

“零基础小白用 Cursor 两小时开发了一个商业级小程序,月入五万”,
这件事真不真我不知道,但是现在确实有个一晚上入五万的机会,等着我和我的 Cursor 去参加。
没错,一年一度的AFAC大赛开始了,由计算机学会、北大、复旦、交大、英伟达等组织,以金融为主题分为挑战组和初创组。
6月3日到7月26日,每天都可以提交3次代码来抢名次。我这次受邀参加了挑战组的比赛,一等奖奖金50k啊。
第一步的选题我就不想了,让 Cursor 干吧,
挑战组里面的四个选题分别是基金产品的长周期申购和赎回预测、金融保险场景下多源文件长上下文一致性校验、智能体赋能的金融多模态报告自动化生成和金融领域中的长思维链压缩。
用 Cursor 的话来说赛题三本质上是对大模型推理过程中的冗余内容进行精简。比起其他赛题需要复杂的数据处理、业务理解和系统搭建,赛题三的数据结构相对简单,听上去是一晚上能做完的样子。

第二步整理任务说明,分解要做的任务我就不想了,让 Cursor 干吧,
这次我给 Cursor 开的是 Agent 模式,允许它自动调度各类模型,最大程度不限制它的发挥。

顺带分享一下我最近在用的 Cursor 布局,
