

王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
近年来,大型语言模型(LLMs)在多模态任务中取得了显著进展,在人工通用智能(AGI)的两大核心支柱(即理解与生成)方面展现出强大潜力。然而,目前大多数多模态大模型仍采用自回归(Autoregressive, AR)架构,通过从左到右逐步处理多模态 token 来完成任务,推理缺乏灵活性。
与此同时,基于掩码的离散扩散模型凭借双向建模能力也逐渐兴起,该架构通过双向信息建模显著提升了模型的建模能力。例如,DeepMind 的 Gemini Diffusion 验证了离散扩散在文本建模领域的潜力;在开源社区,LLaDA、Dream 等扩散式大语言模型(dLLM)也催生了如 MMaDA、LaViDA、Dimple 和 LLaDA-V 等多模态模型。基于掩码(mask)离散扩散为多模态任务提供了一种重要的建模范式。
然而,生成模型的实现方式并不局限于上述两类架构,探索新的生成建模范式对于推动多模态模型的发展同样具有重要意义。
基于这一理念,来自香港大学和华为诺亚方舟实验室的研究团队提出了 FUDOKI,一个基于全新非掩码(mask-free)离散流匹配(Discrete Flow Matching)架构的通用多模态模型。
与传统的自回归方法不同,FUDOKI 通过并行去噪机制实现了高效的双向信息整合,显著提升了模型的复杂推理和生成能力。与离散扩散架构相比,FUDOKI 采用更加通用的概率路径建模框架,从均匀分布出发,允许模型在推理过程中不断更新和修正生成结果,为多模态模型打开了一条崭新的技术路径。

-
论文标题:FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
-
论文链接:https://arxiv.org/abs/2505.20147
-
