
阿里国际AI团队提出了一项创新性的研究成果 —— CIGEval,这是首个系统性探讨基于多模态大模型(LMM)驱动的图像生成评估智能体框架。CIGEval 不仅集成多功能工具箱以实现细粒度分析,更通过任务拆解与工具调度机制,显著提升了在复杂图像生成任务中的评估准确性与可解释性。目前,CIGEval 已正式在 ComfyUI-Copilot 上线使用。

标题:A Unified Agentic Framework for Evaluating Conditional Image Generation论文链接:https://arxiv.org/abs/2504.07046代码仓库:https://github.com/HITsz-TMG/Agentic-CIGEval应用入口:https://github.com/AIDC-AI/ComfyUI-Copilot
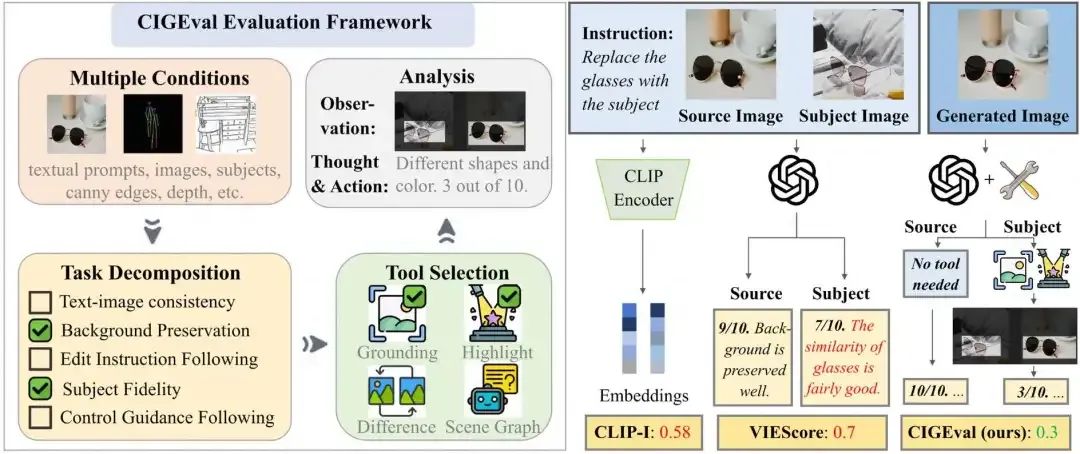
图 1:CIGEval的整体框架以及与传统评估流程的对比。
背景: 图像生成评估的挑战
从最初的自然语言图像生成,到如今支持参考图像驱动的可控生成,生图模型已具备多种复杂任务能力。然而,与模型生成能力的飞跃式发展相比,图像评估体系的进展却显得滞后。 如何自动、公平、可靠地评估AI合成图像仍面临三大关键挑战:
- 任务泛化性差: 现有评估方法如 LPIPS、CLIP-Score 通常只适用于单一类型评估任务,例如感知相似性或图文对齐,难以泛化到图像编辑、合成控制、背景保持等多条件任务。
- 可解释性有限: 大多数指标仅返回单一分数,无法说明错误发生在哪个维度,例如AI合成图片“是否遵循指令”、“是否保留主体”等维度无法拆分分析。
- 与人类评估一致性差:类似 CLIP 和 DINO 这样的传统指标,其评估结果容易忽略图像细节, 即便是如 GPT-4o 驱动的先进方法 VIEScore,也难以识别图像中的细微改动,导致与人工评分间存在显著差异。

图 2:传统指标难以识别的图片中主体颜色变化、背景保留程度等细节。
方法: 图像评估的“工具链式思维”
