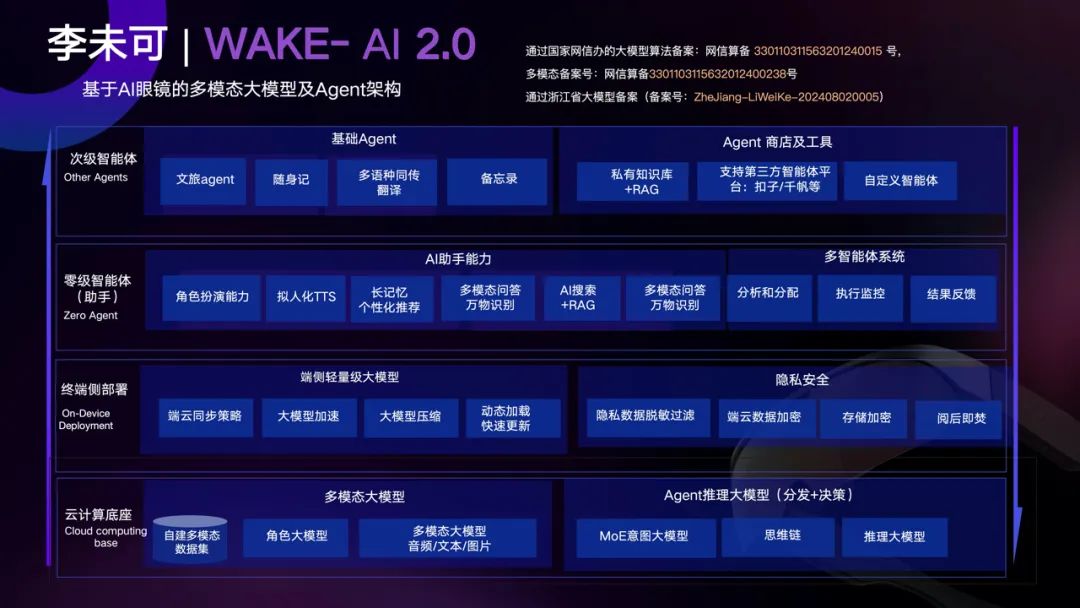
WAKE-AI 2.0架构
智能眼镜的核心价值在于“持续、高效、自然”的人机交互,而决定用户体验“爽不爽”的是:多模态识别精度(图像、语音、文字理解)、语义推理能力(长记忆、上下文理解)、Agent调度能力(能不能真正“干活”)。
这些核心体验,无法单纯靠接入通用大模型API实现,必须进行深度定制和系统级协同。
3.为什么不是大厂来做AI系统平台
对于很多中小公司来说,经常会被问到的问题是:“相比大厂,你们有什么壁垒?”
金沙江创投主管合伙人朱啸虎曾告诉「甲子光年」:“在中国,聪明人太多了,我从来不相信在中国有技术壁垒,我只相信客户壁垒、数据壁垒。”
而在智能眼镜领域,可以理解为平台壁垒高于终端壁垒。那么,谁更有动力也更没有退路去打造真正意义上的AI系统平台?
大厂依靠算力租赁和API分发,不愿冒险走端上之路;大模型公司虽有技术和产品,但缺交互闭环、终端入口以及用户数据;而智能眼镜公司,为了生存,为了体验,为了差异化,只能卷“全栈”。
而从另一个角度来说,相比大厂的某个事业部,李未可在AI智能眼镜细分赛道上可以更加专注。
这种专注体现在解决实际问题上。比如,多智能体协作任务对模型的能力要求非常强,由于多轮自主迭代,模型的token消耗量也很大,如何解决?
古鉴告诉「甲子光年」:“我们通过设计的多智能体框架,在线上实际运行已经收集很多真实agentic数据,去增强大模型的agentic能力,然后设计更加自由灵活的架构,支持让大模型自主决策、工作流配合的方式,这就可以明显减少模型的token消耗。”
通过过往和不断更新的用户数据来迭代AI系统平台,的确可以逐渐构筑壁垒。
这就是为什么,李未可必须做自己的AI系统平台,它不仅仅可以李未可的智能眼镜服务,也可以成为其他可穿戴智能终端的入口。
“AI是大时代,我们希望贡献自己的力量,去共同促进AI赋能硬件赋能生态,共同推进AI普惠,因此我们正在积极和伙伴合作,把我们的AI能力开放给各厂商,而且现在已经有了很多实质性进展和合作了。”古鉴说。
2025年,AI大模型领域的竞争,正在从“谁的模型大”转向“谁的系统强”。
过去的焦点主要放在“参数量、训练数据规模、架构新颖性”上,现在的竞争,不再局限于“单体模型能力”,而是看谁能把AI大模型落地体系打通,到底谁的“系统”更可靠、反应更快、体验更流畅。
“我们尝试用Agent解决我们日常生活中所有的问题,在未来的三个月,我们会推出真正的群体智能,让Agent会调用多个Agent。ZeroAgent其实是一种全新的交互方式,也是一个新的交互入口。”茹忆说。
「甲子光年」认为,谁能率先构建可控、可部署、可落地的系统级AI能力,谁就能在可穿戴终端中之战中拔得头筹。
这套WAKE-AI系统或许不是“最通用”的,但它是国内为数不多以终端为场景、以智能体为中枢、以多模态为核心的真正落地的AI系统。
构建真正的壁垒不能靠别人,只能靠自己。
(封面图及文中配图来源:李未可)
(文:甲子光年)