
今天是2025年6月8日,星期六,北京,晴
我们继续回到GraphRAG的话题,从现有典型的9个GraphRAG方案回顾、GraphRAG方案效果对比Benchmark、GraphRAG能否提升所有类型问题的表现三个话题来看,挺好的一个总结。
一、现有典型的9个GraphRAG方案回顾
先看看当前九种GraphRAG方案

1、RAPTOR
“RAPTOR: Re-cursive abstractive processing for tree-organized retrieval,https://arxiv.org/abs/2401.18059
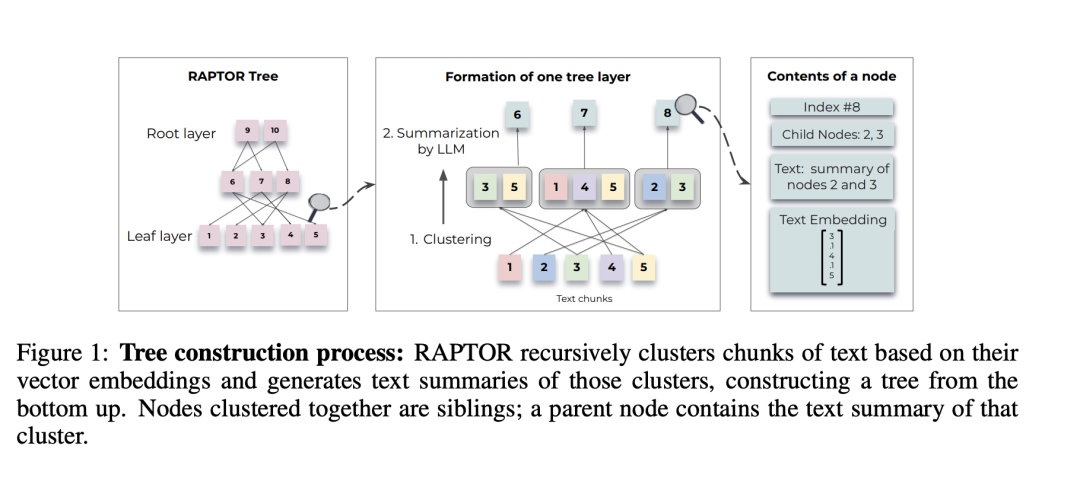
主要思想是递归构建树形文本索引,通过分层聚类与摘要实现多粒度检索。技术亮点在于自底向上递归聚类文本块,生成多层级抽象摘要(叶节点=原文,上层=概括),检索时从树中提取不同抽象层的内容,增强长文档理解。
2、LightRAG
lightrag: Simple and fast retrieval-augmented generation,https://arxiv.org/abs/2410.05779
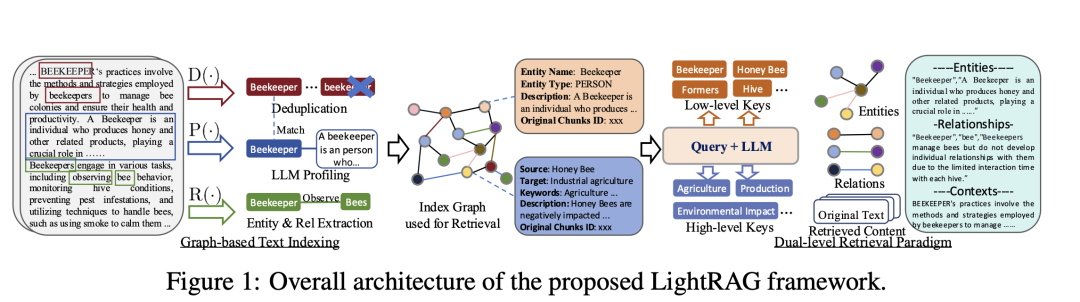
核心是使用LLM为每个实体节点和关系边生成文本键值对,索引键是用于高效检索的词或短语,值是总结相关信息的文本段落,在检索准确性和效率方面比GraphRAG现有方法有显著提高。
3、GraphRAG
