

AI记忆机制团队 投稿
量子位 | 公众号 QbitAI
当AI不再只是“即兴发挥”的对话者,而开始拥有“记忆力”——
来自香港中文大学、爱丁堡大学、

大语言模型(LLMs)正快速从纯文本生成工具演化为具有长期交互能力的智能体。
这一转变对模型的“记忆能力”提出了更高的要求——不仅要能即时理解上下文,还需具备跨轮对话、多模态输入、个性化偏好等长期记忆机制。
然而,目前关于AI记忆系统的研究尚未形成统一清晰的框架,特别是缺乏对记忆机制底层原子操作的系统化理解。
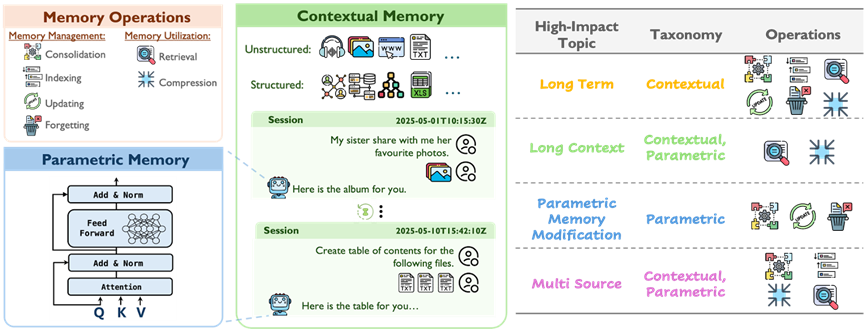
本综述首次从操作与表示两个维度出发,系统构建AI记忆的研究框架。
作者将AI中的记忆表示划分为参数化记忆与上下文记忆两大类,
这些原子操作不仅揭示了AI记忆系统的内部机制,
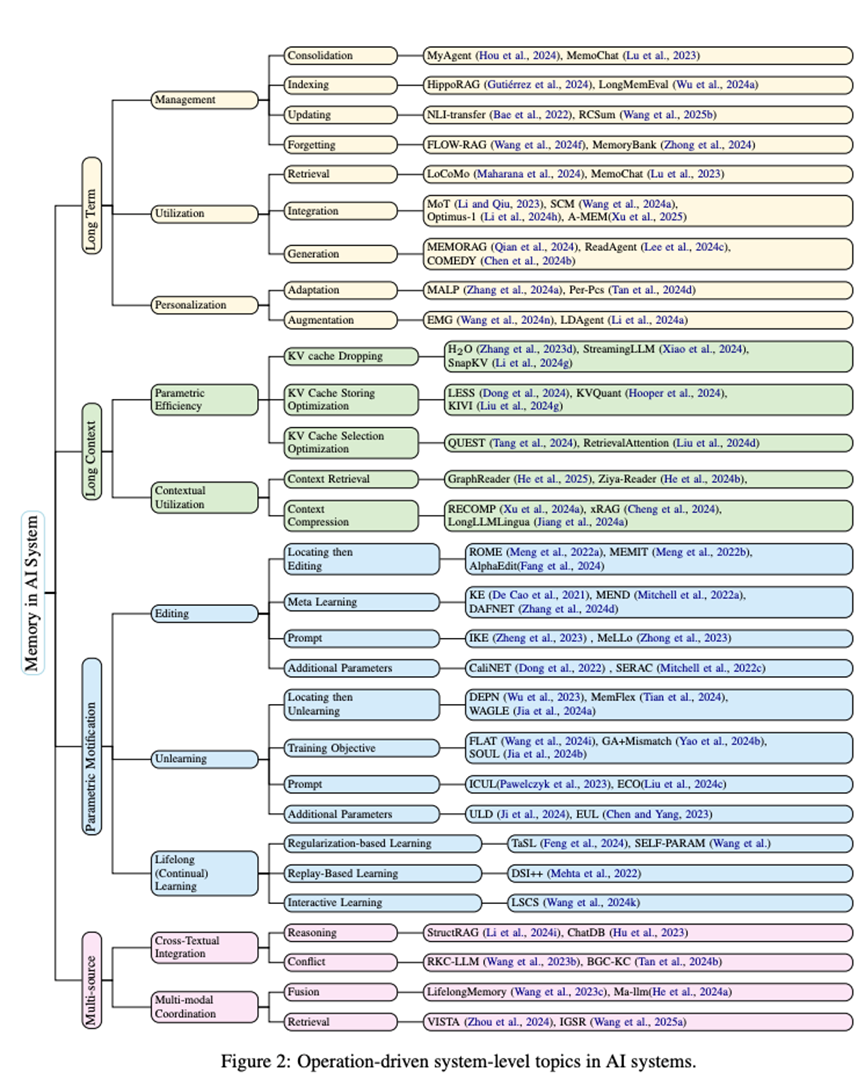
作者进一步将这些操作映射到四类关键研究主题:长期记忆(
通过这一结构化视角,本综述系统梳理了相关的研究方向、
记忆分类
参数化记忆 (Parametric Memory)指的是隐含存储于模型内部参数中的知识。
它作为一种即时、长期且持续存在的记忆形式,使模型能够快速、
然而,这类记忆缺乏可解释性,
上下文记忆 (Contextual Memory)是指显式的、外部的信息,
- 非结构化上下文记忆
一种面向多模态的显式记忆系统, 支持跨异构输入的信息存储与检索,包括文本、图像、 音频和视频等。它能够帮助智能体将推理过程与感知信号相结合, 整合多模态上下文信息。根据时间尺度不同, 非结构化记忆可分为短期(如当前对话轮的上下文)和长期( 如跨会话的历史记录与个性化知识)。 - 结构化上下文记忆
