
对于从事文档智能(Document AI)开发的产品经理和工程师而言,一个持续存在的挑战是在精度、延迟和成本三者之间做出权衡。当前,主流的文档解析技术路径主要有两条,但都存在明显的局限性:
-
1. 流水线 (Pipeline) 模式:将文档解析拆分为布局分析、文本识别、表格/公式识别等多个串联模块(如MinerU)。这种方法的优点是模块化、易于维护和优化。但其致命弱点在于错误累积 (Error Accumulation)。上游模块的任何微小偏差(例如,边界框检测不准),都会被传递并放大到下游,最终影响整体输出质量。 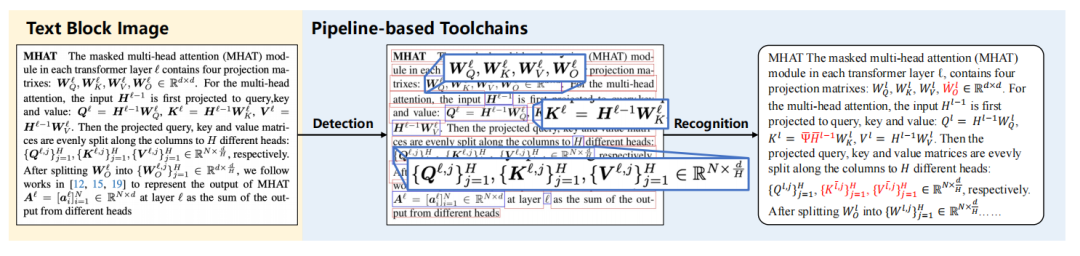
图:流水线方法中,不精确的公式检测(中)导致识别结果(右)出现错误,这正是错误累积的典型表现。 -
2. 端到端 (End-to-End) 大模型模式:利用大型多模态模型(LMMs)直接处理整页文档图像,试图一步到位生成结构化结果(如Qwen-VL)。这种方式简化了流程,但由于Transformer注意力机制的二次方复杂度,处理高分辨率、信息密集的文档时,会面临巨大的计算开销和高延迟,这对规模化部署和成本控制是极大的挑战。
面对这一困境,MonkeyOCR团队没有选择在两条旧路上继续优化,而是提出了一种全新的解决方案。
核心创新:SRR (Structure-Recognition-Relation) 三元组范式
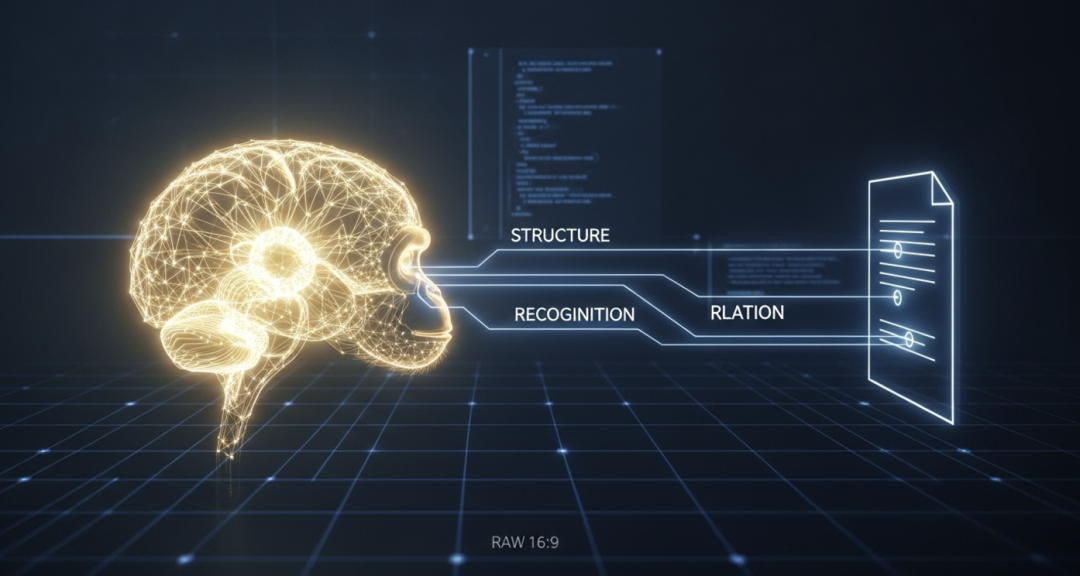
MonkeyOCR的核心是SRR三元组范式,它将复杂的文档解析任务智能地解耦为三个相对独立且可高效执行的阶段。这可以理解为一个高度优化的混合系统:
-
1. 结构 (Structure) – 定位语义区域 -
• 做什么:使用一个轻量级的YOLO检测模型,对文档页面进行快速布局分析,识别并定位出所有语义区域的边界框,如文本块、表格、公式、图片等。 -
