

新智元报道
新智元报道
【新智元导读】最近,30位世界顶尖数学家亲自出马,在UC伯克利对OpenAI o4-mini展开「围剿」,两天连出教授级难题,结果却当场集体「破防」!有人直言:这个AI,的确已接近数学天才的水平。曾经以为AGI遥遥无期,如今仿佛只剩临门一脚了……
AI做数学,到底有多强?
就在最近,30位世界著名数学家齐聚UC伯克利,希望在一次秘密数学会议上超越AI。
在连续两天用教授级难题轰炸这个AI后,研究者们惊愕地发现,它居然能解除一部分这世界上最难的可解问题!
其中一位数学家当场折服,直言这些模型已经接近了数学天才的水平。


在五月中旬的一个周末,一场秘密数学峰会悄然召开。
三十位全球顶尖数学家与一个推理聊天机器人展开对决,后者需要解答专家们专门设计的难题。
结果如开头所见,数学家们彻底服了。
本次参赛的这个机器人,背后就是OpenAI的o4-mini,它已经能进行极其复杂的推理。
当然,它并不是世界上唯一有此能力的模型,谷歌的Gemini 2.5 Flash也具备相似的能力。
为什么o4-mini做起数学题来,能这么强?
这是因为,它是基于专门的数据集训练,并获得了更强的RLHF。这种方法,就能让它比传统的LLM更深入地钻研复杂数学问题。

而训出o4-mini后,OpenAI也一直十分关注它的解题能力。
为了追踪o4-mini的进展,OpenAI此前曾委托非营利组织Epoch AI设计300道解法尚未公开的数学题,专门来考验大模型。
这些题的亮点就在于,因为解法并未问世,就绝不可能存在于训练数据中。
果然,当Epoch AI用这些与训练数据截然不同的问题去测试几款推理模型时,它们几乎全部翻车了。
即使表现最好的模型,解出率也不到2%。
LLM做数学,真的不行么?Epoch AI没有放弃探索。
2024年9月,Epoch AI 聘请了刚获得数学博士学位的Elliot Glazer,参与到一个代号为FrontierMath的全新新基准测试项目中。

这个项目的目的,就是收集不同难度登机的全新数学题。其中,T1-T3分别覆盖本科、研究生及研究级别的挑战。
结果,o4-mini让人刮目相看。
