
项目简介
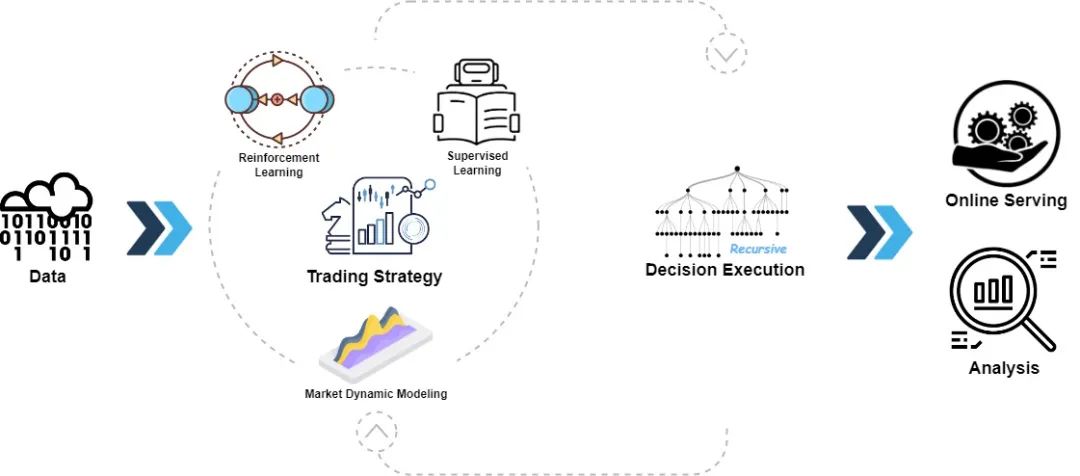
Qlib是一个开源的、面向AI的量化投资平台,旨在利用AI技术实现量化投资的潜力、赋能研究并创造价值,从探索想法到实现生产。Qlib支持多样化的机器学习建模范式,包括监督学习、市场动态建模和强化学习。
越来越多的最先进量化研究工作和论文以不同范式在Qlib中发布,共同解决量化投资中的关键挑战。例如:1)使用监督学习从丰富且异构的金融数据中挖掘市场的复杂非线性模式;2)使用自适应概念漂移技术建模金融市场的动态特性;3)使用强化学习建模连续投资决策,帮助投资者优化交易策略。
Qlib包含数据处理、模型训练、回测的完整ML流程,并涵盖量化投资的整个链条:阿尔法信号寻找、风险建模、投资组合优化和订单执行。更多细节请参阅我们的论文[“Qlib: 一个AI导向的量化投资平台”](https://arxiv.org/abs/2009.11189 “”Qlib: 一个AI导向的量化投资平台””)。
快速开始
本快速入门指南试图展示:
-
使用Qlib构建完整的量化研究工作流并尝试您的想法非常简单。 -
尽管使用公开数据和简单模型,机器学习技术在实践量化投资中表现非常出色。
安装
Qlib支持以下Python版本:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意:
-
建议使用Conda管理Python环境。在某些情况下,在非conda环境中使用Python可能导致头文件缺失,导致某些包安装失败。 -
请注意,在Python 3.6中安装cython会在从源码安装Qlib时引发错误。如果用户使用Python 3.6,建议升级到Python 3.8或更高版本,或使用conda的Python从源码安装Qlib。
通过pip安装
用户可以通过以下命令轻松安装Qlib:
ounter(linepip install pyqlib
注意:pip将安装最新的稳定版qlib。然而,qlib的主分支正在积极开发中。如果您想测试主分支中的最新脚本或功能,请使用以下方法安装qlib。
从源码安装
用户也可以按照以下步骤从源码安装最新的开发版Qlib:
-
在从源码安装Qlib之前,用户需要安装一些依赖项:
pip install numpypip install --upgrade cython -
-
-
-
-
-
-
-
- ounter(line
- ounter(line
-
克隆仓库并安装Qlib:
git clone https://github.com/microsoft/qlib.git && cd qlibpip install . # 开发推荐使用`pip install -e .[dev]`,详情见docs/developer/code_standard_and_dev_guide.rst -
-
-
-
-
-
-
-
- ounter(line
- ounter(line
提示:如果您在环境中安装Qlib或运行示例失败,比较您的步骤与CI工作流[1]可能有助于发现问题。
Mac用户提示:如果您使用M1芯片的Mac,可能会在构建LightGBM的wheel时遇到问题,这是由于缺少OpenMP的依赖。要解决此问题,首先使用brew install libomp安装openmp,然后运行pip install .成功构建。
数据准备
❗ 由于更严格的数据安全政策,官方数据集暂时禁用。您可以尝试社区贡献的此数据源[2]。以下是下载最新数据的示例:
ounter(lineounter(lineounter(lineounter(linewget https://github.com/chenditc/investment_data/releases/latest/download/qlib_bin.tar.gzmkdir -p ~/.qlib/qlib_data/cn_datatar -zxvf qlib_bin.tar.gz -C ~/.qlib/qlib_data/cn_data --strip-components=1rm -f qlib_bin.tar.gz
以下官方数据集将在短期内恢复。
通过运行以下代码加载和准备数据:
使用模块获取数据
ounter(lineounter(lineounter(lineounter(lineounter(line# 获取日频数据python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn# 获取1分钟数据python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min
从源码获取数据