CIGEval 的核心思想是将图像评估任务建模为 工具链式智能体推理流程(Tool-Integrated Evaluation Reasoning)。即模型不再单靠自身视觉能力,而是通过任务拆解 → 工具调度 → 评分融合的结构性策略完成评估任务。
多工具箱设计
CIGEval 引入 4 种关键工具用于扩展 LMM 的细节感知能力:
- Grounding
:定位图像中关键物体; - Highlight
:突出显示图像区域; - Difference
:标注前后图像差异部分; - Scene Graph
:分析图像结构层次与场景元素。
这些工具被组合调度,构成一个外部感知子系统,为模型提供细粒度反馈支持。
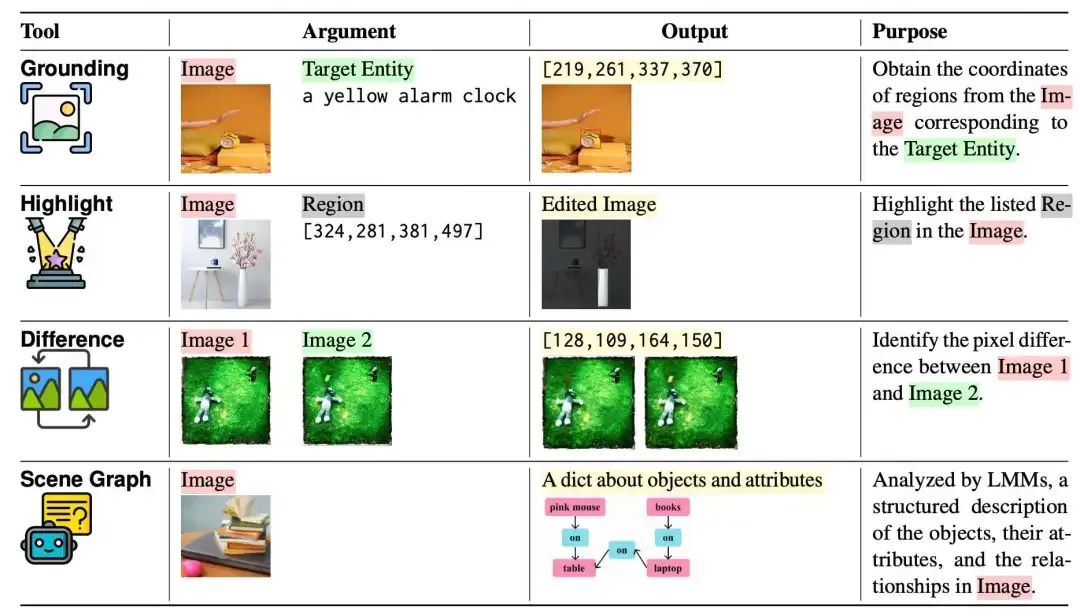
图 3:CIGEval中使用的四种工具。
拆解式评估路径规划
整个评估过程遵循三个阶段:
- 任务拆解
:CIGEval 将复杂任务(如图像编辑)拆解为若干可测子问题(如“背景是否变化”“是否遵循文本描述”等); - 智能工具调度
:模型根据输入目标自动调用匹配工具处理子问题; - 子评分融合
:每一子任务单独评估,最后通过最小分策略输出总评分,确保整体鲁棒性。
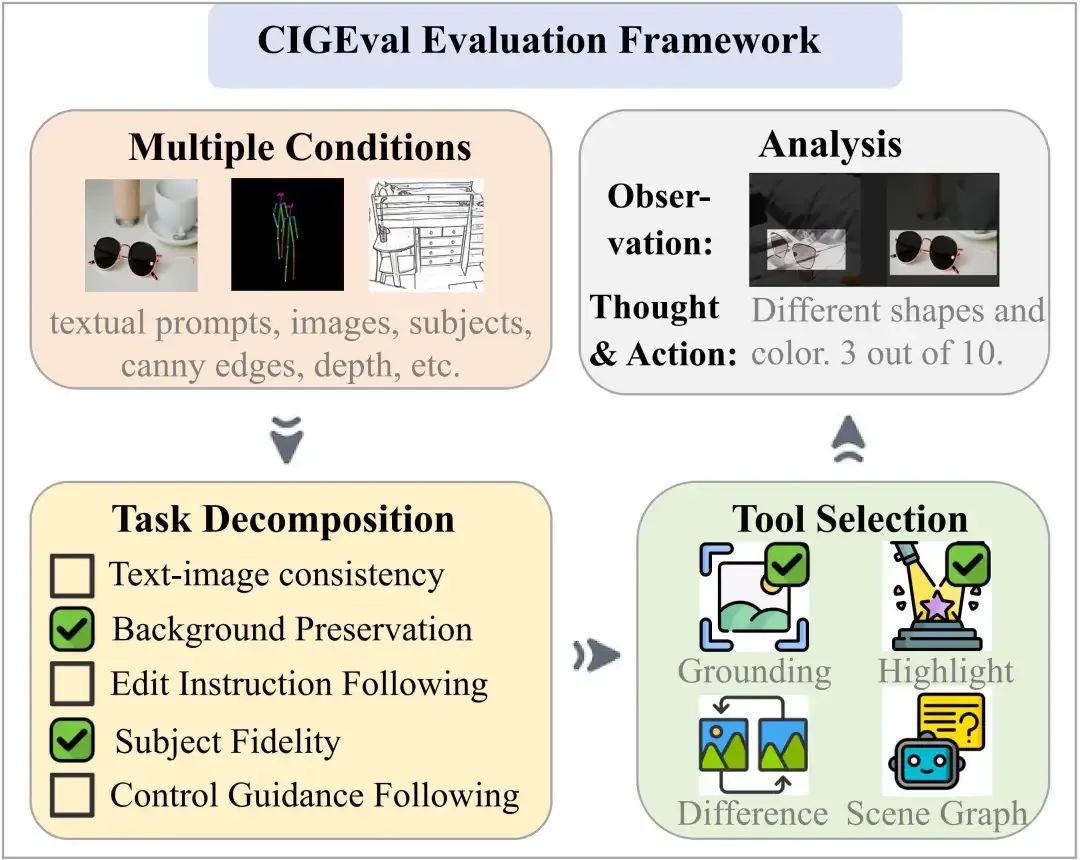
图 4:CIGEval的评估流程示例。
智能体微调
尽管 GPT-4o 驱动下,CIGEval的评估表现理想,但闭源、高成本限制了其可用性。为此,团队提出 agent tuning 策略 —— 使用 GPT-4o 构造评估轨迹,并用这些数据对开源小模型(7B)进行微调,从而实现能力迁移。
- 轨迹生成:用 GPT-4o 自动模拟完整评估过程,包括每步观察结果、思考路径、工具调用、评分输出;

- 数据筛选: 保留与人工评分误差 ≤0.3 的轨迹,确保高质量监督信号,最终选出 2,274 条高质量轨迹(覆盖 ImagenHub 60% 子集);
- 模型微调
:选择 Qwen2-VL-7B 和 Qwen2.5-VL-7B 作为基座,仅对“思考过程”和“工具调用动作”部分计算交叉熵损失,提升其自主评估能力。
实验:CIGEval 如何实现类人评估能力?
