


新智元报道
新智元报道
【新智元导读】在字节当技术人,是怎样一种体验?有探索时的迷茫、挣扎甚至是自我怀疑,也有收获成果后的兴奋与成就感。在这里,他们不断追求前沿,想为「世界折腾点东西出来」。
最近,字节跳动启动了新一年的筋斗云人才计划,共涵盖大模型应用、搜索/推荐/广告、计算机体系结构与系统优化、安全/AI Safety、硬件、AI Coding、视频架构、AIGC等八大领域中的42个技术课题。
其实,在筋斗云计划发起之前,就有一批优秀的字节同学在这些课题中,追逐技术创新的「务实和浪漫」。
在他们之中,有的人想做那个「造锤子」的人,在探索中寻求长期价值,还有的人立志「把论文写在大地上」,用技术为用户带来更丰富、更有价值的体验……
但就像冲突是一个故事不可或缺的因素,他们也曾有过迷茫和挣扎:我是不是最开始就错了?做不成怎么办?要不然就算了……将这样的念头逐个掐灭,走过迷茫和挣扎,他们想要「为世界折腾点东西出来」。
这次,我们邀请到了三位筋斗云课题里的「技术博士」,以下是他们的故事:


2023年7月,从中国科学院博士毕业后,我放弃了几家知名企业的头部人才计划Offer,加入了字节一个在当时相对较小的产品——汽水音乐。
在求职的当口,我最关注自己将来做的事是不是够长期?是不是够创新?敲钉子的事谁都能干,我想做那个造锤子的人。
字节满足了我的期待。我了解到汽水音乐内部也有很多长期课题,这对于一个以应用为主的团队来说非常难得。面试时Leader的一句话也很打动我,「你来了之后,不给你设方向限制。」
入职后我接手的第一个课题就非常长期和有独创性——兴趣时钟。
如何建模时间关联的用户偏好是推荐系统中的一个经典问题。过去行业普遍直接对时间进行小时编码(hour embedding),再让模型自己学习时间与用户偏好的关系。这种方法在传统天级训练的推荐系统中效果不错,但并不适用现在的流式推荐系统:同一时刻所有样本的小时编码相同,会导致模型无法学习其他的小时编码,从而出现过拟合现象。
兴趣时钟的逻辑是直接对某一时间用户的兴趣偏好建模,本质上是让时间成为兴趣的「触发器」,在当前时间使用合适的用户兴趣偏好去预估,将最合适的、用户最喜欢的内容推荐给他们。
听起来,逻辑的转变似乎很简单。但我认为衡量一个技术成功与否的标准从来都不是够不够复杂,一剑封喉,越简单的技术越有效,也更容易被行业广泛使用,从而为更多用户提供更好的体验。
兴趣时钟在汽水音乐上线后,将用户的活跃天数提升了0.509%。后来,我们的论文被顶会SIGIR2024 Industry Track录用,评委们也给出了积极的认可。

互联网是一个0和1构成的世界,技术也是如此,在拿到最终结果之前,无论过程有多长,我们会一直停留在「0」这个阶段。
我印象很深刻,刚开始做兴趣时钟时,大家都很期待。但两三个月后迟迟拿不到效果,也就没人再问了。有那么一段时间,我经常胡思乱想,「这么久都不出来,Leader和其他同学会不会对我有意见?」
之所以这么难,还是因为这是一件从0到1的事,没什么前人的经验可以借鉴,所有事情都要重来,也踩过不少坑。举个很小的例子,模型代码取的是AOE时间,但存储系统取的是UTC8时间。因为时间标准不同,导致最后的收益不及预期。
兴趣时钟的研发过程并没有什么动人心魄的故事,无非就是遇到一个又一个小问题,一次又一次解决它们,直到最后走向成果落地。
2024年,我开始负责汽水音乐的推荐技术。在此期间,我也像曾经的Leader一样,提供一些思路上的指引,让同学们去搞一些长期课题。比如我们去年把兴趣时钟升级成了长期兴趣时钟,提出了不对称扩散模型等。
也是在管理团队后,我突然发现自己当年想多了。有时候不问进展,并不代表不关心,而是不想给同学们太多压力。我相信同学们,也深刻知道,这本来就是一件需要长期投入的事。