ounter(lineounter(lineounter(lineounter(lineounter(line# 获取日频数据python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn# 获取1分钟数据python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min
此数据集由crawler脚本[3]收集的公开数据创建,这些脚本已在同一仓库中发布。用户可以用它创建相同的数据集。数据集描述[4]
请注意**数据是从Yahoo Finance[5]收集的,数据可能不完美。我们建议用户如果有高质量数据集,可以准备自己的数据。更多信息,用户可以参阅相关文档[6]。
日频数据的自动更新(来自雅虎财经)
如果用户只想在历史数据上尝试模型和策略,此步骤是可选的。
建议用户先手动更新一次数据(–trading_date 2021-05-25),然后设置为自动更新。
注意:用户不能基于Qlib提供的离线数据增量更新数据(某些字段已被移除以减少数据大小)。用户应使用yahoo收集器[7]从头下载雅虎数据,然后增量更新。
更多信息,请参阅:yahoo收集器[8]
-
每个交易日自动更新数据到”qlib”目录(Linux)
- ounter(line
-
脚本路径: scripts/data_collector/yahoo/collector.py -
使用crontab:
crontab -e -
设置定时任务:
* * * * 1-5 python <脚本路径> update_data_to_bin --qlib_data_1d_dir <用户数据目录> -
-
-
-
-
手动更新数据
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <用户数据目录> --trading_date <开始日期> --end_date <结束日期> -
-
-
-
-
trading_date: 交易日开始 -
end_date: 交易日结束(不包括) - ounter(line
检查数据健康状态
-
我们提供了一个脚本来检查数据的健康状态,您可以运行以下命令检查数据是否健康: python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data -
-
-
-
- ounter(line
-
当然,您也可以添加一些参数来调整测试结果,例如: python scripts/check_data_health.py check_data --qlib_dir ~/.qlib/qlib_data/cn_data --missing_data_num 30055 --large_step_threshold_volume 94485 --large_step_threshold_price 20 -
-
-
-
- ounter(line
-
如果您想了解更多关于 check_data_health的信息,请参阅文档[9]。
量化研究工作流自动化
Qlib提供了一个名为qrun的工具,可以自动运行整个工作流(包括构建数据集、训练模型、回测和评估)。您可以按照以下步骤启动自动化量化研究工作流并获得图形化报告分析:
-
量化研究工作流:使用lightgbm工作流配置(workflow_config_lightgbm_Alpha158.yaml[10])运行
qrun:cd examples # 避免在包含`qlib`的目录下运行程序qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml如果用户想在调试模式下使用
qrun,请使用以下命令:python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yamlqrun的结果如下,更多解释请参阅文档[11]。 -
-
-
-
-
-
-
-
-
-
-
-
- ounter(line
- ounter(line
- ounter(line
-
图形化报告分析:首先运行
python -m pip install .[analysis]安装所需的依赖项。然后使用jupyter notebook运行examples/workflow_by_code.ipynb以获得图形化报告。 -
回测收益 -
分组累计收益 -
收益分布 -
信息系数(IC) -
预测信号(模型预测)的自相关性 -
预测信号(模型预测)分析 -
投资组合分析 -
上述结果的解释[12]
通过代码构建定制化量化研究工作流
自动化工作流可能不适合所有量化研究人员的研究流程。为了支持灵活的量化研究工作流,Qlib还提供了模块化接口,允许研究人员通过代码构建自己的工作流。这里[13]是一个通过代码定制量化研究工作流的演示。
主要挑战与解决方案
量化投资是一个非常独特的场景,有许多关键挑战需要解决。目前,Qlib为其中几个挑战提供了解决方案。
预测:寻找有价值的信号/模式