• 为什么有效:这一步实现了对页面宏观结构的快速理解,并将一个大而复杂的任务分解为多个小的、标准化的子任务。 -
2. 识别 (Recognition) – 并行处理内容 -
• 做什么:将上一步检测出的所有区域块(Region)并行地送入一个统一的3B多模态模型进行内容识别和结构化。无论是文本、表格还是公式,都由同一个模型处理。 -
• 为什么有效:通过分块处理和并行计算,极大地降低了单个任务的上下文长度,规避了处理整页图像时的高昂算力开销。这使得系统能够以高吞吐量运行。 -
3. 关系 (Relation) – 重构逻辑顺序 -
• 做什么:引入一个独立的阅读顺序预测模型,分析所有已识别内容块的几何与逻辑关系,最终生成符合人类阅读习惯的文档流。 -
• 为什么有效:将逻辑顺序重构作为独立一步,专门处理多栏、图文混排等复杂布局,确保了最终输出内容的结构正确性和可读性。
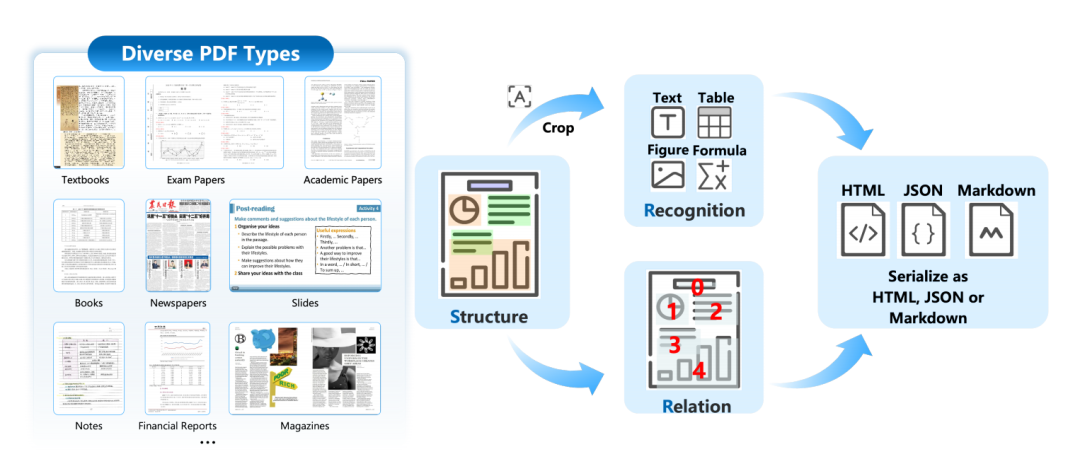
SRR范式的本质,是一种智能的“解耦-并行”架构,它既保留了流水线的灵活性,又通过统一识别模型避免了不同工具间的标准不一和错误累积,同时还解决了端到端大模型的效率瓶颈。
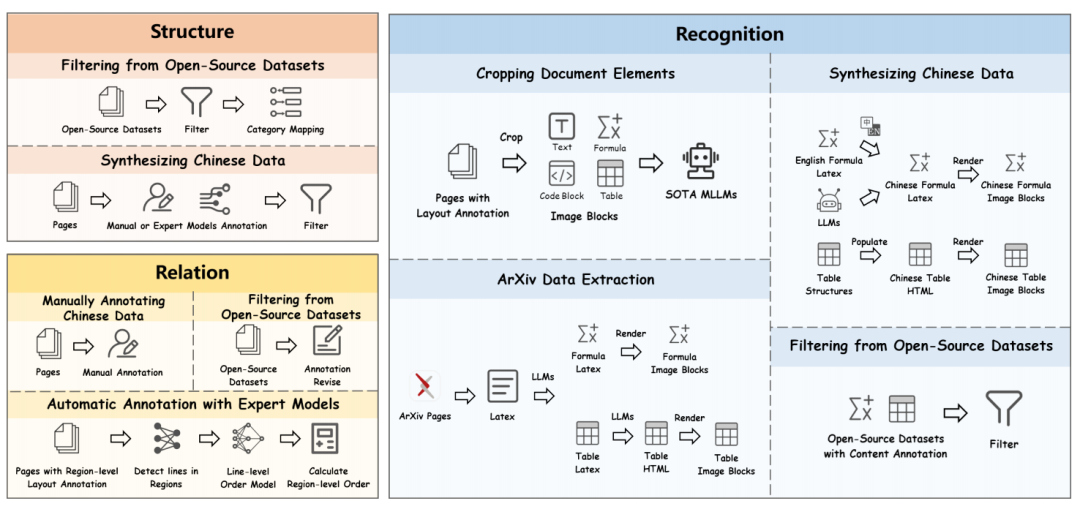
基石:高质量、大规模的MonkeyDoc数据集
优秀的模型架构需要高质量数据的支撑。MonkeyOCR的卓越性能,很大程度上归功于其训练所用的MonkeyDoc数据集。对于AI工程师来说,这是一个宝贵的资产:
-
• 规模与覆盖面:包含390万个实例,覆盖超过10种中英文文档类型,包括学术论文、财报、教科书、手写笔记等。 -
• 任务全面性:一个数据集同时支持布局检测、文本识别、表格识别、公式识别、阅读顺序预测等所有核心文档解析任务。 -
• 高质量构建:通过对公开数据集的精细筛选、大规模人工标注、程序化数据合成(尤其针对稀缺的中文表格和公式),以及专家模型辅助的自动化标注流程,确保了数据的多样性和准确性。
性能验证:数据驱动的全面评测