From local to global: A graph rag approach to query-focused summarization, https://arxiv.org/abs/2404.16130
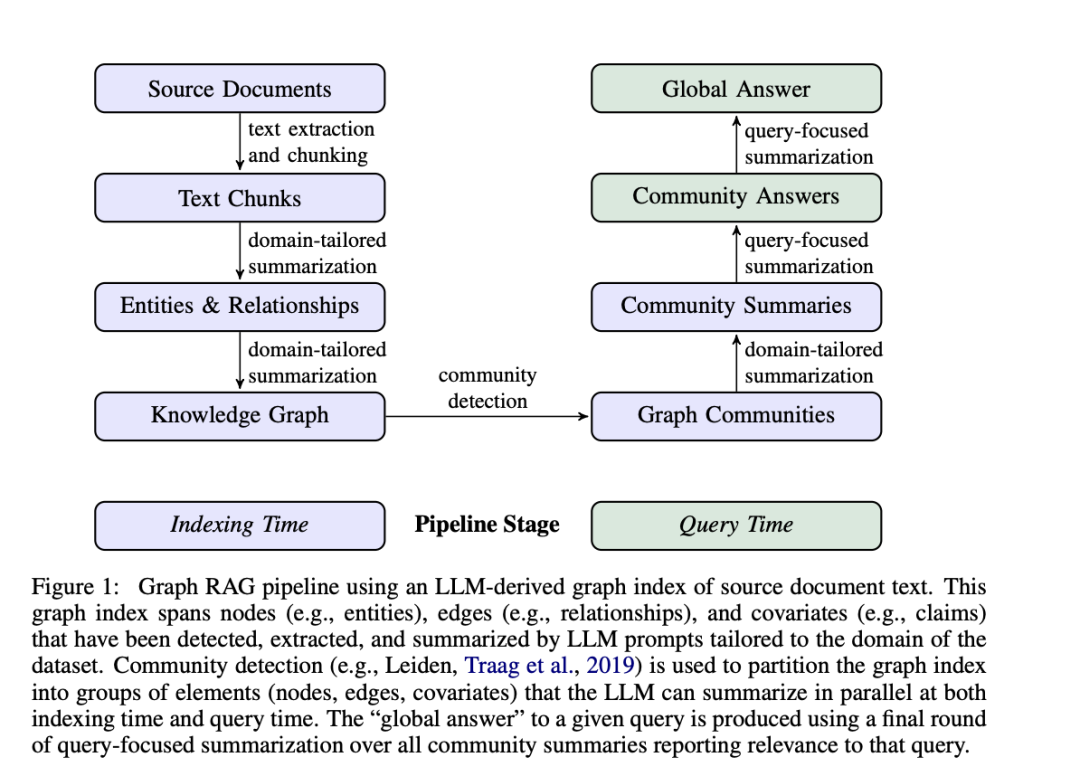
主要思想是用知识图谱结构组织文本索引,支持全局语义理解,构建实体知识图谱,预生成社区摘要(实体群组的概括),检索时融合相关社区摘要,再生成最终答案。
4、G-Retriever
G-retriever:Retrieval-augmented generation for textual graph understanding and question answering,https://arxiv.org/abs/2402.07630
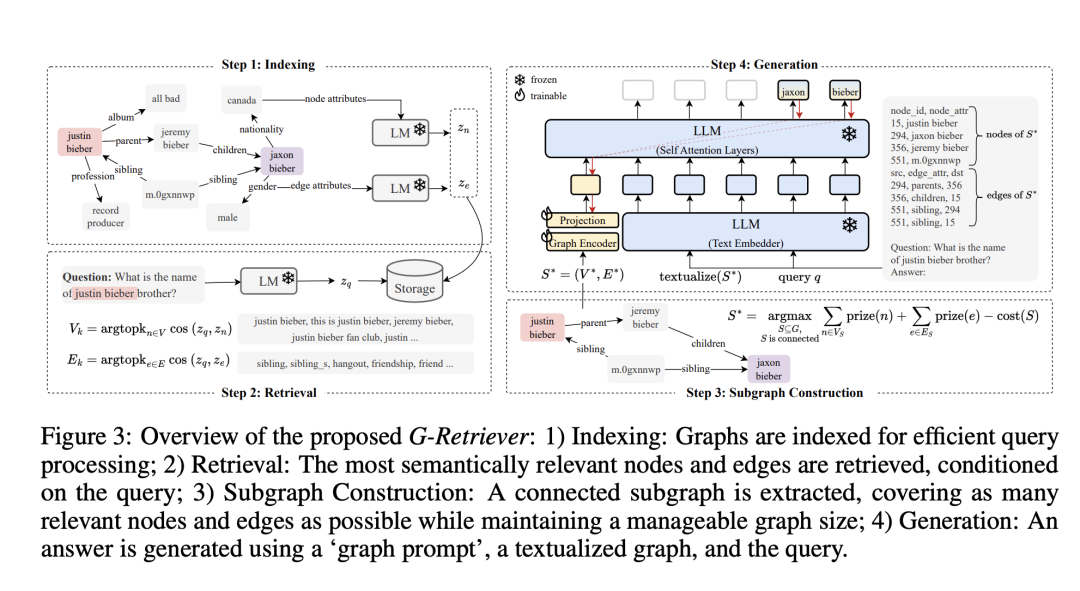
主要思想是针对文本属性图的问答,将RAG与图结构结合。用图神经网络(GNN)学习文本节点表示,增强语义理解。检索时建模为带权斯坦纳树问题,高效定位相关子图。
5、HippoRAG
Hipporag: Neurobiologically inspired long-termmemory for large language models,https://arxiv.org/abs/2405.14831
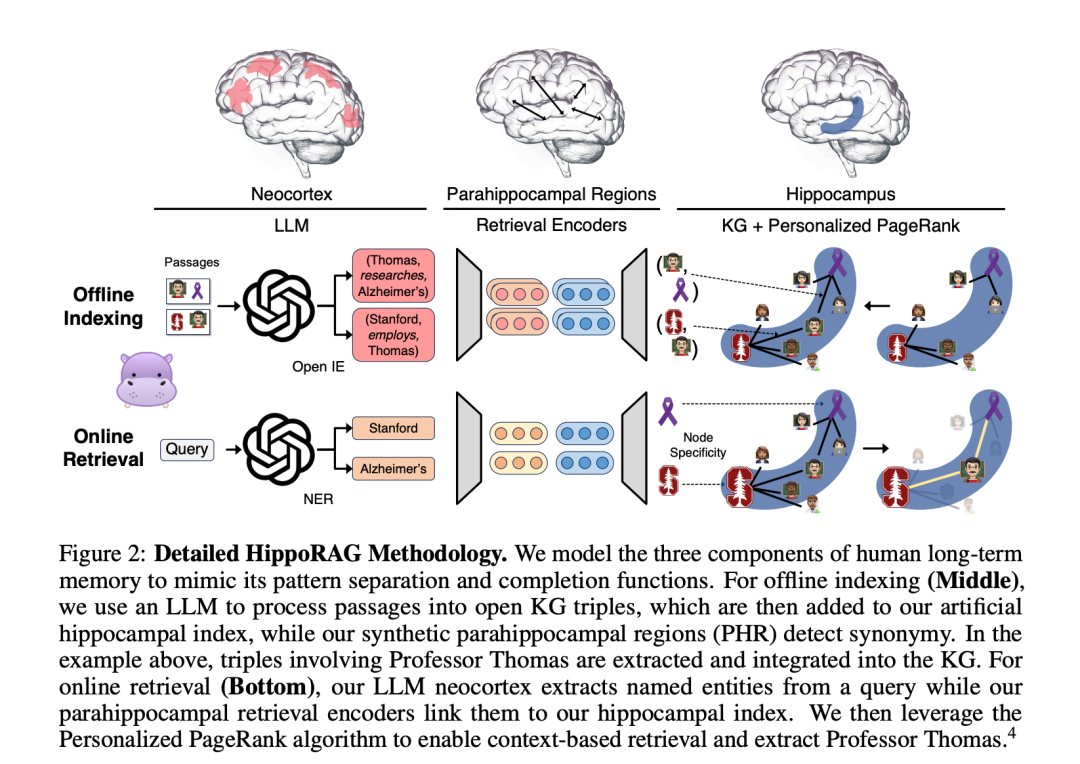
主要思想是受海马体记忆机制启发,设计高效长期记忆框架。模仿大脑索引理论:LLM(新皮层)+KG(海马体)协同记忆,用PageRank算法优化知识检索路径。
