
中国科学院自动化研究所 投稿
量子位 | 公众号 QbitAI
大模型≠随机鹦鹉!Nature子刊最新研究证明:
大模型内部存在着类似人类对现实世界概念的理解。
LLM能理解现实世界和各种抽象概念吗?还是仅仅在“鹦鹉学舌”,纯粹依靠统计概率预测下一个token? 长期以来,AI社区对这一问题存在很大的分歧。
有一种猜测是,纯粹基于语言的形式(例如训练语料库中token的条件分布)进行训练的语言模型不会获得任何语义。
相反,它们仅仅是根据从训练数据中收集的表面统计相关性来生成文本,其强大的涌现能力则归因于模型和训练数据的规模。这部分人将LLM称为“随机鹦鹉”。
但现在研究证明,并非如此!
中国科学院自动化研究所与脑科学与智能技术卓越创新中心的联合团队在《Nature Machine Intelligence》发表题为《Human-like object concept representations emerge naturally in multimodal large language models》的研究。

团队通过行为实验与神经影像分析相结合,分析了470万次行为判断数据,首次构建了AI模型的“概念地图”,证实多模态大语言模型(MLLMs)能够自发形成与人类高度相似的物体概念表征系统。
研究逻辑与科学问题:从“机器识别”到“机器理解”
传统AI研究聚焦于物体识别准确率,却鲜少探讨模型是否真正“理解”物体含义。
论文通讯作者何晖光研究员指出:“当前AI能区分猫狗图片,但这种‘识别’与人类‘理解’猫狗的本质区别仍有待揭示。”
团队从认知神经科学经典理论出发,提出三个关键问题:
-
表征相似性:LLMs的物体表征是否具有与人类相似的低维结构? -
语义可解释性:大模型是否发展出可被人类理解的语义维度? -
神经对应性:AI表征是否与大脑处理物体的神经活动模式存在映射关系?
为回答这些问题,团队设计了一套融合计算建模、行为实验与脑科学的创新范式。