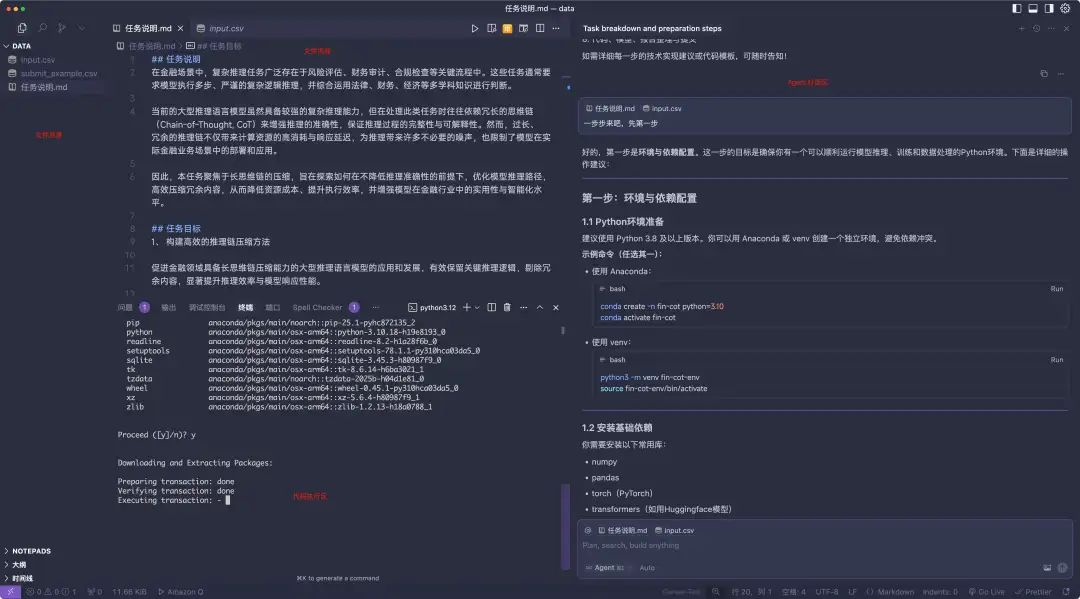
Cursor 给出的步骤清单是这样子的:
1. 环境与依赖配置
2. 数据解压与理解
3. baseline模型准备
4. 推理链压缩方法设计
5. 批量推理与多样性采样
6. 输出格式化与保存
7. 评测与方法优化
8. 代码、模型、报告整理与提交
为了追上前面165支队伍的得分,
我决定一步并两步,四步就完成这次任务。
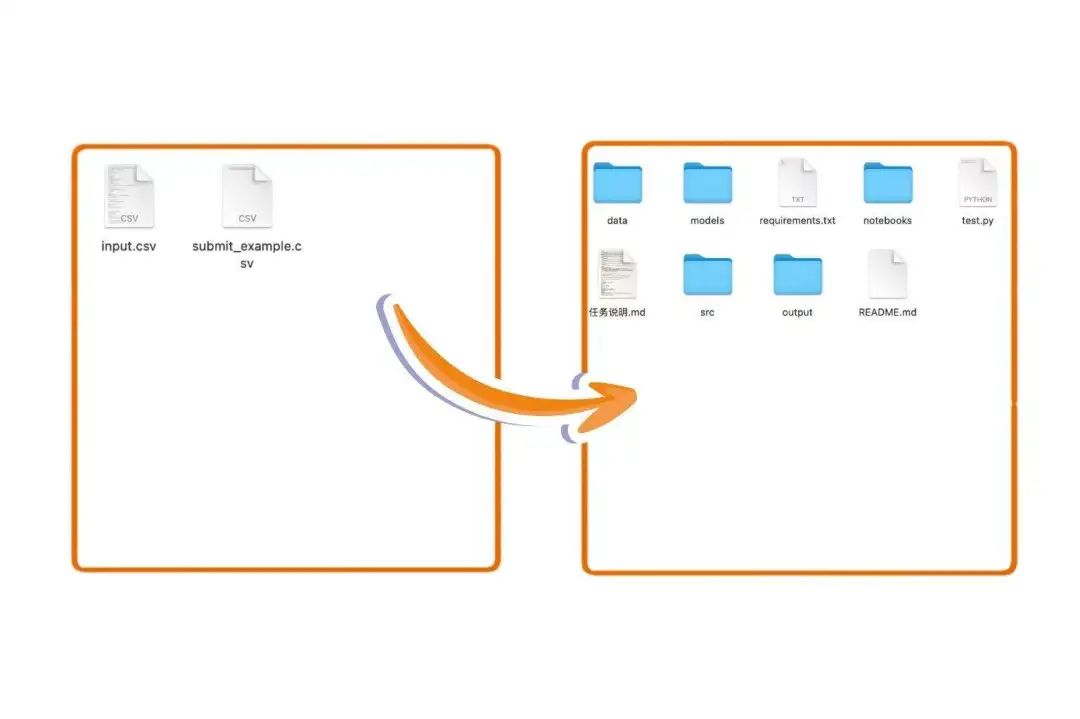
第三步的话我在 Cursor 辅助下完成环境配置和数据解压
这是项目文件前后对比:
虽然我也不是第一次参加技术比赛了,
但是有大模型的超长上下文的帮助,我可以将100道题目丢到模型去统计长度和题型,再见了 Embedding、再见了词频统计、再见了 fasttext。
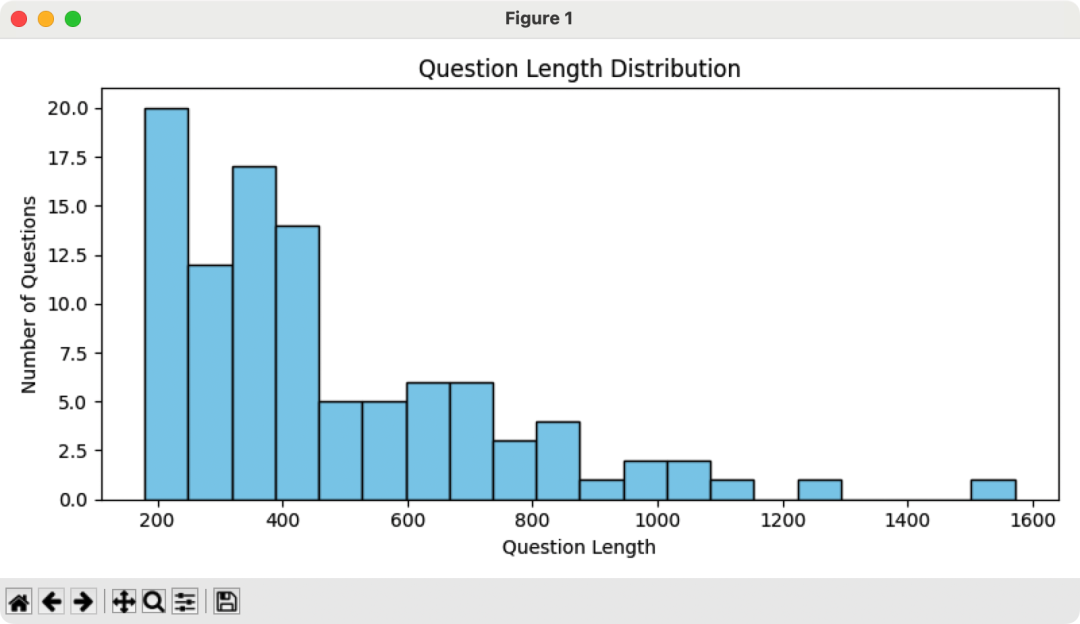
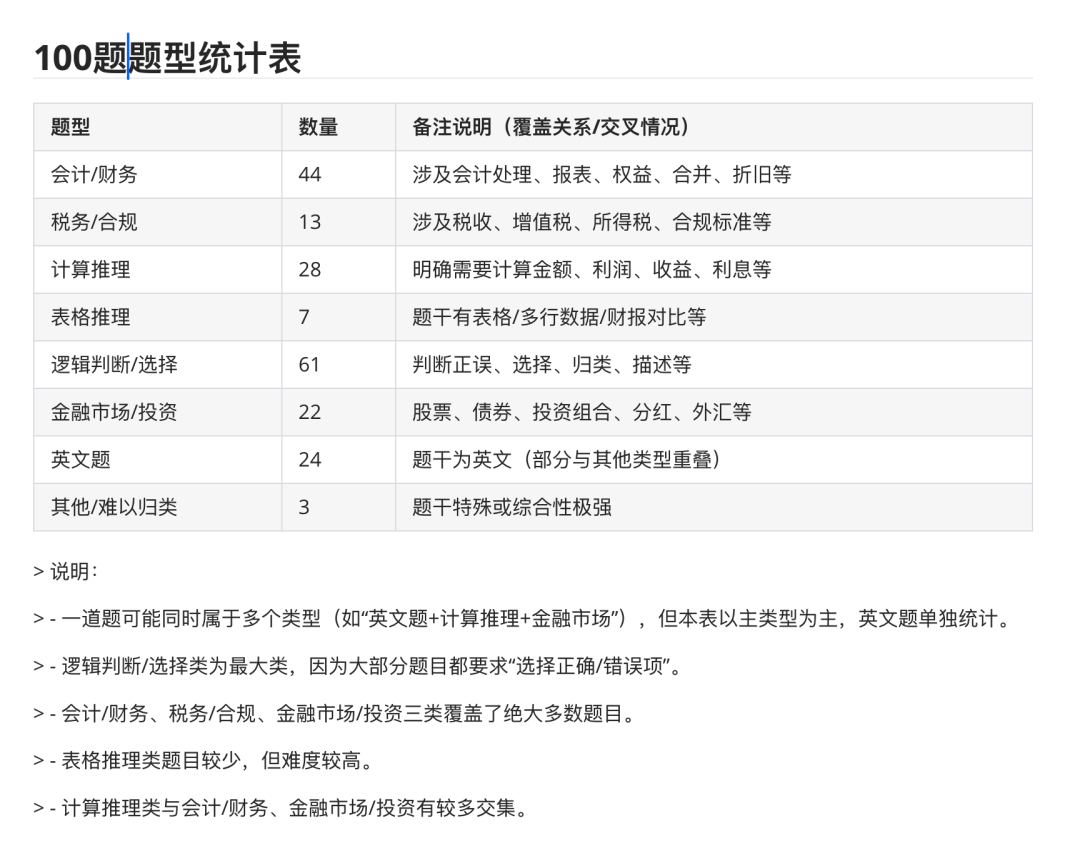
等待Qwen3-4B模型的间隙,我还单独随机抽取了一条数据给Qwen3-235B-A22B解答,一次思考就用了4千token,压缩难度还是有的,