6、GFM-RAG
Gfm-rag: Graph foundation model forretrieval augmented generation,https://arxiv.org/abs/2502.01113
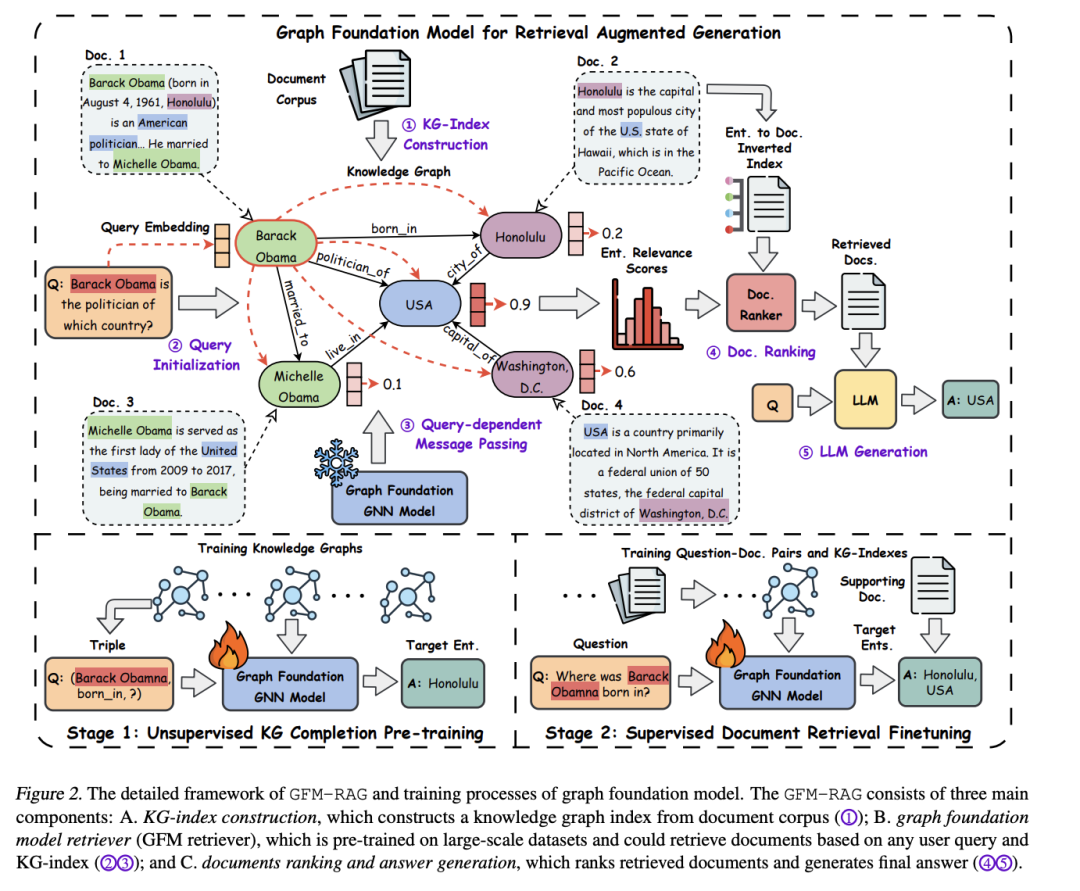
主要思想是训练图基础模型(GFM)统一图检索增强,预训练GNN模型(8M参数)跨60个知识图谱,无需微调即可迁移。建模查询-知识复杂关系,提升多源知识融合能力。
7、DALK
DALK: Dynamic co-augmentation of LLMs and KG to answer Alzheimer‘s disease questions with scientific literature,https://arxiv.org/abs/2405.04819
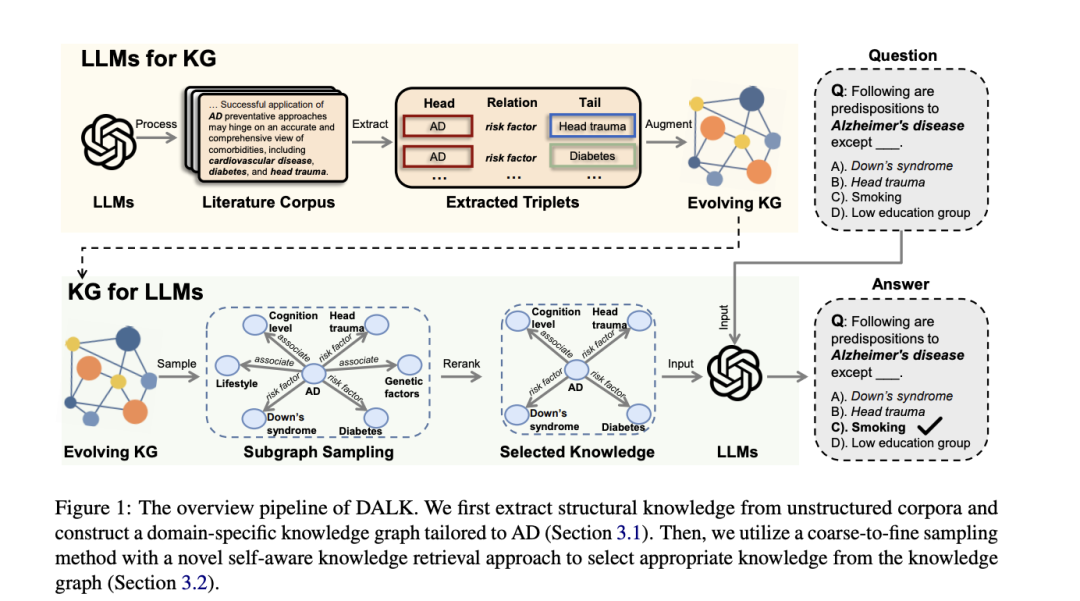
主要思想是LLM与KG动态协同增强,专注阿尔茨海默病领域。LLM构建领域KG,从科学文献抽取AD相关知识,并进行粗到细检索,自感知知识选择+上下文增强推理。
8、KGP
Knowledge graph prompting for multidocument question answering,https://arxiv.org/abs/2308.11730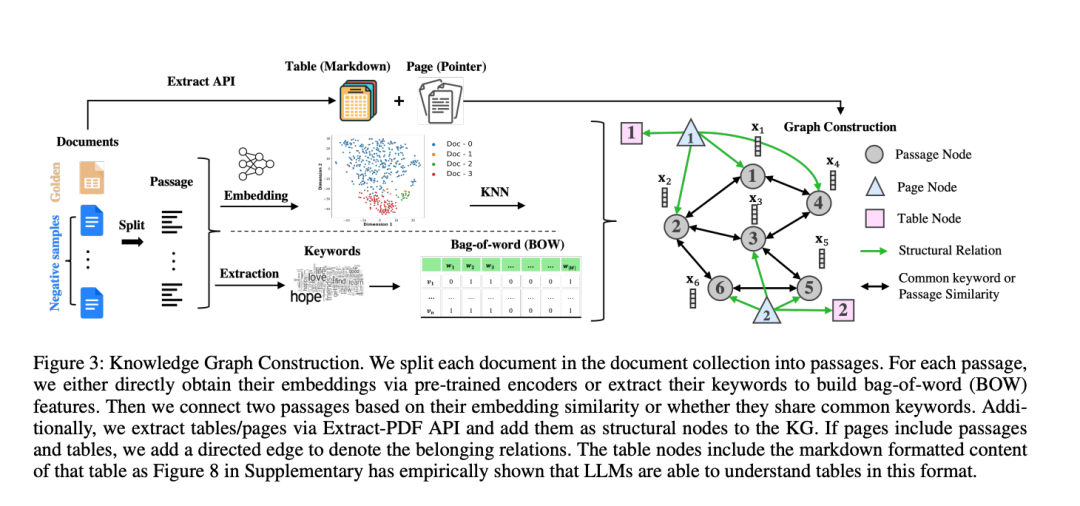 用KG提示解决多文档问答(MD-QA)的结构关联问题。核心在于图构造,节点=文本/结构(如表格),边=语义/结构关系。以及进行图遍历代理,LLM驱动路径搜索,逐步收集证据。