研究采用认知心理学经典的“三选一异类识别任务”(triplet odd-one-out),要求模型与人类从物体概念三元组(来自1854种日常概念的任意组合)中选出最不相似的选项。
通过分析470万次行为判断数据,团队首次构建了AI模型的“概念地图”。
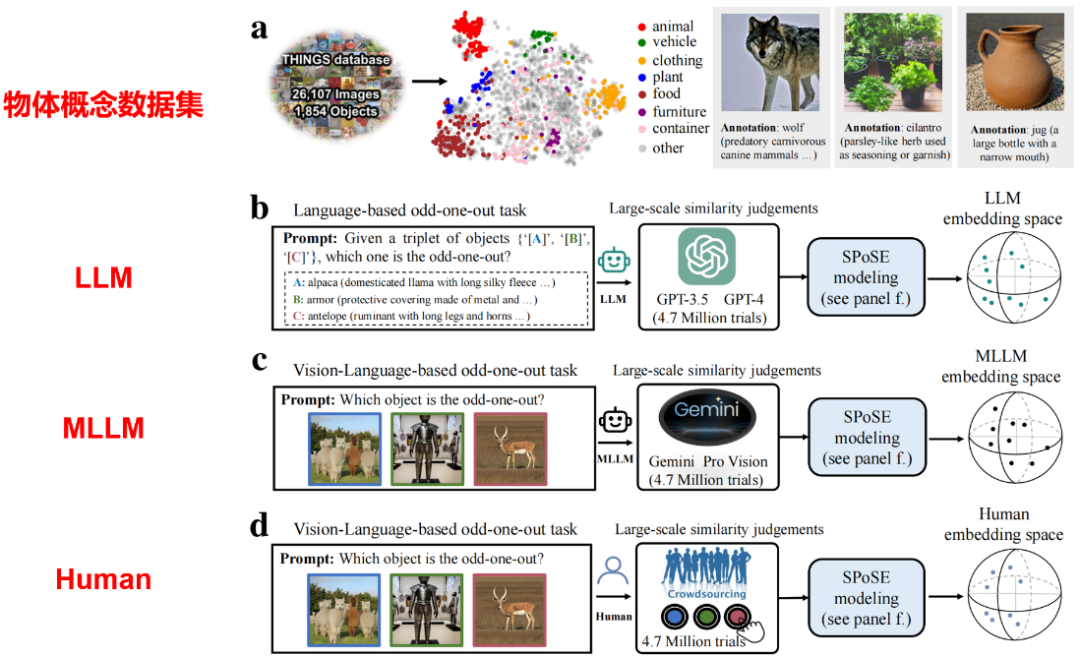
具体来说,本研究突破传统神经网络节点分析范式,首创“行为认知探针”方法:
-
机器行为学实验:将心理学实验范式迁移至AI,通过470万次三选一任务构建选择概率矩阵 -
核心认知维度提取:稀疏正定相似度嵌入算法从大模型行为数据反推其“心智空间”,避免大规模黑箱神经网络的可解释性难题 -
跨模态验证:同步对比人类行为数据、脑神经活动与大模型表征,建立三者间的定量映射关系
“我们不是通过解剖AI模型内部的海量神经元来理解它,而是让AI像人类一样做选择题,从而逆向破解它的认知系统。”论文第一作者杜长德解释道。这种方法为研究闭源商业模型(如GPT-4)的认知特性提供了可行路径。
核心发现:AI的“心智维度”与人类殊途同归
核心发现有以下几点。
1、低维嵌入揭示普适认知结构
研究采用稀疏正定相似性嵌入方法,从海量大模型行为数据中提取出66个核心维度。
令人惊讶的是,纯文本训练的ChatGPT-3.5与多模态Gemini模型均展现出稳定的低维表征结构,其预测人类行为选择的准确度分别达到噪声上限的87.1%和85.9%。这暗示不同架构的AI模型可能收敛到相似的认知解决方案。
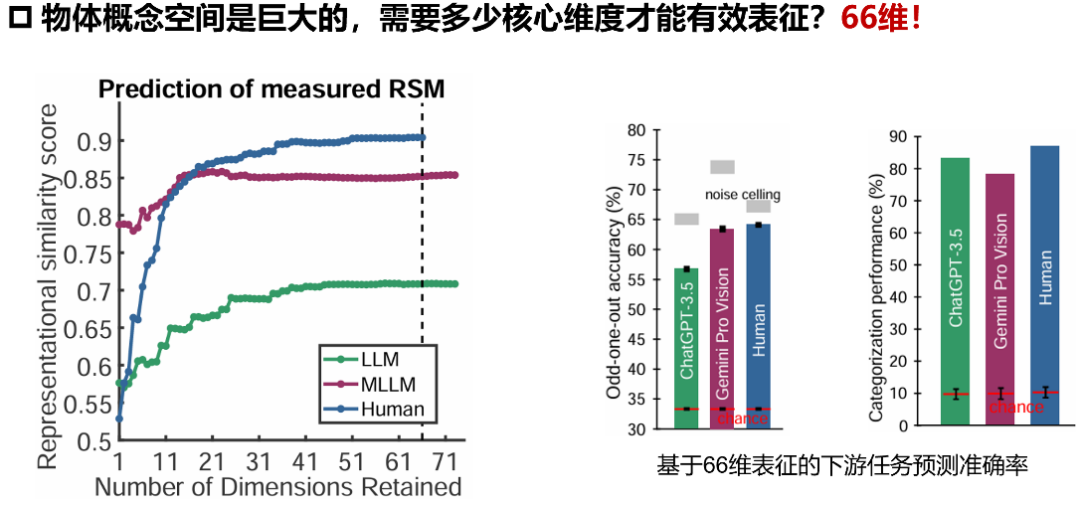
2、涌现的语义分类能力
在没有显式监督的情况下,模型自发形成了18个高级物体概念类别(如动物、工具、食物)的聚类(图3)。
MLLM的分类准确率达78.3%,接近人类的87.1%,显著高于传统视觉模型(包括监督学习、自监督学习等模型)。
值得注意的是,模型表现出与人类一致的“生物/非生物”“人造/自然”分类边界,印证了认知神经科学的经典发现。