项目主页:https://fudoki-hku.github.io/
FUDOKI 的核心亮点包括如下:
-
统一架构:一套简单直观的框架搞定图像生成与文本理解
-
彻底去掩码:无需掩码(mask)策略,与 mask-based discrete diffusion 相比更通用
-
支持动态修正:生成过程可实时调整,更接近人类推理方式
-
性能对标 / 超越同参数 AR 模型(在 GenEval & 多模态 QA 上有实测)
我们先来看以下两个效果展示:
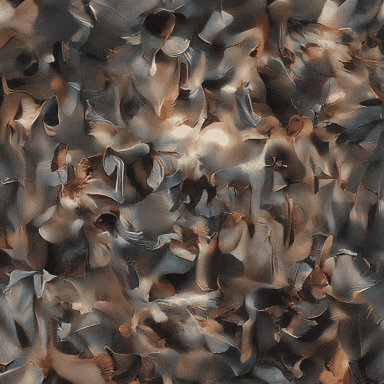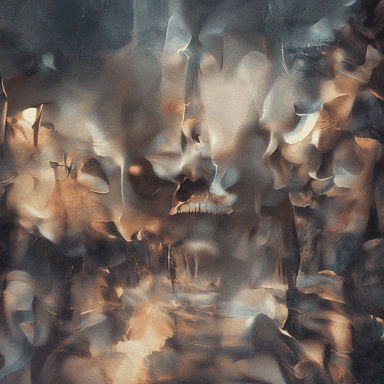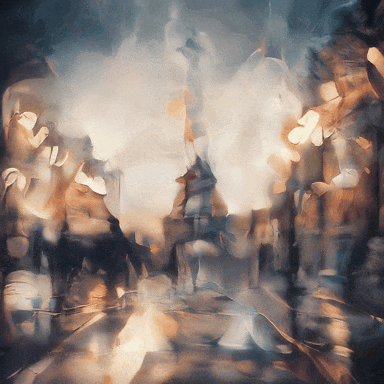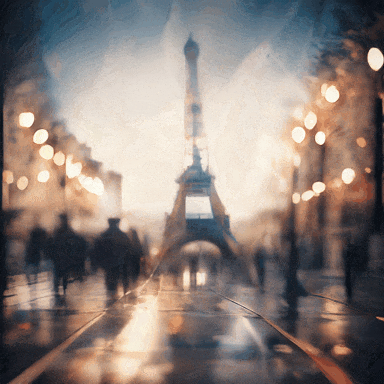
图片生成
图片理解