指将记忆内容组织为预定义、 可解释的格式或结构(如知识图谱、关系表或本体)。 这类记忆具备可查询性和符号推理能力, 常作为预训练语言模型联想能力的有益补充。 结构化记忆既可以在推理时动态构建以支持局部推理, 也可跨会话持久保存高质量知识。
记忆的原子操作
为了使AI系统中的记忆超越静态存储、实现动态演化,
 记忆管理(Memory Management)
记忆管理(Memory Management)
记忆管理操作控制信息的存储、维护与裁剪,
- 巩固(Consolidation)
将短期经验转化为持久性记忆, 如将对话轨迹或交互事件编码为模型参数、图谱或知识库。 是持续学习、个性化建模和外部记忆构建的关键。 - 索引(Indexing)
构建实体、属性等辅助索引, 提升存储信息的检索效率与结构化程度。支持神经、 符号与混合记忆的可扩展访问。 - 更新(Updating)
基于新知识对已有记忆进行激活与修改, 适用于参数内存中的定位与编辑,也包括对上下文记忆的摘要、 修剪与重构。 - 遗忘(Forgetting)
有选择地抑制或移除过时、 无效甚至有害的记忆内容。包括参数记忆中的“遗忘训练” 机制与上下文记忆中的时间删除或语义过滤。
 记忆利用(Memory Utilization)
记忆利用(Memory Utilization)
记忆利用指模型如何在推理过程中调用和使用已存储的信息,
- 检索(Retrieval)
根据输入(查询、 对话上下文或多模态内容)识别与访问相关记忆片段,支持跨源、 跨模态甚至跨参数的记忆调用。 - 压缩(Compression)
在上下文窗口有限的条件下保留关键信息、丢弃冗余内容, 以提高记忆利用效率。可在输入前进行(如摘要预处理), 也可在检索后进行(如生成前压缩或融合进模型)。