到2025年2月,Glazer发现,o4-mini竟然能解出约20%的题目!
接着就在今年5月,Epoch AI还举办过一场竞赛,邀请了约40位数学精英,分成8组,每组由学科专家和优秀本科生组成。
他们要与AI一同在陶哲轩等人提出的FrontierMath基准上,展开终极对决。
比赛一共23题,限时4.5小时,实验最终得出:
o4-mini-medium碾压人类平均水平(19%),解决了约22%题目。
不过,o4-mini能够解决的问题,至少被一组数学家团队破解。由此,人类团队总体上解决了约35%的题目。
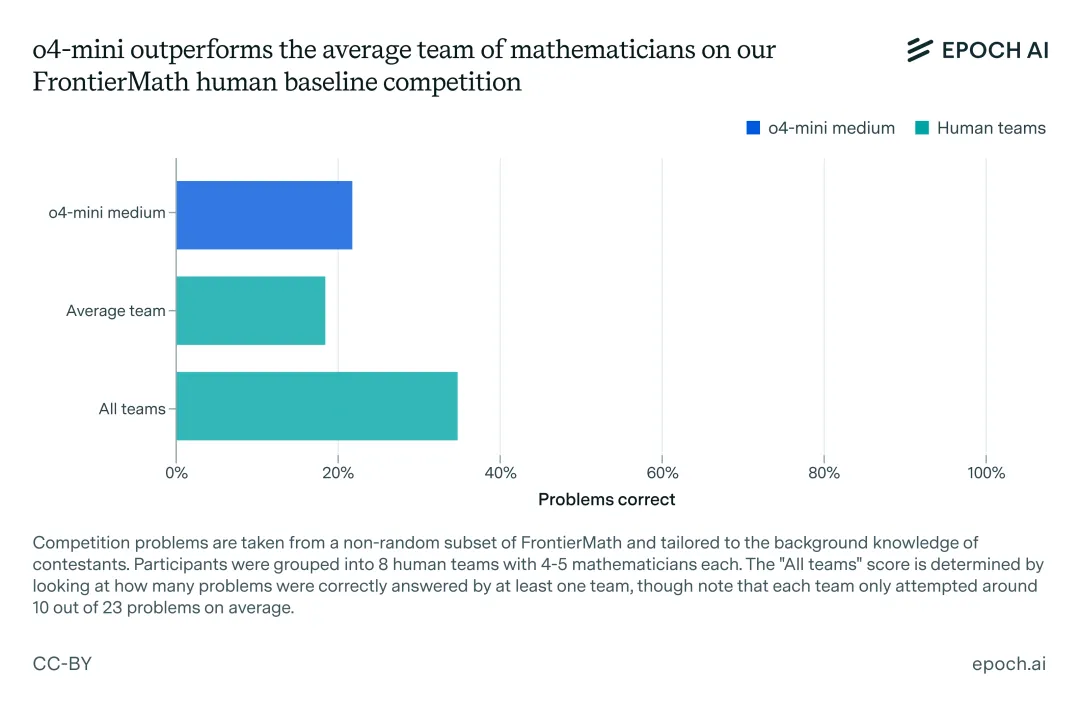
结果显示,o4-mini一共击败六组团队,在数学领域展现了惊人的潜力。
随后,他开始着手进行第四等级的测试——这次,要找出100道即使对专业数学家也极具挑战性的难题。
放眼全球,能提出这种问题的人寥寥无几,更不用说给出解答了。
为此,他要求了全球顶尖的数学家,要求他们必须签署保密协议,甚至只能通过加密通讯应用Signal交流。
因为他担心,如果用电子邮件这类传统的联络方式,有可能就会被LLM扫描到,无意中成为训练数据,从而污染整个测试数据集。
由于采用的方式格外严谨,起初项目的进展十分缓慢。
为了加快进度,Glazer推动Epoch AI 在5月17日(周六)和18日(周日)这两天,举办了这场线下会议。
在会上,数学家们将敲定最后一批最高阶的数学难题。
弗吉尼亚大学数学家、会议领导者兼评委Ken Ono将30名与会者分为六人一组。

在为期两天的会议中,这些顶尖学者需要相互比拼,看谁能设计出自己能解、却又能难倒 AI推理机器人的题目。
这个项目的奖励,也是十分诱人。
o4-mini每解不出一道题,该题的出题人便能获得7500美元的奖励。
结果谁都没想到,o4-mini给了数学家们致命一击!
在周六深夜,全场数学家,都感觉十分挫败——o4-mini出人意料的数学天赋,直接让整个小组的努力付诸东流。
Ono出了一道题,是他专业领域内的专家都公认的数论开放性问题,可以说是一道非常不错的考题,已经达到了博士生的水平。
他充满信心地把这道题给了o4-mini,结果在接下来的十分钟里,他直接遭受了暴击!