在社媒上,FUDOKI 获得了Meta Research Scientist/ Discrete Flow Matching 系列作者推荐:
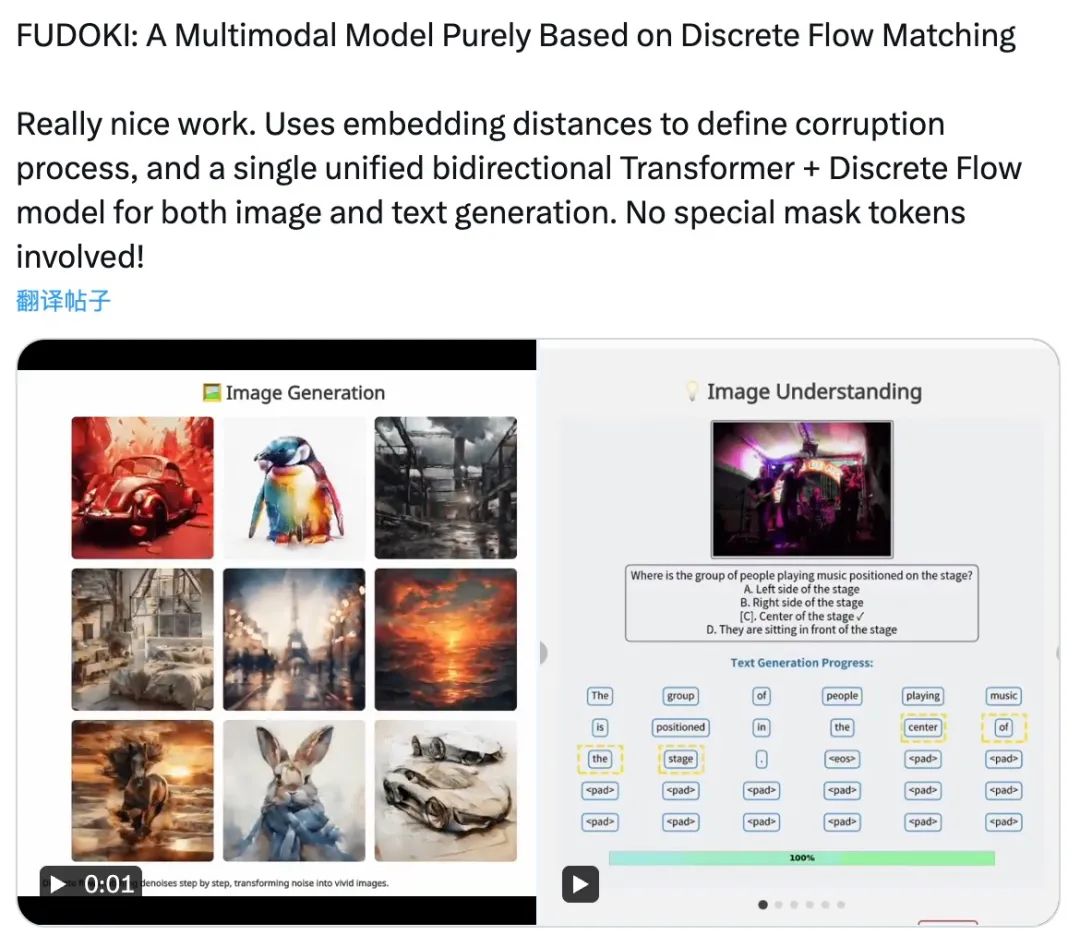
统一的多模态能力
FUDOKI 对文本模态和图像模态均采用通过统一的离散流匹配框架,实现了理解与生成任务的统一建模。
-
图像生成:文本到图像生成任务上在 GenEval 基准上达到 0.76,超过现有同尺寸 AR 模型的性能,展现出色的生成质量和语义准确性

文生图样例
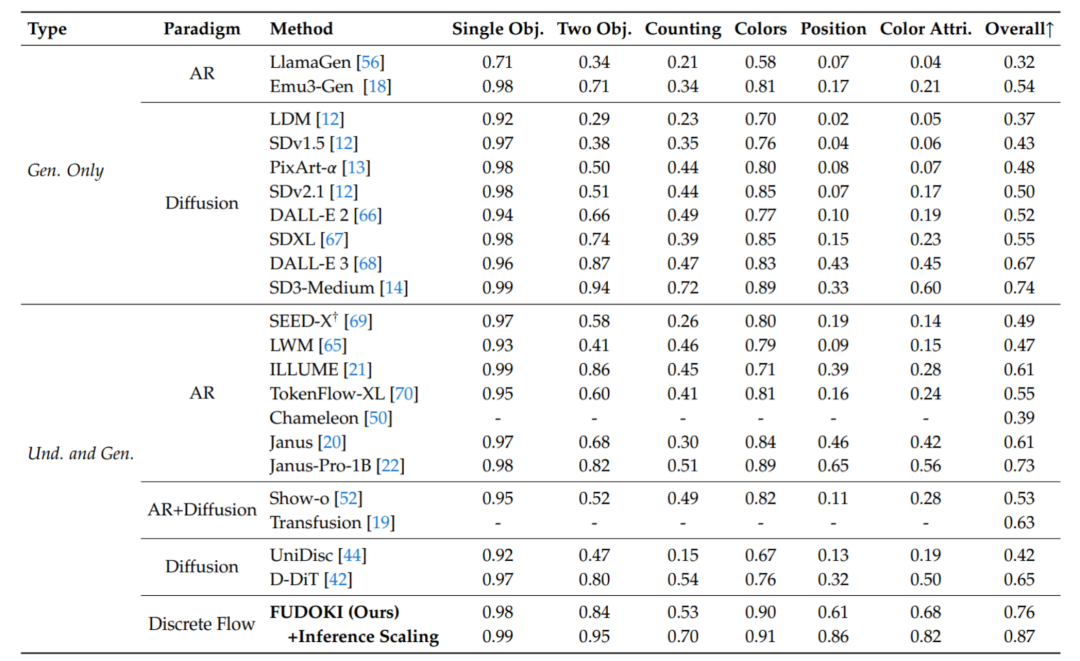
GenEval 基准评测结果

离散流生成过程
-
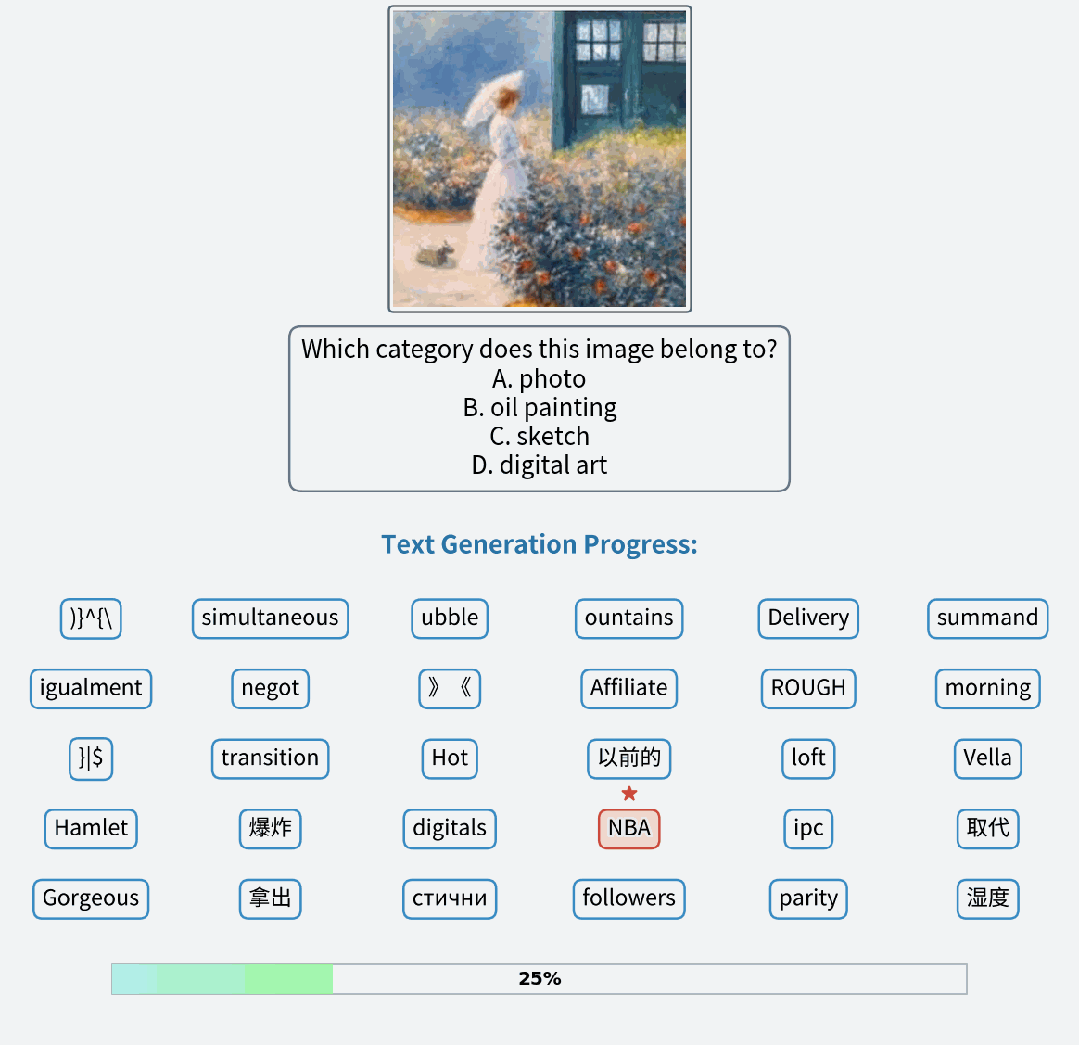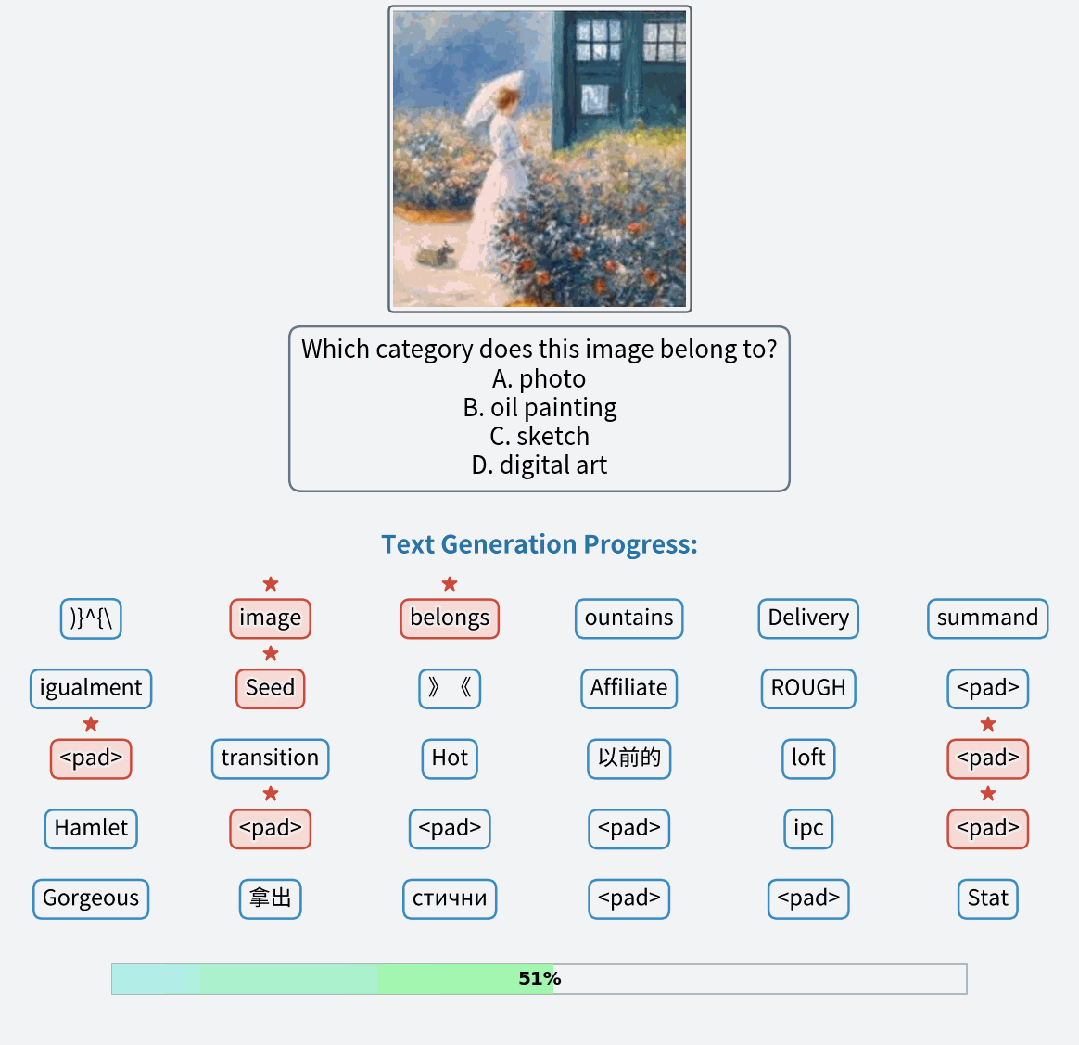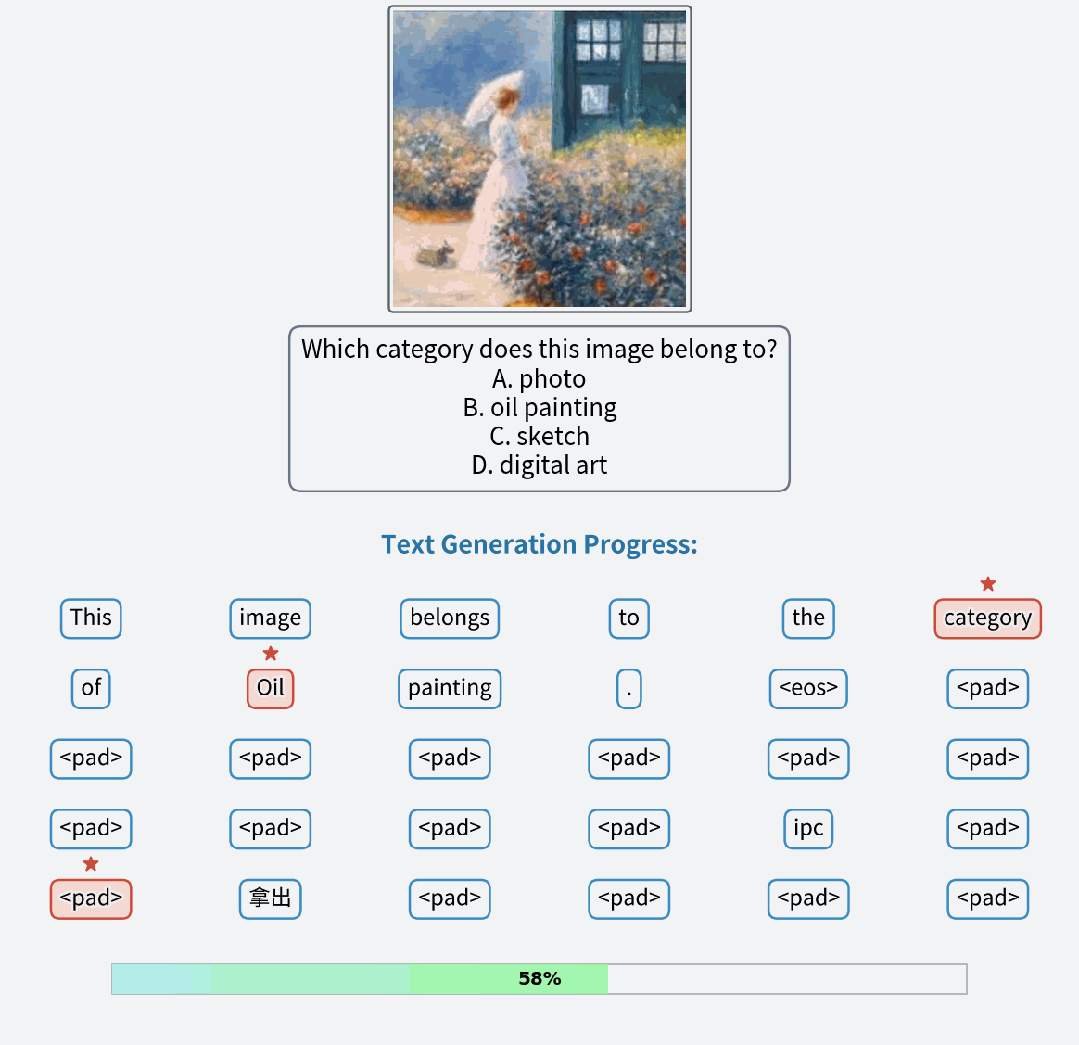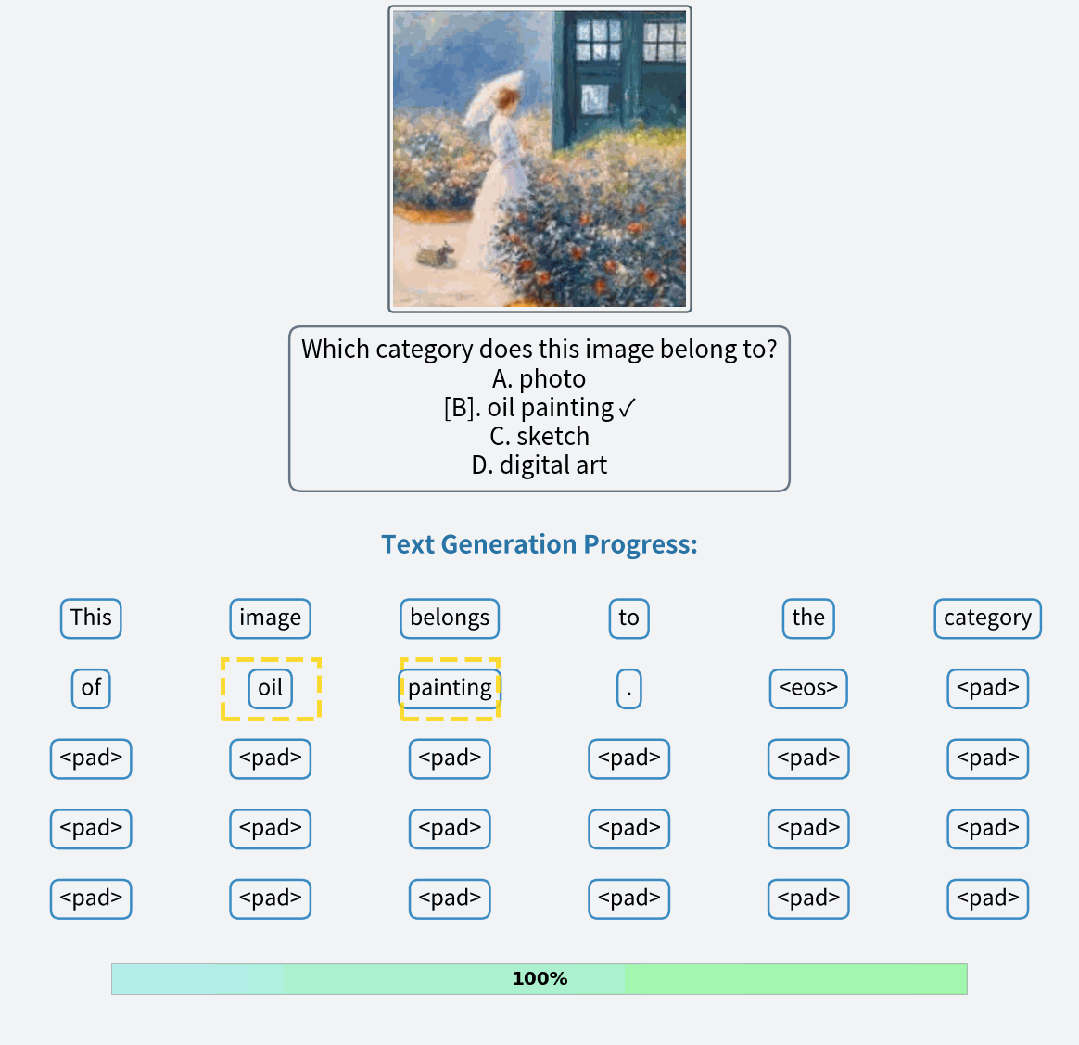