用KG提示解决多文档问答(MD-QA)的结构关联问题。核心在于图构造,节点=文本/结构(如表格),边=语义/结构关系。以及进行图遍历代理,LLM驱动路径搜索,逐步收集证据。
9、ToG
Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph,https://arxiv.org/abs/2307.07697
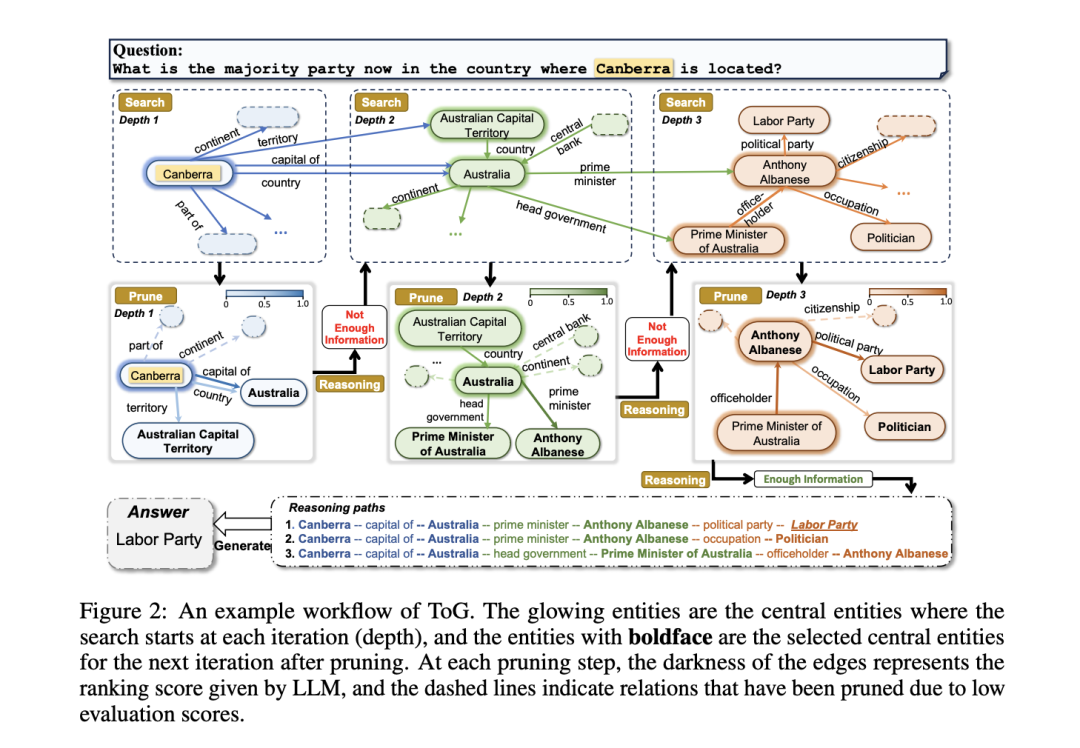
亮点在于LLM⊗KG范式,LLM作为代理探索KG实体关系链,路径可追溯,支持知识纠偏(专家反馈)。
二、GraphRAG方案效果对比Benchmark
目前对GraphRAG模型的评估主要依赖于传统的问答数据集,在问题和评估指标方面的局限性,无法全面评估GraphRAG模型所带来的推理能力提升,所以可以搞个专门的benchmark。
最近工作《GraphRAG-Bench: Challenging Domain-Specific Reasoning for Evaluating Graph Retrieval-Augmented Generation》(https://arxiv.org/pdf/2506.02404),涵盖了包括多项选择题、判断题、多选题、开放式问题和填空题几个推理任务,一共1018个问题。
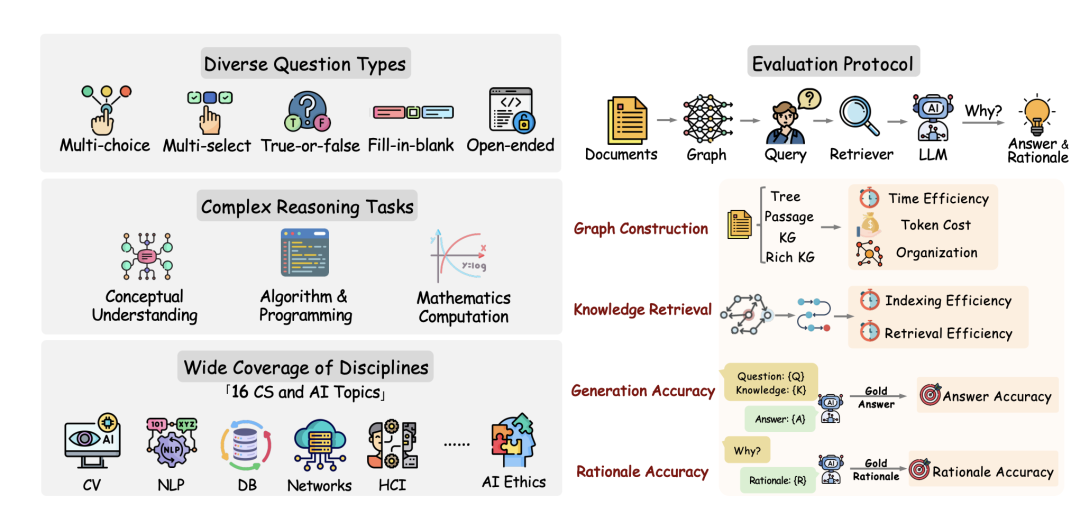