只见o4-mini如行云流水一般,实时演算出了完整的解法,还同步展示出了自己的推理过程。
它先花了两分钟,检索并吃透了相关领域的文献,然后在屏幕上写道,为了学习,它想先尝试一个简化的「玩具」版本。
几分钟后,它写道,自己已准备好解决那个更难的原题。
又过了五分钟,o4-mini 给出了一个正确却又俏皮得意的解答。
Ono描述道:它开始变得得意洋洋,甚至还加上一句,「无需引用,因为这个神秘数字由我算出!」
大受打击的Ono在周日一大早就赶紧登上Signal,向所有与会者通报了情况。
我完全没料到,要跟这样的LLM交手,也从未在模型中见过如此强大的推理能力。这分明是科学家的工作方式。这太可怕了。
最终,团队还是成功找到了10道难倒机器人的题,但AI的惊人能力,仍然让所有研究人员惊叹不已。
Ono感觉,与它共事就好像与一位「强大的合作者」协作。
伦敦数学科学研究所的数学家、AI数学应用先驱之一的Yang Hui He说:「这是一个顶尖优秀的研究生才能做到的事——不,实际上它做得更多。」

而且,o4-mini的速度也令人惊异。它远远超越了专业的数学家,人类专家需要数周甚至数月才能完成的工作,它只需要几分钟。
不仅如此,这次o4-mini的进步,也给人类敲响了警钟。
Ono和He都担心,o4-mini给出的结果可能会被人们过度信赖。
「证明方法有归纳法、反证法,现在又多了个恐吓法。」Yang Hui He说。
「当某人用足够权威的口吻说话时,人们会感到敬畏。我认为o4-mini已经掌握了恐吓式证明的精髓,因为它说每句话时都带着不容置疑的自信。」