视觉理解:在多模理解任务上接近同参数量 AR 模型的性能水平,并允许模型在推理过程不断修复回答。

视觉理解样例
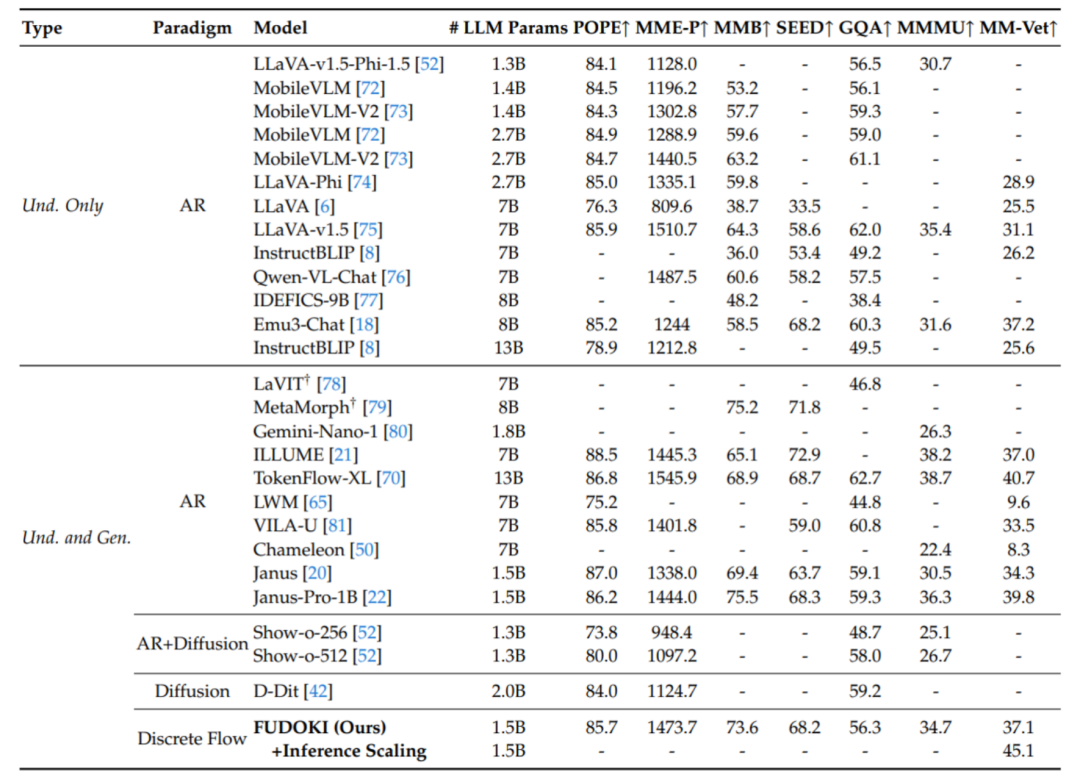
视觉理解基准评测
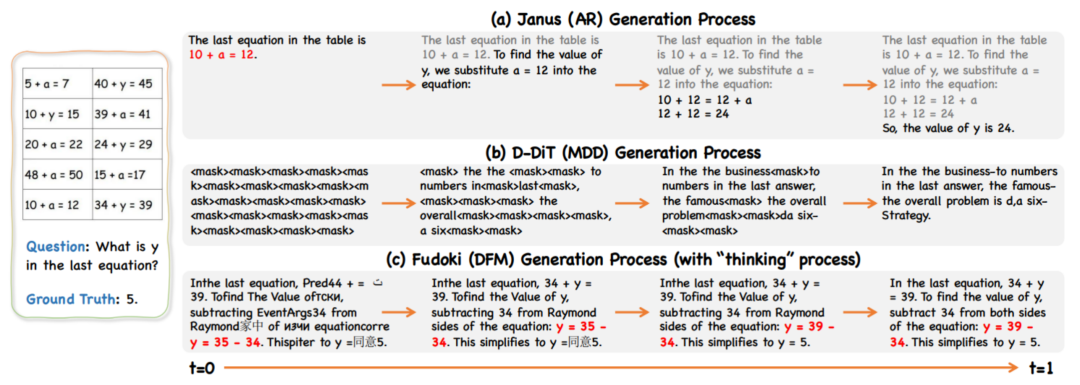
视觉理解案例的过程对比,FUDOKI 允许对已生成的回答进行修正
架构特色
FUDOKI 的核心创新在于将多模态建模统一到离散流匹配框架中。具体而言,FUDOKI 采用度量诱导的概率路径(metric-induced probability paths)和动力学最优速度(kinetic optimal velocities),完成从源分布到目标分布的离散流匹配。
基于度量诱导的概率路径