这些操作既是记忆系统动态运行的基础,也引入了数据中毒、
记忆的关键主题
为了进一步落实记忆操作与表示框架,
例如,在多轮对话系统中,检索增强生成(RAG)
而另一些系统则将长期记忆显式编码为超长上下文输入,对检索与压
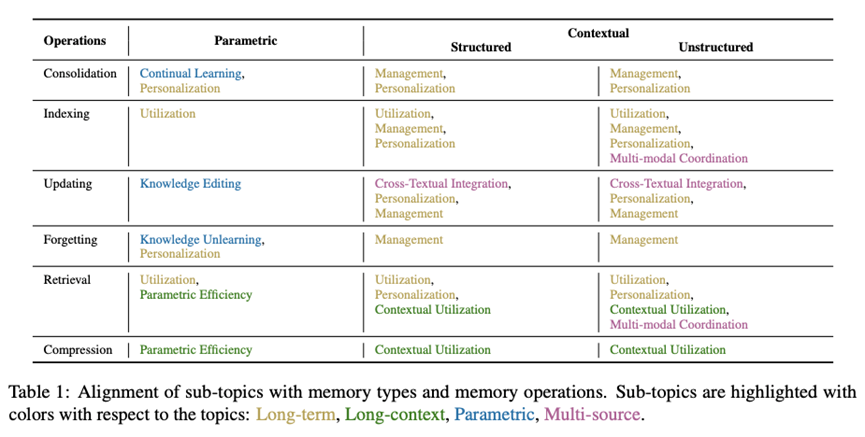
基于这些实际用例,作者将AI记忆研究划分为以下四个核心主题,
- 长期记忆(Long-Term Memory)
跨越所有记忆类型,强调跨会话的记忆管理、 个性化与推理支持, 尤其关注时间结构建模与多轮对话中的持久知识演化; - 长上下文记忆(Long-Context Memory)
主要关联非结构化上下文记忆,关注参数效率( 如KV缓存裁剪)与上下文利用效率(如长上下文压缩); - 参数化记忆修改(Parametric Memory Modification)
特指对模型内部知识的动态重写, 涵盖模型编辑、遗忘机制与持续学习策略; - 多源记忆整合(Multi-Source Memory)
强调对异构文本来源和多模态输入(如视觉、 音频)的统一建模,以提升复杂场景下的稳健性与语义理解。
为系统梳理AI记忆研究的演化趋势,
通过GPT驱动的主题相关性打分系统,
为衡量文献影响力,作者提出了相对引用指数(RCI, Relative Citation Index),借鉴医学领域的 RCR 思路,对引用量进行时间归一化,
RCI 有助于识别阶段性重要成果,
作者不仅展示了这些主题与记忆类型之间的对应关系,
作者同时在文中附录总结了各类主题研究的代表方法、
长期记忆
长期记忆(Long-term Memory)是支撑AI系统进行跨轮推理、