在清华读博时,导师经常鼓励我们要重视技术的实践落地。这点对我影响很大,2020年4月到字节实习后,更加深了我的理解。
博士期间我的研究方向就是数据库和AI。写论文时,我们通常会设置一个理想环境,并在理想条件下拿结果。但真实的工业环境更加复杂,工作不只停留在纸面上,而是要落到具体实践中——当你做的东西解决了实际问题、产生了真正价值,论文和专利这些是水到渠成的事。
从2021年到今天,我职业生涯的第一次实习和第一份工作都在字节跳动的ByteBrain团队。这四年中,激励我一步步走过来的,正是一个又一个可触碰的问题,以及解决问题后带来的满足感。
我在字节ByteBrain团队的工作和博士期间的研究方向一脉相承,刚开始做AI for Infra,也就是用AI技术优化数据库等基础设施,在节省成本的同时提升性能。随着大模型的发展,我的工作也拓展到了Infra for AI领域,本质上是为AI大模型的开发和落地提供基础设施支持,从而加速开发流程、降低落地门槛。
正式入职后不久,ABase(字节跳动规模最大的首个自研NoSQL数据库产品)团队找到我们,提出要做数据库的扩缩容,在用户用量出现持续上涨和下跌时及时预警。对于算法侧来说,常见的思路是在云引擎上线一个算法预测服务,其他需求部门来调用算法API就好。但我们并没有局限于此,而是从0到1把整套链路搭建了起来,涵盖了数据采集、算法预测、扩缩容建议、消息预警、大盘展示等全流程。
说实话,这一定程度上超出了一个算法工程师的工作范畴。但我一直坚信要有长期视角,只要当下舍得沉下心来投入,就一定会收获更多成果。
最后,功能上线后的结果也很不错,在扩容上帮助ABase将紧急扩容工单的数量降低了60%左右,并在缩容上节省了3亿左右的成本。后来,我们与ABase团队在更多场景下展开了更深入的合作,双方共创的论文也被今年的 SIGMOD 25(数据库领域顶级会议)收录。
 |
 |
类似的故事几乎每天都在我的工作中发生。还记得最开始做「MySQL 虚拟索引 VIDEX 开源项目」时,我们的想法很简单,只是觉得它对公司业务有用、对行业有用,值得开源,并没想到最后会产生还不错的影响力。
索引推荐是数据库领域的一个经典问题,如果没有索引工具,仅依靠DBA(数据库管理员)的经验来优化索引会非常耗时耗力。随着数据量级越来越大,在数据库中插入一个真实索引的成本非常高,同时会带来客户隐私数据泄露的风险。虚拟索引便应运而生,它可以实现虚拟环境中实现索引查询,让用户可以按需调用。
MySQL虽然是当前业内最主流的开源数据库,但一直没有成熟的虚拟索引工具。像Meta等公司都提到自己用了类似技术,但没有开源,没人知道他们是怎么做的。
当我们自己上手时,却发现就像打地鼠游戏那样,很多未曾预料的问题总会层出不穷的冒出来,导致索引结果的准确率不高。怎么办?只能埋头去啃代码,下了很多「笨功夫」。
比如结果不准时,我们会对比真实索引和虚拟索引的不同,并深入到代码层寻找卡点。可能就是那么一两个环境变量,但解决了它们,也就将很多环节的卡点都解决了。诸如此类的情况发生了几十上百次,每一次我们都要去几百万行的系统代码中定位到具体的某一行。
在那段时间,很多问题都面临着挑战。应该说,痛并快乐着吧,我喜欢这种「长期专注一件事」的感觉。
VIDEX项目做成后,我们在公开测试集上的加速效果达到了理论基准(Ground Truth)下的90%以上,并且已经在公司大规模上线,每天处理上千个RDS和MySQL的慢SQL优化任务。目前,ByteBrain-VIDEX已经被数据库顶级会议VLDB 2025 Demo Track接收。我们将VIDEX开源后,也引发了行业的关注与认可,并吸引了众多海内外研究者的讨论与贡献。
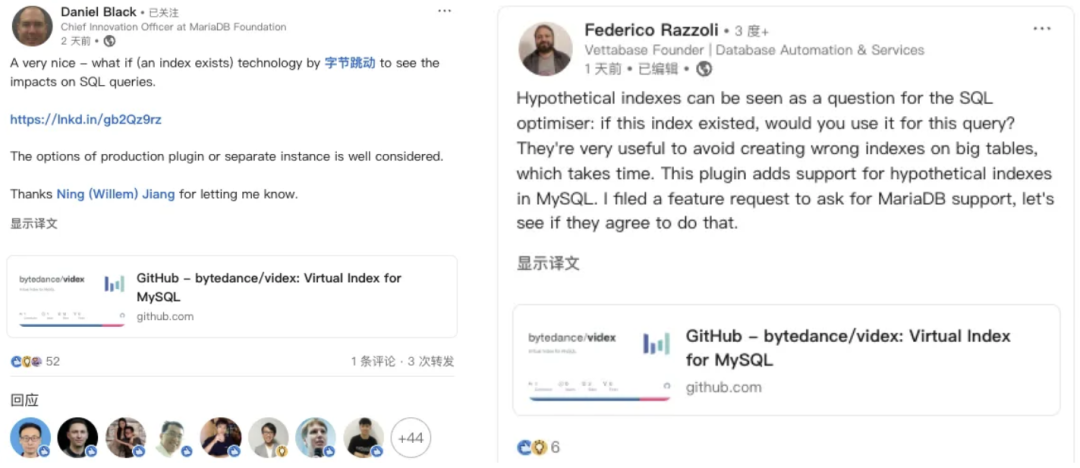
我觉得很多优秀的字节同学都有一个基本特点:如果你认为一件事有价值,那就一定要把它做完、做好。说实话,我没想过自己一定要成为业界最著名的专家或大牛,那太远了。有目标就去干吧,短期做不成就多花一点时间,越努力越幸运,收获一定在前方。