在权威的OmniDocBench基准上,MonkeyOCR的性能数据极具说服力。
1. 综合性能对比
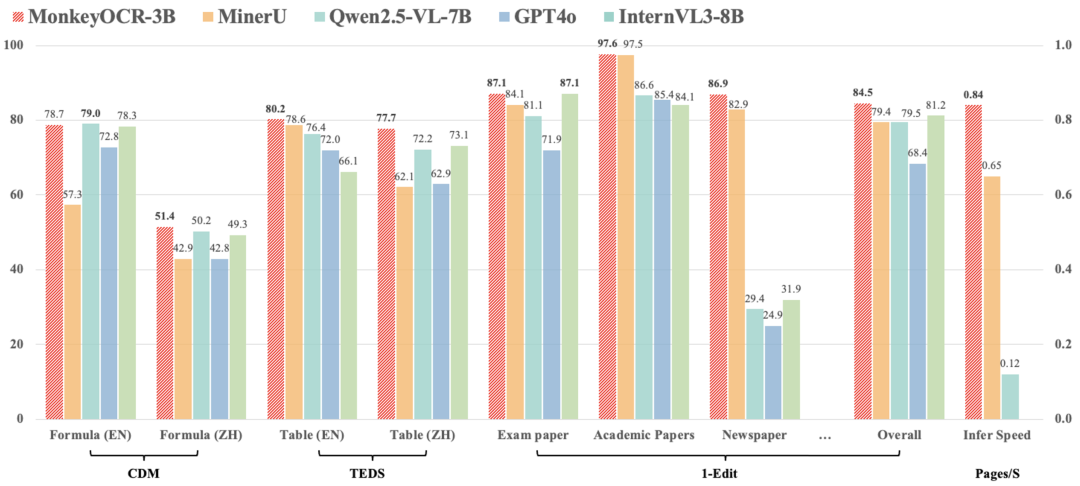
2. 关键任务上的性能优势
下表展示了MonkeyOCR与主流模型在具体任务上的量化对比。
|
|
|
|
Formula CDM↑ | Table TEDS↑ |
|
|
|
|
|
|
EN | ZH |
|
|
|
|
|
|
|
|
|
|
|
|
79.0 |
|
| Mix | MonkeyOCR-3B | 0.140 |
|
|
51.4 |
|
|
MonkeyOCR-3B
|
|
0.277 |
|
|
表: 关键任务性能对比(Edit指标越低越好,CDM/TEDS指标越高越好)。
关键数据解读:
-
• 相比流水线代表MinerU,MonkeyOCR在处理难点任务上优势明显:英文公式识别准确率(CDM)提升约21.4% (78.7 vs 57.3),英文表格结构识别(TEDS) 提升1.6% (80.2 vs 78.6)。在中英文任务上,公式性能平均提升15.0%,表格性能平均提升8.6%。 -
• MonkeyOCR-3B* 是针对中文优化的版本,在中文阅读顺序预测上取得了当前最佳成绩(Edit 0.183)。
3. 与顶级大模型的直接对话
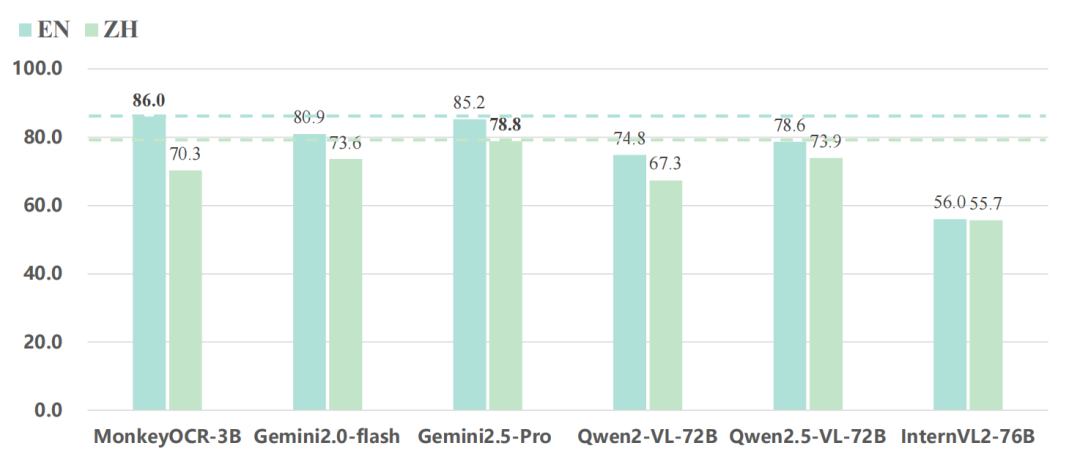
关键结论:
-
• 在英文文档解析任务上,3B参数的MonkeyOCR取得了SOTA(State-of-the-Art)性能,其综合表现超越了72B的Qwen2.5-VL,甚至以微弱优势优于谷歌的旗舰模型Gemini 2.5 Pro。 -
• 在中文任务上,Gemini 2.5 Pro表现出更强的能力,这也表明MonkeyOCR在中文场景下仍有持续优化的空间。
实现与工程价值
对于产品和工程团队而言,MonkeyOCR最大的吸引力在于其卓越的能效比和低部署门槛。
-