相比于短期上下文窗口,长期记忆能够跨越会话边界,
本节围绕长期记忆的运行机制,系统梳理了其关键操作与利用路径,
在记忆管理层面,作者总结了四类基础操作。
巩固(Consolidation)用于将短期交互转化为长期存
索引(Indexing)构建结构化、
更新(Updating)通过融合新知与重构结构实现记忆内容的
遗忘(Forgetting)则以内容剔除或抽象压缩的方式清除
当前主流系统已开始通过图谱建模、
在记忆利用层面,作者提出“检索–压缩–生成”三阶段联动机制。
其中,记忆检索(Retrieval)旨在从长期存储中筛选与当
紧接其后的记忆压缩(Compression)作为连接检索与生
记忆集成(Integration):即将多个检索片段整合为统一上下文表征,以供模型高效解码;
记忆驱动生成(Grounded Generation):
无论是静态拼接、多轮追踪,还是跨模态融合,
尽管检索性能在多个任务中已趋近饱和,
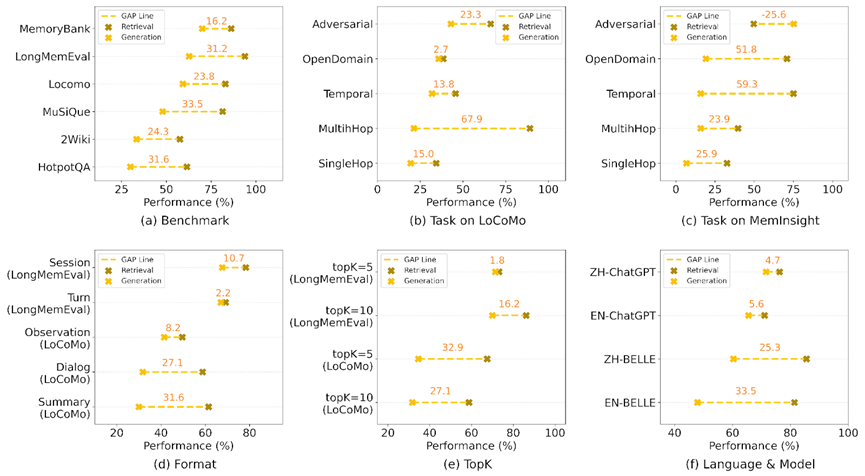
个性化是长期记忆的重要应用方向。作者将现有方法归为两大类:
一类是模型级适配(Model-level Adaptation),
另一类是外部记忆增强(External Memory Augmentation),通过调用结构化知识图谱、
两类方法各具优势,前者强调高效部署与任务泛化,
在评估层面,当前主流基准仍多聚焦于检索准确率或静态问答性能,
为此,作者提出了相对引用指数(RCI)这一新型指标,
通过结合RCI得分与研究主题,作者进一步揭示了不同记忆类型、
长上下文记忆
长上下文机制是大语言模型中记忆系统的重要组成部分,
它通过在超长输入序列中存储与调取历史交互、