FUDOKI 的离散流采用基于度量诱导的概率路径,定义了一种语义上更有意义的转换过程。在前向过程中(t 从 1 减少到 0),FUDOKI 会对每个 token  的概率分布(即 0/1 分布)进行逐步扰动,直到趋近于均匀分布。值得注意的是,在扰动过程中,FUDOKI 的离散流会综合考虑字典里每个 token 与真实数据 token
的概率分布(即 0/1 分布)进行逐步扰动,直到趋近于均匀分布。值得注意的是,在扰动过程中,FUDOKI 的离散流会综合考虑字典里每个 token 与真实数据 token 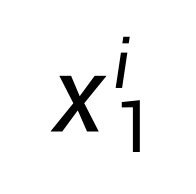 的语义距离
的语义距离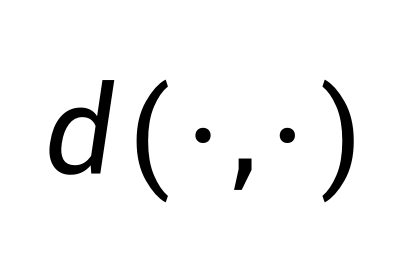 ,并使用如下公式计算概率路径,使得所有与语义相似的 token 仍然具有较高的概率。
,并使用如下公式计算概率路径,使得所有与语义相似的 token 仍然具有较高的概率。