但是,Cursor 反直觉设计出了一个完全不需要训练模型的方法,

听起来有点不太靠谱啊,我说停停,
这个比赛要提交的文件里明明是需要提交模型的参数和训练代码的啊,我本来还打算租几张卡,让 Cursor 辅助我训练模型。
这一下子成本低到我有点不好意思了都,但本着来都来了,要不第一版本先试试看 Cursor 给的这套几乎没成本、只修改了提示语的方案能不能顺利提交吧。
请你扮演一位金融和会计领域专家,回答以下问题。请用最简洁的推理链,去除冗余,只保留关键推理步骤,最后用 \\boxed{} 给出答案。\n
结果还真的就成功提交了
成绩应该是要明天才能看到了,我会实时更新在评论区的!
有 Cursor 在场真的太爽了,输出文件的格式都不需要我担心,目前为止生成的所有代码都在模型们的舒适区内,甚至还没有平时做一个3D动画演示网页做的代码复杂。
提交完代码后,我现在已经按照系统的提示潜入比赛 Group 里了,要是有新的刷榜的好办法的话,我可以将聊天记录打包给 Cursor,让它再给我出一版方案。
因为是一个1个多月的长期项目,所以之前学到的 Cursor 小技巧派上用场了。
创建一个 todolist.md 文件,使用复选框并列出你需要完成的所有任务。让每个任务成为一个勾选框,在其下方放置项目符号。然后,一旦完成,你就可以逐个完成任务列表,将它们勾选掉。
这样就可以有效防止过个四五天后打开 Cursor,我和它都忘记做到哪了。
最开始,我只是想验证一个想法:
如果让 AI 做我的队友,能不能撑起一整支参赛团队?
结果证明,不仅可以,
而且效率高得离谱。
所以想和大家分享一点点我的思路,
算抛砖引玉,
期待看到大家更多天马行空的想法和作品。
对了对了,就算是不参加比赛的话也能薅薅官方的羊毛,

(文:卡尔的AI沃茨)