准确预测股票价格趋势是构建盈利投资组合的重要部分。然而,金融市场中各种格式的大量数据使得构建预测模型具有挑战性。
越来越多的最先进量化研究工作/论文,专注于构建预测模型以挖掘复杂金融数据中有价值的信号/模式,已在Qlib中发布。
量化模型(论文)集[14]
以下是构建在Qlib上的模型列表:
-
基于XGBoost的GBDT (Tianqi Chen等, KDD 2016)[15] -
基于LightGBM的GBDT (Guolin Ke等, NIPS 2017)[16] -
基于Catboost的GBDT (Liudmila Prokhorenkova等, NIPS 2018)[17] -
基于pytorch的MLP[18] -
基于pytorch的LSTM (Sepp Hochreiter等, Neural computation 1997)[19] -
基于pytorch的GRU (Kyunghyun Cho等, 2014)[20] -
基于pytorch的ALSTM (Yao Qin等, IJCAI 2017)[21] -
基于pytorch的GATs (Petar Velickovic等, 2017)[22] -
基于pytorch的SFM (Liheng Zhang等, KDD 2017)[23] -
基于tensorflow的TFT (Bryan Lim等, International Journal of Forecasting 2019)[24] -
基于pytorch的TabNet (Sercan O. Arik等, AAAI 2019)[25] -
基于LightGBM的DoubleEnsemble (Chuheng Zhang等, ICDM 2020)[26] -
基于pytorch的TCTS (Xueqing Wu等, ICML 2021)[27] -
基于pytorch的Transformer (Ashish Vaswani等, NeurIPS 2017)[28] -
基于pytorch的Localformer (Juyong Jiang等)[29] -
基于pytorch的TRA (Hengxu, Dong等, KDD 2021)[30] -
基于pytorch的TCN (Shaojie Bai等, 2018)[31] -
基于pytorch的ADARNN (YunTao Du等, 2021)[32] -
基于pytorch的ADD (Hongshun Tang等,2020)[33] -
基于pytorch的IGMTF (Wentao Xu等,2021)[34] -
基于pytorch的HIST (Wentao Xu等,2021)[35] -
基于pytorch的KRNN[36] -
基于pytorch的Sandwich[37]
欢迎提交新的量化模型的PR。
各模型在Alpha158和Alpha360数据集上的性能可以在这里[38]找到。
运行单个模型
以上列出的所有模型都可以用Qlib运行。用户可以通过benchmarks[39]文件夹找到我们提供的配置文件和一些关于模型的详细信息。更多信息可以在上面列出的模型文件中找到。
Qlib提供了三种不同的方式来运行单个模型,用户可以选择最适合自己情况的方式:
-
用户可以使用上面提到的工具 qrun基于配置文件运行模型的工作流。 -
用户可以基于 examples文件夹中的示例[40]创建一个workflow_by_codepython脚本。 -
用户可以使用 examples文件夹中的脚本`run_all_model.py`[41]来运行模型。以下是具体的shell命令示例:python run_all_model.py run --models=lightgbm,其中--models参数可以接受上面列出的任意数量的模型(可用模型可以在benchmarks[42]中找到)。更多用例请参考文件的文档字符串[43]。 -
注意:每个基线有不同的环境依赖,请确保您的Python版本符合要求(例如由于 tensorflow==1.15.0的限制,TFT仅支持Python 3.6~3.7)
运行多个模型
Qlib还提供了一个脚本`run_all_model.py`[44],可以多次运行多个模型。(注意:目前该脚本仅支持Linux。未来将支持其他操作系统。此外,它还不支持并行运行同一模型多次,这将在未来的开发中修复。)
该脚本将为每个模型创建一个唯一的虚拟环境,并在训练后删除环境。因此,只会生成和存储诸如IC和回测结果等实验结果。
以下是运行所有模型10次的示例:
ounter(linepython run_all_model.py run 10
它还提供了API来一次性运行特定模型。更多用例请参考文件的文档字符串[45]。
适应市场动态
由于金融市场环境的非平稳性,不同时期的数据分布可能会发生变化,这使得基于训练数据构建的模型在未来测试数据上的性能下降。因此,使预测模型/策略适应市场动态对模型/策略的性能非常重要。
以下是构建在Qlib上的解决方案列表:
-
滚动重训练[46] -
基于pytorch的DDG-DA (Wendi等, AAAI 2022)[47]
强化学习:建模连续决策
Qlib现在支持强化学习,这一功能旨在建模连续投资决策。通过与环境交互学习以最大化某种累积奖励的概念,该功能帮助投资者优化其交易策略。
以下是按场景分类的构建在Qlib上的解决方案列表。
订单执行的强化学习[48]
这里[49]是该场景的介绍。以下所有方法都在这里[50]进行了比较。
-
TWAP[51] -
[PPO: “基于近端策略优化的端到端最优交易执行框架”, IJCAL 2020](examples/rl_order_execution/exp_configs/backtest_ppo.yml “PPO: “基于近端策略优化的端到端最优交易执行框架”, IJCAL 2020″) -
[OPDS: “用于订单执行的通用交易与预言策略蒸馏”, AAAI 2021](examples/rl_order_execution/exp_configs/backtest_opds.yml “OPDS: “用于订单执行的通用交易与预言策略蒸馏”, AAAI 2021″)
量化数据集集
数据集在量化中扮演着非常重要的角色。以下是构建在Qlib上的数据集列表:
|
|
|
|
|---|---|---|
| Alpha360[52] |
|
|
| Alpha158[53] |
|
|
这里[54]是一个使用Qlib构建数据集的教程。 欢迎提交构建新量化数据集的PR。
学习框架
Qlib高度可定制,其许多组件是可学习的。可学习的组件是预测模型和交易代理的实例。它们基于学习框架层学习,然后应用于工作流层中的多个场景。学习框架也利用工作流层(例如共享信息提取器,基于执行环境创建环境)。
根据学习范式,它们可以分为强化学习和监督学习。
-
对于监督学习,详细文档可以在这里[55]找到。 -
对于强化学习,详细文档可以在这里[56]找到。Qlib的RL学习框架利用 工作流层中的执行环境创建环境。值得注意的是,嵌套执行器也被支持。这使用户能够一起优化不同级别的策略/模型/代理(例如为特定的投资组合管理策略优化订单执行策略)。
更多关于Qlib
如果您想快速浏览Qlib最常用的组件,可以尝试这里[57]的笔记本。
详细文档组织在docs[58]中。构建HTML格式的文档需要Sphinx[59]和readthedocs主题。
ounter(lineounter(lineounter(lineounter(lineounter(linecd docs/conda install sphinx sphinx_rtd_theme -y# 或者您可以使用pip安装# pip install sphinx sphinx_rtd_thememake html
您也可以直接在线查看最新文档[60]。
Qlib正在积极持续开发中。我们的计划在路线图中,作为一个github项目[61]管理。
离线模式和在线模式
Qlib的数据服务器可以部署为离线模式或在线模式。默认模式是离线模式。
在离线模式下,数据将本地部署。
在在线模式下,数据将作为共享数据服务部署。数据及其缓存将由所有客户端共享。由于更高的缓存命中率,数据检索性能有望提高。它也将消耗更少的磁盘空间。在线模式的文档可以在Qlib-Server[62]找到。在线模式可以使用基于Azure CLI的脚本[63]自动部署。在线数据服务器的源代码可以在Qlib-Server仓库[64]找到。
Qlib数据服务器性能
数据处理的性能对于像AI技术这样的数据驱动方法非常重要。作为一个面向AI的平台,Qlib为数据存储和数据处理提供了解决方案。为了展示Qlib数据服务器的性能,我们将其与其他几种数据存储解决方案进行了比较。
我们通过完成相同的任务来评估几种存储解决方案的性能,该任务从股票市场的基本OHLCV日数据(2007年至2020年每天800只股票)创建一个数据集(14个特征/因子)。该任务涉及数据查询和处理。
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
7.4±0.3 |
|
|
|
|
|
|
|
4.2±0.2 |
|
-
+(-)E表示(不)使用表达式缓存 -
+(-)D表示(不)使用数据集缓存
大多数通用数据库加载数据花费太多时间。在深入了解底层实现后,我们发现数据在通用数据库解决方案中经过太多层接口和不必要的格式转换。这种开销大大减慢了数据加载过程。Qlib数据以紧凑格式存储,这种格式可以高效地组合成数组用于科学计算。
相关报告
-
Qlib指南:微软的AI投资平台[65] -
微软也搞AI量化平台?还是开源的! -
微矿Qlib:业内首个AI量化投资开源平台
项目地址
https://github.com/microsoft/qlib/blob/main/README.md
参考资料