3、可解释的认知维度
研究为AI模型的“思考维度”赋予语义标签。例如:
-
语义类别相关的维度:如动物、食物、武器或车辆

-
感知特征相关的维度:如硬度、价值、厌恶度、温度或纹理

-
物理成分相关的维度:如木材、陶瓷、金属、其他材料

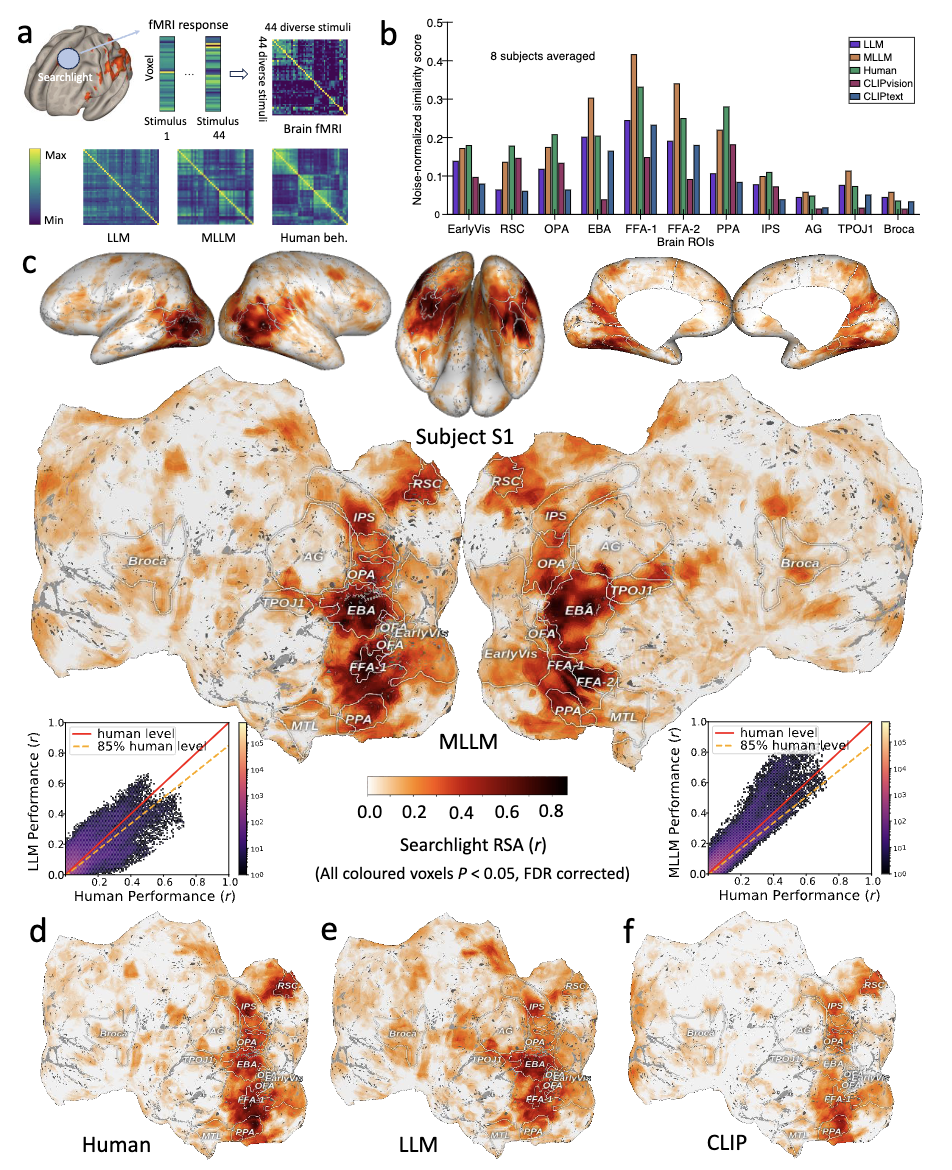
4、与大脑神经活动的惊人对应
通过分析7T高分辨率fMRI数据(NSD数据集),团队发现MLLM的表征与大脑类别选择区域(如处理面孔的FFA、处理场景的PPA、处理躯体的EBA)的神经活动模式显著相关。
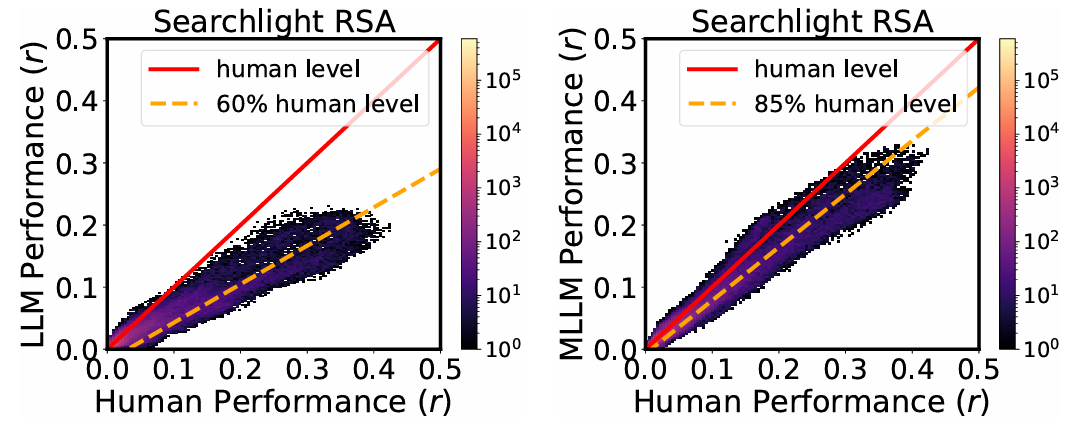
在梭状回面孔区(FFA),MLLM的低维“心智”嵌入预测神经活动的准确度达到人类水平的85%,远超纯文本模型(60%)。
这一发现为“AI与人类共享概念处理机制”提供了直接证据。