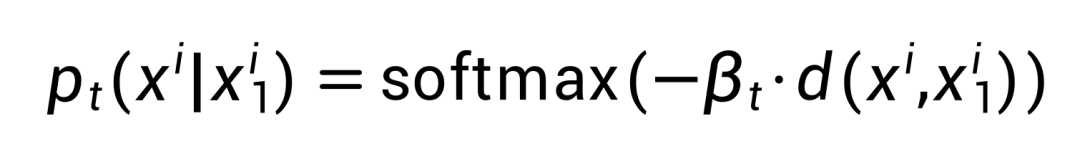
动力学最优速度
FUDOKI 的反向过程(t 从 0 增加到 1)通过并行去噪机制,将 t=0 的均匀分布逐步映射回 t=1 的目标分布(即 0/1 分布)。具体而言,在时刻 t,FUDOKI 会根据动力学最优速度 u 对第 t+h 时刻的 token 进行重采样,计算方式如下:
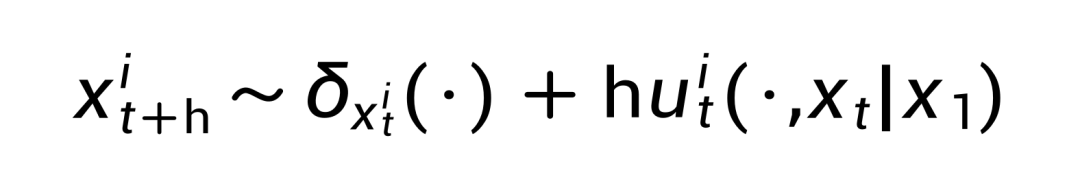
这一机制具有两个关键特性:首先,随着 t 从 0 增加到 1,动力学最优速度 u 会提升与真实数据 token 语义相似的候选 token 的概率,使模型能够在每个时间步采样到语义相近的替代 token,从而有效扩展了采样空间的多样性。此外,该采样策略还支持在反向过程中对已生成的 token 进行动态调整与修正,为生成过程提供了更大的灵活性。
模型结构与训练损失