CI工作流: .github/workflows/test_qlib_from_source.yml
[2]此数据源: https://github.com/chenditc/investment_data/releases
[3]crawler脚本: scripts/data_collector/
[4]数据集描述: https://github.com/microsoft/qlib/tree/main/scripts/data_collector#description-of-dataset
[5]Yahoo Finance: https://finance.yahoo.com/lookup
[6]相关文档: https://qlib.readthedocs.io/en/latest/component/data.html#converting-csv-format-into-qlib-format
[7]yahoo收集器: https://github.com/microsoft/qlib/tree/main/scripts/data_collector/yahoo#automatic-update-of-daily-frequency-datafrom-yahoo-finance
[8]yahoo收集器: https://github.com/microsoft/qlib/tree/main/scripts/data_collector/yahoo#automatic-update-of-daily-frequency-datafrom-yahoo-finance
[9]文档: https://qlib.readthedocs.io/en/latest/component/data.html#checking-the-health-of-the-data
[10]workflow_config_lightgbm_Alpha158.yaml: examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
[11]文档: https://qlib.readthedocs.io/en/latest/component/strategy.html#result
[12]解释: https://qlib.readthedocs.io/en/latest/component/report.html
[13]这里: examples/workflow_by_code.ipynb
[14]量化模型(论文)集: examples/benchmarks
[15]基于XGBoost的GBDT (Tianqi Chen等, KDD 2016): examples/benchmarks/XGBoost/
[16]基于LightGBM的GBDT (Guolin Ke等, NIPS 2017): examples/benchmarks/LightGBM/
[17]基于Catboost的GBDT (Liudmila Prokhorenkova等, NIPS 2018): examples/benchmarks/CatBoost/
[18]基于pytorch的MLP: examples/benchmarks/MLP/
[19]基于pytorch的LSTM (Sepp Hochreiter等, Neural computation 1997): examples/benchmarks/LSTM/
[20]基于pytorch的GRU (Kyunghyun Cho等, 2014): examples/benchmarks/GRU/
[21]基于pytorch的ALSTM (Yao Qin等, IJCAI 2017): examples/benchmarks/ALSTM
[22]基于pytorch的GATs (Petar Velickovic等, 2017): examples/benchmarks/GATs/
[23]基于pytorch的SFM (Liheng Zhang等, KDD 2017): examples/benchmarks/SFM/
[24]基于tensorflow的TFT (Bryan Lim等, International Journal of Forecasting 2019): examples/benchmarks/TFT/
[25]基于pytorch的TabNet (Sercan O. Arik等, AAAI 2019): examples/benchmarks/TabNet/
[26]基于LightGBM的DoubleEnsemble (Chuheng Zhang等, ICDM 2020): examples/benchmarks/DoubleEnsemble/
[27]基于pytorch的TCTS (Xueqing Wu等, ICML 2021): examples/benchmarks/TCTS/