会议临近结束时,整个团队也开始思考,数学家的未来将何去何从。
讨论转向了那个无法回避的T5——那些连最顶尖的数学家也无法解决的问题。
如果最终,AI达到了那个层次,那么显然,数学家的角色将经历剧变。
到那时,数学家或许将转向只负责提出问题,并与推理机器人互动,引导它们发现新的数学真理,就像教授指导研究生一样。
因此,Ono预测,在高等教育中培养创造力,将是让数学这门学科薪火相传的关键。
「我一直告诉我的同事们,那种认为AGI永远不会到来,认为它不过是台计算机的想法,是大错特错的。」Ono说。
「我不想渲染恐慌,但在许多方面,这些LLM已经超越了我们世界上绝大多数最优秀的研究生。
其实AI做数学研究的这种超绝能力,陶哲轩早就心知肚明了。
最近,他一直在社交平台上做出密集分享,给我们汇报AI解数学题的惊人进展。
比如就在几天前,他刚刚分享了这个消息。
一道封尘18年的数学难题,在短短30天内被AlphaEvolve与人类联手三度突破!

6月2日,Fan Zheng在arXiv亮出的最新论文——又又又一次把和差集指数θ纪录往上推了0.000027,从1.173050提升到了1.173077。
0.000027——一个在显微镜下才分辨得出的跨度,却把加法组合学的天花板又往上顶了一寸。

论文地址:https://arxiv.org/abs/2506.01896
如此迅速、连续的取得进展,都离不开数学家与AI(AlphaEvolve)的相互配合。
这种突破让陶哲轩都惊叹:「对我而言,这是一个引人入胜的例证。」
陶哲轩认为,这展示了未来的数学研究中,高度计算机辅助、中度计算机辅助与传统「纸笔」方法之间将如何相互作用。