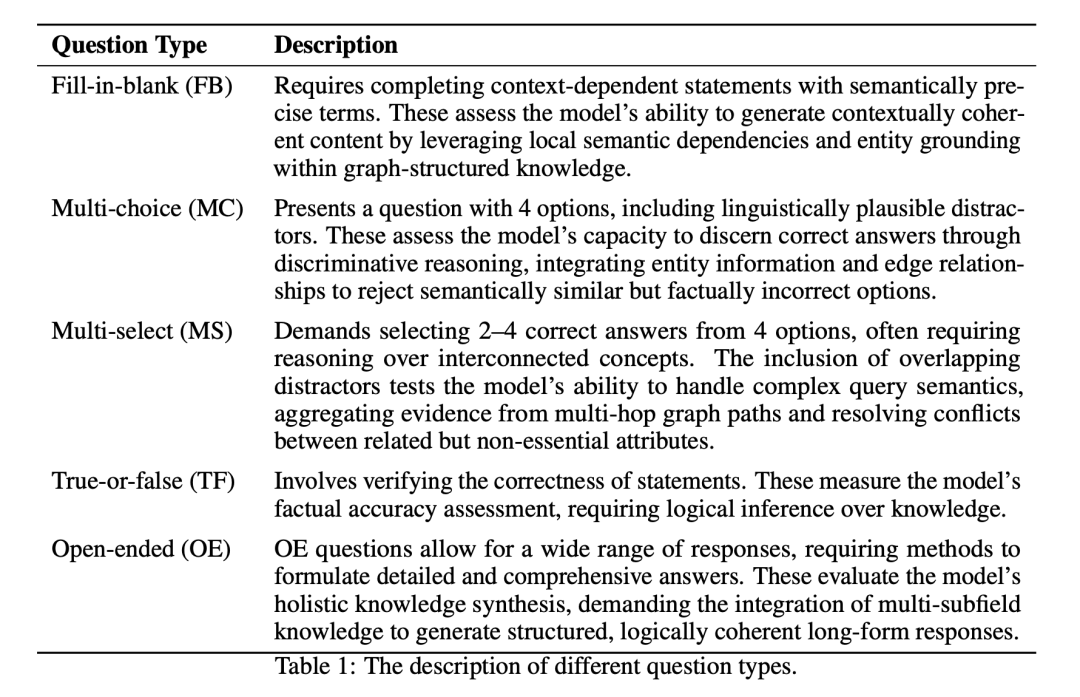
其中涉及到的几种问题类型的定义如下:
从数据的构建方式上,从20本PDF格式的核心教材中提取准确内容,应用LayoutLMv3进行多模态文档布局分析,将提取的内容组织成层次化的教材树结构,最终将教材元数据(例如,章节标题、小节划分和页码范围)映射到一个四级层次结构中:书名->章节->小节(子章节)->知识内容单元。
先看看不同Graphrag的效果对比,从图构建、知识检索两个角度进行对比。
1、图构建的对比
从三个方面评估图构建:1) 效率:构建完全图所需的时间。2) 成本:图构建过程中消耗的 token 数量。3) 组织性:构建图中非孤立结点的比例。
当前主流的图构建方法可分为四类,对应的结论如下:
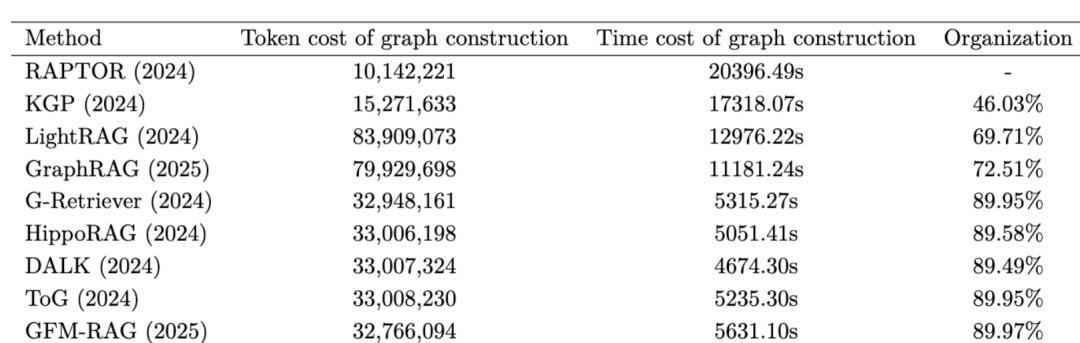
1)树结构Tree:RAPTOR采用此结构,其中每个叶结点代表一个文本块。通过利用大语言模型生成摘要并应用聚类方法,迭代创建父结点,形成层次化的树结构。产生的token数量最少,因为它仅调用LLMs进行摘要生成,但由于迭代聚类过程,所需时间最长;
2)段落图Passage Graph:KGP采用此结构,将每个文本块表示为一个结点,并通过实体链接工具建立边。段落图的token成本次优,仅调用LLMs对实体或关系进行摘要,其时间消耗第二长,主要归因于耗时的实体链接过程。段落图的非孤立结点比率最低,表明实体链接工具未能有效在大多数实体对之间建立边。