为降低大规模离散流匹配模型的训练成本,FUDOKI 通过利用预训练的自回归(AR)模型进行初始化,最大化复用现有模型的知识,从而实现从 AR 范式到流匹配范式的平滑过渡。其训练损失函数与离散扩散模型类似,目标是让模型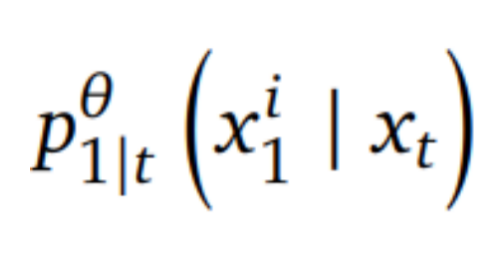 预测出加噪样本所对应的真实数据。具体而言,训练过程中采用交叉熵损失函数,以优化模型在生成任务中的性能。
预测出加噪样本所对应的真实数据。具体而言,训练过程中采用交叉熵损失函数,以优化模型在生成任务中的性能。
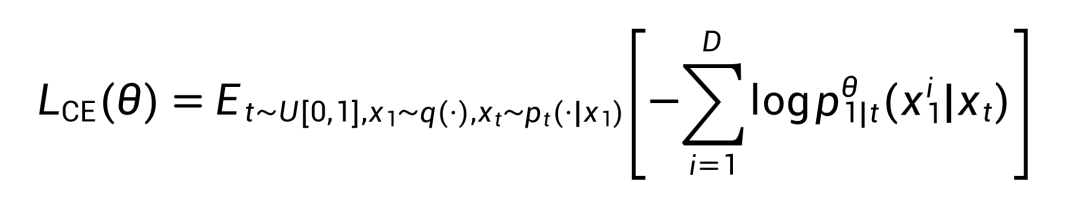
结语
FUDOKI 的提出不仅挑战了现有自回归和掩码扩散范式,也为多模态生成与理解的统一架构带来了新的思路。通过离散流匹配的方法,它为通用人工智能的发展提供了更加灵活和高效的技术基础。我们期待未来会有更多的探索和进展。

©
(文:机器之心)