5、哪个模型在行为选择模式上更接近人类?
研究还对比了多个模型在行为选择模式上与人类的一致性(Human consistency)。
结果显示,大模型(如ChatGPT-3.5、Gemini_Pro、Qwen2_VL)和多模态模型(如CLIP)在一致性方面表现更优,而传统单模态模型(如 ResNet18、VGG16、AlexNet、GPT2)一致性得分较低。
此外,随着模型性能的提升(如从ChatGPT-3.5到GPT-4),一致性得分显著提高,但仍有一定提升空间,尚未达到理论上限(Noise ceiling)。
总体而言,大模型和多模态模型在模拟人类行为选择模式上更具优势。

6、人类和大模型做决策时所依赖的主要维度有什么不同?
下图展示了人类与LLM及MLLM在决策判断任务中所依赖的关键维度的差异。
通过一系列三元组选择示例,揭示了人类在做决策时更倾向于结合视觉特征和语义信息进行判断,而大模型则倾向依赖于语义标签和抽象概念。
尽管两者在某些选择上趋于一致,但在背后起作用的关键认知维度也存在一些区别:
人类更具灵活性和感知整合能力,而模型则更侧重语言驱动的语义归类。这种对比反映出当前人工智能在模仿人类决策过程中的局限性与进步空间。

本文研究发现具有广阔的应用前景,包括:
-
类脑智能:寻找机器与人类间的认知结构差异,开发与人类认知维度对齐的AI系统 (NeuroAI) -
神经科学:基于大模型的类人“心智维度”探索生物脑实现概念组合与泛化、灵活决策与推理的神经机制(AI for Neuroscience) -
脑机接口:利用大模型核心维度表征解码大脑神经信号,构建认知增强型脑机接口系统(AI for BCI)
团队还指出了下一步重点:
-
拓展至新一代多模态大模型,形成认知基准测试平台,为评估AI的语义理解提供客观标准。正如论文通讯作者何晖光研究员所说:“这项工作不仅是在测试AI的能力,更是在寻找人与机器之间共通的认知语言,探测AI模型的“概念地图”只是第一步,未来需要建立涵盖推理、情感等维度的完整认知评估体系。” -
采用更大规模、更加细粒度、层次化的概念集,全面建立大模型“认知图谱”。 -
开发基于认知对齐的大模型持续微调方法,构建新一代认知增强型大模型。
团队简介
自动化所副研究员杜长德为第一作者,何晖光研究员为论文通讯作者。

杜长德,中国科学院自动化研究所副研究员,硕士生导师。
杜长德从事脑认知与人工智能方面的研究,在神经信息编解码、多模态神经计算、NeuroAI、脑机融合智能等方面发表论文50余篇,包括Nature Machine Intelligence、IEEE TPAMI、ICLR、ICML等。
曾获得2019年IEEE ICME Best Paper Runner-up Award、2021年AI华人新星百强、中国科学院院长优秀奖等。长期担任Nature Human Behaviour, TPAMI等重要期刊的审稿人。个人主页:https://changdedu.github.io/

何晖光,中国科学院自动化研究所研究员,博士生导师,国家高层次人才,中国科学院大学岗位教授,上海科技大学特聘教授。
其研究领域为脑-机接口、类脑智能、医学影像分析等,在CNS子刊, IEEE TPAMI, ICML等发表文章200余篇。他还是自动化学报编委,CCF/CSIG杰出会员。
论文的主要合作者还包括脑智卓越中心的常乐研究员等。该研究得到了中国科学院基础与交叉前沿科研先导专项、国家自然科学基金、北京市自然科学基金项目以及脑认知与类脑智能全国重点实验室的资助。
团队还表示正在招收2026级博士生、硕士生。招生方向:脑机接口、NeuroAI、类脑智能、脑机融合智能等。欢迎对此方向感兴趣的同学报考(邮箱:changde.du@ia.ac.cn)。
论文链接:https://www.nature.com/articles/s42256-025-01049-z
代码:https://github.com/ChangdeDu/LLMs_core_dimensions
数据集:https://osf.io/qn5uv/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)