3)知识图谱Knowledge Graph:G-Retriever、HippoRAG、GFM-RAG和DALK使用此结构,借助开放信息提取(OpenIE)工具从文本块中抽取实体和关系,构建知识图谱。知识图谱的token使用量适中,需要LLMs从语料库中提取实体并从实体生成三元组,但由于在获取三元组后快速构建知识图谱,因此实现了最短的时间消耗;**知识图谱表现最佳,其非孤立结点比率保持在约90%**。
4)丰富知识图谱Rich Knowledge Graph:GraphRAG和LightRAG采用此结构,通过添加额外信息(如为结点或边生成总结性描述)来增强标准知识图谱。其消耗的token最多,因为它在标准知识图谱的基础上通过LLMs为实体和关系生成额外的描述,导致时间成本增加。图中非孤立结点的比例次优,虽然它包含了额外信息,但不可避免地引入了更多噪声。
2、知识检索的对比
从两个维度进行评估:1)索引时间,即构建用于检索的向量数据库所需的时间;2)平均检索时间,表示每次查询进行知识检索所消耗的平均时间。
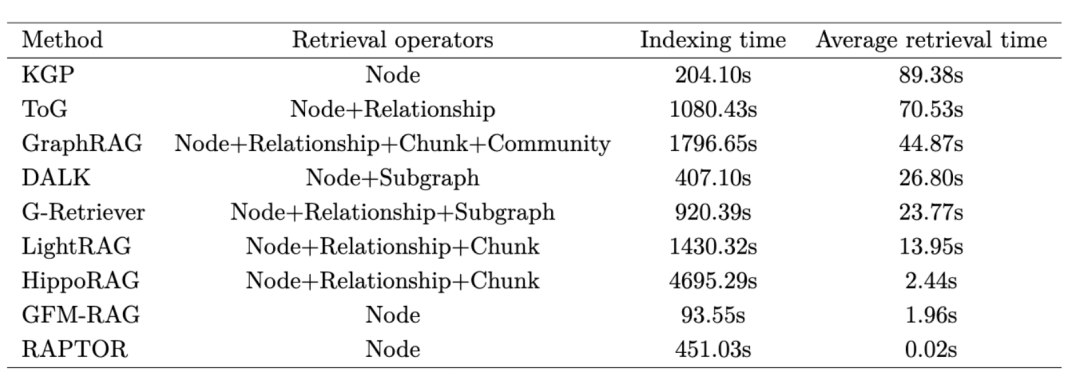
1)索引时间方面
GFM-RAG的索引时间最短,它并未构建传统的向量数据库来存储实体,而是在图构建过程中仅存储与问题对应的实体;
在使用向量数据库的方法中,KGP、RAPTOR和DALK由于存储信息最少,成本较低;ToG、G-Retriever和LightRAG的成本适中,因为关系存储本身耗时;
GraphRAG通过额外存储社区报告进一步增加了索引时间。
HippoRAG的索引时间最长,归因于其额外构建了实体<->关系和关系<->块映射。
2)平均检索时间方面