2021年的秋天,我在清华大学读博四,到了该考虑职业发展的时候。
当时我的想法很明确:比起以发表论文为目标的纯学术研究,我更希望自己的研究成果落到实处,为用户带来更丰富、更有价值的体验。
博士毕业后,我加入TikTok推荐部门,成了一名算法工程师。在之后一年半的时间里,我都在做同一个长期课题——怎样更好的建模用户留存?
在此之前,无论是公司还是行业,都做了不少探索。但从好到更好,还有很多事情要做。
当时行业中常见的方法是基于用户画像和点赞、评论等即时行为建模,并以此来预估他们的留存意愿。但这样会导致推荐系有点「短视」,对用户长期价值的关注不够。
经过与同事们不断讨论后,我们决定换一种视角——在关注用户即时行为的同时,对用户留存本身进行建模,并将其作为信号来指导推荐系统。事实上,这样的思路并不是我们的原创,而是在游戏和小说等领域得到了验证,这也给了我们信心。
但在这样一个对短视频来说相对空白的领域,我们还是走了不少弯路,失败也紧随而至。
一开始,我们参考了前人的经验,采用注意力机制让模型自己去做「用户行为归因」,也就是具体找到是哪条视频、用户的那一类行为导致了用户留存。但尝试了一段时间,发现并不能拿到满意的结果。
原因很简单,看小说和玩游戏相对容易归因,但在短视频领域,影响用户留存的因素很多、也很复杂,即时的、长期的,主动的、被动的,甚至是随机的……它们就像是一堆杂乱无章的「线团」,模型很难做到抽丝剥茧,找到真正有用的「线头」。
前人的路走不通,那就自己趟一条路出来。团队经过复盘后,我们想到,既然在海量视频和行为中难以精准归因,不如换一种「聚合视角」,在用户的累积行为中去寻找答案。
举个简单的例子,有用户在某一天看了5小时、评论了一次,第二天就不来了;一段时间后,同样的用户看了1小时、评论了10次,第二天又回来了。显然在这种情况下,真正影响用户留存的因素并非时长,而是评论互动。我们要推荐给用户的,也应该是高互动性内容。
现在回忆起来,那是一段非常难忘、有趣的经历。我们在一次次讨论、一次次复盘、一次次A/B Test中不停转换视角、寻找答案。对我来说,这也是一件很有成就感的事:我们开发的「归因模型」不仅为用户活跃度带来了不错的提升,也为公司其他业务部门带来了不错的借鉴和增益。
在那一年半里,我自己的角色也不仅仅是算法工程师,而是带着产品和运营的视角工作。这也正是字节最吸引我的地方:这里不设边界,不会把人绑定在某一个业务或产品上。你可以用自己的「工具箱」做很多尝试,公司那么多产品,都能成为发挥能力的舞台。
2024年,我转到了TikTok用户增长方向,主要关注日韩、欧洲等市场。从原来着眼全球的「广度」到如今聚焦当地的「深度」,对我而言,这又是一次重大的视角转变。
作为算法工程师,我经常会和部门其他同学到一线做用户的实地调研,有时候甚至会去一些偏远的小城和小镇。我经常跟朋友开玩笑说:你很难想象一位算法工程师会走上街头给用户「发传单」吧,我们这么干了!

但那是一种非常新奇的体验,你会见到不同的真实的人、会深入观察到不同文化,在交流和碰撞中,会打破你固有的认知,进而产生全新的技术想法。
还记得之前在德国问一位用户对TikTok的使用情况,他把手机屏幕使用时间给我们看,我惊讶的发现他一天中大部分时间都在浏览新闻,手机对他来说更像是一种工具而不是娱乐载体。这种惊讶在后来的大规模街访也得到了验证——相比我们的既有认知,德国人花在线上的时间确实要少得多。
每个国家和地区都有自身独有的属性。这也意味着,原本通用的技术思路在本地市场并不适用,而是要在用户增长和留存等方面进行大量的本土化适配——这正是我们正在努力的事,经过一段时间的探索,我们也成功将某个市场的新用户活跃度提升了1.5%左右。
在TikTok这样一个全球化的产品,我们每天都在探索新奇。可能很小的一次技术迭代,都会对用户的服务体验带来很大改变。这是一件很有成就感的事,但也提醒我们要时刻保持一颗敬畏之心。
我经常会想:能够通过自己的技术为用户的服务体验贡献力量,这真的是一件激动人心的事。
最后的最后,欢迎大家点击「阅读原文」投递筋斗云人才计划,加入这个才华横溢的团队!
(文:新智元)