尽管当前模型架构和训练技术已使得输入长度延伸至百万级toke
这些挑战主要体现在两个方面:
一是参数记忆效率(Parametric Efficiency),
二是上下文记忆利用(Contextual Utilization),即如何在有限窗口中选择、
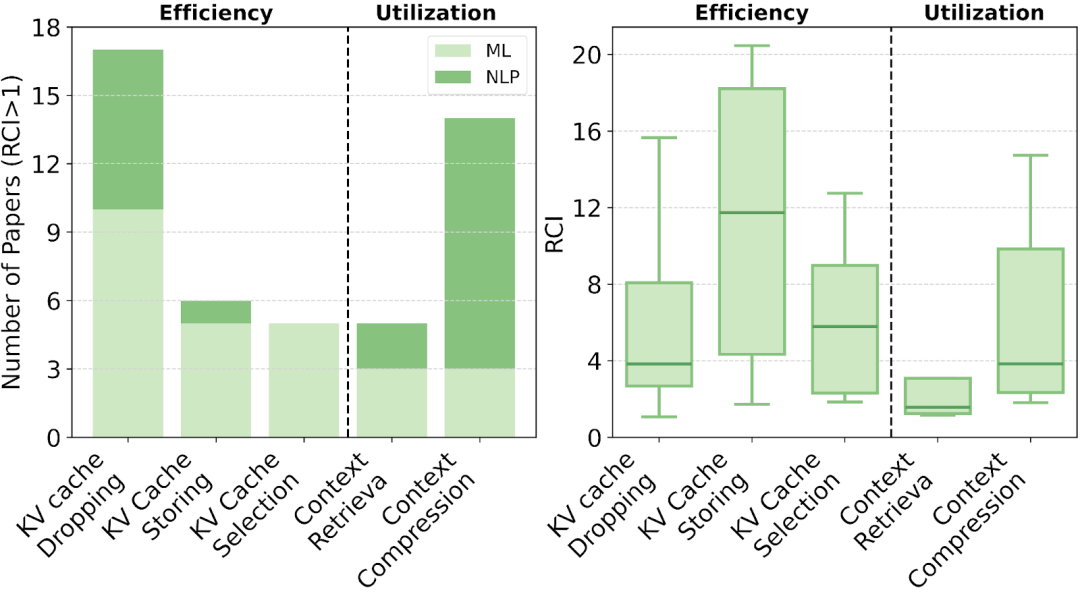
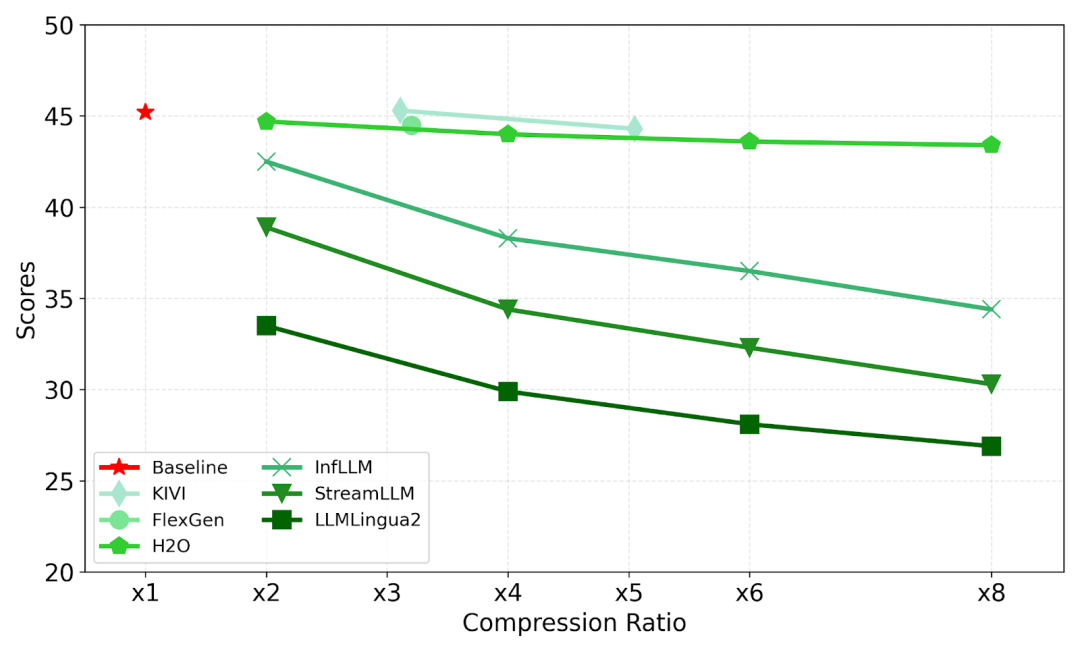
具体来说,KV缓存优化涉及裁剪、压缩与检索策略,
而上下文利用则涵盖检索、压缩、集成与生成等核心记忆操作,
作者指出,这些上下文机制本质上是构建“即时记忆”与“
结合RCI引用指数的分析,
尽管相关工作已有初步成果,但在面对多源、跨模态、
参数记忆修改
参数化记忆作为大语言模型中隐式编码的知识载体,
随着大模型逐步走向开放世界环境与个性化应用场景,
本节从“编辑(Editing)、遗忘(Unlearning)
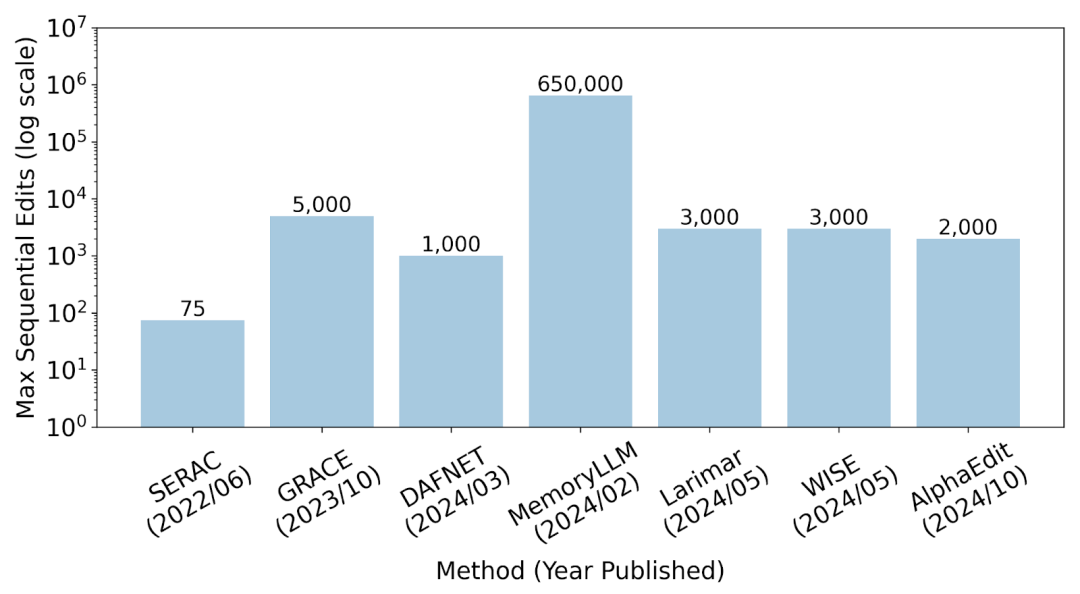
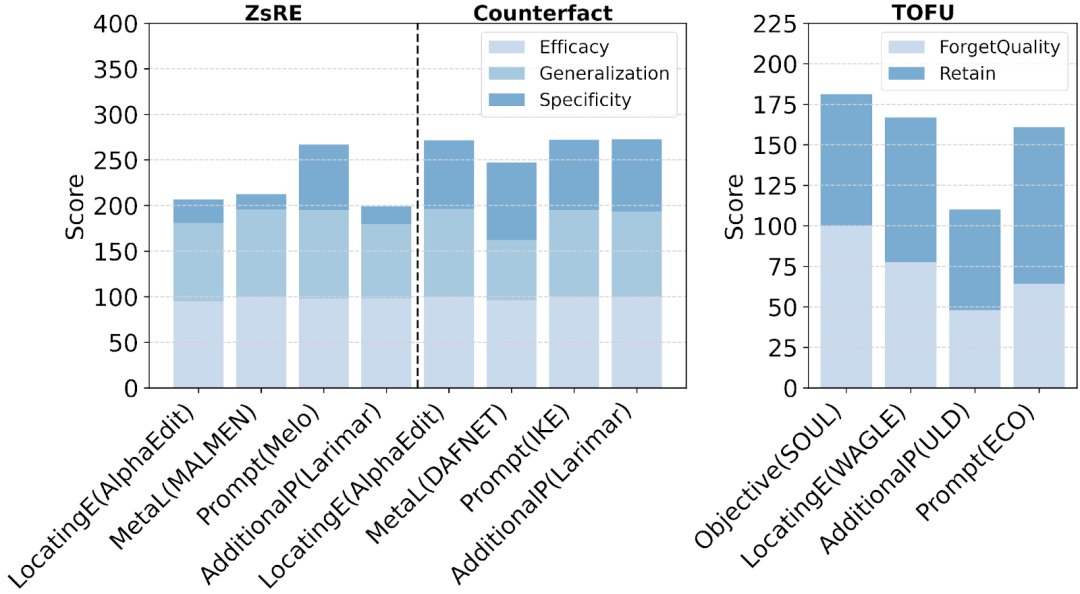
编辑类方法旨在对模型中的特定记忆进行精准定位与修改,
遗忘方法则聚焦于选择性地移除敏感或错误知识,
持续学习方法通过正则化或回放机制,
作者进一步在三个方面进行了深入讨论:
-
性能表现分析:不同方法在CounterFact、 ZsRE与ToFU基准上展示了不同的权衡格局,提示“ 特异性建模”与“持续性挑战”仍是后续研究重点; -
可扩展性评估:当前大多数非提示法仍受限于模型规模与计算资源, 在大模型上的大规模修改能力亟待提升; -