这些范式各有优劣。
例如,当前的AlphaEvolve还极难用上后续论文中使用的渐近构造;但另一方面,若没有AlphaEvolve的暴力搜索,人类方法也很难发现这些改进的切入点。
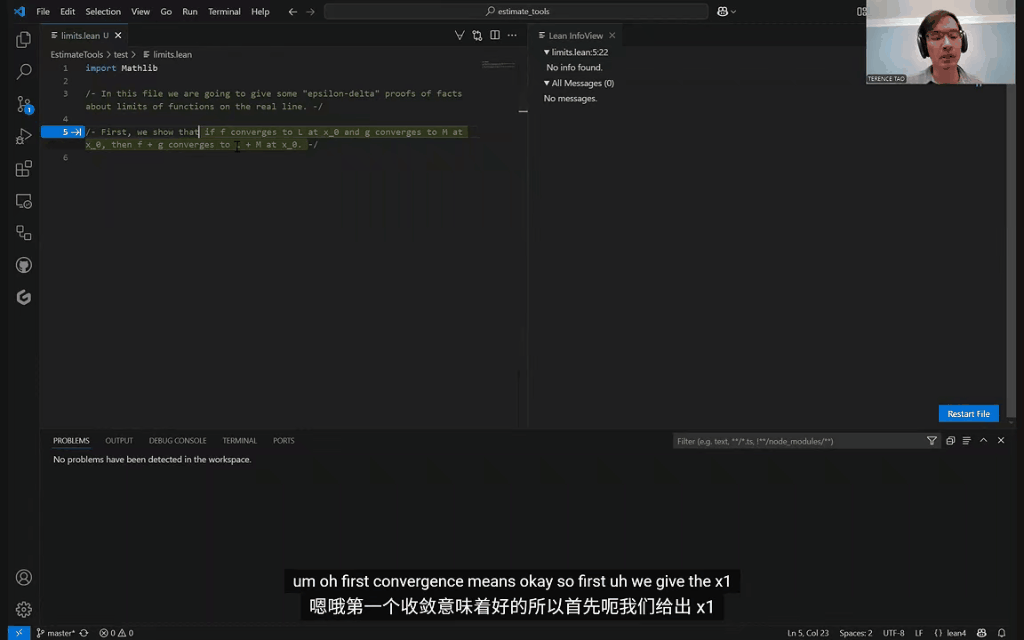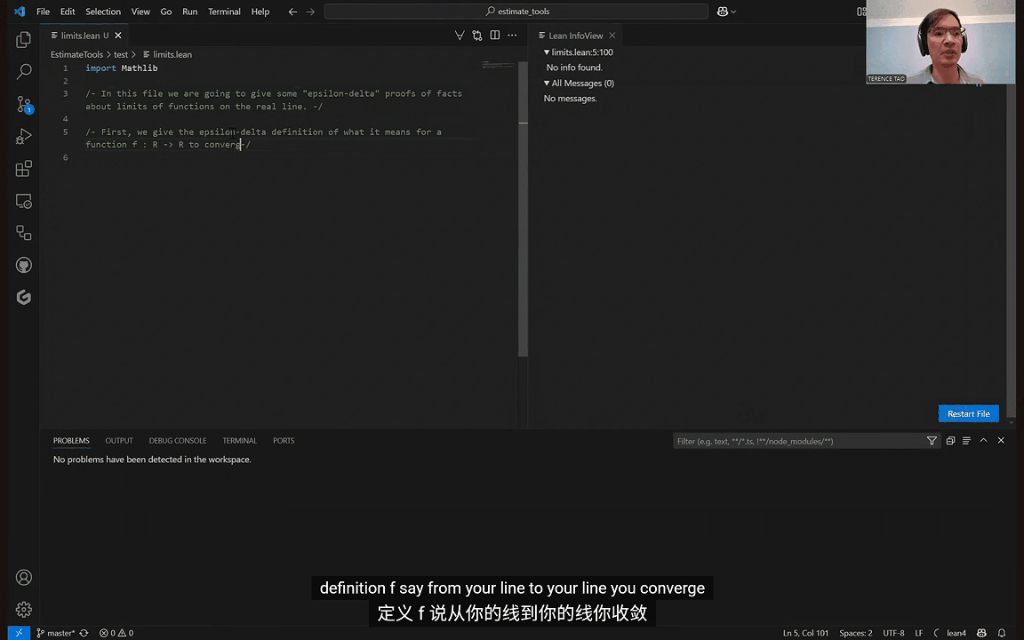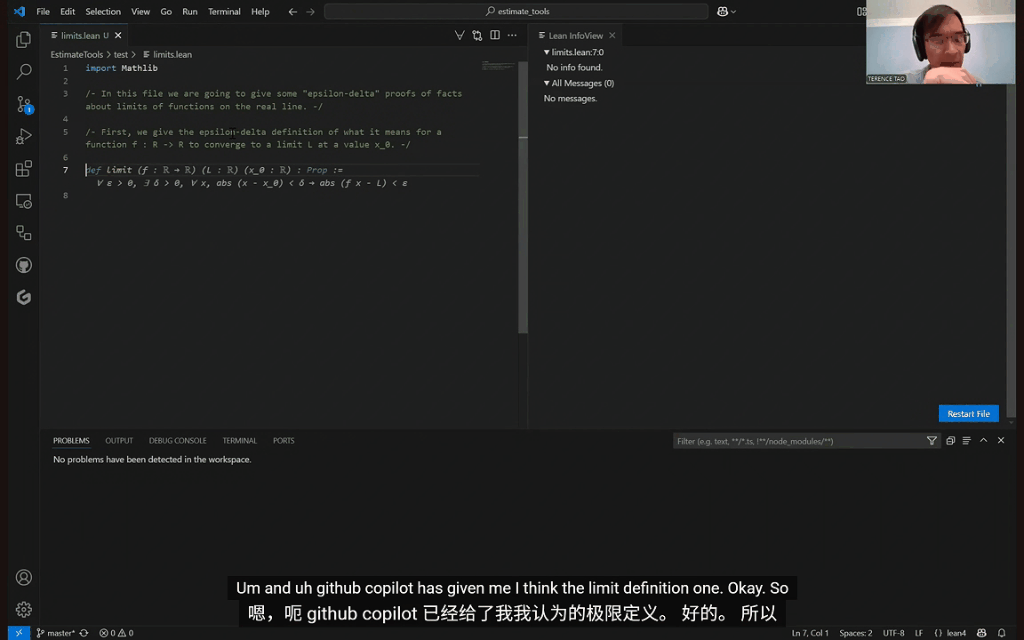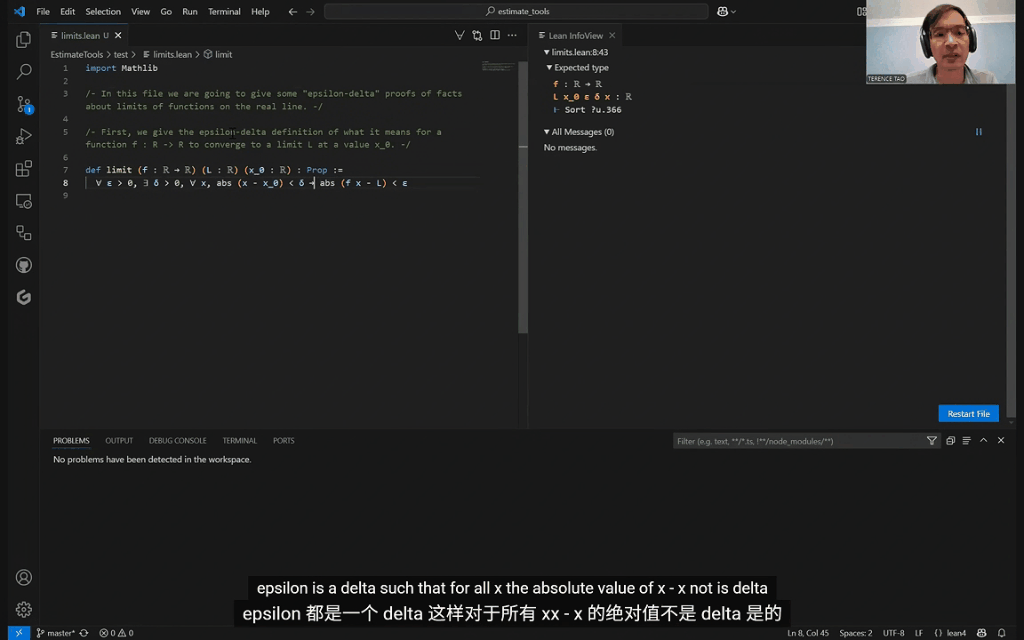
而在上个月,陶哲轩还刚刚联手AI,挑战了分析学经典中的「ε-δ」极限问题。
GitHub Copilot在帮助新手入门和处理基础任务时表现得相当不错。
它能帮助用户快速上手Lean语言,提供语法提示,并智能补全基本定义和声明。
在比较简单的证明,比如函数极限的和定理中,Copilot还能准确预测证明结构和关键步骤,表现得就像个得力助手一样。
但当证明变得复杂时,Copilot的短板就暴露出来了。
比如在处理函数极限的差和积定理时,它在复杂的代数推导、寻找合适的数学引理(比如与绝对值相关的引理)等方面显得力不从心。
Copilot有时还会出现「幻觉」,生成压根不存在的策略,或者犯一些低级错误,导致证明过程乱成一团。
这时,陶哲轩不得不亲自出马,修正错误,甚至完全接管证明。
但总之,现在LLM的发展,已经让我们愈发接近曾经陶哲轩的那个预言了——
在2026年,AI将与搜索和符号数学工具相结合,成为数学研究中值得信赖的合著者。
(文:新智元)