RAPTOR速度最快,其树形结构能够快速定位信息。GFM-RAG和HippoRAG紧随其后,分别利用GNN和PageRank算法进行检索;
G-retriever采用了奖赏收集斯坦纳森林算法,而LightRAG依赖于基于关系的检索,两者都引入了额外的延迟。
GraphRAG需要利用社区信息进行检索,因此耗时较长;
KGP、ToG和DALK由于在检索过程中依赖LLM调用,产生了较大的时间成本。
3、准确性的评估
在准确性方面的对比也很有意思:
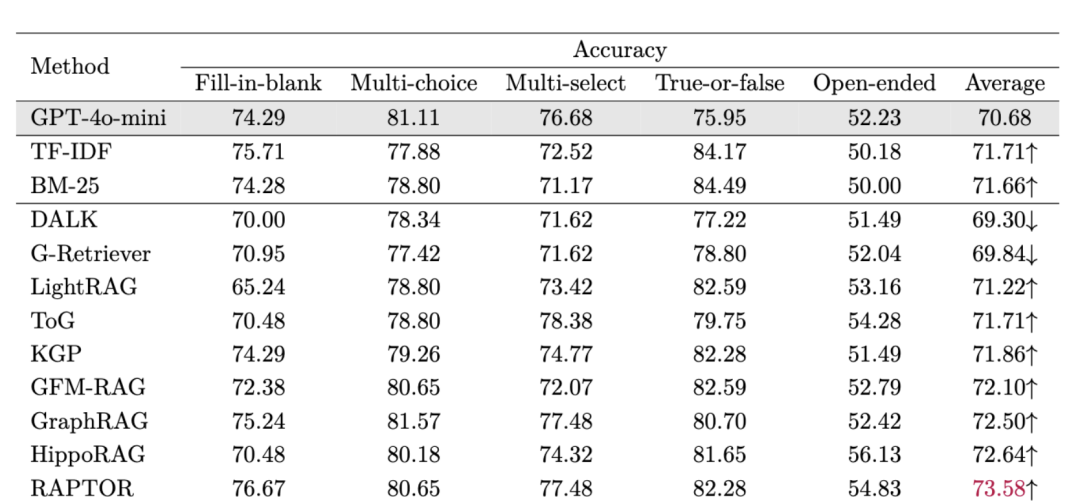
DALK和G-Retriever降低了LLM的性能;它们过度依赖结构信息而牺牲语义内容,在生成过程中引入了过多的噪声,损害了LLM的判断准确率;
LightRAG、ToG和KGP实现了轻微的性能提升,表明其检索到的内容对生成任务提供了有限的帮助;
相比之下,GFM-RAG、GraphRAG和HippoRAG通过有效整合图结构信息与块级语义,显著提升了LLM的性能:GFM-RAG利用大规模预训练获得了一个强大的基础模型,GraphRAG通过基于社区的信息优化了检索,而HippoRAG则通过PageRank算法提高了检索效率;
表现最佳的方法是RAPTOR,它通过迭代聚类构建树结构,这一设计与教科书数据的自然层次组织相契合,从而实现了高效的相关信息检索。
大多数GraphRAG方法在生成准确率上优于传统的RAG基准方法如BM-25和TF-IDF,凸显了基于图形的架构在提升生成准确率方面的实用性。
三、GraphRAG能否提升所有类型问题的表现?