影响力趋势(RCI分析):编辑方法关注度高、落地丰富, 而遗忘方法虽数量较少,但在“训练目标”和“附加参数” 等方向展现出良好影响潜力。
综上,作者强调:
参数记忆不仅是模型知识调控的关键接口,也是未来智能体学习能力延展的基础模块,值得围绕“表达粒度、多轮积累、语义泛化”等方向持续深入探索。
多源记忆
多源记忆是构建现实世界智能体的核心机制。
现代AI系统需融合内在的参数化知识与多样化的外部记忆,
本节围绕两大核心挑战——跨文本整合与多模态协调,
在跨文本整合方面,研究主要聚焦于两类任务:
其二是冲突处理,强调在整合异构信息时进行显式的来源归因与一致性验证,避免事实漂移与语义冲突。代表性工作涵盖上下文冲突检测、知识可信度调控与冲突消解等策略。
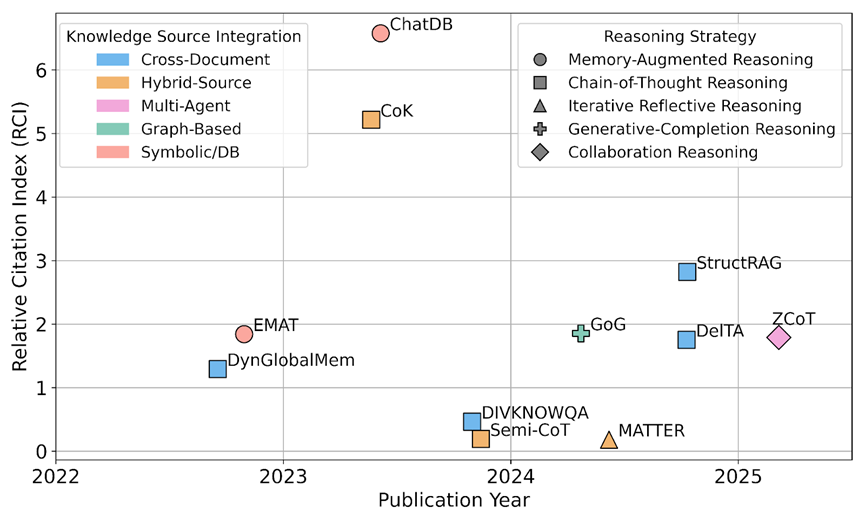
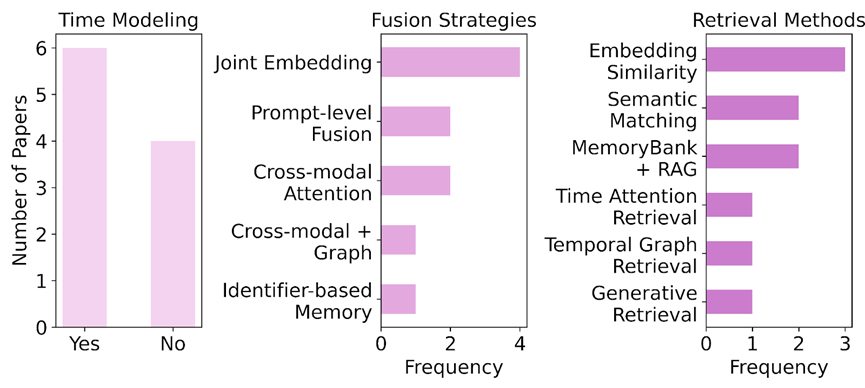
在多模态协调方面,研究路径沿三大方向逐步拓展:
模态融合策略从联合嵌入与提示级融合发展到基于图结构的可控对齐
模态检索从静态相似度匹配演进为时间感知与意图驱动的动态召回;
时间建模则成为支撑多轮交互与任务延续的关键,涌现出如 WorldMem 与 E-Agent 等具备自维护能力的系统,能够实现多模态记忆的持续压缩、
RCI 统计显示,跨文本推理仍是当前多源记忆研究的主要阵地,
与此同时,多模态协调研究也快速兴起,在融合、
尽管如此,
未来的研究应致力于构建具备冲突感知、
记忆的实际应用
随着AI系统从静态对话走向动态交互、长期适应与多模态融合,
无论是编码通用知识的参数化模型(如编程助手、医学/法律问答)
代表性产品如ChatGPT、GitHub Copilot、Replika、Amazon推荐系统与腾讯 ima.copilot,体现了记忆驱动AI从“任务工具”向“