• 轻量化模型:核心模型仅3B参数。 -
• 硬件要求:可在单张NVIDIA 3090 GPU上高效完成推理。 -
• 高处理效率:在处理多页文档时,推理速度可达0.84页/秒,显著高于MinerU (0.65 pages/S) 和Qwen2.5-VL-7B (0.12 pages/S)。
这意味着,企业无需投入昂贵的A100/H100集群,即可部署一套性能顶尖的文档解析服务,这对于成本控制和技术普及具有重要意义。

总结与启示
MonkeyOCR的成功,为文档AI领域带来了几个重要的技术启示:
-
1. 架构创新优于盲目扩大规模:在一个垂直领域,通过精巧的系统设计(如SRR范式),一个中等规模的模型完全有可能在性能和效率上超越通用的大型模型。这为资源有限的团队提供了新的解决思路。 -
2. “智能流水线”是未来方向:传统流水线并未过时,而是可以向更加智能、解耦和并行的方向进化。SRR范式正是这种“智能流水线”的成功实践,它规避了传统方法的缺陷,同时发挥了模块化的优势。 -
3. 专用高质量数据是核心壁垒:MonkeyDoc数据集的构建,再次证明了在AI工程中,高质量、高相关性的数据是模型性能突破的基石和核心竞争力。
MonkeyOCR不仅提供了一个即插即用的强大工具,更重要的是,它为如何构建下一代高效、精准、可落地的文档智能系统,提供了一个极具参考价值的范本。
资源链接
读
-
• “互联网女皇”首份AI报告深度解读:“互联网女皇”首份AI报告深度解读:科技大爆炸前夜,谁主沉浮?
-
• 论文原文: https://arxiv.org/abs/2506.05218 -
• GitHub代码库: https://github.com/Yuliang-Liu/MonkeyOCR -
• 在线Demo: http://vlrlabmonkey.xyz:7685/ -
• 模型下载 (Hugging Face): https://huggingface.co/echo840/MonkeyOCR
(文:子非AI)