1、多项选择题准确率下降
大模型(LLMs)通过在大规模语料库上进行广泛训练,内化了大量知识,这使得它们通常能够在多项选择任务中正确选择答案。
然而,GraphRAG基于检索的增强可能会引入冗余或与问题上下文关联不紧密的信息。这种检索噪声可能会干扰模型的决策能力,最终降低其在多项选择题上的准确率。
2、判断题准确率提升
判断题需要对事实或逻辑陈述进行二元判断。对于某些事实,大模型可能存在知识盲点或知识不完整,从而导致回答错误。
通过检索相关的事实证据,GraphRAG帮助模型在回答之前验证陈述。这些补充信息提高了模型在判断题上的准确率。
3、开放式问题准确性提升
开放式问题允许进行广泛的、详细的回答,这对于仅依赖内部知识的大模型来说可能是一个挑战。
GraphRAG通过提供来自外部语料库的额外上下文和事实来缓解这一挑战。检索到的信息丰富了模型的回答,提高了主题细节和表达力,并通过将答案基于明确的证据来减少幻觉现象的发生。
4、填空题准确性下降
填空题需要精确理解上下文才能正确预测缺失的词语。GraphRAG检索到的语料库往往无法精确匹配上下文,引入的噪声会降低模型在填空题上的表现。
5、多项选择题准确性下降
多选题要求从一组选项中选择多个正确答案,并且涉及对复杂选项组合的推理;如果GraphRAG的检索遗漏了相关答案选项或包含无关细节,可能会使模型感到困惑。
因此,这些题型对检索精度要求很高;除非GraphRAG的检索高度准确,否则其益处可能有限。
参考文献
1、https://arxiv.org/pdf/2506.02404
(文:老刘说NLP)