在工具层面,记忆增强系统逐步构建出从底层组件(向量数据库、
它们支撑长期上下文管理、个体状态建模、
作者在附录中详尽的分析了记忆相关的组件,框架,服务以及产品。
人类 vs. AI:记忆系统对照
作者进一步详细分析了人类与人工智能系统的记忆的相似点和不同点
具体来说,二者在机制虽然在功能上高度趋同——都支持学习、
但在人类大脑中,记忆由神经网络隐式编码,依赖情绪、
而在AI系统中,记忆可以是显式存储的结构化数据或模型参数,
两者在以下关键维度上差异显著:
- 存储结构
生物分布式 vs. 模块化/参数化 - 巩固机制
被动慢速整合(睡眠等生理机制)vs. 显式快速写入(策略驱动、可选择) - 索引方式
稀疏联想激活(海马体驱动)vs. 嵌入索引或键值查找 - 更新方式
重构式再巩固 vs. 精准定位与编辑 - 遗忘机制
自然衰减 vs. 策略删除与可控擦除 - 检索机制
联想触发 vs. 查询驱动 - 可压缩性
隐式提炼 vs. 显式裁剪与量化 - 所有权属性
私有与不可共享 vs. 可复制与可广播 - 容量边界
生物限制 vs. 受存储与计算资源约束,接近于无限扩展
AI记忆系统的未来蓝图:从操作瓶颈到认知跃迁
要构建真正具备长期适应、
本研究基于RCI分析与最新趋势,
在该文提及的主题层面,当前AI系统仍面临一些关键挑战:
在前沿视角上,研究者正积极探索更具人类认知特征的机制:
此外,统一表示体系、
论文地址:https://arxiv.org/abs/2505.00675
Github地址:https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)