CIGEval 在标准评估数据集 ImagenHub 上进行系统验证:
数据集说明:
-
覆盖 7 大任务(如图像编辑、局部控制、指令遵循等); -
包含 29 个模型、4,800 张图像; -
每张图由 3 位人类评分员评估,分数范围 [0.0, 1.0]; -
共计 14,400 条人工评分,用于 Spearman 相关性评估。
核心结果:
- GPT-4o + CIGEval
:在人类相关性上达到 0.4625,接近人工评分者间的上限 0.47; - 7B 微调模型性能提升
: -
Qwen2-VL-7B-Instruct:相关性提升 76%; -
Qwen2.5-VL-7B-Instruct:相关性提升 34%。 - 对比 VIEScore
:在多主体合成、文本遵循等复杂任务上,CIGEval 显著优于 VIEScore; - 数据效率高
:仅用 2,274 条合成轨迹,CIGEval 就能让开源模型超越 GPT-4o 驱动的 VIEScore。
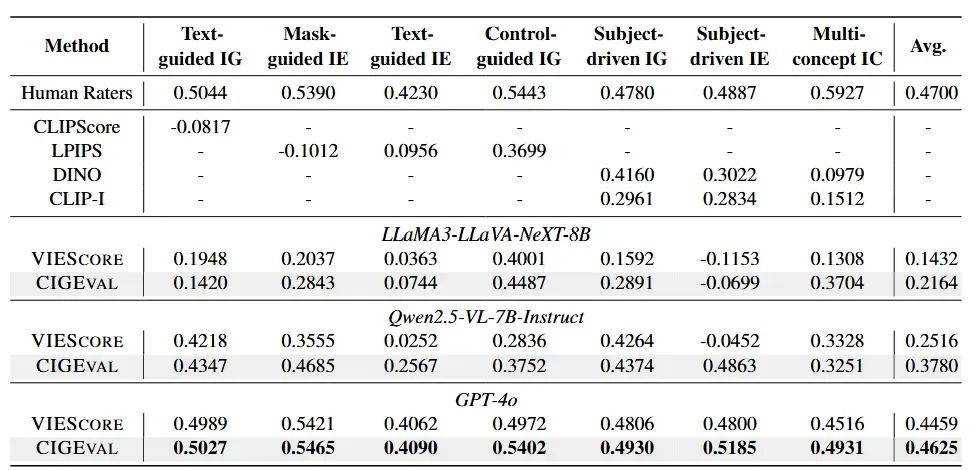
图 5:GPT-4o 驱动的CIGEval实现了与人类评估者的高相关性,当使用不同模型作为底层 LMM 时,CIGEval的表现始终优于VIEScore。
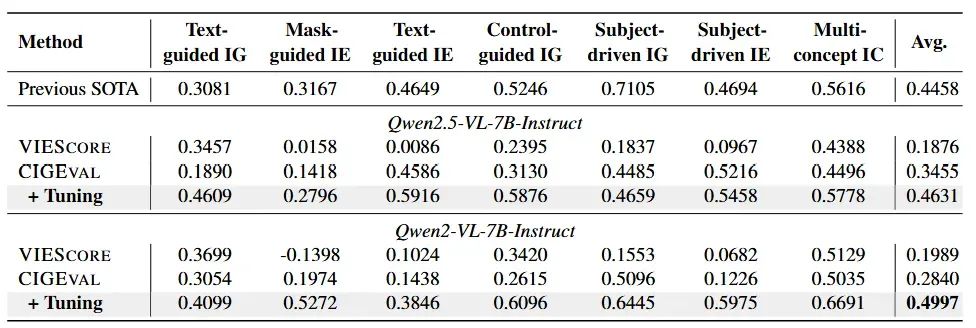
图 6:在多个评估任务中,微调后的 Qwen 系列模型与 CIGEval 框架结合后的表现显著提升,与闭源 SOTA 方法拉近差距甚至反超。
评估案例
在多物体场景中,VIEScore 常常无法对目标物体进行精准对比。例如图中案例,原图为白色花朵,生成图中则为红花,VIEScore 仍错误地判断为高度相似。而 CIGEval 通过工具链式推理,首先定位目标花朵区域(Grounding),再借助高亮差异(Highlight)明确形状与颜色变化,最终准确识别图像偏差,实现更贴近人类感知的评估效果。

图 7:CIGEval 检测颜色细节的示例。
在背景不变性评估任务中,VIEScore 往往难以捕捉图像中背景区域的细微变更,导致对明显差异视而不见。而 CIGEval 通过引入 Scene Graph 工具,构建图像整体结构的语义表示,能够精准识别生成图与原图在场景构成上的差异,成功发现背景被过度修改的情况。