[28]基于pytorch的Transformer (Ashish Vaswani等, NeurIPS 2017): examples/benchmarks/Transformer/
[29]基于pytorch的Localformer (Juyong Jiang等): examples/benchmarks/Localformer/
[30]基于pytorch的TRA (Hengxu, Dong等, KDD 2021): examples/benchmarks/TRA/
[31]基于pytorch的TCN (Shaojie Bai等, 2018): examples/benchmarks/TCN/
[32]基于pytorch的ADARNN (YunTao Du等, 2021): examples/benchmarks/ADARNN/
[33]基于pytorch的ADD (Hongshun Tang等,2020): examples/benchmarks/ADD/
[34]基于pytorch的IGMTF (Wentao Xu等,2021): examples/benchmarks/IGMTF/
[35]基于pytorch的HIST (Wentao Xu等,2021): examples/benchmarks/HIST/
[36]基于pytorch的KRNN: examples/benchmarks/KRNN/
[37]基于pytorch的Sandwich: examples/benchmarks/Sandwich/
[38]这里: examples/benchmarks/README.md
[39]benchmarks: examples/benchmarks
[40]示例: examples/workflow_by_code.py
[41]run_all_model.py: examples/run_all_model.py
benchmarks: examples/benchmarks/
[43]文档字符串: examples/run_all_model.py
[44]run_all_model.py: examples/run_all_model.py
文档字符串: examples/run_all_model.py
[46]滚动重训练: examples/benchmarks_dynamic/baseline/
[47]基于pytorch的DDG-DA (Wendi等, AAAI 2022): examples/benchmarks_dynamic/DDG-DA/
[48]订单执行的强化学习: examples/rl_order_execution
[49]这里: https://qlib.readthedocs.io/en/latest/component/rl/overall.html#order-execution
[50]这里: examples/rl_order_execution
[51]TWAP: examples/rl_order_execution/exp_configs/backtest_twap.yml
[52]Alpha360: ./qlib/contrib/data/handler.py
[53]Alpha158: ./qlib/contrib/data/handler.py
[54]这里: https://qlib.readthedocs.io/en/latest/advanced/alpha.html
[55]这里: https://qlib.readthedocs.io/en/latest/component/model.html
[56]这里: https://qlib.readthedocs.io/en/latest/component/rl.html
[57]这里: examples/tutorial/
[58]docs: docs/
[59]Sphinx: http://www.sphinx-doc.org
[60]最新文档: http://qlib.readthedocs.io/
[61]github项目: https://github.com/microsoft/qlib/projects/1
[62]Qlib-Server: https://qlib-server.readthedocs.io/
[63]基于Azure CLI的脚本: https://qlib-server.readthedocs.io/en/latest/build.html#one-click-deployment-in-azure
[64]Qlib-Server仓库: https://github.com/microsoft/qlib-server
[65]Qlib指南:微软的AI投资平台: https://analyticsindiamag.com/qlib/
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)