图 8:CIGEval 理解图像整体结构与元素细节的示例。
CIGEval 构建的多工具链条可无缝扩展至更多真实场景下的复杂生图任务。例如,通过引入 OCR 工具,CIGEval 能精准判断图像中文字是否准确符合条件要求,进一步提升在文本生成一致性维度的评估能力。

图 9:OpenAI 官网展示的 GPT-4o 图像生成案例评估结果。
结语:CIGEval 不止是一个框架,更是图像评估范式的进化
CIGEval 展现出一种全新的图像评估范式:
- 细粒度推理驱动而非单一打分
:通过多工具组合实现可解释、多维度分析; - 任务拆解与智能体调度机制
:提升在复杂条件下的泛化能力; - 可迁移至轻量模型
:仅用 2K 轨迹数据就可将 7B 模型调优至类 GPT-4o 水平。
未来,CIGEval 所代表的 Agentic Evaluation Paradigm 有望在更多多模态生成任务(如视频编辑、多视角合成、图文问答)中发挥关键作用,推动模型从“能生成”走向“能理解与评估”。
参考文献Imagenhub: Standardizing the evaluation of conditional image generation models. ICLR 2024.VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation. ACL 2024.Agent-FLAN: Designing data and methods of effective agent tuning for large language models. ACL 2024.LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation. NeurIPS 2023.MultiSkill: Evaluating large multimodal models for fine-grained alignment skills. EMNLP 2024.
(文:PaperAgent)